【论文笔记】MCANet: Medical Image Segmentation withMulti-Scale Cross-Axis Attention
医疗图像分割任务中,捕获多尺度信息、构建长期依赖对分割结果有非常大的影响。该论文提出了 Multi-scale Cross-axis Attention(MCA)模块,融合了多尺度特征,并使用Attention提取全局上下文信息。
论文地址:MCANet: Medical Image Segmentation with Multi-Scale Cross-Axis Attention
代码地址:https://github.com/haoshao-nku/medical_seg
一、MCA(Multi-scale Cross-axis Attention)
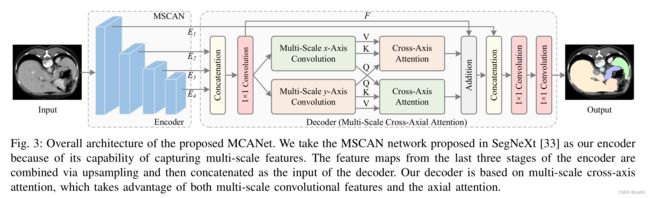
MCA的结构如下,将E2/3/4通过concat连接起来(concat前先插值到同样分辨率),经过1x1的卷积后(压缩通道数来降低计算量),得到了包含多尺度信息的特征图F,然后在X和Y方向使用不同大小的卷积核进行卷积运算(比如1x11的卷积是x方向,11x1的是y方向,这里可以对着代码看,容易理解),将Q在X和Y方向交换后(这就是Cross-Axis),经过注意力模块后,将多个特征图相加,并融合E1,经过卷积后得到输出。该模块有以下特点:
1、注意力机制作用在多个不同尺度的特征图;
2、Multi-Scale x-Axis Convolution和Multi-Scale y-Axis Convolution分别关注不同轴的特征,在计算注意力时交叉计算,使得不同方向的特征都能被关注到。
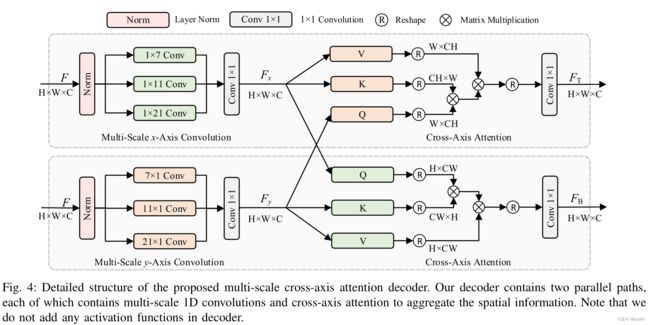
MCA细节如下图,输入特征图进入x和y方向的路径,经过不同大小的卷积后进行融合,然后跨轴(x和y轴的Q交换)计算Attention,最后得到输出特征图。
二、代码
MCA的代码如下所示,总体来说比较简单:
from audioop import bias
from pip import main
import torch
import torch.nn as nn
import torch.nn.functional as F
import numbers
from mmseg.registry import MODELS
from einops import rearrange
from ..utils import resize
from mmcv.cnn import ConvModule, DepthwiseSeparableConvModule
from mmseg.models.decode_heads.decode_head import BaseDecodeHead
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
def to_4d(x,h,w):
return rearrange(x, 'b (h w) c -> b c h w',h=h,w=w)
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
sigma = x.var(-1, keepdim=True, unbiased=False)
return x / torch.sqrt(sigma+1e-5) * self.weight
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma+1e-5) * self.weight + self.bias
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type =='BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
class Attention(nn.Module):
def __init__(self, dim, num_heads,LayerNorm_type,):
super(Attention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.project_out = nn.Conv2d(dim, dim, kernel_size=1)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(
dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(
dim, dim, (21, 1), padding=(10, 0), groups=dim)
def forward(self, x):
b,c,h,w = x.shape
x1 = self.norm1(x)
attn_00 = self.conv0_1(x1)
attn_01= self.conv0_2(x1)
attn_10 = self.conv1_1(x1)
attn_11 = self.conv1_2(x1)
attn_20 = self.conv2_1(x1)
attn_21 = self.conv2_2(x1)
out1 = attn_00+attn_10+attn_20
out2 = attn_01+attn_11+attn_21
out1 = self.project_out(out1)
out2 = self.project_out(out2)
k1 = rearrange(out1, 'b (head c) h w -> b head h (w c)', head=self.num_heads)
v1 = rearrange(out1, 'b (head c) h w -> b head h (w c)', head=self.num_heads)
k2 = rearrange(out2, 'b (head c) h w -> b head w (h c)', head=self.num_heads)
v2 = rearrange(out2, 'b (head c) h w -> b head w (h c)', head=self.num_heads)
q2 = rearrange(out1, 'b (head c) h w -> b head w (h c)', head=self.num_heads)
q1 = rearrange(out2, 'b (head c) h w -> b head h (w c)', head=self.num_heads)
q1 = torch.nn.functional.normalize(q1, dim=-1)
q2 = torch.nn.functional.normalize(q2, dim=-1)
k1 = torch.nn.functional.normalize(k1, dim=-1)
k2 = torch.nn.functional.normalize(k2, dim=-1)
attn1 = (q1 @ k1.transpose(-2, -1))
attn1 = attn1.softmax(dim=-1)
out3 = (attn1 @ v1) + q1
attn2 = (q2 @ k2.transpose(-2, -1))
attn2 = attn2.softmax(dim=-1)
out4 = (attn2 @ v2) + q2
out3 = rearrange(out3, 'b head h (w c) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out4 = rearrange(out4, 'b head w (h c) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = self.project_out(out3) + self.project_out(out4) + x
return out
@MODELS.register_module()
class MCAHead(BaseDecodeHead):
def __init__(self,in_channels,image_size,heads,c1_channels,
**kwargs):
super(MCAHead, self).__init__(in_channels,input_transform = 'multiple_select',**kwargs)
self.image_size = image_size
self.decoder_level = Attention(in_channels[1],heads,LayerNorm_type = 'WithBias')
self.align = ConvModule(
in_channels[3],
in_channels[0],
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
self.squeeze = ConvModule(
sum((in_channels[1],in_channels[2],in_channels[3])),
in_channels[1],
1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg)
self.sep_bottleneck = nn.Sequential(
DepthwiseSeparableConvModule(
in_channels[1] + in_channels[0],
in_channels[3],
3,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg),
DepthwiseSeparableConvModule(
in_channels[3],
in_channels[3],
3,
padding=1,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg))
def forward(self, inputs):
"""Forward function."""
inputs = self._transform_inputs(inputs)
inputs = [resize(
level,
size=self.image_size,
mode='bilinear',
align_corners=self.align_corners
) for level in inputs]
y1 = torch.cat([inputs[1],inputs[2],inputs[3]], dim=1)
x = self.squeeze(y1)
x = self.decoder_level(x)
x = torch.cat([x,inputs[0]], dim=1)
x = self.sep_bottleneck(x)
output = self.align(x)
output = self.cls_seg(output)
return output