深度学习---从入门到放弃(七)CNN进阶,迁移学习
深度学习—从入门到放弃(七)CNN进阶,迁移学习
引入
图像是高维的。即image_length* image_width*image_channels是一个很大的数字,而上一教程里所提到的CNN的权值共享便是一种解决图像和其他领域高维问题的方法。

从上图中可以看出现代卷积神经网络主要被用于各类图像识别和捕捉,而这些应用也归功于我们之后要讲到的Large-scale CNNs以及迁移学习了。
在CNN网络结构的演化上,出现过许多优秀的CNN网络,本文的目的就是带大家了解现代卷积神经网络的发展历程,本文主要关注以下四种网络:LeNet,AlexNet,VGG-Net,ResNets。
1.有关卷积神经网络的回顾

卷积可以被简单的理解为在过滤器(filter)的基础上对于我们图像的卷积运算,即通过一个滑动的filter,计算filter与滑动窗口内像素矩阵的点积,从而生成一个带有某一种空间特征的输出项,而在这之中的权值共享可以大大减少模型参数的个数,从而降低计算负担。
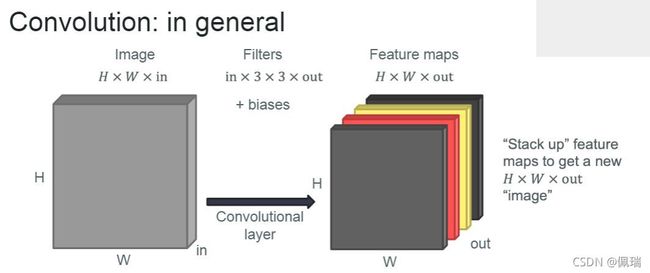
上图是模拟一个大小为 H ∗ W H*W H∗W且有in个channel的图像的卷积过程,可以发现通过卷积生成了out个filter并且输出大小也发生了改变(a new H ∗ W ∗ o u t H*W*out H∗W∗out “image”)
2.CNN 经典网络结构
2.1 AlexNet
AlexNet 可以说标志着当前深度学习时代的开始。它融合了当今成功 DL 的许多定义特征:深度网络、GPU 驱动的并行化和编码特定任务先验的构建块。
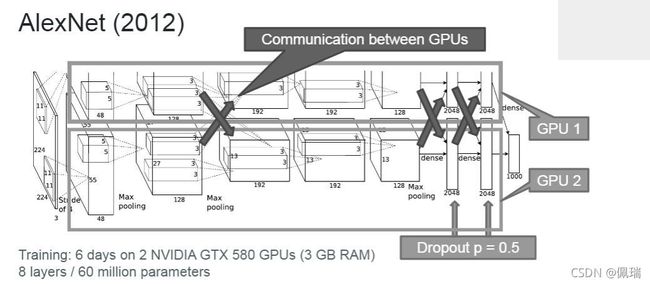
AlexNet加入了 (1)非线性激活函数:ReLU;利用ReLU进行训练时训练速度明显优于tanh(2)防止过拟合的方法:随机Dropout,Data augmentation。同时,使用多个GPU,LRN归一化层。
2.2 VGG
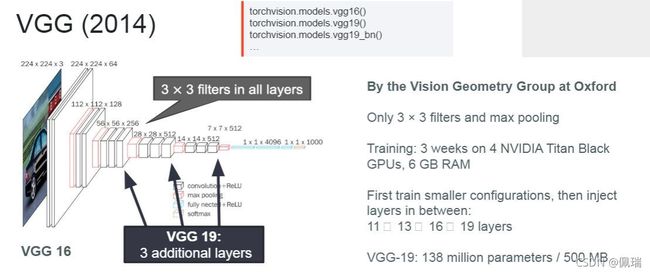
VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。同时,VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3。
2.3 残差网络 (ResNets)
ResNet

ResNet提出了一种减轻网络训练负担的残差学习框架,这种网络比以前使用过的网络本质上层次更深。
ResNet 有两个特别有趣的特性。首先,它使用跳过连接来避免梯度消失问题。其次,ResNet 中的每个块(层的集合)都可以被视为学习残差函数。
在数学上,神经网络可以被认为是将输入(如狗的图像)映射到输出(如标签“狗”)的一系列操作。在数学上,从输入到输出的映射称为函数。神经网络是表达该功能的灵活方式。
如果你要从网络学习的函数中减去将图像映射到类标签的真实函数,则会留下残差或“残差函数”。ResNets 尝试学习原始函数,然后是残差函数,然后是残差的残差,依此类推,使用它们的残差块并将它们添加到前面层的输出中。
ResNeXt
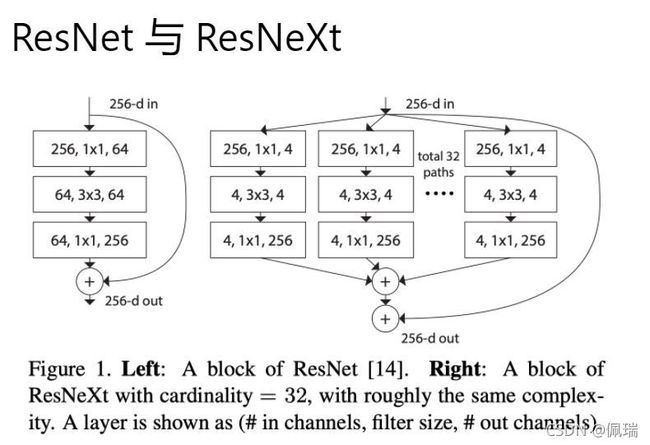
ResNeXt通过添加路径的方式可以做到进一步节省参数。
2.4 MobileNet
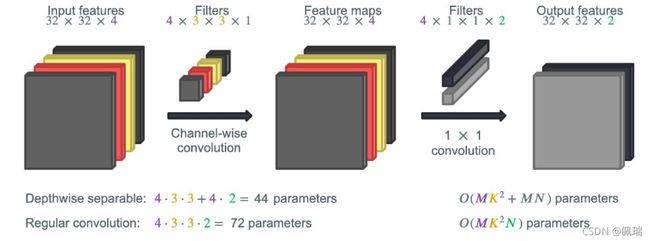
另一种降低大型模型计算成本的方法是使用深度可分离卷积。深度可分离卷积是使MobileNets高效的关键组件。它可以进一步降低计算复杂度,减少参数。
- 它的核心思想是将一个完整的卷积运算分解为两步进行,分别为Depthwise Convolution(逐深度卷积)与Pointwise Convolution(逐点1*1卷积)。
3.迁移学习
在实践中训练大图像模型的最常见方式是通过迁移学习。首先在像 ImageNet 这样的大型分类数据集上预训练网络,然后使用该网络的权重作为初始化(“微调”)。
3.1 加载数据
import zipfile, io
# original link: https://github.com/ben-heil/cis_522_data.git
url = 'https://osf.io/u4njm/download'
fname = 'small_pokemon_dataset'
if not os.path.exists(fname+'zip'):
print("Data is being downloaded...")
r = requests.get(url, stream=True)
z = zipfile.ZipFile(io.BytesIO(r.content))
z.extractall()
print("The download has been completed.")
else:
print("Data has already been downloaded.")

在这里我们引入一个具有9个宝可梦类别的图像数据集。
3.2 微调 ResNet
在计算机视觉中,采用在大型数据集(通常是 ImageNet)上训练的大型模型,替换分类层并对整个网络进行微调以执行不同的任务是很常见的。
在这里,我们将使用预训练的 ResNet 模型对 Pokemon 的类型进行分类。
resnet = torchvision.models.resnet18(pretrained=True)
num_ftrs = resnet.fc.in_features
# 将全连接层中类别标签个数改为9
resnet.fc = nn.Linear(num_ftrs, num_classes)
resnet.to(DEVICE)
#对于网络中是所有权值进行微调
optimizer = torch.optim.Adam(resnet.parameters(), lr=1e-4)#优化器为Adam
loss_fn = nn.CrossEntropyLoss()#交叉熵损失为目标函数
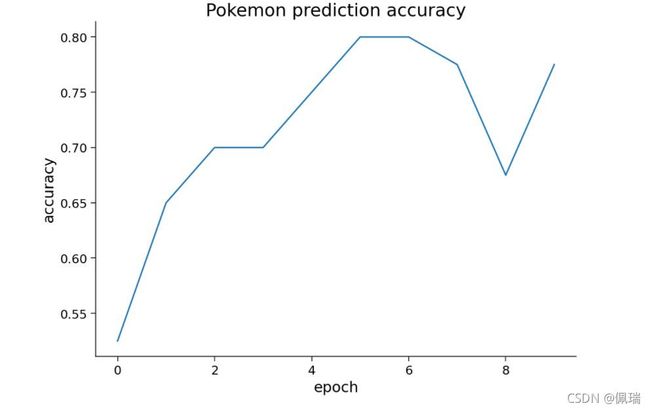
下面的示例代码则为进行迁移训练后的模型效果评估
pretrained_accs = []
for epoch in range(10):
# Train loop
for batch in pokemon_train_loader:
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
#梯度下降
optimizer.zero_grad()
output = resnet(images)
loss = loss_fn(output, labels)
loss.backward()
optimizer.step()
#训练效果评估
with torch.no_grad():
loss_sum = 0
total_correct = 0
total = len(pokemon_test_set)
for batch in pokemon_test_loader:
images, labels = batch
images = images.to(DEVICE)
labels = labels.to(DEVICE)
output = resnet(images)
loss = loss_fn(output, labels)
loss_sum += loss.item()
predictions = torch.argmax(output, dim=1)
num_correct = torch.sum(predictions == labels)
total_correct += num_correct
# Plot accuracy
pretrained_accs.append(total_correct / total)
plt.plot(pretrained_accs)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title('Pokemon prediction accuracy')
IPython.display.clear_output(wait=True)
IPython.display.display(plt.gcf())
plt.close()

3.3 仅训练分类层
利用迁移学习的另一种可能方法是采用预先训练的模型并替换最后一层,即分类层(有时也称为“linear readout”)。我们没有像以前那样对整个模型进行微调,而是只训练分类层。
resnet = torchvision.models.resnet18(pretrained=True)
for param in resnet.parameters():
param.requires_grad = False#锁定了网络中其他权值的梯度下降
num_ftrs = resnet.fc.in_features
# 将全连接层中类别标签个数改为9
resnet.fc = nn.Linear(num_ftrs, num_classes)
resnet.to(DEVICE)
optimizer = torch.optim.Adam(resnet.fc.parameters(), lr=1e-2)#这里只对分类层权值进行梯度下降
loss_fn = nn.CrossEntropyLoss()#交叉熵损失为目标函数
3.4 从头开始训练 ResNet
我们还可以从头开始训练ResNet,即:随机初始化权重并专门在 Pokemon 数据集上训练整个网络。
resnet = torchvision.models.resnet18(pretrained=False)#在Pokemon数据集上训练整个网络
num_ftrs = resnet.fc.in_features
# 将全连接层中类别标签个数改为9
resnet.fc = nn.Linear(num_ftrs, num_classes)
resnet.to(DEVICE)
optimizer = torch.optim.Adam(resnet.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
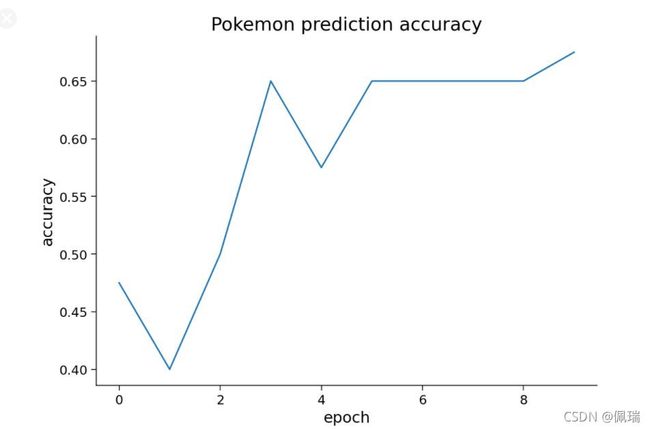
3.5 三种训练方式的比较

- Pretrained ResNet vs Trained from Scratch(从头开始训练)的 ResNet:
- 预训练数据和目标数据越接近,Pretrained ResNet训练效果越好
- 预训练数据越多,Pretrained ResNet预训练效果越好
- Pretrained ResNet可能会导致学习到无用的特征
- fine-tuning(微调整个网络)vs linear Readout(只训练分类层):
1.因为只训练了一层,所以linear Readout训练过程更快/计算成本更低
2.更多的权值调整可能意味着fine-tuning更好的训练效果
欢迎大家关注公众号奇趣多多一起交流!

深度学习—从入门到放弃(一)pytorch基础
深度学习—从入门到放弃(二)简单线性神经网络
深度学习—从入门到放弃(三)多层感知器MLP
深度学习—从入门到放弃(四)优化器
深度学习—从入门到放弃(五)正则化
深度学习—从入门到放弃(六)CNN入门