Unet复现,包含不同的上采样和下采样方式
注意
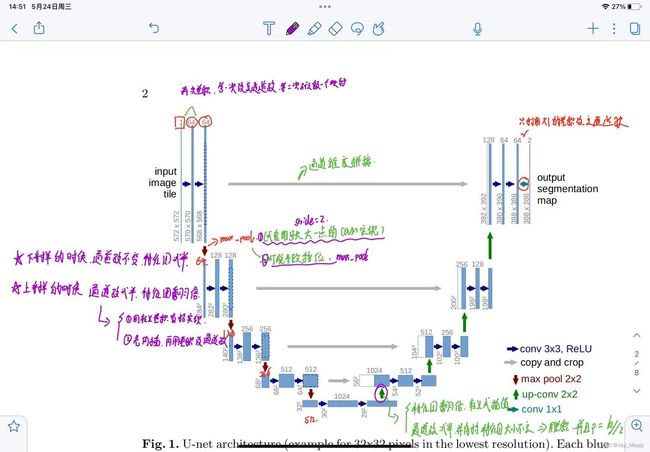
1. 下采样
下采样的时候,通道数不变,只有特征图减半了。可以通过maxpool实现,也可以是使用步长为2的卷积实现。
2. 上采样
上采样的时候,通道数减半,特征图翻倍。如果使用插值方法,那么先进行插值计算,然后利用卷积实现通道数减半,如果使用转置卷积的话,可以一步实现。
3. 基本模块
每次的卷积计算包括俩部分,第一次卷积将通道数改变,第二次卷积通道数不变。
4. unet改进
一个unet的改进,只是将卷积层的改变,通过替换不同的模块,如resnet的,等等,就可以实现模块的改进。
# coding:utf8
import torch
from torch import nn
from torch.nn import init
# 基本模块
class Conv_block(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_channels),
nn.SiLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_channels),
nn.SiLU(inplace=True),
)
def forward(self, x):
return self.conv(x)
# 下采样
class Down_conv(nn.Module):
def __init__(self, channels):
super().__init__()
# 原论文只是做了一个maxpool,并没有在后边加上卷积,此处加入卷积的目的就是为了更好的融合特征
self.down = nn.Sequential(
nn.MaxPool2d(2),
# 原文只有maxpool,我这里加入了卷积,为了能更好的融合maxpool的特征
nn.Conv2d(channels, channels, kernel_size=1)
)
# 方式二:
self.down1 = nn.Sequential(
nn.Conv2d(channels, channels, kernel_size=3, stride=2, padding=1, bias=True),
nn.BatchNorm2d(channels),
nn.SiLU(inplace=True),
)
def forward(self, x):
return self.down1(x)
# 上采样,上采样的时候,先将特征图的大小翻倍,翻倍之后还需要还需要
class Up_conv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
# 方式一:利用各种插值的方式
self.up = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_channels),
nn.SiLU(inplace=True),
)
# 方式二,转置卷积
# print(in_channels, out_channels)
self.up1 = nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size=3,
stride=2,
padding=1,
output_padding=1),
nn.SiLU(inplace=True)
)
def forward(self, x):
return self.up1(x)
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.conv1 = Conv_block(3, 64)
self.down1 = Down_conv(64)
self.conv2 = Conv_block(64, 128)
self.down2 = Down_conv(128)
self.conv3 = Conv_block(128, 256)
self.down3 = Down_conv(256)
self.conv4 = Conv_block(256, 512)
self.down4 = Down_conv(512)
self.conv5 = Conv_block(512, 1024)
self.up1 = Up_conv(1024, 512)
self.conv6 = Conv_block(1024, 512)
self.up2 = Up_conv(512, 256)
self.conv7 = Conv_block(512, 256)
self.up3 = Up_conv(256, 128)
self.conv8 = Conv_block(256, 128)
self.up4 = Up_conv(128, 64)
self.conv9 = Conv_block(128, 64)
self.end = nn.Conv2d(64, 3, kernel_size=3, padding=1, stride=1)
self.act = nn.Softmax(dim=1)
def forward(self, x):
conv1 = self.conv1(x)
conv2 = self.conv2(self.down1(conv1))
conv3 = self.conv3(self.down2(conv2))
conv4 = self.conv4(self.down3(conv3))
conv5 = self.conv5(self.down4(conv4))
up1 = self.conv6(torch.cat([conv4, self.up1(conv5)], dim=1))
# print(up1.shape)
print(conv3.shape, self.up2(up1).shape)
up2 = self.conv7(torch.cat([conv3, self.up2(up1)], dim=1))
up3 = self.conv8(torch.cat([conv2, self.up3(up2)], dim=1))
up4 = self.conv9(torch.cat([conv1, self.up4(up3)], dim=1))
return self.act(self.end(up4))
def init_weights(m):
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
init.xavier_uniform_(m.weight)
init.constant_(m.bias, 0.1)
# kaiming初始化
# init.kaiming_uniform_(m.weight)
# init.kaiming_normal_(m.bias)
if __name__ == '__main__':
xx = torch.randn((1, 3, 640, 640))
model = UNet()
model.apply(init_weights)
print(model(xx).shape)