OpenAI超级对齐团队发布第一篇论文,Ilya带头研究,用GPT-2监督GPT-4
OpenAI 又搞出大动作了!
由OpenAI 首席科学 Ilya Sutskever 领导的 “超级对齐”团队发布了他们的第一篇论文,提出了“弱对强泛化”的概念以及用小模型 GPT-2 监督大模型 GPT-4 的方法,展示了未来控制超级AI智能的有效手段!
早在今年七月,OpenAI 就提出“未来十年内,可能会出现智商超过人类的 AI 系统”,而如果真的出现这种 AI 系统,那么迫在眉睫的问题将是“如何使得超级 AI 与人类利益对齐?”
区别于现在的诸如 RLHF 这样的对齐方法,“超级对齐”问题面临的最大挑战在于:这是一个“未来”的问题,在目前我们仅仅知道他们“将来”,但是事实上却对超级 AI 一无所知。

面对这样一个“谜题”,由 Ilya Sutskever 领衔,OpenAI 于今年7月成立了 Superalignment 超级对齐团队,使用当下 OpenAI 20% 的算力,携手之前对齐部门的科学家与工程师,致力于在四年内解决超级 AI 的对齐与控制问题(刚刚!OpenAI宣布,斥巨资建立「超级对齐」团队!向人类意图看齐)!
而很快,就在今天 OpenAI 官宣了 Superalignment 团队的第一篇论文——《Weak-To-Strong Generalization: Eltciting Strong Capabilities With Weak Supervision》,奥特曼也发推捧场,称赞其为“Great Work”。

针对这个超级 AI 的对齐问题,事实上 Superalignment 团队另辟蹊径绕开了定义“超级 AI 是什么”的问题,没有直接测试人类是否真的可以充分地监督超级 AI,转而测试了一般的弱人工智能是否可以监督更强的人工智能。
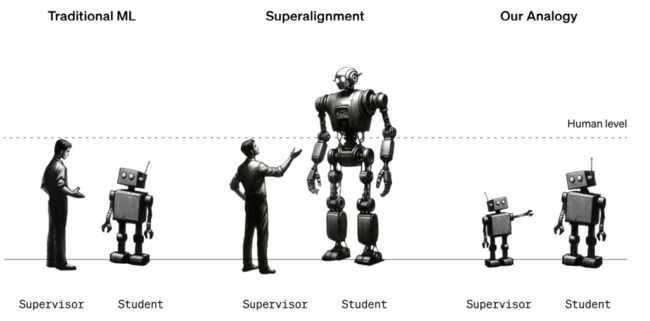
套用论文中非常有趣的一张图片,传统的机器学习方法是监督者监督对齐弱 AI,而如果当所谓超越人类水平的超级 AI 出现,人类极有可能无法监督指导与控制强 AI 的行为,而这篇研究如下最右边的图片,探索了如何使用弱 AI 去监督控制强 AI,即“一个弱 AI 如何监督一个强 AI”,为“自动化”的控制超级 AI 打下基础。
具体而言,超级对齐团队定义了三种任务,分别是一组有代表性的 NLP 任务、国际象棋以及 RLHF 中的构建 Reward model 的问题。依据以下三步,论文做了广泛的实验:
-
创建一个弱监督者:通过在真实标签上微调小型模型(GPT-2)创建弱监督者,并称弱监督者的性能为 Weak performance;
-
训练一个强学生模型:使用弱监督者预测的弱标签,微调大型模型(GPT-4),称微调后的大模型为强学生模型,其性能为 Weak-to-strong performance;
-
训练一个强模型:使用真实标签微调大模型构成强模型作为参照,其性能被称为 Strong ceiling performance。
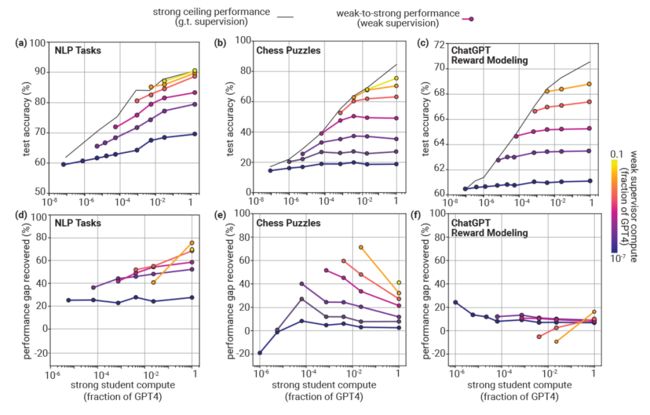
而在实验中,论文团队发现,使用弱标签微调后的强学生模型,其性能几乎始终高于原本的弱监督者,即使弱监督者有时会在数据集中的一些例子上“犯错”,但是强学生模型依然可以发现并纠正这些错误,实现更高的正确率:

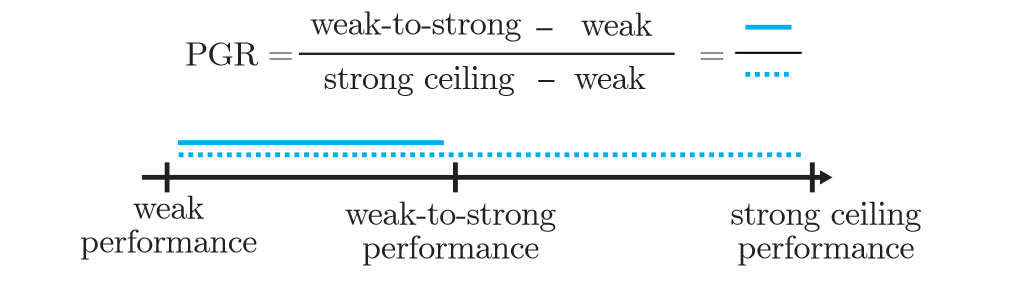
这一有趣的现象催生了超级对齐团队的思考,并将其定义为一个“弱对强泛化”的问题,类似于传统泛化理论的训练误差、泛化误差与近似误差,如下图所示,论文定义了从弱监督者的 Weak performance 到弱学生模型的 Weak-to-strong performance 以及强模型对照的 Strong ceiling performance。
显然,理论上,Strong ceiling performance 将会大于 Weak-to-strong performance 且大于 Weak performance,而“弱对强泛化”问题研究的,正是如何增强强学生模型的性能缩小 Weak-to-strong performance 与 Strong ceiling performance 的距离,为此论文定义了 Performance Gap Recovered (PGR) 如下作为指标刻画“弱对强泛化”问题
跟随这个问题出发,论文进行了大量的实验来研究“弱对强泛化”,以强学生模型的规划为变量,作者不仅发现在几乎所有规模的学生模型下,学生模型都呈现了比弱监督器更好的性能(PGR 为正),还发现了在 NLP 任务上这种弱对强泛化表现的尤其的好,使用 GPT-2 进行弱监督 GPT-4 可以提升 20% 以上的规模差距,对于完整版 GPT-4,PGR 将高于 50%。
但是这种“规模效应”却在国际象棋任务上显得力不从心,甚至 PGR 会随着学生模型的规模增加而减小,甚至在 Reward Model 构建任务上,弱对强泛化能力非常低,学生模型与弱监督者的性能之间只有不到 10% 的差距:
面对这一现象,论文团队认为这种“弱对强泛化能力差”是“一个可以解决的问题”,具体而言,论文使用了两种方法作为“弱对强泛化能力”的提升手段,分别是 Bootstrapping 和添加辅助置信度损失(Auxiliary Confidence Loss)。
对于 Bootsrapping 其实很好理解,从不同模型的规模出发,论文构建了一个弱监督训练的线性序列,依据参数量的大小从小到大构建 , , , ……, n 个模型,先有监督微调 ,再使用 弱监督微调 ,使用 弱监督微调 ,依此类推。在象棋任务中,作者发现 Bootstrapping 极大的提升了学生模型的性能:

而借鉴之前半监督学习的研究成本,作者团队希望强学生模型可以:“了解弱监督者的意图,但不要模仿他们的错误”,从这个想法出发,论文团队使用条件熵最小化的思想构建了额外的正则化辅助损失,在学生模型发现标签有误时,增强其对自己能力的“自信心”:

这种方法极大的提升了学生模型在 NLP 数据集上的泛化能力:

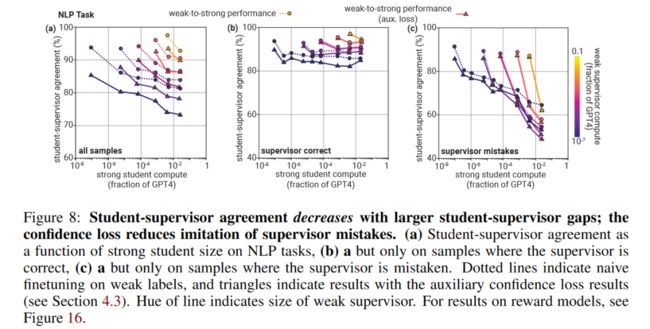
从某种程度上讲,对于弱对强泛化,这种辅助置信度损失的方法事实上是一种减轻过拟合的正则方法,在弱对强泛化的语境下,过拟合是指学生模型过分模仿弱监督者的错误,导致在真实标签下模型性能不佳,这种过拟合可以被学生模型在多大程度上模仿了弱监督者的错误而衡量,作者也对这一现象进行了细致的实验:

并且证实 Bootstrapping(也可以被理解为一种正则化)和辅助置信度损失都可以减轻过拟合:
除了“模仿”以外,作者还分析了弱对强泛化可能生效的原因是在于弱标签事实上唤醒了强模型本身具备的对一些问题所需的概念的理解,从这一想法出发,作者对比了微调、Zero-shot 和 5-shot prompting 下模型的性能,尽管 Zero-shot 和 5-shot 的性能始终低于微调,但是 5-shot 下就已经产生了满意解,这说明学生模型可以通过这种方式获得任务相关的知识,从而实现弱对强泛化:

结合这种思想,论文通过增强任务相关概念理解的方法使得 GPT-2 监督 GPT-4 的效果得到了提升:

当然尽管这篇论文为弱监督器自动监督强模型“开了一个好头”,但是对于超级对齐团队的真正目标,即控制超级 AI 来说,这篇工作也有许多不足。
譬如对于学生模型而言,其所做的工作可能仍然仅仅是超越弱监督者的错误,但是目前弱监督者的犯错类型可能与超级 AI 的错误类型完全不同,再如 GPT-4 仍然是预训练模型,因此这种方法生效可能是建立在预训练的结构下(NLP 任务的效果更好),而是否适用于未来的超级 AI,仍然存在问题,甚至人们会质疑大模型的这种忽略错误指令而“自信的有自己想法”的能力似乎更加恐怖。
当然,言谈大模型的自信似乎也为时尚早,小模型的错误一般表现在问题太难它没有办法完成之上,对这个任务的完成并没有挑战大模型的指令遵循能力,并且就如网友们讨论的那样,这种方法已经超越了人们一般奉行的“模型输出质量与输入质量成正比”的原则。

最后,欢迎大家更进一步阅读 OpenAI 的这篇论文,弱对强泛化的概念还是非常有趣的~
此外,OpenAI 还宣布将提供 1000 万美元的资助用于超级 AI 的对齐研究,感兴趣的大家也可以持续关注!