5、目标检测评估指标
目标检测评估指标
- 1、精确度(Precision)、召回率(recoll)、准确率 (Accuracy)
- 2、AP与mAP
- 3、IOU
- 4、置信度(confidence)
- 5、NMS
- 6、边框
- 7、感受视野
1、精确度(Precision)、召回率(recoll)、准确率 (Accuracy)
假设为正确的P,假设为错误的为N;
其中判断对的为T,判断错的为F;

准确率:检测出来,并且检测对的
召回率:检测漏的
FN:没有检测到的
TP:正确检测出
准确率 (Accuracy)
A = (TP + TN)/(P+N) = (TP + TN)/(TP + FN + FP + TN);
反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负。
精确度(Precision)精确率又称为查准率
P = TP/(TP+FP);
分对的样本数除以所有的样本数 ,即:准确(分类)率 = 正确预测的正反例数 / 总数。
准确率一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
反映了被分类器判定的正例中真正的正例样本的比重。精确度衡量的是一个分类器预测出的真正例的概率。
召回率(recall)召回率又称查全率。
R = TP/(TP+FN) = 1 - FN/T;(FN为漏检个数,FN越小,Recall越大)
反映了被正确判定的正例占总的正例的比重。衡量的是一个分类器能把所有的正类都找出来的能力。
2、AP与mAP
AP与mAP:同时评估精度(准确率)和召回率

Precision-recall 曲线:如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。
AP就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是多个类别AP的平均值。这个mean的意思是对每个类的AP再求平均,得到的就是mAP的值,mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
AP(Average Precision)
查准率和查全率是一对矛盾的度量,一般而言,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。AP:平均正确率就是得出每个类的检测好坏的结果
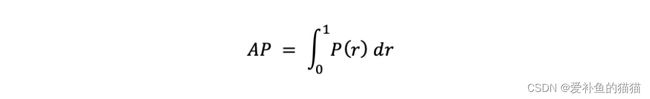
mAP:平均类别AP,mean Average Precision, 即各类别AP的平均值,计算出所有类别的AP后除以类别总数,就是mAP
AP: PR曲线下的面积,综合考量了 recall 和 precision 的影响,反映了模型对某个类别识别的好坏。
mAP: mean Average Precision, 即各类别AP的平均值,衡量的是在所有类别上的平均好坏程度。
3、IOU
iou:交集/并集,评估重合度,衡量目标检测任务中,预测结果的位置信息的准确程度。
边界框回归的三大几何因素:重叠面积、中心点距离、纵横比
IOU Loss:考虑了重叠面积,归一化坐标尺度;
GIOU Loss:考虑了重叠面积,基于IOU解决边界框不相交时loss等于0的问题;
DIOU Loss:考虑了重叠面积和中心点距离,基于IOU解决GIOU收敛慢的问题;
CIOU Loss:考虑了重叠面积、中心点距离、纵横比,基于DIOU提升回归精确度;
EIOU Loss:考虑了重叠面积,中心点距离、长宽边长真实差,基于CIOU解决了纵横比的模糊定义,并添加Focal Loss解决BBox回归中的样本不平衡问题。

4、置信度(confidence)
置信度(confidence):有物体的概率(前景概率)
分类器返回某个目标的类别置信度,即该目标属于A的概率,属于B的概率,即分类器最后softmax得到的结果。
置信度用来判断边界框内的物体是正样本还是负样本,大于置信度阈值的判定为正样本,小于置信度阈值的判定为负样本即背景。
置信度和IOU一起用来计算精确率(查确率,所有判断的目标中判断正确的比例,分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例)TP/TP+FP和召回率(查全率,所有目标中被检测到的目标比例,分类器认为是正类并且确实是正类的部分占所有确实是正类的比例)TP/TP+FN。精确率就是判断为正样本中实际为正样本的概率,召回率就是所有真实样本中被找到为正样本的概率。当通过IOU判断是正样本的情况属于P当通过confidence阈值判断的正样本属于T,所以如果IOU判断是正样本且confidence也判断是正样本时属于TP,这时剩下的实际的GT但置信度却小于confidence阈值的被认为是FN。
5、NMS
非极大值抑制用在最后阶段,即所有边界框都已经回归调整过后,对图片每一类使用NMS防止一个目标出现多个边界框。
1、非极大值抑制需要设置一个阈值
2、使用时间是最后调整完预测框位置后
3、多少个类就使用多少次非极大值抑制
3、每一类使用非极大值抑制后找到所有这类的边界框
6、边框
边界框,bounding box,用于标识物体的位置,常用格式有左上右下坐标,即xyxy;中心宽高,即xywh。
真实框,Ground truth box, 是人工标注的位置,存放在标注文件中
预测框,Prediction box, 是由目标检测模型计算输出的框(锚框的长宽比微调)
锚框,Anchor box,根据数据集的对象位置类聚出来,用于预测框计算做参考;基于这个参考,算法生成的预测框仅需要在这个锚框的基础上进行“精修或微调fine-tuning”即可,这样算法可以收敛的更快,检测效果更好。
设置
在训练的时候,需要anchor的大小和长宽比与待检测的物体尺度基本一致,才可能让anchor与物体的IoU大于阈值,成为正样本,否则,可能anchor为正样本的数目特别少,就会导致漏检很多。anchor只有跟你要检测的物体的大小和长宽比更贴近,才能让模型的效果更好。
7、感受视野
一个感受视野带有一个卷积核,我们将感受视野中的权重w矩阵称为卷积核将感受视野对输入的扫描间隔称为步长(stride); 当步长比较大时(stride>1),为了扫描到边缘的一些特征,感受视野可能会“出界”,这时需要对边界扩充(pad),边界扩充可以设为0 或其他值。
感受视野(receptive field):CNN中,某一输出层feature map中一个元素点(这里我们还是称之为像素点)对应的输入层区域的大小,被称作感受视野(receptive field)。例如,feature map2的一个像素点对应feature map1的一个5*5像素区域,其坐标取决于卷积核滤波的坐标位置。
增大感受野:增加层数、增大strides,增加fsize即卷积滤波器的大小都可以增加感受野的大小。
增加pooling层,但是会降低准确性(pooling过程中造成了信息损失)
增大卷积核的kernel size,但是会增加参数(卷积层的参数计算参考[2])
增加卷积层的个数,但是会面临梯度消失的问题(梯度消失参考[3])

一些名词:convx(convince)卷积层 FC全连接层 cell(单元格)strike(步长)