数据结构学习 12字母迷宫
dfs 回溯 剪枝
这个题和dfs有关,但是我之前没有接触过,我看了这一篇很好的文章,看完之后写的答案。
我觉得很好的总结:
dfs模板
int check(参数) { if(满足条件) return 1; return 0; } void dfs(int step) { 判断边界 { 相应操作 } 尝试每一种可能 { 满足check条件 标记 继续下一步dfs(step+1) 恢复初始状态(回溯的时候要用到) } }
尝试每一种可能,一般都是用for循环。
在一些情况下,for循环这一步可以写到外面去,然后再调用dfs,比如这题就可以。,比如我刚刚提到的文章的油田问题。
题目:

我的思路:
其实就是模仿我刚刚提到的文章。
我的dfs是:bool dfs(std::vector
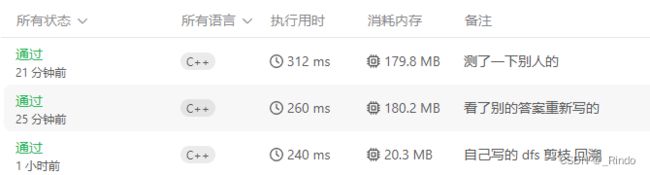
是拿上一步的pre_i和pre_j作为输入,然后我发现这样写没办法启动dfs,但是我当时脑子抽了,没找到直接输入i和j就能做出来的办法。所以只能第一步遍历所有格子的时候,把它写在dfs外面,总之有点愚蠢。但是,执行时间和内存都比我下一种写法要少很多,这是为啥?
 (我自己写的)
(我自己写的)
复杂度:

代码:
#include
#include
#include
//我写的 dfs 剪枝 回溯
class Solution {
public:
Solution(){}
bool wordPuzzle(std::vector>& grid, std::string target) {
n = target.size();
if (n == 0 || grid.empty() || grid[0].empty())return false;
rows = grid.size();//行
cols = grid[0].size();//列
int step = 1;
vis = std::vector(rows * cols);
res = std::vector(n);
for (int i = 0; i < rows; ++i)//因为我写的dfs需要接受前一个dfs的位置i,j,为了启动,只能把第一轮遍历写在外面了
{
for (int j = 0; j < cols; ++j)
{
if (grid[i][j] == target[step - 1])
{
res[step - 1] = grid[i][j];//访问
vis[i * cols + j] = 1;//标记
result = dfs(grid, target, step + 1, i, j);
if (result)return result;
vis[i * cols + j] = 0;//回溯
res[step - 1] = '\0';//回溯
}
}
}
return result;
}
private:
bool dfs(std::vector>& grid, std::string target, int step, int pre_i, int pre_j)
{
if (step == n + 1)return true;//中止条件 判断边界
for (int i = 0; i < rows; ++i)//尝试每一种可能
{
for (int j = 0; j < cols; ++j)
{
if (vis[i * cols + j] == 0 &&//走过的不要
grid[i][j] == target[step-1]&&//不相同的直接不要
((i * cols + j) == (pre_i * cols + pre_j - cols) ||//上
(i * cols + j) == (pre_i * cols + pre_j + cols) ||//下
(i == pre_i && j == pre_j - 1) ||//左
(i == pre_i && j == pre_j + 1)))//右
{
res[step-1] = grid[i][j];//访问
vis[i * cols + j] = 1;//标记
result = dfs(grid, target, step + 1, i, j);//下一个
if (result)return result;
vis[i * cols + j] = 0;//回溯
res[step - 1] = '\0';//回溯
}
}
}
return result;
}
int n = 0;
int rows = 0;
int cols = 0;
std::vector vis;
std::vector res;
bool result = false;
};
void Test_solution1()
{
Solution solution;
std::vector> grid{ { 'C','A','A'} ,{'A','A','A'},{'B','C','D'} };
std::cout<< solution.wordPuzzle(grid ,std::string("AAB"));
} 答案思路:
把循环写到dfs外面了。
dfs判断的是当前的点。所以dfs是:
dfs(std::vector
这里传进来的i和j是需要被判断的点,而不是我写的pre_i和pre_j
找方向用的是:
result = dfs(grid, target, step + 1, i - 1, j) ||
dfs(grid, target, step + 1, i + 1, j) ||
dfs(grid, target, step + 1, i, j - 1) ||
dfs(grid, target, step + 1, i, j + 1);
比我的好多了,呵呵。
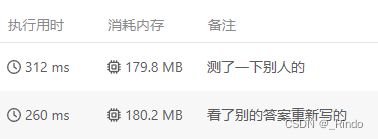
但是测试的时间和内存异常多。然后我又测试了答案提供的,还是很多时间和内存,很奇怪啊。
看了答案之后自己根据思路重新写了一遍代码:
#include
#include
#include
//看了答案之后模仿写的 dfs 剪枝 回溯
//这个要用很多内存 呃,为什么?
class Solution {
public:
Solution() {}
bool wordPuzzle(std::vector>& grid, std::string target) {
n = target.size();
if (n == 0 || grid.empty() || grid[0].empty())return false;
rows = grid.size();//行
cols = grid[0].size();//列
int step = 1;
vis = std::vector(rows * cols);
//res = std::vector(n);
for (int i = 0; i < rows; ++i)//循环写在外面了
{
for (int j = 0; j < cols; ++j)
{
result = dfs(grid, target, step, i, j);
if (result)return result;
}
}
return result;
}
private:
bool dfs(std::vector>& grid, std::string target, int step, int i, int j)
{
if (step == n + 1)return true;//中止条件
if (i >= 0 && i < rows && j >= 0 && j < cols &&//超过的不要
vis[i * cols + j] == 0 &&//走过的不要
grid[i][j] == target[step - 1])//不相同的直接不要
{
//res[step - 1] = grid[i][j];//访问
vis[i * cols + j] = 1;//标记
result = dfs(grid, target, step + 1, i - 1, j) ||
dfs(grid, target, step + 1, i + 1, j) ||
dfs(grid, target, step + 1, i, j - 1) ||
dfs(grid, target, step + 1, i, j + 1);
if (result)return result;
vis[i * cols + j] = 0;
//res[step - 1] = '\0';
}
return result;
}
int n = 0;
int rows = 0;
int cols = 0;
std::vector vis;
//std::vector res;
bool result = false;
};
void Test_solution2()
{
Solution solution;
std::vector> grid{ { 'C','A','A'} ,{'A','A','A'},{'B','C','D'} };
std::cout << solution.wordPuzzle(grid, std::string("AAB"));
} 测试结果: