数据分析师狂喜!手把手教你用混元大模型做数据分析

导读
最近,腾讯发布了自主研发的大型语言模型:混元大模型。该大模型具备多轮对话能力、内容创作能力、逻辑推理能力、搜索增强和知识图谱等特点。除了对于人类自然语言的理解,混元大模型对于计算机编程语言同样可以进行分析和和生成。今天我就来用一个很常见的 Python 开发需求:对一组数据进行采集、整理、可视化分析,来演示下混元大模型在编程辅助开发上所能提供的帮助。
目录
1 获取数据
2 存储数据
3 读取数据
4 清洗数据
5 数据处理
6 数据可视化
7 总结
开发实例:学生成绩排名及分布
需求目标是从网页上抓取某班级学生的各科成绩汇总表,然后对分数进行排名,并通过可视化图表展示成绩的分布情况。在开发的过程中,我会使用腾讯混元大模型作为辅助。
先问问混元,一般这种程序要如何来写?

混元给出的建议:
获取网页数据
数据清洗与处理
数据分析与排名
数据可视化
结果展示
跟我的想法不谋而合,显然这种常见需求难不倒它。那我们就开始实际操作吧。
01
获取数据
为了保证测试环境的稳定,我自己提前准备好了一份测试数据,地址为:https://python666.cn/static/score.html
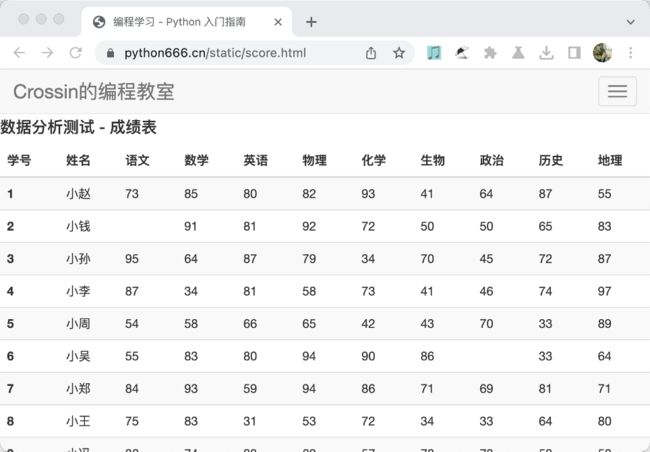
首先需要通过代码获取其中的表格数据。
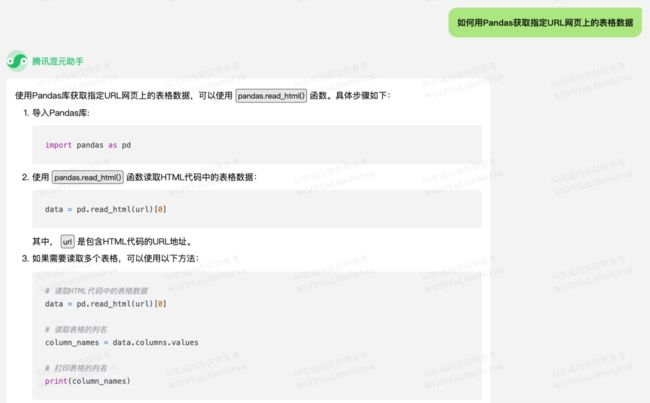
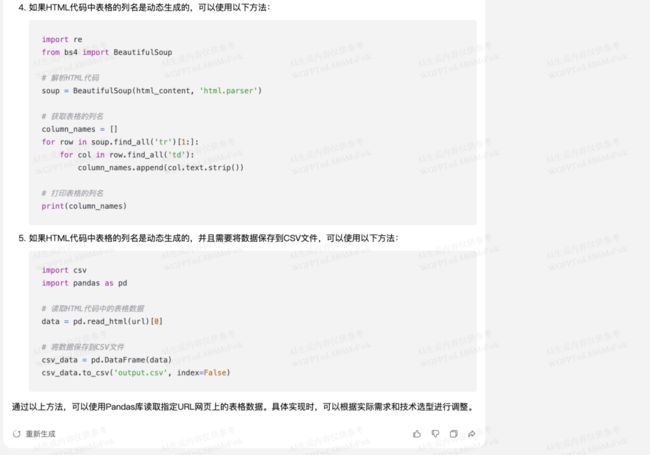
测试网页上只有一个表格,所以只需要回答中的前两个步骤就可以成功获取了。把目标 URL 代入混元给出的代码中:
运行效果如下:

02
存储数据
在上一个回答中,混元已经给我们提供了将数据保存为 csv 文件的方法。不过我想要 Excel 文件,所以让它再给我改一下。
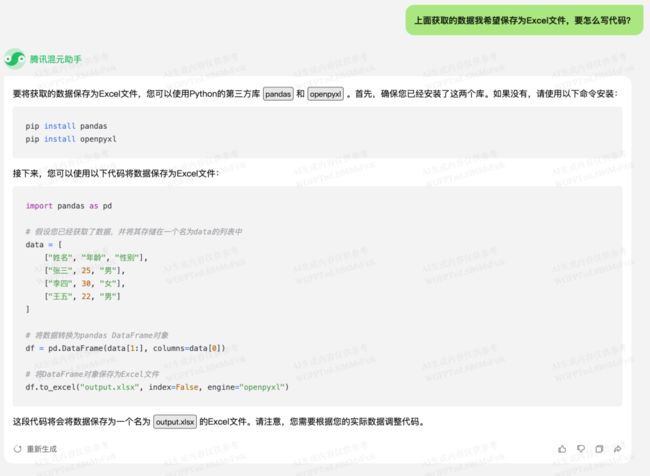
混元给出的方案是使用 pandas 的 .to_excel 方法,把它加入到我们前面的代码中:
执行后得到的 Excel 文件如下:
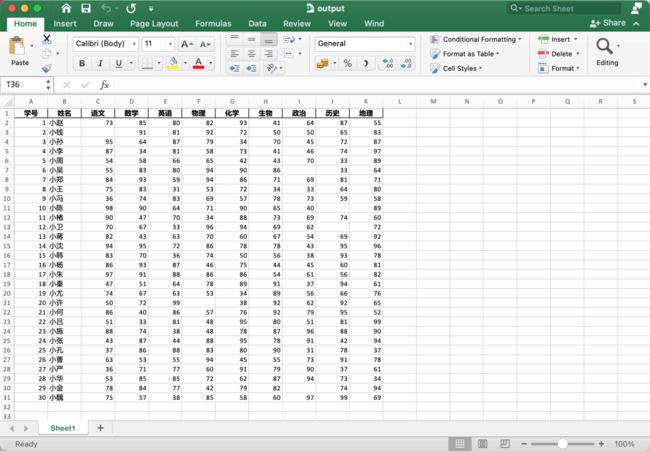
03
读取数据
保存完数据之后,再进行处理的话需要从文件中读取出数据。之所以没有在抓取数据后直接处理,是因为把数据保存到本地更方便后续反复操作,这更符合通常数据分析的操作流程。

读取 Excel 数据的代码很简单,在混元给出的代码上改一下文件名就可以用了:
运行效果如下:
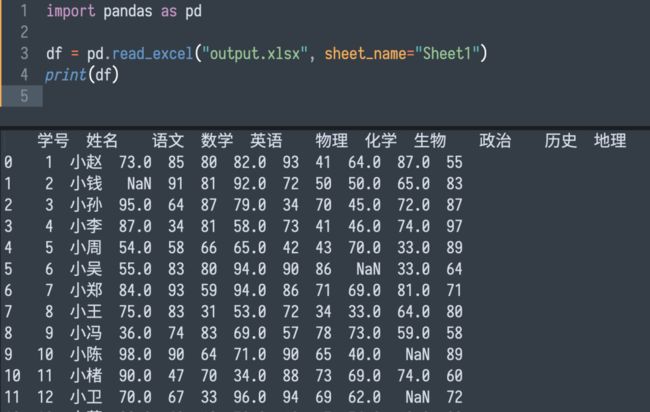
04
清洗数据
成绩表中有一些缺失的分数。对于这些成绩我希望将其替换成0分,以便于后续的计算。

将 .fillna(0) 方法添加进上一步的代码中:
顺利实现需求:
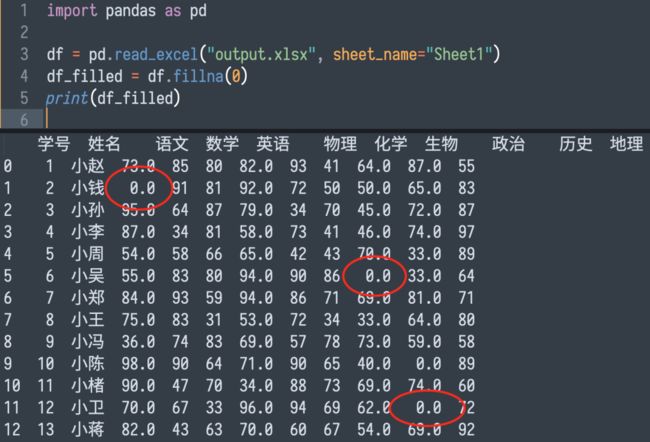
05
数据处理
数据的前期准备都已妥当,下面可以开始做些进一步的处理和分析了。
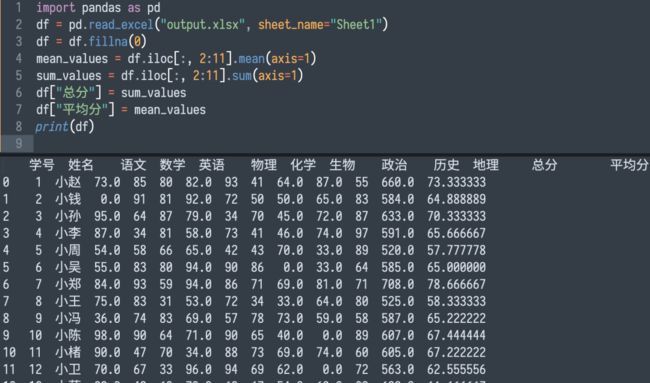
比如来计算一下每个学生的各科成绩总分和平均分。

混元给出了计算总分和平均分的方法,但有点小问题,计算取的列不对。于是我再提醒它一下:
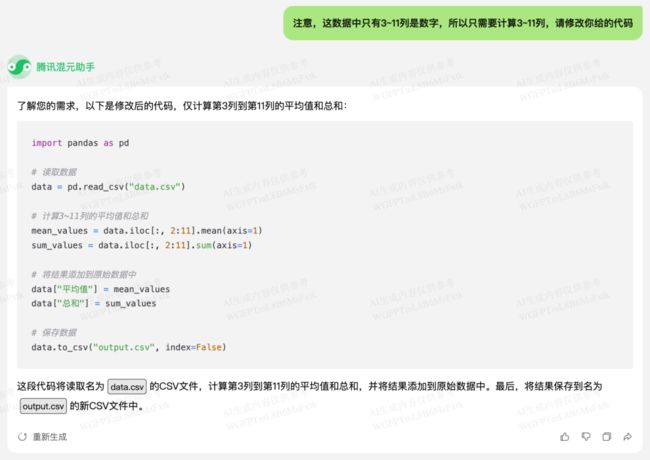
根据修改后的回答,更新我们的代码:
运行效果如下:
06
数据可视化
最直观展示数据整体情况的方法就是通过可视化图表。

混元给出了 matplotlib 和 seaborn 两种方案,整合进之前的代码,呈现出如下效果:
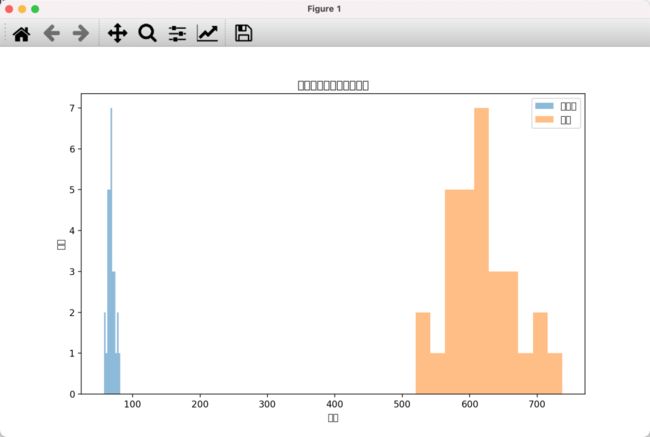
大致意思是对的,细节上还有点小问题:
图上的中文图例都显示成了□;
seaborn 没有区分平均分和总分两种数据,全部放在一起画分布图;
matplotlib 虽然做了区分,但也是画在一张图上,导致比例有点失调。
我来让它在 matplotlib 代码的基础上进一步修正,seaborn 的我们暂时就不用了。首先是中文显示的问题:


混元给出的解决方案是通过 plt.rcParams['font.sans-serif'] 设置中文字体。不过它给的 'Microsoft YaHei' 字体我电脑上没有,替换成我系统里有的 'Songti SC',确实可以解决显示问题:

然后再把这两张分布图分开绘制:


混元给出的方案是根据 matplotlib 的 subplots 方法设置子图表布局,然后在两个子图表上分别绘制。
整合进代码,效果如下:

成功绘制出了总分和平均分两张分布图。
最终的完整代码如下:
import pandas as pd
import matplotlib.pyplot as plt
# 读取Excel中书数据
df = pd.read_excel("output.xlsx", sheet_name="Sheet1")
# 对空值进行填充
df = df.fillna(0)
# 计算总分和平均分
mean_values = df.iloc[:, 2:11].mean(axis=1)
sum_values = df.iloc[:, 2:11].sum(axis=1)
df["总分"] = sum_values
df["平均分"] = mean_values
# print(df)
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['Songti SC']
plt.rcParams['axes.unicode_minus'] = False
# 创建一个2x1的子图表布局
fig, axes = plt.subplots(nrows=2, ncols=1, figsize=(6, 8))
# 绘制总分直方图
axes[0].hist(df['总分'], bins=20, color='blue', edgecolor='black', alpha=0.7)
axes[0].set_title('总分')
axes[0].set_xlabel('分数')
axes[0].set_ylabel('人数')
# 绘制平均分直方图
axes[1].hist(df['平均分'], bins=20, color='red', edgecolor='black', alpha=0.7)
axes[1].set_title('平均分')
axes[1].set_xlabel('分数')
axes[1].set_ylabel('人数')
# 显示图表
plt.tight_layout()
plt.show()07
总结
以上就是我们借助混元大模型,辅助开发一个数据分析案例的全过程演示。
从结果上来看,混元的确可以给我们在开发程序时提供帮助,提高开发效率。尤其对于数据分析这种开发需求来说,会用到很多第三方模块中的函数,在过去需要频繁查阅文档和搜索网络来了解具体的用法和参数设置,现在借助于大模型,可以很方便地得到示例代码,稍加调整就可以应用在代码中,大大节省了时间。
当然在此过程也会发现,由于程序设计会牵涉到业务需求的细节和具体的数据格式,大模型并不是每次都能直接给出完美的代码。这种情况下,需要使用者针对问题进一步提问,或对给出的代码进行验证和调整。
但总的来说,作为一个「开发助手」的角色,混元大模型已经可以给到开发者实实在在的效率提升。并且,大模型还在不断地进化迭代,期待后续有更令人惊艳的表现。
-End-
原创作者|Crossin的编程教室

你还能想到“混元大模型”能在那些地方上帮到你?欢迎评论分享。我们将选取1则最有趣的评论,送出腾讯云开发者社区定制鼠标垫1个(见下图)。12月14日中午12点开奖。

欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)



