【Java 集合】LinkedBlockingQueue
LinkedBlockingQueue, 顾名思义: 基于链表的阻塞队列, 位于 JUC (java.util.concurrent) 下, 是一个线程安全的集合, 其本身具备了
- 不支持 null 元素: 存入 null 元素会抛出异常
- 固定不限容量: 在不手动设置容量时, 最大可以支持 Integer.MAX_VALUE 个元素, 也就是理论上的无限个数
- 有序性: 内部采用链表作为底层数据结构,保持了元素的有序性。这意味着当你向队列中添加元素时,它们将按照添加的顺序排列,而消费者线程将按照相同的顺序取出这些元素
- LinkedBlockingQueue 会在队列满时, 阻塞添加数据的线程直至队列非满状态, 同样, 在队列空时, 阻塞获取数据的线程直至队列重新非空
- 支持锁公平性配置: 在初始化时可以指定是否使用公平锁, 默认为非公平锁。公平锁通常会降低吞吐量, 但是减少了可变性和避免了线程饥饿问题
1 实现的数据结构
内部的实现结构就是一个链表, 而且是所有链表中最简单的单向链表, 所以就不展开了。
2 源码分析
2.1 LinkedBlockingQueue 链表节点的定义
我们知道 LinkedBlockingQueue 的底层实现结构就是一个链表, 而链表绕不开的一个概念就是节点, 所以我们先来看一下 LinkedBlockingQueue 的节点定义。
public class LinkedBlockingQueue<E> {
// 链表节点类, 数据的主要存储地方
static class Node<E> {
// 节点的数据
E item;
// 下一个节点
Node<E> next;
Node(E x) {
item = x;
}
}
}
通过节点 Node 的定义中就一个数据域和一个指向下一个节点的指针, 明确 LinkedBlockingQueue 就是一个单向链表。
2.2 LinkedBlockingQueue 持有的属性
public class LinkedBlockingQueue<E> {
/** 队列的大小,默认为 Integer.MAX_VALUE */
private final int capacity;
/** 队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger();
/** 队列头结点 */
transient Node<E> head;
/** 队列尾节点 */
private transient Node<E> last;
/** 可重入锁, 用于从队列中获取元素时使用, 后面我们统一叫做读锁 */
private final ReentrantLock takeLock = new ReentrantLock();
/** 非空条件对象,当队列没有数据时, 用于挂起获取数据的线程 */
private final Condition notEmpty = takeLock.newCondition();
/** 可重入锁, 用于先队列添加元素时使用, 后面我们统一叫做写锁 */
private final ReentrantLock putLock = new ReentrantLock();
/** 非满条件对象,当队列数据已满时, 用于挂起添加数据的线程 */
private final Condition notFull = putLock.newCondition();
}
和 ArrayBlockingQueue 类似, 都是通过可重入锁控制并发, 通过 Condition 来实现线程的挂起和唤醒。
和 ArrayBlockingQueue 不同的时, 添加和删除数据, ArrayBlockingQueue 使用的是同一把锁, 而 LinkedBlockingQueue 将添加数据和删除数据分开, 使用了两把锁, 这样可以提高并发度。
2.3 LinkedBlockingQueue 构造函数
public class LinkedBlockingQueue<E> {
// 无参构造函数
public LinkedBlockingQueue() {
// 默认大小为 Integer.MAX_VALUE
this(Integer.MAX_VALUE);
}
// 指定容量的构造函数
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.capacity = capacity;
// 初始化头尾节点
last = head = new Node<E>(null);
}
// 指定集合的构造函数
public LinkedBlockingQueue(Collection<? extends E> c) {
// 同样默认为 Integer.MAX_VALUE 的容量
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
// 获取添加数据锁
putLock.lock();
try {
int n = 0;
for (E e : c) {
// 非空校验
if (e == null)
throw new NullPointerException();
// 达到容量了
if (n == capacity)
throw new IllegalStateException("Queue full");
// 将当前的数据封装为 Node 节点, 添加到队列中
// 先知道这个方法的作用, 后面新增数据的时候有分析
enqueue(new Node<E>(e));
// 添加个数 + 1
++n;
}
// 当前链表的个数设置为添加的个数
count.set(n);
} finally {
putLock.unlock();
}
}
}
从 LinkedBlockingQueue 的 3 个构造函数中可以看出, 都需要通过指定容量构造函数先构建出一个只有 1 个节点, 同时节点数据为空的链表, 如下:
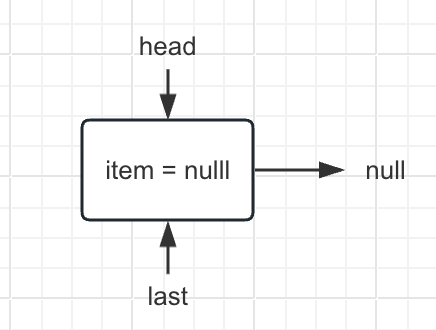
在构建为这个空链表后, 实际我们的 LinkedBlockingQueue 算是初始化完成了。
而指定集合的构造函数, 会在初始化完成, 加上写锁后, 将入参的集合元素添加到当前的队列中。
同 ArrayBlockingQueue 一样, 在构造函数中使用了 ReentrantLock 来加锁, 通过这个锁达到 Happens-Before 的监视器原则, 达到后面可见性。
2.4 LinkedBlockingQueue 支持的方法
2.4.1 数据入队方法
LinkedBlockingQueue 提供了多种入队操作的实现来满足不同情况下的需求,入队操作有如下几种:
- boolean add(E e)
- boolean offer(E e)
- boolean offer(E e, long timeout, TimeUnit unit)
- void put(E e)
add(E e)
public class LinkedBlockingQueue<E> {
public boolean add(E e) {
// 直接调用自身的 offer 方法, 添加成功就返回 true
// offer 方法后面分析
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
}
offer(E e)
顺着 add 方法, 看一下 offer 方法:
public class LinkedBlockingQueue<E> {
public boolean offer(E e) {
// 新增的数据为空, 直接抛异常
if (e == null)
throw new NullPointerException();
final AtomicInteger count = this.count;
// 达到了容量上限, 直接返回
if (count.get() == capacity)
return false;
int c = -1;
// 将当前的数据封装为 Node 节点
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
// 获取添加锁
putLock.lock();
try {
// 当前队列的容量还没达到上线
if (count.get() < capacity) {
// 将当前这个节点添加到队列的尾部
enqueue(node);
// 获取当前的数组容量
c = count.getAndIncrement();
// 当前的数组容量 + 1 后还是小于容量上限
if (c + 1 < capacity)
// 唤醒阻塞在非满条件上的线程
notFull.signal();
}
} finally {
putLock.unlock();
}
// 上面 c = count.getAndIncrement(), 会先将 count 当前的值赋给 c, 然后在 count 再 + 1
// 所以这里 c == 0, 表示当前链表新增了一个节点前,没有数据, 尝试唤醒阻塞在非空条件上的线程
if (c == 0)
signalNotEmpty();
return c >= 0;
}
private void enqueue(Node<E> node) {
// 简单的链表新增节点操作
// 把当前链表的尾结点的下一个节点设置为新增的节点
// 把当前的尾节点更新为新增的节点
last = last.next = node;
}
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
// 获取读锁
takeLock.lock();
try {
// 唤醒在非空条件上阻塞的线程 (唤醒前需要获取对应的锁, 所以上面先获取了读锁)
notEmpty.signal();
} finally {
// 释放读锁
takeLock.unlock();
}
}
}
offer 方法概括一下就是:
- 非空和队列容量判断
- 获取写锁成功时, 将当前的元素封装为节点放到链表的尾部
- 添加成功后, 队列的容量没有达到上限, 唤醒在非满条件上阻塞的线程, 然后释放锁
- 如果当前添加的元素是当前链表的第一个元素, 唤醒在非空条件上阻塞的线程
offer(E e, long timeout, TimeUnit unit)
offer(E e, long timeout, TimeUnit unit) 方法只是在 offer(E e) 的基础上增加了超时时间的概念。在队列上阻塞了多少时间后, 队列还是满的, 就返回。
public class LinkedBlockingQueue<E> {
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {
if (e == null)
throw new NullPointerException();
// 时间转为纳秒
long nanos = unit.toNanos(timeout);
int c = -1;
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// 获取可中断的写锁
putLock.lockInterruptibly();
try {
// while 循环的目的是防止在中断后没有到达传入的 timeout 时间, 可以继续重试
// 等待超时时间达到了 nanos,就直接返回 false
while (count.get() == capacity) {
if (nanos <= 0)
return false;
// 将当前线程阻塞在非空条件上
nanos = notFull.awaitNanos(nanos);
}
// 把当前的节点放到队列的尾部
enqueue(new Node<E>(e));
// 获取当前的数组容量
c = count.getAndIncrement();
// 当前的数组容量 + 1 后还是小于容量上限
if (c + 1 < capacity)
// 唤醒阻塞在非空条件上的线程
notFull.signal();
} finally {
putLock.unlock();
}
// 上面 c = count.getAndIncrement(), 会先将 count 当前的值赋给 c, 然后在 count 再 + 1
// 所以这里 c == 0, 表示当前链表新增了一个节点前,没有数据, 尝试唤醒阻塞在非空条件上的线程
if (c == 0)
signalNotEmpty();
return true;
}
}
可以看到主要的逻辑和 offer(E e) 方法一样, 只是在队列满时, 使用的是带超时时间的阻塞方法。
该方法会在等待时间到达后, 会自动唤醒, 同时线程时间到达后被唤醒, 队列还是满的, 就返回 false。
put(E e)
public class LinkedBlockingQueue<E> {
public void put(E e) throws InterruptedException {
// 非空校验
if (e == null)
throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
// 获取添加需要的 putLock, 也就是写锁
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
// 获取锁中断
putLock.lockInterruptibly();
try {
// 判断队列是否已满,如果已满阻塞等待
// 如果每次唤醒都是满的话,就会一直阻塞
while (count.get() == capacity) {
notFull.await();
}
// 把node放入队列中
enqueue(node);
// 链表中的元素个数 + 1
c = count.getAndIncrement();
// 再次判断队列是否有可用空间,如果有唤醒下一个线程进行添加操作
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
// 上面 c = count.getAndIncrement(), 会先将 count 当前的值赋给 c, 然后在 count 再 + 1
// 所以这里 c == 0, 表示当前链表新增了一个节点前,没有数据, 尝试唤醒阻塞在非空条件上的线程
if (c == 0)
signalNotEmpty();
}
}
put 方法和 offer 方法类似, 前者在当队列已满时, 进入阻塞, 后者在队列已满时, 则是返回。
2.3.2 数据出队方法
同入队的方法一样, 出队也有多种实现, LinkedBlockingQueue 提供了好几种出队的方法, 大体如下:
- E poll();
- E poll(long timeout, TimeUnit unit);
- E take()
poll()
public class LinkedBlockingQueue<E> {
public E poll() {
final AtomicInteger count = this.count;
// 当前的数组为节点个数为空, 直接返回 null
if (count.get() == 0)
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
// 获取读锁
takeLock.lock();
try {
// 当前的数组容量大于 0, 有数据可以获取
if (count.get() > 0) {
// 获取头节点的数据
x = dequeue();
// 当前数组的节点个数 - 1
c = count.getAndDecrement();
// 当前数组的节点个数还是大于 1
if (c > 1)
// 唤醒阻塞在非空条件上的线程
notEmpty.signal();
}
} finally {
// 释放读锁
takeLock.unlock();
}
// 当前的容量等于上限了
if (c == capacity)
// 唤醒阻塞在非满条件上阻塞的线程
signalNotFull();
return x;
}
private E dequeue() {
// 简单的链表删除操作
Node<E> h = head;
// 获取当前头节点的下一个节点
Node<E> first = h.next;
// 将头节点下一个节点设置为自身, 这里的操作后面分析
h.next = h;
// 将当前的头节点设置为头节点的下一个节点
head = first;
// 获取旧的头结点的数据
E x = first.item;
// 设置旧的节点的数据为 null
first.item = null;
// 返回旧的节点的数据
return x;
}
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
// 获取写锁
putLock.lock();
try {
// 唤醒阻塞在非满条件上的线程
notFull.signal();
} finally {
putLock.unlock();
}
}
}
poll() 逻辑整理如下
- 队列为空, 直接返回 null
- 获取读锁, 队列不为空, 获取头节点的数据
- 获取后队列还是有数据, 唤醒阻塞在非空条件上的线程, 释放锁
- 如果当前的容量等于上限了, 再次唤醒阻塞在非满条件上阻塞的线程
public class LinkedBlockingQueue<E> {
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E x = null;
int c = -1;
long nanos = unit.toNanos(timeout);
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
// 当前的数组容量为 0, 队列为空, 将当前线程阻塞在非空条件上
while (count.get() == 0) {
if (nanos <= 0)
return null;
// 带超时时间的等待
nanos = notEmpty.awaitNanos(nanos);
}
// 队列不为空, 获取头节点的数据
x = dequeue();
// 当前数组的节点个数 - 1
c = count.getAndDecrement();
// 当前数组的节点个数还是大于 1
if (c > 1)
// 唤醒阻塞在非空条件上的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 当前的容量等于上限了
if (c == capacity)
// 唤醒阻塞在非满条件上阻塞的线程
signalNotFull();
return x;
}
}
整个 poll(long timeout, TimeUnit unit) 方法和 poll() 方法类似, 只是在队列为空时, 使用的是带超时时间的阻塞方法。
take()
public class LinkedBlockingQueue<E> {
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
// 获取可中断的锁
takeLock.lockInterruptibly();
try {
// 队列为空,阻塞等待
while (count.get() == 0) {
notEmpty.await();
}
// 获取头节点的数据
x = dequeue();
// 获取当前的数组容量
c = count.getAndDecrement();
// 队列中还有元素,唤醒下一个消费线程进行消费
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
// 移除元素之前队列是满的,唤醒生产线程进行添加元素
if (c == capacity)
signalNotFull();
return x;
}
}
take() 方法和 poll() 方法类似, 当队列为空时, 进入阻塞, 一直等待, 直到被唤醒, 唤醒后调用 dequeue() 方法获取队列中的元素, 而 poll() 方法则是在队列为空时, 直接返回 null。
2.3.3 获取元素方法
获取数据的就一个方法, 同时只支持获取头节点的数据。
public class LinkedBlockingQueue<E> {
public E peek() {
// 当前数组上的节点为 0, 直接返回
if (count.get() == 0)
return null;
final ReentrantLock takeLock = this.takeLock;
// 获取读锁
takeLock.lock();
try {
// 获取头节点的下一个节点 (有数据的头节点)
Node<E> first = head.next;
// 头节点的下一个节点为 null
if (first == null)
// 返回 null
return null;
else
// 返回头节点的数据
return first.item;
} finally {
takeLock.unlock();
}
}
}
很简单, 就是获取头节点的下一个节点的数据, 有数据返回数据, 没有数据, 就返回 null。
2.3.4 删除元素方法
public class LinkedBlockingQueue<E> {
public boolean remove(Object o) {
if (o == null) return false;
// 两个 lock 全部上锁
fullyLock();
try {
// 从 head 开始遍历元素,直到最后一个元素
for (Node<E> trail = head, p = trail.next; p != null; trail = p, p = p.next) {
// 如果找到相等的元素,调用 unlink 方法删除元素
if (o.equals(p.item)) {
unlink(p, trail);
return true;
}
}
return false;
} finally {
// 两个lock全部解锁
fullyUnlock();
}
}
void fullyLock() {
putLock.lock();
takeLock.lock();
}
void unlink(Node<E> p, Node<E> pred) {
// 简单的链表节点删除操作
// 将这个节点的数据项设置为 null
// 同样是删除元素, 什么这里这里删除的元素 p 不需要想 dequeue 方法一样, 将他的 next 设置为 自身?
p.item = null;
// 将这个节点的上一个节点的 next 设置为删除节点 p 的下一个节点
pred.next = p.next;
// 删除的节点为尾结点
if (last == p)
// 设置尾节点为删除节点的上一个节点
last = pred;
// 当前数组的容量减 1 后还是等于数组上限
if (count.getAndDecrement() == capacity)
// 唤醒 notFull 上等待队列的线程
notFull.signal();
}
void fullyUnlock() {
takeLock.unlock();
putLock.unlock();
}
}
3 问题
在上面的源码的分析中, 留了 2 个比较特殊的地方
- dequeue 方法中里的移除的元素 h, 为什么需要将 h.next 指向自身, 而不是 null
- 同样删除元素的 unlink 方法却不需要将 p.next = null 或者 p.next = p 这样的操作
这里都可以在 LinkedBlockingQueue 内部的迭代器中找到答案
private class Itr implements Iterator<E> {
// 遍历的链表头节点
private Node<E> current;
// 遍历的链表头节点的数据
private E currentElement;
// 构造函数
Itr() {
// 加双锁
fullyLock();
try {
current = head.next;
if (current != null)
currentElement = current.item;
} finally {
fullyUnlock();
}
}
// 获取入参节点的下一个节点
private Node<E> nextNode(Node<E> p) {
for (;;) {
// 解决了问题 1
Node<E> s = p.next;
if (s == p)
return head.next;
if (s == null || s.item != null)
return s;
p = s;
}
}
}
问题 1 在 nextNode 方法中也能找到
- 为了正确遍历,nextNode 中通过 s == p 进行判断,当下一个元素是自己本身时,返回 head 的下一个节点。
而第二个问题主要在迭代器的遍历中, 迭代器的遍历分为两步
- 加双锁, 然后链表的头节点放到一个临时变量中
- 遍历临时变量的元素。在遍历的过程是无锁的, 也就是其他线程可以执行 remove 方法, 如果其他线程通过 unlink 修改了 p 的 next,可能在导致迭代异常
4 总结
它是 BlockingQueue 接口的一种实现,通过链表的形式存储元素,在不明确指定容量时, 可以存储 Integer.MAX_VALUE 个元素, 也就是理论上的无上限, 但是建议在使用中还是指定容量, 避免 OOM 等问题。
同时借助 2 个 ReentrantLock 达到读写互不影响, 提高并发性能。同时 ReentrantLock 的 Condition 提供了阻塞操作,使得在队列已满或为空时,线程能够安全地等待。
5 参考
【细谈Java并发】谈谈LinkedBlockingQueue