基于Scrapy框架爬虫和数据挖掘的亚马逊网页信息分析
摘 要
为免去人工下载的烦琐,满足大规模下载数据的需求,基于 Python 设计了网页信息数据爬取程序,并对其进行实例分析。通过获取 Weh 数据资源,收集大量数据进行分析挖掘,并研究其所需的原始统计数据。为了减少重复烦琐的前期工作,提高开发效率,进一步搭建 Scrapy 工程,并采用决策树算法规避网站反爬虫,基于 Python 编写爬虫程序下载数据,存入数据库中完成网页信息数据爬取设计。爬取某购物网站的信息数据,并对数据进行筒单统计分析得到可视化示例,所设计的方法获取的某购物网站信息清晰明了,为网更信息教据爬取设计提供了参考。
本文的主要工作分为如下几个部分:
(1)亚马逊网页信息分析录像系统的分析与设计:通过对系统的业务需求分析以及功能需求分析确定了系统的功能架构组成,并对系统进行了安全性设计。
(2) 亚马逊网页信息分析录像系统的实现的方法:主要是让亚马逊网页信息分析录像系统功能满足实现过程中用户的各种需求,让这种系统能够真正的应用到实际业务中,实际上这种系统功能的实现是在对系统进行需求分析的基础上进行的。
关键词:亚马逊网页信息分析录像分析;Python;MYSQL数据库
3.1 系统功能分析
本系统是亚马逊网页信息分析录像系统,系统中用户进行浏览中可以以游客的身份访问,只有对数据进行查看时才需要进入登录系统,在后台操作时管理员必须要登入才能进入。
用户网页端
1、系统首页
2、个人中心
3、鞋子信息管理
4、用户管理
5、系统管理
3.2 可行性分析
3.2.1经济可行性
由于电脑网站已经有了一个大概的轮廓,同时该网站使用的技术以及语言也已经研发好,所以,该网站的创作成本十分的低,没有什么太大的要求。同时,它的使用范围很广泛,研发的时间也不会很长,而且对各大带来了十分便捷且善于管理的体验,因此,该网站的发展空间很大,应用范围也很广,各大都能使用该亚马逊网页信息分析录像,这样来看,该网站能给我们带来的利润也极其丰厚,因此,在经济方面,该网站是十分可行的。
3.2.2技术可行性
该系统主要是基于电脑网站进行开发的,而从目前的情况来看,电脑网站的技术已经相当的成熟,随着电脑的发展以及应用的广泛,人们看到了电脑网站的发展前景,因此,各种各样的网站也在电脑里产生,作为一个不需要下载便能使用的系统,用户也很乐于去使用,因此,基于电脑网站的项目越来越多,各种平台也很乐于在电脑中开发网站,电脑网站的技术也随着越来越成熟,因此在该系统在技术可行性这方面同样是属于可行的。
3.2.3操作可行性
软件运行的困难程度直接影响到使用者的感受和人数,这是一个需要考虑的问题。而随着手机的普及,电脑网站的系统也被越来越多的人使用,电脑网站的功能都大同小异,因此,人们可以不需要指导,就能去操作一个新的电脑网站,操作难度对人民群众来说不值一提,人们对此十分的熟练,操作也能很快的上手,因此,在对该网站的操作可行性来看,也是可行的。
3.2.4法律可行性
在法律方面,网站的每一方面我都进行了十分严谨的思考,并不会去触碰到对应的法律,而且由于网站的开发门槛并不是很高,也不需要太多的资金和十分复杂的技术要求,而且由于我的考虑,在该网站的功能和其他的方面,都不会有任何的触犯法律的情况,因此,该网站在法律可行性方面也是没有任何问题的。
3.3 需求分析
该网站是为了辅助对亚马逊网页信息分析录像的管理所研发,同时也是为了帮助用户进行亚马逊网页信息分析录像或者管理员对亚马逊网页信息分析录像等信息进行管理,因此,该网站必须要做到,亚马逊网页信息分析录像或用户可以浏览亚马逊网页信息分析录像等信息,同时,亚马逊网页信息分析录像可以进行亚马逊网页信息分析录像以及个人信息的修改,而该网站必须还有一个管理员的角色去操作管理员的功能,例如查看用户的亚马逊网页信息分析录像情况等。
该亚马逊网页信息分析录像在主要功能方面应该达到如下要求:
3.3.1可扩展性
该网站的设计是在目前所需要的功能为目标的基础上进行设计研发的,为了适应未来实际的需求的变化,给未来的功能提供更便捷的扩展和维护,我们必须去考虑到网站的扩展问题,在现有的基础上去增加功能时,网站原本的框架和功能点不会被太大的影响。
3.3.2稳定性
亚马逊网页信息分析录像的使用度十分的广泛,因此,该网站的运行必须要稳定,可靠的同时,也要高效,因此,在按照功能进行划分时,要使得他们不会有强烈的依赖,这样才能保持网站的稳定性,提高用户的使用舒适度。
3.3.3易用性
该亚马逊网页信息分析录像是为了系统管理所开发,因此必须开发一个易操作且高效的网站,避免有些用户未使用过电脑网站而不会操作,同时在易操作和的基础上,我们还应该做到界面的美观,这样才能让用户有更好的体验感。
3.3.4流畅性
一个好的网站,它的流畅性是必须要好的,要想有一个好的流畅性,需要考虑的地方无疑是需要更加全面的,不是简单的网站运行起来就可以,我们还应该更多的去考虑代码的运行效率即合理的算法设置等,通过这些操作来提高内存与网站同用户之间的一个响应速度,让使用者拥有一个全新且舒适的使用效果。对此,我们可以删除不需要的一些属性,提高布局复用,同时通过线程等方法去优化该网站的启动速度。
3.3.5安全性
该亚马逊网页信息分析录像由于可以应用于所有的浏览器,因此,这个应用网站有很多关于用户和管理员的信息,其中应用网站必须建立安全机制和权限设置,以确保操作用户身份的合法性,并防止未经授权的操作。它可以保证用户连接的真实性,提高用户连接的真实性,同时也保护了用户的个人信息,让用户个人信息的安全得到了具体的保障。
3.3.6网站维护分析
近几年来,随着网站的崛起,越来越多的企业开始对网站进行了研发,随着网站的日益增多,网站的维护也成为了一个无法逃避的问题,因此,本块对网站的维护进行了简单的介绍。网站维护包括以下几个方面的工作:
- 在网站的维护过程中,常常会遇到问题,使得网站需要做出相应改动,这些问题基本是没有办法去避免的,所以务必在每次维护的同时进行最大限度的改进,否则一旦问题堆积后,完后对网站的改动会比较大,增加了维难度和维护工作量。例如:常见的网站会遇到不符合要求的错误数据,那么网站就会出现错误,从而导致整个网站的中断。网站长时间被用户使用,用户会对其网站日渐了解,相应的会反馈一些我们未发现的漏洞,或者随着社会发展随着时间,环境,大势变化,用户会要求台添加相应需求项目,到了这个阶段,一些软件就要进行维修了。
(2)进行实时更新和维护的数据库:当因为一些操作和需求的改变,这个时候我们就需要对现在的这个数据库进行一个与各种操作的改变同时发生的一个转变,并需要对库进行一个随时的保养和维护。
(3)代码的保养与维护:随着社会发展随着时间,环境,大势变化,网站长时间被用户使用,相应的会反馈一些我们未发现的漏洞,然后需要改进代码,在原有的基础上改进代码,或者重新编写代码。一般来说,运行新代码是代码维护的难点,所以网站需要专业人员来负责代码维护。
这里将网站的功能整合在一张功能结构图中。

图4.1 系统功能结构图
4.2.1 用户的功能设计
该系统主要功能如下。
用户主要功能如图4-2所示
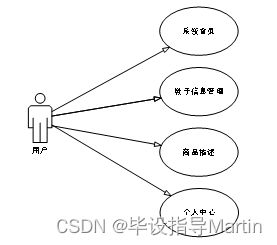
图4.2 用户功能图
4.2.2 管理员的功能设计
该系统主要功能如下。
管理员主要功能如图4-2所示

图4.2 管理员功能图
4.4 用户端设计
4.4.1 首页功能
亚马逊网页信息分析录像系统首页界面功能包括:可以查看首页信息等。该亚马逊网页信息分析录像系统的首页界面如图4-6所示:
图4-6首页功能
核心代码:
import scrapy
class AmazonSpider(scrapy.Spider):
name = 'amazon'
allowed_domains = ['amazon.com']
start_urls = ['https://www.amazon.com/']
def parse(self, response):
# 进入首页后获取所有的搜索分类链接
categories = response.xpath('//div[@id="navbar"]//a[@class="nav-a"]')
for category in categories:
category_link = category.xpath('./@href').extract_first()
# 进入每个分类页面
yield scrapy.Request(url=category_link, callback=self.parse_category)
4.4.2个人中心功能
亚马逊网页信息分析录像系统的个人中心界面功能包括:可以查看个人中心等。该亚马逊网页信息分析录像系统的个人中心界面如图4-7所示:

图4-7个人中心功能
4.4.3鞋子信息管理功能
亚马逊网页信息分析录像系统的鞋子信息管理界面功能包括:可以查看鞋子信息管理等。该亚马逊网页信息分析录像系统的鞋子信息管理界面如图4-9所示:

图4-9鞋子信息管理功能
注:展示部分文档内容和系统截图,需要完整的视频、代码、文章和安装调试环境请私信up主。
目录
摘 要
ABSTRACT
1 概述
1.1 研究背景及意义
1.1.1 研究背景
1.1.2 研究意义
1.2 国内外研究现状
1.3研究方法
1.4本章小结
2 开发平台及工具的选择
2.1网站的开发环境
2.2Python语言简介
2.3网站所使用的数据库
2.4网站所使用的技术
2.5本章小结
3 系统分析
3.1 系统功能分析
3.2 可行性分析
3.2.1经济可行性
3.2.2技术可行性
3.2.3操作可行性
3.2.4法律可行性
3.3 需求分析
3.3.1可扩展性
3.3.2稳定性
3.3.3易用性
3.3.4流畅性
3.3.5安全性
3.3.6网站维护分析
3.4 业务流程分析
3.5 数据流程分析
3.5.1 第一层数据流程图
3.5.2 第二层数据流程图
4 系统分析
4.1网站设计原则
4.2 系统功能设计
4.2.1 用户的功能设计
4.2.2 管理员的功能设计
4.3 数据库设计
4.3.1 概念结构设计
4.3.2 逻辑结构设计
4.4 用户端设计
4.4.1 首页功能
4.4.2个人中心功能
4.4.3鞋子信息管理功能
4.45管理员端设计
4.5.1 后台登录
4.5.2系统首页功能
4.5.3个人中心功能
4.5.4鞋子信息管理功能
4.5.5用户管理功能
4.5.6系统管理功能
4.6本章小结
5 系统测试
5.1 系统测试
5.2 测试结论
5.3本章小结
6 总结
致 谢
毕业设计小结
参考文献