Make your own Pytorch-YOLOv3
Make your own Pytorch-YOLOv3
1.主干网络(backbone)
YOLOv3主干网络是darknet53,主要是由基本的模块ResBlock连接而成,没有网络分支,前向传播较为简单。
基本的ResBlock模块代码如下所示,主要是交替完成1x1和3x3的卷积,每个卷积之后都应用了BN层和LeakyReLU层。
# 本文注释的数字都是以416x416的图像作为输入,类别参考VOC共20个类别。
class BasicBlock(nn.Module):
def __init__(self, channels):
"""
1x1卷积 与 3x3卷积 交替的网络结构
:param channels: List,对应于整个残差块的输入输出通道,例如[32,64],[64,128]
"""
super(BasicBlock, self).__init__()
# 64x64 --> 32x32
# 128x128 --64x64
self.conv1 = nn.Conv2d(in_channels=channels[1], out_channels=channels[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(channels[0])
self.relu1 = nn.LeakyReLU(0.1)
# 32x32 --> 64x64
# 64x64 --> 128x128
self.conv2 = nn.Conv2d(in_channels=channels[0], out_channels=channels[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(channels[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
"""
生成ResNet结构
:param x: 网络输入特征图
:return: 经过处理后的特征图
"""
# 残差边 shortcut
residual = x
# 减少通道数的卷积
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
# 增加通道数的卷积
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
# 残差边和卷积边连接
out += residual
return out
下面代码是DarkNet类,表示darknet网络的基本结构,其中传入的layers参数用来控制网络的层数,比如darknet53中layers = [1, 2, 8, 8, 4],darkent21中layers = [1, 1, 2, 2, 1]可以提高代码的重用。
class DarkNet(nn.Module):
def __init__(self, layers):
super(DarkNet, self).__init__()
# [1, 2, 8, 8, 4]
self.layers = layers
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu1 = nn.LeakyReLU(0.1)
# res_blockn表示基本的残差模块,n表示该残差模块循环了几次,实际循环中使用num_blocks进行控制
# 416,416,32 -> 208,208,64
self.res_block1 = self._make_layer([32, 64], layers[0])
# 208,208,64 -> 104,104,128
self.res_block2 = self._make_layer([64, 128], layers[1])
# 104,104,128 -> 52,52,256
self.res_block3 = self._make_layer([128, 256], layers[2])
# 52,52,256 -> 26,26,512
self.res_block4 = self._make_layer([256, 512], layers[3])
# 26,26,512 -> 13,13,1024
self.res_block5 = self._make_layer([512, 1024], layers[4])
def _make_layer(self, in_out_channels, num_blocks):
"""
stride=2的降采样卷积,提高通道数,并生成残差块
:param in_out_channels:网络的输入输出通道,例[32,64],[64,128]
:param num_blocks:残差块个数,即BasicBlock循环次数
:return:[1,2,8,8,4]对应数量的残差块网络
"""
layers = []
# 下采样,步长为2,卷积核大小为3
layers.append(("ds_conv", nn.Conv2d(in_channels=in_out_channels[0], out_channels=in_out_channels[1], kernel_size=3, stride=2, padding=1, bias=False)))
layers.append(("ds_bn", nn.BatchNorm2d(in_out_channels[1])))
layers.append(("ds_relu", nn.LeakyReLU(0.1)))
# 加入残差结构
for i in range(0, num_blocks):
layers.append(("residual_{}".format(i), BasicBlock(in_out_channels)))
return nn.Sequential(OrderedDict(layers))
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.res_block1(x)
x = self.res_block2(x)
# 52x52x256
out3 = self.res_block3(x)
# 26x26x512
out4 = self.res_block4(out3)
# 13x13x1024
out5 = self.res_block5(out4)
print("out3:")
return out3, out4, out5
然后我们可以使用tensorboard模块将网络结构进行可视化检查
from torch.utils.tensorboard import SummaryWriter
if __name__ == '__main__':
darknet53 = DarkNet([1, 2, 8, 8, 4])
writer = SummaryWriter(log_dir='logs_net', flush_secs=1)
inputs = torch.rand(1, 3, 416, 416)
writer.add_graph(darknet53, inputs)
writer.close()
# 在logs_net路径下会生成event文件,在bash中`tensorboard --logdir=logs_net`可以显示

tensorboard中显示的网络结构可以不断放大,只到最基础的结构。
- 小结
一般主干网络的结构较为简单,没有较多的分支连接,逻辑较为清晰。github上有较多的开源代码可以使用,这部分一般只需看懂,在开源代码的基础上修改即可。
2.YOLOv3多尺度融合网络(YOLOv3 detect Header)
这部分主要完成YOLOv3的多尺度融合部分代码,由于多尺度融合网络结构较为复杂,分支和连接较多,只看代码容易晕,需保持逻辑清晰。下图较为清晰的展示了YOLOv3的网络结构,我们在这部分只关注多尺度融合部分即可。与代码结合着学习,可以清晰的了解网络结构和实现原理。
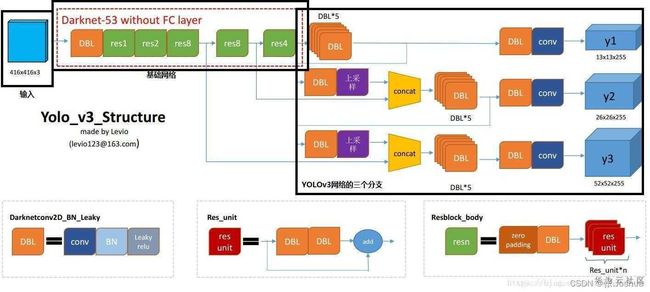
这部分还是使用由小到大的策略,从图中可以看出DBL模块(代码中定义的CBL模块)使用较多,先实现这个小模块,代码如下:
# CBL模块
# Conv+BN+LeakyReLU
class CBL(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding, stride=1):
"""
Conv+BN+LeakyReLU子模块
:param in_channels:
:param out_channels:
:param kernel_size:
:param padding:
:param stride:
"""
super(CBL, self).__init__()
self.cbl = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, padding=padding, stride=stride, bias=False),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1),
)
def forward(self, x):
return self.cbl(x)
其中由3处使用了5次DBL模块,这里也将其当做一个小模块实现,代码如下:
# CBL*5模块,由5个CBL模块组成
# 在YOLOv3中使用了三次该模块,分别是13x13, 26x26, 52x52
class CBL_5(nn.Module):
def __init__(self, in_channels, channels_large, channels_small):
"""
:param channels_large: CBL*5模块中较大的通道数
:param channels_small: CBL*5模块中较小的通道数
"""
super(CBL_5, self).__init__()
self.cal_5 = nn.Sequential(
CBL(in_channels=in_channels, out_channels=channels_small, kernel_size=1, padding=0),
CBL(in_channels=channels_small, out_channels=channels_large, kernel_size=3, padding=1),
CBL(in_channels=channels_large, out_channels=channels_small, kernel_size=1, padding=0),
CBL(in_channels=channels_small, out_channels=channels_large, kernel_size=3, padding=1),
CBL(in_channels=channels_large, out_channels=channels_small, kernel_size=1, padding=0),
)
def forward(self, x):
return self.cal_5(x)
YOLOv3的结构图中最后输出时为DBL+conv,我们将这两个合为一个模块进行实现,代码如下:
class CBL_CONV(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
"""
CBL_CONV:CBL(Conv+BN+LeakyReLU子模块)+卷积模块
CBL_CONV用于最后一层输出
:param in_channels:输入通道
:param middle_channels:CBL输出通道,Conv2d的输入通道
:param out_channels:输出通道,VOC为75 3x(20+1+4),COCO为255 3x(80+1+4)
"""
super(CBL_CONV, self).__init__()
self.cbl_conv = nn.Sequential(
CBL(in_channels, middle_channels, kernel_size=3, padding=1),
nn.Conv2d(middle_channels, out_channels, kernel_size=1, padding=0, bias=True)
)
def forward(self, x):
return self.cbl_conv(x)
现在多尺度融合部分还剩下上采样和Concat这两个模块没有,Concat部分功能简单,只需将两个特征图拼接即可,torch中自带了torch.cat()可以实现。YOLOv3作者使用的是最近邻插值上采样算法,上采样率为2,也就是输入特征图的每个元素复制4份进行输出。上采样部分代码实现如下:
class CBL_UpSample(nn.Module):
def __init__(self, in_channels, out_channels):
"""
CBL_UpSample:CBL+上采样子模块模块
CBL_UpSample一般用于torch.cat之前
上采样算法有:nearest, linear(3D - only), bilinear(4D - only), bicubic (4D-only), trilinear(5D - only) .只有4D可用
最近邻、线性、双线性, 双三次(bicubic)和三线性(trilinear)插值算法
:param in_channels:对应于小尺寸的通道数
:param out_channels:输出通道数
"""
super(CBL_UpSample, self).__init__()
self.cbl_conv = nn.Sequential(
CBL(in_channels, out_channels, kernel_size=1, padding=0),
nn.Upsample(scale_factor=2, mode="nearest")
)
def forward(self, x):
return self.cbl_conv(x)
至此,我们已经完成了组成多尺度融合网络的所有组件的代码实现,接下来只需要像搭积木一样把我们已经完成的组件按照网络结构搭建起来即可。多尺度融合代码如下:
class YOLOv3(nn.Module):
def __init__(self):
super(YOLOv3, self).__init__()
# 主干网络
self.backbone = darknet53()
COCO_CLASS = (80 + 5) * 3
VOC_CLASS = (20 + 5) * 3
# 13尺度,CBL*5模块
self.cbl_5_13 = CBL_5(1024, 1024, 512)
# 13尺度,CBL+Conv模块
self.cbl_conv_13 = CBL_CONV(512, 1024, VOC_CLASS)
# 26尺度, CBL+上采样模块
self.cbl_upsample_26 = CBL_UpSample(512, 256)
# 26尺度, CBL*5模块
self.cbl_5_26 = CBL_5(768, 512, 256)
# 26尺度, CBL+Conv模块
self.cbl_conv_26 = CBL_CONV(256, 512, VOC_CLASS)
# 52尺度, CBL+上采样模块
self.cbl_upsample_52 = CBL_UpSample(256, 128)
# 52尺度, CBL*5模块
self.cbl_5_52 = CBL_5(384, 256, 128)
# 52尺度, CBL+Conv模块
self.cbl_conv_52 = CBL_CONV(128, 256, VOC_CLASS)
def forward(self, x):
# 获取主干网络的三个输出
# x2:52x52x256
# x1:26x26x512
# x0:13x13x1024
x2, x1, x0 = self.backbone(x)
# 13x13x1024 --> 13x13x512 --> 13x13x1024 --> 13x13x512 --> 13x13x1024 --> 13x13x512
# 卷积核: 1x1 --> 3x3 --> 1x1 --> 3x3 --> 1x1
out0_branch = self.cbl_5_13(x0)
# 13x13x512 --> 13x13x1024 --> 13x13x75
out0 = self.cbl_conv_13(out0_branch)
# CBL+UpSample
# 13x13x512 --> 13x13x256 --> 26x26x256
out1_branch = self.cbl_upsample_26(out0_branch)
# [26x26x256, 26x26x512] --> 26x26x768
out1_branch = torch.cat([out1_branch, x1], 1)
# 26x26x768 --> 26x26x256 --> 26x26x512 --> 26x26x256 --> 26x26x512 --> 26x26x256
out1_branch = self.cbl_5_26(out1_branch)
# 26x26x256 --> 26x26x512 --> 26x26x75
out1 = self.cbl_conv_26(out1_branch)
# out2_branch 为了保持和前文形式统一
# 26x26x256 --> 26x26x128 --> 52x52x128
out2_branch = self.cbl_upsample_52(out1_branch)
# [52x52x128, 52x52x256] --> 52x52x384
out2_branch = torch.cat([out2_branch, x2], 1)
# 52x52x384 --> 52x52x128 --> 52x52x256 --> 52x52x128 --> 52x52x256 --> 52x52x128
out2_branch =self.cbl_5_52(out2_branch)
# 52x52x128 --> 52x52x256 --> 52x52x75
out2 = self.cbl_conv_52(out2_branch)
# out0:13x13x75
# out1:26x26x75
# out2:52x52x75
return out0, out1, out2
代码最后返回的out0, out1, out2是YOLOv3最终输出的三个尺度特征图(feature map)。至此完成了YOLOv3网络模型的搭建。同样,也可以使用tensorboard查看网络结构。也可以使用pytorch自带的summary模块查看网络参数,代码实现如下:
import torch
from torchsummary import summary
from yolov3 import YOLOv3
if __name__ == "__main__":
# 需要使用device来指定网络在GPU还是CPU运行
# summary显示网络结构
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = YOLOv3().to(device)
summary(model, (3, 416, 416))
运行成功后输出内容如图所示:

3.损失函数
3.1 锚框(anchor)
- YOLOv3中锚框的尺寸是通过k-means聚类得到的。具体实现:初始花k(= 9)个锚框尺寸,计算数据集中每一个bounding box与这9个anchor box的IoU,然后找出IoU最大的anchor box,把这bounding box归类到这个IoU最大的anchor box中,遍历完所有的bounding box后,对每个anchor box的尺寸进行更新,更新策略有使用bounding box中值更新,也有均值更新。直到anchor box的尺寸不再变化,或者说每个anchor box中的bounding box不再变化。
- YOLOv3中得到的9个anchor box尺寸为:[10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326]。
- 在训练自己的网络时anchor box尺寸数值一般不做更改,因为用自己的数据集通过k-means聚类产生的anchor box效果不一定会有提升。主要是因为自己的数据集一般不够丰富,Label中标注框(真实框)的大小往往差不多,尺寸大小比较集中,这时通过k-means聚类产生的anchor box自然就很集中,几乎相差不大,反而体现不出模型的多尺度输出的优势,检测效果自然就变差了。
3.2 交并比计算(IoU)
IoU原理较为简单,实际代码实现时需要考虑较多的情况,比如两框不相交,两框左斜相交、右斜相交,一个小框包含在另一个框里面等情况。

IoU的计算计算,代码如下:
def calculate_iou(self, _box_a, _box_b):
"""
:param _box_a:真实框
:param _box_b:先验框
:return:IoU
"""
# 计算真实框的左上角和右下角
# _box_a = [cx, cy, w, h]
b1_x1, b1_x2 = _box_a[:, 0] - _box_a[:, 2] / 2, _box_a[:, 0] + _box_a[:, 2] / 2
b1_y1, b1_y2 = _box_a[:, 1] - _box_a[:, 3] / 2, _box_a[:, 1] + _box_a[:, 3] / 2
# 计算先验框获得的预测框的左上角和右下角
# _box_b = [cx, cy, w, h]
b2_x1, b2_x2 = _box_b[:, 0] - _box_b[:, 2] / 2, _box_b[:, 0] + _box_b[:, 2] / 2
b2_y1, b2_y2 = _box_b[:, 1] - _box_b[:, 3] / 2, _box_b[:, 1] + _box_b[:, 3] / 2
# 将真实框和预测框都转化成左上角右下角的形式
# 真实框:box_a = [x1, y1, x2, y2]
# 预测框:box_b = [x1, y1, x2, y2]
box_a = torch.zeros_like(_box_a)
box_b = torch.zeros_like(_box_b)
box_a[:, 0], box_a[:, 1], box_a[:, 2], box_a[:, 3] = b1_x1, b1_y1, b1_x2, b1_y2
box_b[:, 0], box_b[:, 1], box_b[:, 2], box_b[:, 3] = b2_x1, b2_y1, b2_x2, b2_y2
# A为真实框的数量,B为先验框的数量
A = box_a.size(0)
B = box_b.size(0)
# 计算交的面积
# torch.clamp(input,min,max),将输入input张量的每个元素夹紧到区间 [min,max],这里只限制了最小值,把负数拉回到0,应该是解决两框不相交的情况,计算面积时,0与任何数相乘得到交面积为0
# max_xy相当于图中的BBox1的(x2,y2)
# min_xy相当于图中的BBox2的(x1,y1)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2), box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2), box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0, )
# 交面积,如果不相交的话,torch.clamp会使inter两项产生一个0。从图形上讲就是不相交时长或宽为负,为了避免计算出负面积,clamp设置长宽小于0时即为0,从而下试计算的交面积为0。交面积为0时,IoU=0
inter = inter[:, :, 0] * inter[:, :, 1]
# 计算预测框和真实框各自的面积
# (x2 - x1) * (y2 - y1)
area_a = ((box_a[:, 2] - box_a[:, 0]) * (box_a[:, 3] - box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2] - box_b[:, 0]) * (box_b[:, 3] - box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
# 计算并的面积
union = area_a + area_b - inter
# 求IOU
return inter / union # [A,B]
3.3 真实值(target)的编码
在计算损失函数之前首先是对于13x13x75 26x26x75 52x52x75的输出进行解码的过程,转换为在特征图上的位置信息,然后才能基于特征图的尺寸根据先验框与真实框之间的位置信息(这里指的是x y w h,都是相对于特征图的,非相对于原图尺寸)计算位置损失函数,另外还有类别损失。以13x13的特征图为例,在VOC(20类)数据集中,该特征图需要产生13x13x(4+1+20)x3 = 12675 个anchor box。
class YOLOLoss(nn.Module):
def __init__(self, anchors, num_classes, input_shape, cuda, anchors_mask=[[6, 7, 8], [3, 4, 5], [0, 1, 2]]):
super(YOLOLoss, self).__init__()
# 以下锚框尺寸是相对与416x416的原始图像而言的
# 13x13的特征层对应的anchor是[116,90],[156,198],[373,326]
# 26x26的特征层对应的anchor是[30,61],[62,45],[59,119]
# 52x52的特征层对应的anchor是[10,13],[16,30],[33,23]
self.anchors = anchors
self.num_classes = num_classes
self.bbox_attrs = 5 + num_classes
self.input_shape = input_shape
self.anchors_mask = anchors_mask
self.ignore_threshold = 0.5
self.cuda = cuda
def clip_by_tensor(self, t, t_min, t_max):
"""
这个函数的作用就是抑制小数和大数
若t < t_min, t = t_min
若t > t_max, t = t_max
若t in [t_min, t_max], t = t
"""
t = t.float()
result = (t >= t_min).float() * t + (t < t_min).float() * t_min
result = (result <= t_max).float() * result + (result > t_max).float() * t_max
return result
def MSELoss(self, pred, target):
# 均方损失函数,一般没必要自己重写,直接用torch.nn
return torch.pow(pred - target, 2)
def BCELoss(self, pred, target):
"""
官方的nn.BCELoss是二分类任务时的交叉熵计算函数。相当于nn.CrossEntropyLoss函数的特例,其分类限定为二分类,y必须是{0, 1}。还需注意的是,input应为概率分布的形式,这样才符合交叉熵的应用。所以在BCELoss之前,input一般为sigmoid激活层的输出。
"""
epsilon = 1e-7
# 小于0的数置为epsilon,大于0的数置为(1.0 - epsilon)
# clip_by_tensor把pred确保在(0-1)的取值范围
pred = self.clip_by_tensor(pred, epsilon, 1.0 - epsi lon)
output = - target * torch.log(pred) - (1.0 - target) * torch.log(1.0 - pred)
return output
def forward(self, l, input, targets=None):
"""
:param l: 当前输入进来的有效特征层,是第几个有效特征层
:param input: input的shape为
bs, 3*(5+num_classes), 13, 13
bs, 3*(5+num_classes), 26, 26
bs, 3*(5+num_classes), 52, 52
:param targets: 真实框
:return:
"""
bs = input.size(0)
in_h = input.size(2)
in_w = input.size(3)
# 计算步长(缩放比例),也就是YOLOv3最终输出的特征图上的每一个特征点(像素)对应原来的图片上多少个像素点(对应原图上多大的感受野)
# 如果特征层为13x13的话,一个特征点就对应原来的图片上的32个像素点
# 如果特征层为26x26的话,一个特征点就对应原来的图片上的16个像素点
# 如果特征层为52x52的话,一个特征点就对应原来的图片上的8个像素点
# stride_h = stride_w = 416/13 = 32、416/26 = 16、416/52 = 8
stride_h = self.input_shape[0] / in_h
stride_w = self.input_shape[1] / in_w
# 此时获得的scaled_anchors大小是相对于特征层(feature map)的
# 13x13的特征层对应的anchor是[116,90],[156,198],[373,326] --> scaled_anchors:(3.625, 2.8125), (4.875, 6.1875), (11.65625, 10.1875)
# 26x26的特征层对应的anchor是[30,61],[62,45],[59,119] --> scaled_anchors:(1.875, 3.8125), (3.875, 2.8125), (3.6875, 7.4375)
# 52x52的特征层对应的anchor是[10,13],[16,30],[33,23] --> scaled_anchors:(1.25, 1.625), (2.0, 3.75), (4.125, 2.875)
# 实际上这里代码是计算了每个尺度是特征层的9个anchor,不过有用的数据仅有以上三行,全部计算仅是为了代码方便
scaled_anchors = [(a_w / stride_w, a_h / stride_h) for a_w, a_h in self.anchors]
# 对于(N C H W)的顺序调整为(N 3 H W cls)
# 输入的input一共有三个,他们的shape分别是
# batch_size, 3*(5+num_classes), 13, 13 =>
# batch_size, 3, 13, 13, 5 + num_classes
# batch_size, 3, 26, 26, 5 + num_classes
# batch_size, 3, 52, 52, 5 + num_classes
# (0, 1, 3, 4, 2)顺序变换 --> (bs, len(self.anchors_mask[l]), in_h, in_w, self.bbox_attrs), self.bbox_attrs = 5 + num_classes
# eg: prediction.shape: torch.Size([4, 3, 13, 13, 25])
prediction = input.view(bs, len(self.anchors_mask[l]), self.bbox_attrs, in_h, in_w).permute(0, 1, 3, 4, 2).contiguous()
# 先验框的中心位置的调整参数, 从(5 + num_classes)中取出x y
# 用sigmoid函数,把x,y的值归一化到(0,1)的范围,避免调整量过大,同时避免影响其他anchor
# x.shape: [4, 3, 13, 13]
x = torch.sigmoid(prediction[..., 0])
y = torch.sigmoid(prediction[..., 1])
# 先验框的宽高调整参数, 从(5 + num_classes)中取出w h, shape: [4, 3, 13, 13]
w = prediction[..., 2]
h = prediction[..., 3]
# 获得置信度,是否有物体, 从(5 + num_classes)中取出conf, shape: [4, 3, 13, 13]
conf = torch.sigmoid(prediction[..., 4])
# 种类置信度, VOC有20个, COCO80个, pothole数据集1个, shape: [4, 3, 13, 13, 20]
pred_cls = torch.sigmoid(prediction[..., 5:])
# //获得网络应该有的预测结果, 进入get_target()
# targets是大小为8的列表,表示输入的bs=8的8张图片,targets[1]表示第2张图片中包含的目标,[cx,cy,w,h,class],targets[1]*13变换到13x13的特征图上的坐标
# y_true是 tx,ty,tw,th,conf,cls; noobj_mask是一个全是1的矩阵,但除了有目标的那个位置是0,即没有目标的位置全是1;
# box_loss_scale是调整loss大小的权重,大目标loss权重小,小目标loss权重大(大目标调整幅度大,需要抑制) in_h = 13
y_true, noobj_mask, box_loss_scale = self.get_target(l, targets, scaled_anchors, in_h, in_w)
# 将预测结果进行解码,判断预测结果和真实值的重合程度
# 如果重合程度过大则忽略,因为这些特征点属于预测比较准确的特征点
# 作为负样本不合适
'''
noobj_mask是一个全为1的矩阵,把IoU大于0.5的预测框去除掉,因为IoU大于0.5说明这些框已经预测的比较准确了,虽然不是最大的,但也不错了,不作为负样本
get_ignore返回的noobj_mask就全都是负样本了(不是最大的并且与真实框的IoU<0.5)
'''
noobj_mask = self.get_ignore(l, x, y, h, w, targets, scaled_anchors, in_h, in_w, noobj_mask)
if self.cuda:
y_true = y_true.cuda()
noobj_mask = noobj_mask.cuda()
box_loss_scale = box_loss_scale.cuda()
# reshape_y_true[...,2:3]和reshape_y_true[...,3:4]
# 表示真实框的宽高,二者均在0-1之间
# 真实框越大,比重越小,小框的比重更大。
box_loss_scale = 2 - box_loss_scale
# 计算中心偏移情况的loss,使用BCELoss效果好一些
# y_true[..., 0]是真实框的位置在单元格内的小数位的值,x是输出的25个神经元之一,x已经通过sigmoid归一化到了(0,1)区间
# 为什么x可以只预测小数值:因为锚点的位置已经确定,在通过计算最大IoU的哪一步,找到了最合适的锚框,而锚框的位置是我们预先设置好的,是已知的。
loss_x = torch.sum(self.BCELoss(x, y_true[..., 0]) * box_loss_scale * y_true[..., 4])
loss_y = torch.sum(self.BCELoss(y, y_true[..., 1]) * box_loss_scale * y_true[..., 4])
# 计算宽高调整值的loss
loss_w = torch.sum(self.MSELoss(w, y_true[..., 2]) * 0.5 * box_loss_scale * y_true[..., 4])
loss_h = torch.sum(self.MSELoss(h, y_true[..., 3]) * 0.5 * box_loss_scale * y_true[..., 4])
# 计算置信度的loss,对于有目标的锚框,他们的第二项为0
loss_conf = torch.sum(self.BCELoss(conf, y_true[..., 4]) * y_true[..., 4]) + \
torch.sum(self.BCELoss(conf, y_true[..., 4]) * noobj_mask)
# 这个是怎么计算的???
loss_cls = torch.sum(self.BCELoss(pred_cls[y_true[..., 4] == 1], y_true[..., 5:][y_true[..., 4] == 1]))
loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
num_pos = torch.sum(y_true[..., 4])
num_pos = torch.max(num_pos, torch.ones_like(num_pos))
return loss, num_pos
def get_target(self, l, targets, anchors, in_h, in_w):
# 计算一共有多少张图片 bs:4
bs = len(targets)
# 用于选取哪些先验框不包含物体 [4, 3, 13, 13]
noobj_mask = torch.ones(bs, len(self.anchors_mask[l]), in_h, in_w, requires_grad=False)
# 让网络更加去关注小目标 [4, 3, 13, 13]
box_loss_scale = torch.zeros(bs, len(self.anchors_mask[l]), in_h, in_w, requires_grad=False)
# batch_size, 3, 13, 13, 5 + num_classes [4, 3, 13, 13, 25]
y_true = torch.zeros(bs, len(self.anchors_mask[l]), in_h, in_w, self.bbox_attrs, requires_grad=False)
for b in range(bs):
# 判断该图中是否包含目标,不包含目标就直接跳过
if len(targets[b]) == 0:
continue
# 生成一个和targets[b]一样的列表list
# targets[7]: tensor([[ 0.1683, 0.6731, 0.0721, 0.4183, 4.0000],[ 0.4663, 0.5156, 0.3606, 0.7043, 14.0000]], device='cuda:0')
# targets[7]*13: [ 2.1875, 8.7500, 0.9375, 5.4375, 4],[ 6.0625, 6.7031, 4.6875, 9.1562, 14]
# targets[7][:, [0, 2]]: tensor([[0.1683, 0.0721], [0.4663, 0.3606]], device='cuda:0')
batch_target = torch.zeros_like(targets[b])
# [0, 2],纵向拉伸(x方向),从归一化尺寸(真实尺寸/416)还原到13x13的特征图上
"""
tensor([
[2.1875, 0.9375],
[6.0625, 4.6875]], device='cuda:0')
13x13特征图:[cx, w]
"""
batch_target[:, [0, 2]] = targets[b][:, [0, 2]] * in_w
# [1, 3],横向拉伸(y方向),从归一化尺寸还原到13x13的特征图上
"""
tensor([[8.7500, 5.4375],
[6.7031, 9.1562]], device='cuda:0')
13x13特征图:[cy, h]
"""
batch_target[:, [1, 3]] = targets[b][:, [1, 3]] * in_h
# 类别序号
# tensor([ 4., 14.], device='cuda:0')
batch_target[:, 4] = targets[b][:, 4]
batch_target = batch_target.cpu()
# batch_target [cx*13, cy*13, w*13, h*13, class ]
"""
tensor([[0.0000, 0.0000, 0.9375, 5.4375],
[0.0000, 0.0000, 4.6875, 9.1562]])
"""
# gt_box的第一项和第二项是0,第三项和第四项是从batch_target中取出的w*13, h*13
gt_box = torch.FloatTensor(torch.cat((torch.zeros((batch_target.size(0), 2)), batch_target[:, 2:4]), 1))
"""
anchor_shapes: 9个先验框,9行, 4列,后两列来自anchors
tensor([[ 0.0000, 0.0000, 0.3125, 0.4062],
[ 0.0000, 0.0000, 0.5000, 0.9375],
[ 0.0000, 0.0000, 1.0312, 0.7188],
[ 0.0000, 0.0000, 0.9375, 1.9062],
[ 0.0000, 0.0000, 1.9375, 1.4062],
[ 0.0000, 0.0000, 1.8438, 3.7188],
[ 0.0000, 0.0000, 3.6250, 2.8125],
[ 0.0000, 0.0000, 4.8750, 6.1875],
[ 0.0000, 0.0000, 11.6562, 10.1875]])
---------------------------------------
anchors: 是k-means得到的anchors/32的数值,相当于把anchors缩放到13x13的特征图上的位置
[(0.3125, 0.40625), (0.5, 0.9375), (1.03125, 0.71875), (0.9375, 1.90625), (1.9375, 1.40625), (1.84375, 3.71875), (3.625, 2.8125), (4.875, 6.1875), (11.65625, 10.1875)]
"""
# 思考:这里 gt_box只有长和宽的信息,anchor_shapes也是只有长和宽的原因
# 解答:应该是为了后续计算锚框与真实框的IoU,这里的计算方法有一点意外,前两项置为0相当于先将真实框和锚框左上角再计算IoU(有的地方是通过对齐中心后再计算IoU的,与左上角对齐效果一样)
# 对齐再计算IoU的好处:可以找到大小最合适的锚框,后面通过损失函数再调整中心位置的偏移。非常巧妙
anchor_shapes = torch.FloatTensor(
torch.cat((torch.zeros((len(anchors), 2)), torch.FloatTensor(anchors)), 1))
# 计算交并比
# self.calculate_iou(gt_box, anchor_shapes) = [num_true_box, 9]每一个真实框和9个先验框的重合情况
# best_ns:anchors的索引值,tensor([5, 7])
# 每个真实框最大的重合度max_iou, 每一个真实框最重合的先验框的序号
"""
tensor([[0.0456, 0.1684, 0.1895, 0.4834, 0.2492, 0.4059, 0.2038, 0.0923, 0.0234], #这个对应5号框
[0.0053, 0.0197, 0.0311, 0.0750, 0.1144, 0.2879, 0.4281, 0.7894, 0.2005]]) #这个对应7号框
"""
best_ns = torch.argmax(self.calculate_iou(gt_box, anchor_shapes), dim=-1)
# t=0, best_n=8
'''
anchors_mask[0]:[[6, 7, 8],
anchors_mask[1]:[3, 4, 5],
anchors_mask[2]:[0, 1, 2]]
'''
for t, best_n in enumerate(best_ns):
# 如果IoU得分最大的锚框的序号best_n在预设的该尺度下的3个锚框的序号anchors_mask[l]中,继续。否则跳过
if best_n not in self.anchors_mask[l]:
continue
# 判断这个先验框是当前特征点的哪一个先验框
# anchors_mask[l] = [6, 7, 8]
# anchors_mask[l].index(6) = 0
# anchors_mask[l].index(7) = 1
# anchors_mask[l].index(8) = 2】
# k=2
k = self.anchors_mask[l].index(best_n)
# 获得真实框属于哪个网格点
# torch.floor()向下取整,long()将tensor投射为long类型
# i=8 j=5
# batch_target[0]=tensor([ 8.2813, 5.7656, 6.6250, 11.5312, 14.0000])
i = torch.floor(batch_target[t, 0]).long()
j = torch.floor(batch_target[t, 1]).long()
# 取出真实框的种类 14
c = batch_target[t, 4].long()
# noobj_mask代表无目标的特征点, 把有目标的位置noobj_mask[7, 2, 5, 8]=0
noobj_mask[b, k, j, i] = 0
# tx、ty代表中心调整参数的真实值
# 竖直方向,中心点:0.2813表示的是真实框映射在在13*13尺度上,单个网格内的尺寸
y_true[b, k, j, i, 0] = batch_target[t, 0] - i.float()
# 水平方向,中心点:0.7656
y_true[b, k, j, i, 1] = batch_target[t, 1] - j.float()
# anchors[best_n][0] = 11.65625 y_true[b, k, j, i, 2] = tensor(-0.5650)
# 竖直方向,宽度
y_true[b, k, j, i, 2] = math.log(batch_target[t, 2] / anchors[best_n][0])
# 水平方向,高度
y_true[b, k, j, i, 3] = math.log(batch_target[t, 3] / anchors[best_n][1])
# 这个是啥意思?? 暂且当做置信度 conf
# 确实是置信度,真实框的在该锚点内有目标,所有置信度是1,这时真实框
y_true[b, k, j, i, 4] = 1
# 类别 c+5: 19
y_true[b, k, j, i, c + 5] = 1
'''
tensor([ 0.2813, 0.7656, -0.5650, 0.1239, 1.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 1.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000])
'''
# 用于获得xywh的比例
# 大目标loss权重小,小目标loss权重大
# w*h/32/32 box_loss_scale[b, k, j, i]:tensor(0.4520)
box_loss_scale[b, k, j, i] = batch_target[t, 2] * batch_target[t, 3] / in_w / in_h
return y_true, noobj_mask, box_loss_scale
def get_ignore(self, l, x, y, h, w, targets, scaled_anchors, in_h, in_w, noobj_mask):
# 计算一共有多少张图片batch_size
bs = len(targets)
# 改变数据类型
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
# 生成网格,先验框中心,网格左上角
# torch.linspace(0, 13 - 1, 13) 生成0-12的13个数构成等差数列 13
# repeat(13,1)扩充 13*13
# repeat(24,1,1)扩充 24*13*13
# x.shape:[8,3,13,13]
# grid_x是如何调整x的??? 随机值?
grid_x = torch.linspace(0, in_w - 1, in_w).repeat(in_h, 1).repeat(
int(bs * len(self.anchors_mask[l])), 1, 1).view(x.shape).type(FloatTensor)
grid_y = torch.linspace(0, in_h - 1, in_h).repeat(in_w, 1).t().repeat(
int(bs * len(self.anchors_mask[l])), 1, 1).view(y.shape).type(FloatTensor)
# 生成先验框的宽高
# [w,h]: [[ 3.625 2.8125 ], [ 4.875 6.1875 ], [11.65625 10.1875 ]]
scaled_anchors_l = np.array(scaled_anchors)[self.anchors_mask[l]]
# index_select(行列,[a,b]) 1表示取列,[a,b]表示取a列和b列
anchor_w = FloatTensor(scaled_anchors_l).index_select(1, LongTensor([0]))
anchor_h = FloatTensor(scaled_anchors_l).index_select(1, LongTensor([1]))
# anchor_w.shape [8,3,13,13]
anchor_w = anchor_w.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(w.shape)
anchor_h = anchor_h.repeat(bs, 1).repeat(1, 1, in_h * in_w).view(h.shape)
# 计算调整后的先验框中心与宽高
pred_boxes_x = torch.unsqueeze(x.data + grid_x, -1)
pred_boxes_y = torch.unsqueeze(y.data + grid_y, -1)
pred_boxes_w = torch.unsqueeze(torch.exp(w.data) * anchor_w, -1)
pred_boxes_h = torch.unsqueeze(torch.exp(h.data) * anchor_h, -1)
pred_boxes = torch.cat([pred_boxes_x, pred_boxes_y, pred_boxes_w, pred_boxes_h], dim=-1)
for b in range(bs):
# 将预测结果转换一个形式
# pred_boxes_for_ignore num_anchors, 4
pred_boxes_for_ignore = pred_boxes[b].view(-1, 4)
# 计算真实框,并把真实框转换成相对于特征层的大小
# gt_box num_true_box, 4
if len(targets[b]) > 0:
batch_target = torch.zeros_like(targets[b])
# 计算出正样本在特征层上的中心点
batch_target[:, [0, 2]] = targets[b][:, [0, 2]] * in_w
batch_target[:, [1, 3]] = targets[b][:, [1, 3]] * in_h
batch_target = batch_target[:, :4]
# 计算交并比
# anch_ious num_true_box, num_anchors
anch_ious = self.calculate_iou(batch_target, pred_boxes_for_ignore)
# 每个先验框对应真实框的最大重合度
# anch_ious_max num_anchors
anch_ious_max, _ = torch.max(anch_ious, dim=0)
# [3,13,13]
anch_ious_max = anch_ious_max.view(pred_boxes[b].size()[:3])
# 只把阈值大于ignore_threshold(0.5)的noobj_mask设为0,也就是保留他们
noobj_mask[b][anch_ious_max > self.ignore_threshold] = 0
# [8,3,13,13]
return noobj_mask
4.网络训练
待更新
5.结语
共同学习,共同交流,共同进步!
参考文章:https://blog.csdn.net/weixin_44791964/article/details/105310627