大数据技术探索
1. 基础组件认识
大数据其实是对数据的分布式存储、分析运算,用于决策的一系列技术,所有组件环境一般用使用Linux系统部署。
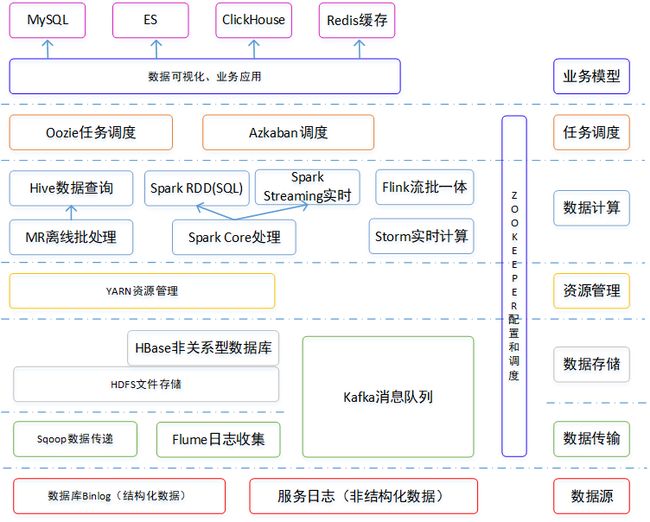
1.1 HDFS
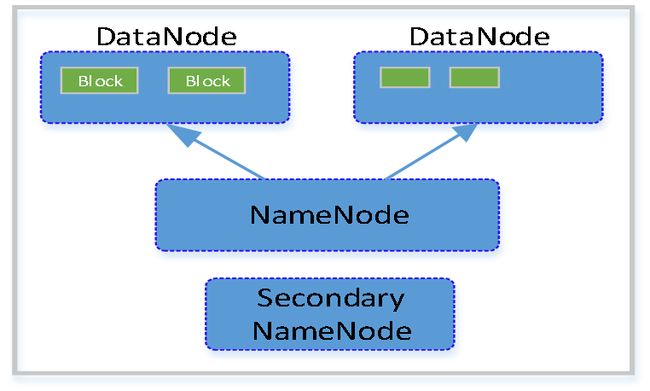
1)HDFS集群包括:NameNode和DataNode以及Secondary Namenode。
2)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
3)DataNode负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
4)Secondary NameNode用来监控HDFS状态的辅助后台程序,定期获取HDFS元数据的快照。
1.2 HBase
一个用以储存结构化和非结构化数据的分布式列式存储数据库,数据储存在hdfs中,仅支持单维度查询且不支持sql语句。
1.3 Kafka
一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统。
1.4 Sqoop

主要用于Hadoop(Hive) 与传统数据库(MySql,Oracle)间的数据传递,底层通过Hadoop的MR计算导入导出。
1.5 Yarn
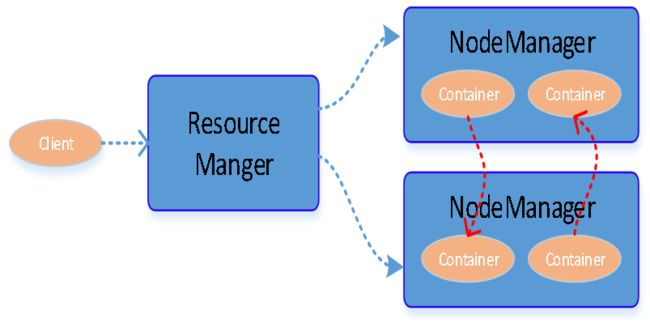
负责调度数据分析运算所需要的资源、CPU、内存、磁盘空间等。
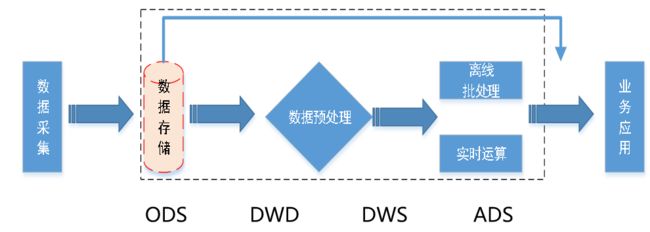
2. 数据异构技术栈
数据采集可以是web服务器埋点日志或通过工具采集输出到指定位置(数据库binlog监听) 。中间数据仓采用Spark离线批处理+FLink流式处理技术对业务数据进行加工清洗,处理结果聚合输出到外部快速查询数据库实现业务需求。
2.1 Spark组件栈
基于内存离线计算,计算速度快,解决批处理、结构化数据查询、流计算、图计算和机器学习业务场景。
Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成;基本数据结构:RDD(弹性分布式数据集)。
2.1.1 开发流程
1、创建sparksession实例:
SparkSession sparkSession = SparkSession.builder().appName("SparkUnionTable").getOrCreate();2、加载数据源:(//此处以访问mysql为例)
Dataset dataset= sparkSession.read().option("driver", JDBC_Driver_Mysql).jdbc(Db_Store_URL, "XXX", db_store_pro)
3、数据集转换算子(数据转换方法):
- 直接调用Spark SQL算子select、join、union、filter等操作;
- 转换成RDD调用Spark Core API进行RDD算子转换。
此处以RDD mapPartitions为例:将待处理的数据以分区为单位发送到计算节点进行处理。
JavaRDD javaRDD = WaProductRDD.mapPartitions(new FlatMapFunction, SgProductsIndex>() {
@Override
public Iterator call(Iterator iterator) throws Exception {
List resultList= new ArrayList<>();
while (iterator.hasNext()) {
SgProductsIndex sgProductsIndex = iterator.next();
//此处对iterator遍历时,尽可能将实体做一次拷贝,避免对象引用地址重复导致数据异常
SgProductsIndex newIndex = new SgProductsIndex();
BeanUtils.copyProperties(newIndex, sgProductsIndex);
//拷贝后再对newIndex进行操作........
resultList.add(newIndex);
}
return list.iterator;
}
}); 4、数据输出:
dataset.write().mode(SaveMode.Append)
.option("driver", JDBC_Driver_Mysql)
.option("batchsize", 2000)
.option("isolationLevel", "NONE")
.jdbc(Db_Store_URL, Store_Product_Table, engineer_pro);任务提交:
spark-submit \
--name store-scene-avg-price \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \ --设置Driver进程的内存
--num-executors 3 \ --各个工作节点上,启动相应数量的Executor进程
--executor-cores 2 \ --每个Executor进程的CPU core数量
--executor-memory 2g \ --每个Executor进程的内存
--conf spark.executor.memoryOverhead=2g \
--conf spark.debug.maxToStringFields=200 \
--conf spark.yarn.maxAppAttempts=1 \
--class com.scene.main.StoreSceneAvgPriceJob \
store-scene-avg-price-1.0-SNAPSHOT.jar- spark.default.parallelism 处理RDD时设置每个stage的默认task数量(设置为总cores的2-3倍)
- spark.sql.shuffle.partitions 处理SparkSQL Dataset时设置shuffle分区数(同上)
- spark.storage.memoryFraction 设置RDD持久化数据在Executor内存中能占的比例,默认0.6
- spark.shuffle.memoryFraction shuffle 过程中进行聚合操作能够使用的Executor内存比例,默认0.2
任务提交启动过程:
提交任务,Application首先被Driver构建DAG图并分解成Stage;然后Driver向Cluster Manager申请资源(Yarn);Work Node启动Executor进程并向Driver申请任务;Driver分配Task给Work Node,以Stage为单位执行Task,期间Driver进行监控;Driver收到Executor任务完成的信号后向Cluster Manager发送注销信号;Cluster Manager向Work Node发送释放资源信号;Work Node对应Executor停止运行。
2.1.2 Dataset Join
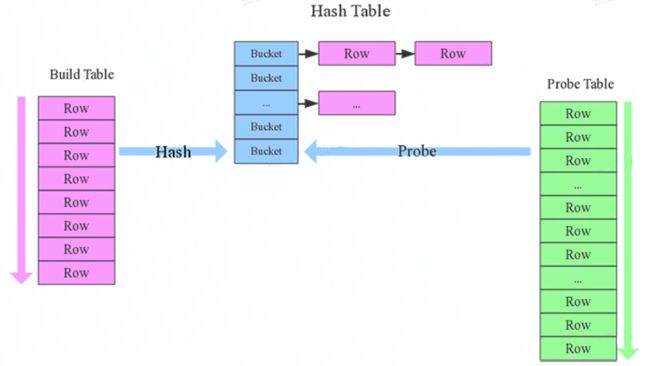
1.确定Build Table以及Probe Table:
Build Table使用join key构建Hash Table,而Probe Table使用join key进行探测,探测成功就可以join在一起,小表会作为Build Table,大表作为Probe Table。
2.构建Hash Table:
依次读取Build Table的数据,对于每一行数据根据join key进行hash,hash到对应的Bucket,生成hash table中的一条记录;
3.再依次扫描Probe Table的数据,使用相同的hash函数映射Hash Table中的记录,映射成功之后再检查join条件,如果匹配成功就可以将两者join在一起。
//在select时注意 as 使用方式
/**
* 获取门店列表
*/
Dataset mdSet = sparkSession.read()
.jdbc(CommonConfig.Db_Store_URL, "xxx", db_store_pro)
.selectExpr("xx as storeId", "xx as mdCode", "xx as mdName");
/**
* 店铺属性
*/
Dataset storeSet = sparkSession.read()
.jdbc(CommonConfig.Db_Store_URL, "xxx", db_store_pro)
.selectExpr("xx as storeId", "xx as storeCode", "xx as storeName");
//Dataset join过程注意去重(可在join-->select进行dropDuplicates操作)
Dataset dataSet = mdSet.join(storeSet,"storeId");
2.1.3 Spark-广播变量
广播变量不需要每个task带上一份变量副本,而是变成每个节点的executor拷贝一份副本,极大的减少了Executor的内存开销。
Map> cityStreetMap = new HashMap<>();
Broadcast>> cityStreetBroadcast = javaSparkContext.broadcast(cityStreetMap);
Map> cityStreetMap = cityStreetBroadcast.getValue(); RDD不能作为广播变量传递。
在声明广播变量的时候,必须在driver端,因为javaSparkContext没有被序列化,是不能被发送到Executor端的。
2.1.4 Row、RDD、实体类转换
Dataset products
Dataset productsDataset
JavaRDD productRDD
//Row ---> 对象:确保对象中属性必须在Row中存在相应column
productsDataset = products.as(Encoders.bean(SgProducts.class))
//RDD ---> Row
Dataset productSet = sparkSession.createDataFrame(productRDD, SgProducts.class)
2.2 Flink组件栈
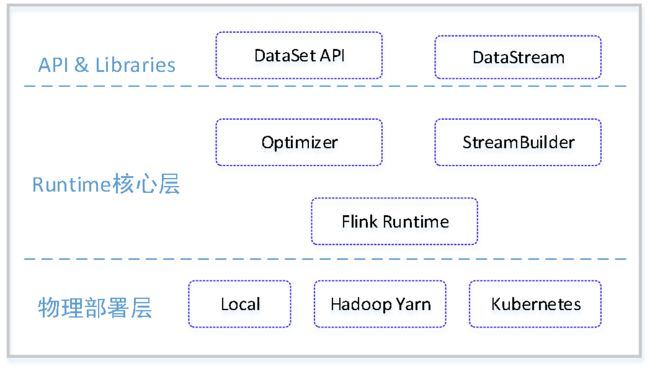
Flink是一种分布式处理引擎,对无界和有界数据流进行计算,由上往下依次分为API&Libraries层、Runtime核心层以及物理部署层。
2.2.1 程序数据流
1、获得执行环境execution environment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//设置checkpoint
environment.enableCheckpointing(10 * 60 * 1000);//每隔10min产生一次
CheckpointConfig checkpointConfig = environment.getCheckpointConfig();
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); //确保一次语义
checkpointConfig.setCheckpointTimeout(60 * 1000);2、加载初始数据源Source
//对接Kafka数据
KafkaSource kafkaStoreSource = KafkaSource.builder()
.setBootstrapServers(CommonConfig.KAFKA_SERVERS_IP)
.setTopics(CommonConfig.KAFKA_STORE_TOPIC)
.setGroupId(CommonConfig.KAFKA_STORE_GROUP_ID)
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema()).build();
DataStream dataStream= environment.fromSource(kafkaStoreSource, WatermarkStrategy.noWatermarks(), "Store Source")
.setParallelism(CommonConfig.MIN_PARALLELISM_NUM) 3、输入各种转换算子Transformation
//采用Side Output 进行分流,向下游输出指定条件的数据
SingleOutputStreamOperator singleOutPutStream = dataStream.map((MapFunction) JsonUtil::str2SimplifyJsonNode)
.process(new SplitTableStreamFunction());
//使用getSideOutput 方法来获取不同 OutputTag 的数据进行后续算子
singleOutPutStream.getSideOutput(SplitTableStreamFunction.STORE_MD_TAG)
.flatMap(new PrivateMdFunction()); 4、最终结果的输出Sink
//自定义输出sink
inputStream.addSink(new CustomSink());
//启动任务
environment.execute("Application");任务提交:
flink run -m ${Mode} -yjm ${JobManagerMem} -ytm ${TaskManagerMem} -ys ${TaskSlot} -ynm ${ApplicationName} --class ${CLASS_NAME} ${JAR}
-m yarn-cluster 在yarn上运行独立的flink job
-s 每个TaskManager分配的任务槽数
-yjm 申请的JobManager的内存大小
-ytm 申请的每个TaskManager的内存大小
-ynm yarn application 显示的名称
--class 类名2.2.2 Stream分流、合流
使用Fliter过滤接口可以进行拆分,遍历整个数据流获取相应的数据,这样性能很低,但是Flink不支持连续过滤。
采用Side Output 进行分流,Side-Output 可以以侧流的形式,向下游输出指定条件的数据、异常数据、迟到数据等等。
-
首先需要定义一个 OutputTag 来标识 Side Output,代表这个 Tag 要收集哪种类型的数据。
public static final OutputTag OCO_STREET = new OutputTag<>("xxx", TypeInformation.of(JsonNode.class));
public static final OutputTag STORE_PRODUCT = new OutputTag<>("xxx", TypeInformation.of(JsonNode.class));
public static final OutputTag SG_STORE = new OutputTag<>("xxx", TypeInformation.of(JsonNode.class));
public static final OutputTag STOCK = new OutputTag<>("xxx", TypeInformation.of(JsonNode.class)); - 使用下面几种函数来处理数据,在数据处理逻辑实现接口processElement()过程中将不同类型的数据存到不同的 OutputTag 中。
public void processElement(JsonNode jsonNode, Context context, Collector collector) throws Exception {
String tableName = jsonNode.get("table").asText();
switch (tableName) {
case "xxx":
context.output(STOCK, jsonNode);
break;
case "xxx":
context.output(SG_STORE, jsonNode);
break;
}
} - 使用 getSideOutput 方法来获取不同 OutputTag 的数据进行后续算子操作。
DataStream<> stockStream = sideStream.getSideOutput(ProductStoreProcessFunction.STOCK);
DataStream<> sgStoreStream = sideStream.getSideOutput(ProductStoreProcessFunction.SG_STORE);Union、Connect
-
Union可以将两个或多个同数据类型的流合并成一个流。
-
Connect可以用来合并两种不同类型的流。
-
Connect合并后,可用map中的CoMapFunction或flatMap中的CoFlatMapFunction来对合并流中的每个流进行处理。
2.2.3 窗口Windows
流处理中的聚合操作不同于批处理,因为数据流是无限,无法在其上应用聚合,所以通过限定窗口(window)的范围来进行流的聚合操作。
Windows是处理无限流的核心,将流分成有限大小的”数据存储桶“。
一般会分两类:
1、键控流:
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
.reduce/aggregate/fold/apply() <- required: "function"
2、非键控流:
.windowAll(...)
.reduce/aggregate/fold/apply() <- required: "function"
二者的区别是:对键控流的keyBy(…)调用window(…),而非键控流则是调用windowAll(…)。
TimeWindow:窗口是左闭右开的
1、Event Time:事件时间是每个事件在其生产设备上发生的时间。
2、Processing Time:处理时间是指正在执行相应算子操作的机器的系统时间,默认的时间属性就是Processing Time。
滚动窗口:
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
滑动窗口:
.window(SlidingProcessingTimeWindows.of(Time.seconds(5), Time.seconds(3)))
会话窗口
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
2.2.4 Flink数据性能
常见性能问题:
-
JSON序列化和反序列化
-
数据倾斜 --- 影响系统的吞吐
-
频繁的GC ---内存或比例分配不均
-
大窗口 --- 窗口size大、数据量大或者滑动窗口step大
-
存在低速系统频繁交互
基于上述性能问题的定位口诀:一压二查三指标,延迟吞吐是核心。时刻关注资源量 , 排查首先看GC。
-
反压:通常最后一个被压的subTask下游就是瓶颈之一;
-
checkpoint时长:checkpoint时长可以在一定程度影响Job吞吐;
-
核心指标:延迟指标和吞吐;
-
资源利用率:合理分配资源,提高利用率。
(1)看反压(backpressure):最后一个反压的 Subtask,其下游就是反压的源头,即 job 的瓶颈。
-
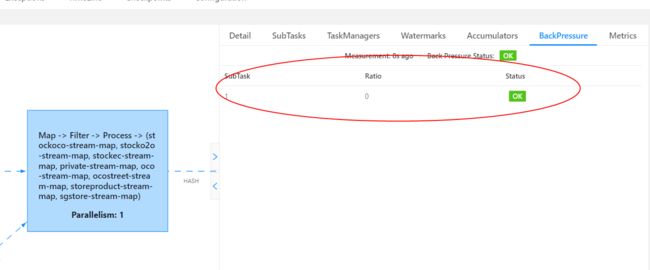
通过 Flink Web UI 自带的反压监控面板;
Flink Web UI 的反压监控提供了 SubTask 级别的反压监控,要采集所有 Task 的栈信息,得到线程被阻塞在请求的频率。默认配置下,这个频率在 0.1 以下则为 OK,0.1 至 0.5 为 LOW,而超过 0.5 则为 HIGH。
-
通过 Flink Task Metrics。
监控反压时会用到的 Metrics 主要和 Channel 接受端的 Buffer 使用率有关,最为有用的是以下几个 Metrics, outPoolUsage占用率很高,则表明它被下游反压限速了;inPoolUsage占用很高,则表明它将反压传导至上游。

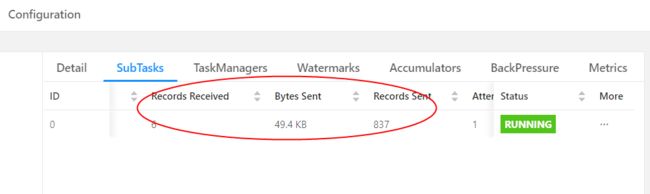
在实践中,很多情况下的反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认。
另外 Checkpoint detail 里不同 SubTask 的 State size 也是分析数据倾斜的有用指标。
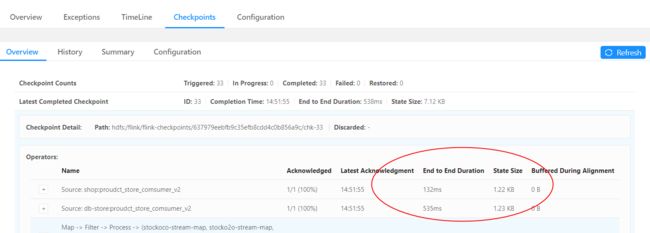
2.2.5 自定义Sink
FLink内置支持连接器:Apache Kafka、Elasticsearch、Hadoop文件系统、RabbitMQ、Apache ActiveMQ、Apache Flume、Redis。
Flink自定义Sink需要继承RichSinkFunction类,主要重写三个方法 ,分别为:open(),invok(),close()。
public class CustomSink extends RichSinkFunction {
/**
* 在创建sink时候只调用一次,用于初始化一些资源配置,譬如创建了JDBC、Redis的连接
*/
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
/**
* invoke方法是sink数据处理逻辑的方法,在每次有数据流入时都会调用
* value参数即为流中的数据元素,与RichSinkFunction中的泛型对应
* context为一些上下文信息
*/
@Override
public void invoke(String value, Context context) throws Exception {
//具体数据处理逻辑
}
/**
* close()方法用于关闭sink时调用,一般用于释放资源
*/
@Override
public void close() throws Exception {
super.close();
}
} 3. 团队介绍
「三翼鸟数字化技术平台-交易交付平台」负责搭建门店数字化转型工具,包括:海尔智家体验店小程序、三翼鸟工作台APP、商家中心等产品形态,通过数字化工具,实现门店的用户上平台、交互上平台、交易上平台、交付上平台,从而助力海尔专卖店的零售转型,并实现三翼鸟店的场景创新。