初始Redis
redis.conf 配置文件详解
redis.conf 配置项说明如下:
1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
3. 指定Redis监听端口,默认端口为6379,为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
4. 绑定的主机地址
bind 127.0.0.1
5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
8. 设置数据库的数量,默认数据库为0,可以使用SELECT
databases 16
9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
11. 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
12. 指定本地数据库存放目录
dir ./
13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof
14. 当master服务设置了密码保护时,slav服务连接master的密码
masterauth
15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH
requirepass foobared
16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory
18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
19. 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
20. 指定更新日志条件,共有3个可选值: no:表示等操作系统进行数据缓存同步到磁盘(快) always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全) everysec:表示每秒同步一次(折中,默认值)
appendfsync everysec
21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
redis 的基本操作命令
del key : 该命令用于在ke'y存在时删除key (没有相应的key 返回0,删除成功返回1)
dump key: 查看序列化的值
exists key : 判断此key 是否存在(存在返回1,不存在返回0)
expire key: 为给定的key设置指定时间(以秒计时,-1代表永久,-2代表无效) | pexprie key 毫秒单位
ttl key: 以秒为单位返回key的剩余过期时间 | pttl key 以毫秒单位
persist key: 移除 key 的过期时间, key将持久保持
keys patterm: 查找所有符合给定模式(patterm)的key。 (* 代表所有 ?表示代表一个字符)
random key: 从当前数据库中随机返回一个key
select index: 切换到数据库1(select 1),redis数据库共16个(0至15)
rename key newkey: 修改key的名称
move key db: 将当前的key移动到指定的数据库db中
type key: 判断什么类型(string 字符串,hash 哈希,list 列表,set 集合,zset 有序集合)
常用: expire key 应用场景(1,限时优惠,数据缓存(对于一些定时更新的数据),手机验证码,限制网站访客频率)
key的命名规范(redis 的key 单个存入512M大小)
1.key不要太长,尽量在1024字节,避免多消耗内存,增加查找几率
2.key不要太短,key短可读性降低
3.统一的命名格式 建议(user:123:password)
数据类型简介
1.String
stirng 类型是 二进制安全的(二进制安全是,在传输数据时保证二进制信息安全,也就是不会被串改和破译等,如果攻击能即使检测出) ,可包含任何数据,如 jpg图片或序列化对象
setnx key value: 只有在key不存在时设置 key的值。setnx 命令在指定的key不存在时。为key设置值
注释:经常面试,涉及到分布式锁的问题
getrance key start end:用于获取存储在指定 key 中字符串的字符串。字符串的截取范围由 start 和 end 两个偏移量决定(宝包括 start 和 end 在内)
getset: 用于指定key的值,并返回key的旧值,当key不存在时返回null (先取再赋)
strlen key: 查看字符串长度
重点命令:1),自增自减 incr key name: incr 命令是将key中储存的数字增加1。如果key不存在,那么key的值会被初始化为0,然后再执行incr 的操作。 decr key name -1。 还有一种自增方式可以自定义自增的数量 incrby key name 10,同样 decrby keyname 10,每执行一次减10个。
2.Hash
redis中的hash特别像javabean,可以看成key value的map容器,暂用空间小。
hset key field value: 赋值语法
hmset key field value [filed,value] .... : 同时将多个 filed-value 设置到哈希表 key 中。例如hmset username:1 id 1 name zhangsan age 22
hget key field: 取值
hmget key field[field] : hmget username:1 id name。 还可以查询出所有字段与值,hmgetall username:1
hkeys key: 获取所有字段
hlen key: 获取字段数量
hdel key field1[field2]: 删除一个或多个hash表字段
hsetnx key field value: 只有在字段field 不存在时候,设置哈希表字段值
hincrby key field increment:为哈希表 key 中的 指定字段 的整数值 加上增量 increment
hincrbyfloat key field increment: 为哈希表 key 中的 指定字段 的浮点数值 加上增量 increment
hexisis key field: 查看哈希表 中指定的字段是否存在(存在返回1,不存在返回0)
应用场景:通常用来存储一个用户信息的对象
3.List
是一个 双向链表类型,通过push,pop操作链表的头部和尾部,例添加和删除元素。使得list可以用作堆栈,也可以用作队列。
用作队列:设置队列长度,新添用户后会去掉踢出最后的用户。
lpush key: 在key 对应 list 的头部添加字符串元素
rpop key: 从list的尾部删除元素,并返回删除的元素
llen key: 返回key 对应list的长度,key 不存在返回0,如果key对应类型不是list,返回错误。
lrange key start end: 返回指定区间的元素,下标从0开始
lpop key : 从list 的头部删除元素,并返回删除的元素
itrim key start end:截取list,保留指定区间的元素
4.Set (没有重复元素)
是一个 集合类型(常用场景,QQ推荐“可能认识的好友”),并集,差集,交集计算,set 是 String类型的无序集合,最多元素可有2的32次方-1(42亿)。
sadd key member: 添加一个String元素到key对应的 set 集合中,成功返回1,如果元素存在返回0,key对应的set不存在返回錯誤
srem key member [member]: 从key 对应的key 中移除给定元素,成功返回1
smove p1 p2 member: 从p1 中移除 member 元素,并追加到p2对应的set中
scard key: 返回set元素的个数
sismember key member: 判断 member 是否存在在set 中
sinter key1 key2 .... keyN:返回所有给定key的交集(两个key都有key)
sunion key1 key2 ....keyN: 返回所有给定key的并集(两个key的所有值)
sdiff key1 key2 .....keyN: 返回所有给定key的差集(两个key 只取左边的)
smembers key : 返回key对应的所有元素,结果是无序的
5.SortSet
sortset 排序集合类型,使用场合 获得热门帖子信息
zadd key score member: 添加元素到集合,元素在集合中存在则更新对应的score
zrem key member: 删除指定元素,1表示成功,0表示元素不存在。
zincrby key incr member: 按照incr幅度增加对应member的score值,返回score值
zrank key member: 返回指定元素在集合中的排名(下标),集合元素是按着score的值从小到大排序
zrevrank key member: 同上,不同与集合元素是按着score的值 从大到小排序
zrange key start end: 类似lrange从集合中指定区域,返回有序结果
zrevrange key start end: 同上,返回结果为score逆序
zcard key : 返回集合中元素个数
zscore key element:返回给定元素对应的score
zremrangebyrank key min max: 删除集合中排名在给定区间的元素 (0,1是两位, 0,0下标是一位元素)

redis持久化: 会把本身数据以文件的形式保存到硬盘一份,在服务器重启之后会自动将硬盘里的数据回复到 内存(redis)里去。
1)snap shotting 快照持久化
默认自动开启,一次性把redis中跑的全部数据保存到存储硬盘中,如果太大例如 10~20G,则不适合操作(dump.db)
手动发起异步快照持久化 redis-cli [ -h 192.168.1.X -p 6379] bgsave
rdb:命令
save:同步命令,在执行之前其他所有命令得排队。新替换旧。
bgsave:异步命令,执行完成之后会立即返回OK,会在后台单独的线程去执行。会生成一个子进程,去完成createRDB,创建完成后会告诉主进程创建成功。一般不会阻塞redis。
不使用客户端,自动触发RDB文件生成:save [bgsave]配置详情见 redis.conf
触发RDB文件生成还有:
1.全量复制也能写入RDB文件,例如在主从复制的时候。
2.debug reload: debug级别的重启,不需要讲内存清空。这个时候任然触发RDB文件的生成
3.shutdown: 有个参数叫 shutdown save,也会触发RDB。
配置:daemonize yes 守护线程打开
src]# make install2)append only file (AOF持久化)
精细持久化,把用户执行每个 “写” 指令(添加,删除,修改)都备份到文件中,还原数据的时候就是执行具体的写指令
AOF的三种策略:
always: 每条都进入到硬盘
everysec: 每秒把缓冲区刷新fcync到硬盘
no:根据操作系统决定策略
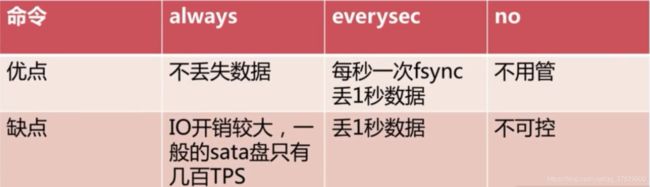
通常会使用everysec。
当 并发或者访问过大或随着时间的推移,文件会逐渐变大,这时如果使用AOF进行恢复的话,会非常的慢。AOF 提供了重写功能。

假如左边写入了三条命令,分别记录到AOF控件中。
AOF重写的两种方式:bgrewriteaof,类似与bgsave,fork出子进程,去完成aof重写的过程。
AOF重写配置,提供两个配置完成。

增长率:
aof_current_size(当前尺寸) - aof_base_size(上次重写或重启的尺寸 ) / aof_base_size(上次重写或重启的尺寸 )
> auto-aof-rewrite-percentage (得到增长率,如果增长率大于配置中的增长率,就可将其进行aof的重写)
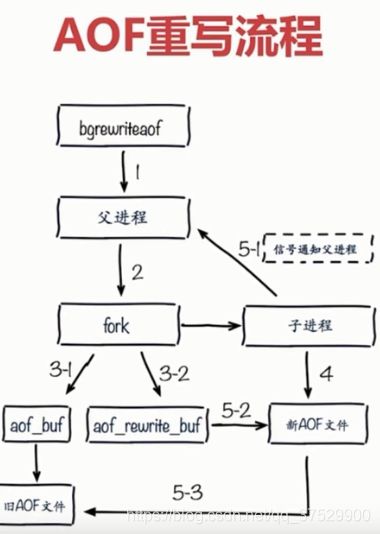
appendonly 支持动态设置。config get appendonly (config set appendonly yes)。 之后config rewrite 配置重写。
相关配置:appendonly yes (默认是no) appendfilename "appendonly-${port}.aof" appendfsync everysec (aof同步的三中策略之一)
查看aof文件:
*2 //下面的命令有两个参数(SELECT)
$6 //代表下面的字符,有6个字节(SELECT)
SELECT
$1 //代表一个字节,对应的0
0 //对应的是0号数据库
*3 //下面的命令,参数有三个
$3 //命令占3个字节
SET
$1 // 参数占一个字节
c //参数
$1 //代表一个字节,对应的d
d
dir /bigdiskpath 保存日志目录
no-appendfsync-on-rewrite yes : 在aof重写的时候,不做append操作 ,这里是yes不做append操作。
aof-load-truncated yes :aof 文件在不完成,有问题的时候,重启加载是否忽略。
fork:
info:latest_fork_usec,查询redis在持久化的运行时间
改善fork,1.fork和redis中实例内存大小是有关系的:maxmemory,2.Linux内存分配策略:vm.overcommit_menmory = 1(默认为0)
3.降低fork频率,例如放宽AOF重写自动触发机制,不必要的全量复制。
子进程开销和优化
1.CPU,RDB和AOF属于CPU密集操作。通常子进程的开销CPU会在90%以上。
优化:不要做CPU的绑定,不要把redis的进程绑定在一个CPU上。
2.内存开销:copy-on-write,父子进程会共享相同的物理内存件,但是在父进程写请求的时候,会创建一个副本,相当与在这个时候才会消耗一个内存。而在这个期间子进程会共享fork父进程的一个内存的快照。
优化:1.单机做部署的时候不允许做大量的重写。2.在主进程写入量比较小的时候做AOF重写或bgsave.。3.在Linux内核中做优化,在2.6.38的版本中增加了thp的特性,就是支持大的内存页分配。
3.硬盘的消耗。
AOF的追加阻塞

---------------------------------------------------------------------------特性---------------------------------------------------------------------------------------
慢查询
1.先进先出队列,其内部是redis队列实现的 2.这个队列是固定长度的,如果长度满了之后,最先进队列的就会被踢出去 3. 保存在内存当中,当redis重启之后,信息也会效时
配置: slowlog-log-slowe-than = 10000 请求超时设置单位毫秒,当请求在超时范围内就进入了队列中 。
slowlog list
slowlog-max-len =100
slowlog-log-slower-than: 1.满查询的预值,当大于多少进入慢查询单位是微秒 2.如果想将所有的命令都记录在慢查询则 slowlog-log-solower-than=0,通常不用。
方法: 1).默认值:config get slowlog-max-len = 128 config get slowlog-log-slower-than = 10000
命令:slowlog get[n] : 获取指定条数的慢查询 n 是个数。 slowlog len:获取慢查询的长度。 slowlog reset:清空慢查询队列。
运维经验:1.slowlog-max-len 不要设置过大,默认10ms,通常设置1ms.
2.slowlog-log-slower-than 队列长度设置不要过小,默认是128,通常可设置为1000左右
3.理解命令的生命周期。
4.定期做慢查询的持久化。
pipeline(流水线)
1).流水线,首先,命令时间 = 网络时间 + 命令时间,如果多此请求网络为了打到较少的 命令时间,流水线将一批命令进行打包,而在服务端进行一批计算,再按顺序将结果返回。
2).流水线pipeline,不应许执行在多个节点上。
发布订阅:
publish channel messgae : 发布到 对应的频道 写上对应的消息。返回订阅者数
subscirbe [channel] :对于订阅者,可订阅一个或多个例如:subscirbe baidu,返回订阅的结果
unsubscribe [channel]: 取消订阅
psubscirbe: 按照模式订阅 punsubscirbe [patten....]:退订指定模式 pubsub channels: 列出至少有一个订阅者的频道 pubsub numsub [channel....] 列出给定频道的订阅者数量
消息队列:是资源抢夺的,类似红包,只有部分收到。
Bitmap
1)可操作 bit 位,1.setbit key offset(偏移量) value 2.getbit key offset 3.bitcount key [start end],获取位图指定范围(start 到 end,单位字节,如果不指定就获取全部)为值为1的个数。 4.bitop op destkey key [key ...],做多个bitmap的and交集,or(并集),not(非),xor(亦或)操作并将结果保存在destkey中。5.bitops key targetBit [start end] 计算位图指定范围(start 到 end,单位为字节,如果不指定就获取全部)第一个偏移量指定的值等于targetBit的位置。
HyperLogLog
1)基于HyperLogLog算法:极小的空间完成独立数量统计(本质数据结构还是String)
2)使用方法:pfadd key element [element ...]: 向hyperloglog添加元素
3)pfcount key [key ...] : 计算hyperloglog的独立总数
4)pfmerge destkey sourcekey [sourcekey ...] : 合并多个hyperloglog
使用方法:

不足:错错误率在0.81%
GEO(redis3.2后,地理信息定位,可计算距离)类似场景如微信摇一摇
1).geo key longitude latitube member [longitude latitude member ....] //添加地理位置信息

2)geopos key member [member ...] 获取地理位置信息

3) geodist key member1 member2 [unit] 获取两个地理位置的距离 unit: mi(英里),ft(尺)

4) georadius 算出指定范围内的number |经纬度


基于 type geoKey = zset,所以删除可以使用 zrem key member
redis的复制原理与优化
1.主从复制的配置
1)slaveof命令
info replication,可查看当前reids属于什么状态,例如master,slave
例如,6380 作为 6379 的从节点,在6380下执行slaveof 127.0.0.1:6379。取消则slaveof no one,则不再是从节点,而之前的数据依然存在。
2)配置
slaveof ip port
slave-read-only yes //只做读的操作
全量复制与部分复制
redis-cli -p 6379 info server | grep run 查看run_id。重启后run_id会改变
偏移量:
数据写入量的一个字节,例如做一个set hello world ,就是一个字节,就可以记录写了多少数据。而另个节点会被同步,另个节点也会记录这个偏移量,当两个节点,偏移量达到一致的时候,数据就属于一个完全同步的过程。如果6379比6380大的话,就可能主从不一致。是部分复制的 重要 依据。

故障转移:分为两点1.slave 宕机 2. master 宕机
运维中常见的问题:
1.读写分离:读流量分摊到从节点。1)复制数据的延迟(可能有线程阻塞)2)读到过期的数据(redis删除过期数据,两种策略1.懒惰策略,在操作时去发现数据有无过期 )
2.主从配置不一致
3.避免全量复制:1)产生全量复制的条件,第一复制给slave,无法避免,可减少危害可用小主节点,地峰。第二,节点运行ID不匹配,可用故障转移处理 ,第三,复制积压缓冲区不足
4.规避复制风暴:假设master 上挂了很从节点,当master挂掉之后,重启,这时因为run_id 发生了变化所以所有的slave都会执行一次全量复制,生成RDB,再进行传输,消耗过大。
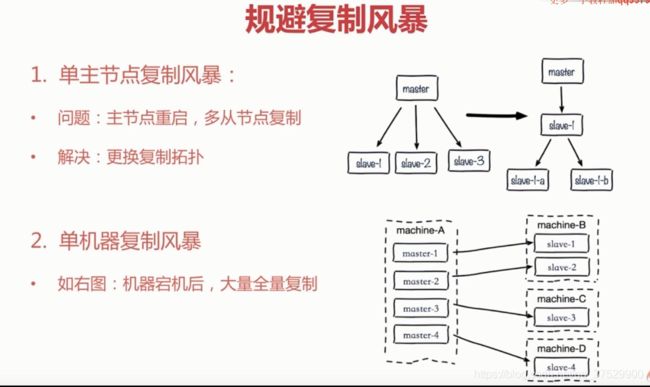
可,在slave里生成master。
Redis Sentinel
当master出现问题后,有手动故障转移,(可选一个新的slave,做为一个新的master)
安装和配置:1.配置开启主从节点 2.配置开启Sentinel检控主节点,主要是去监控主节点。

sentinel monitor mymaster 127.0.0.1 7000 2(分配多少sentinel,对master认为有问题发动下一步的故障转移)
sentinel down-after-miliseconds mymaster 30000 (设置 ping 多少毫秒后ping 不通就说明有问题)
sentinel parallel-syncs mymaster 1 (关于复制的配置,我们选择新的master后,其他的节点slave会对新的master进行复制。1代表每次复制1个)
sentinel failover-timeout mumaster 180000 (故障转移时间)
redis-cli -p 7000 info replication
cat sentinel.conf |grep -v "#" |grep -v "^$" //查看setinel.conf文件,追加 带# 的 和 ^$(空格吧),-v (注释掉吧 )