大数据---24.Hive的连接三种连接方式
一、CLI连接
进入到 bin 目录下,直接输入命令:
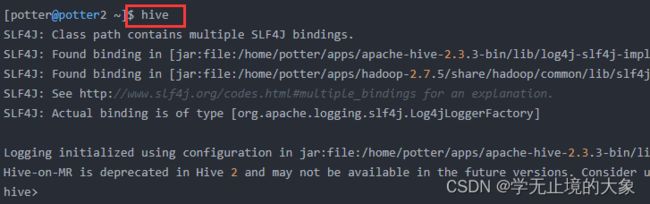
查看:
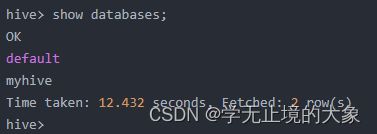
启动成功的话如上图所示,接下来便可以做 hive 相关操作
补充:
1、上面的 hive 命令相当于在启动的时候执行:hive --service cli
2、使用 hive --help,可以查看 hive 命令可以启动那些服务
3、通过 hive --service serviceName --help 可以查看某个具体命令的使用方式
二、HiveServer2/beeline
1、修改 hadoop 集群的 hdfs-site.xml 配置文件
2、修改 hadoop 集群的 core-site.xml 配置文件
在现在使用的最新的 hive-2.3.3 版本中:都需要对 hadoop 集群做如下改变,否则无法使用
第一:修改 hadoop 集群的 hdfs-site.xml 配置文件:加入一条配置信息,表示启用 webhdfs
dfs.webhdfs.enabled true 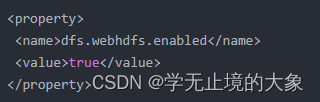 第二:修改 hadoop 集群的 core-site.xml 配置文件:加入两条配置信息:表示设置 hadoop的代理用户potter----替换成自己的用户名
hadoop.proxyuser.potter.hosts * hadoop.proxyuser.potter.groups * 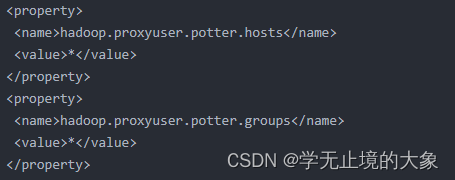配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户
hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
需要重启zookeeper,和,HDFS,YARN,集群。
以上操作做好了之后,请继续做如下两步:
第一步:先启动 hiveserver2 服务
启动方式,
(假如是在 hadoop02 上):
启动为前台:hiveserver2
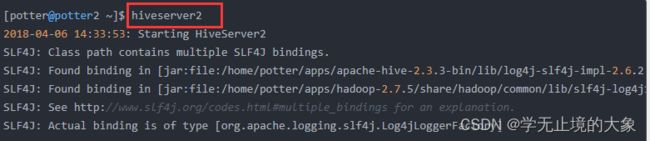
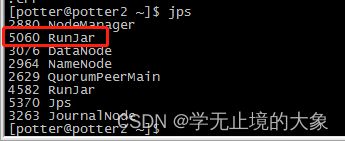
启动后会多出一个进程:
启动为后台:
nohup hiveserver2 1>/home/hadoop/hiveserver.log 2>/home/hadoop/hiveserver.err &
或者:nohup hiveserver2 1>/dev/null 2>/dev/null &
或者:nohup hiveserver2 >/dev/null 2>&1 &

命令中的 1 和 2 的意义分别是:
1:表示标准日志输出
2:表示错误日志输出
如果我没有配置日志的输出路径,日志会生成在当前工作目录,默认的日志名称叫做:nohup.xxx

nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束,那么可以使用 nohup 命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。nohup 就是不挂起的意思(no hang up)。
该命令的一般形式为:nohup command &
第二步:然后启动 beeline 客户端去连接:
执行命令:
先执行 beeline
然后按图所示输入:!connect jdbc:hive2://hadoop02:10000 按回车,然后输入用户名,这个用户名就是安装 hadoop 集群的用户名

-u : 指定元数据库的链接信息
-n : 指定用户名和密码
三、Web UI
1、 下载对应版本的 src 包:apache-hive-2.3.2-src.tar.gz
2、 上传,解压
tar -zxvf apache-hive-2.3.2-src.tar.gz
3、 然后进入目录${HIVE_SRC_HOME}/hwi/web,执行打包命令:
jar -cvf hive-hwi-2.3.2.war *
在当前目录会生成一个 hive-hwi-2.3.2.war
4、 得到 hive-hwi-2.3.2.war 文件,复制到 hive 下的 lib 目录中
cp hive-hwi-2.3.2.war ${HIVE_HOME}/lib/
5、 修改配置文件 hive-site.xml
hive.hwi.listen.host 0.0.0.0 监听的地址 hive.hwi.listen.port 9999 监听的端口号 hive.hwi.war.file lib/hive-hwi-2.3.2.war war 包所在的地址6、 复制所需 jar 包
1、cp ${JAVA_HOME}/lib/tools.jar ${HIVE_HOME}/lib
2、再寻找三个 jar 包,都放入${HIVE_HOME}/lib 目录:
commons-el-1.0.jar
jasper-compiler-5.5.23.jar
jasper-runtime-5.5.23.jar
不然启动 hwi 服务的时候会报错。
7、 安装 ant
1、 上传 ant 包:apache-ant-1.9.4-bin.tar.gz
2、 解压
tar -zxvf apache-ant-1.9.4-bin.tar.gz -C ~/apps/
3、 配置环境变量
vi /etc/profile
在最后增加两行:
export ANT_HOME=/home/hadoop/apps/apache-ant-1.9.4
export PATH=$PATH:$ANT_HOME/bin
配置完环境变量别忘记执行:source /etc/profile
4、 验证是否安装成功

8、 上面的步骤都配置完,基本就大功告成了。进入${HIVE_HOME}/bin 目录:
${HIVE_HOME}/bin/hive --service hwi
或者让在后台运行:
nohup bin/hive --service hwi > /dev/null 2> /dev/null &
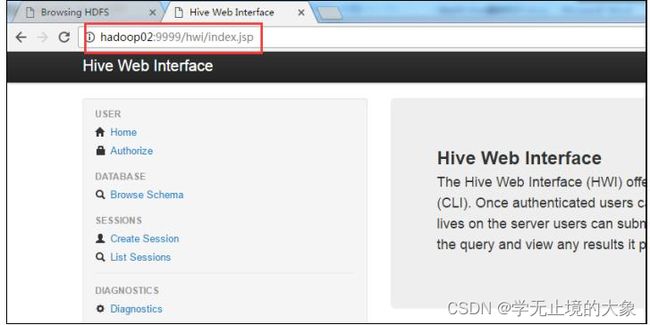
9、 前面配置了端口号为 9999,所以这里直接在浏览器中输入:
hadoop02:9999/hwi
10、至此大功告成