金融风控建设核心 —— 决策引擎
目录
一、前言
二、什么是风控决策引擎?
三、什么是特征?
五、功能模块
1. 特征管理
a)特征类型
b)特征来源
2. 规则管理
3. 规则集管理
a)规则表
b)规则树
4. 评分卡管理
5. 决策流管理
6. 历史决策管理
六、贷前应用场景
a)决策模型及规则介绍
贷前模型:
b)数据使用原则(主打一个降本~)
风控策略、风控运营等业务人员时常会用到一类系统,即风控决策引擎。那么,什么是风控决策引擎?风控决策引擎有哪些具体的功能模块,其对应的设计又是怎么样的?一起来看看作者的解读。
一、前言
信贷管理中的贷前管理、贷中管理、贷后管理这三篇介绍了信贷管理业务中的主要业务及系统是如何设计的,但是从内容来说,我自我感觉还是稍微比较乱的,后续的工作中如果有了新的理解,可能出再出对应的文章去做补充说明。
信贷管理部分就此告一段落,接下去就介绍下之前一直留下来的一个大坑——风控篇,也就是风控决策引擎部分。
二、什么是风控决策引擎?
「风控决策引擎」目前在市场上没有统一的官方定义,但是从用途来说主要是通过可视化的操作,提供规则、评分卡、决策流等工具,管理和评估风险的系统。主要在金融、电商、保险等各领域被使用。
为什么要设计成的系统?
本质上还是与业务流程的结耦,因为风控规则是高度灵活变动的,在业务的不同阶段和时期,或者说不同领导人的要求下,都是变动的。
如果配置灵活度不高,后期重新设计开发的可能性比较高。
风控决策引擎主要的使用对象是风控策略、风控运营等业务人员,主要工具包含规则、评分卡、决策流。
三、什么是特征?
在说具体工具之前,我们先来聊一聊特征,什么是特征?
特征可以说是风控系统中的最小单元,是风控工具的重要组成部分,我们也可以理解成变量。不过叫什么问题不大,团队内有相同的共识就行。
那么特征有哪些呢?
我们来稍微举几个例子,年龄、性别、年收入这些都属于特征,而这些特征我们需要给予他们对应的类型。从变量分类的角度来分类,可以有int、long、double、string、boolean等类型。但我是设计成了数值型(普通数值型/汇总数值型)、字符串型和枚举型这三种,做了一层归集和删减。
但是,无论采取哪种分类方式,后续的设计能够闭环即可。
四、什么是规则?
一个规则包含特征、逻辑运算符、比较运算符、阈值和触发结果。其中,特征、比较运算符和阈值构成条件表达式,规则由一个或多个条件表达式和触发结果构成,具体关系如下图:
看不懂?
没关系,我们就来举个简单的例子,就以进入网吧的准入规则为例:
- 若对象年龄大于等于18岁,则可进入
- 若对象年龄小于18岁,则不可进入
这就是一个简单的规则,也是一个条件表达式,其中特征=年龄、比较运算符=大于等于、阈值=18,若满足条件,则触发结果=True,则可进入网吧;否则触发结果=False,不可进入。
那如果增加一个准入条件“是否有钱呢”,那么准入规则就变成为:
- 若对象年龄大于等于18岁,且有钱,则可进入
- 若对象年龄大于等于18岁,且没钱,则不可进入
- 若对象年龄小于18岁,且有钱,则不可进入
- 若对象年龄小于18岁,且没钱,则不可进入
在满足年龄大于等于18岁的条件下,还增加了一个条件是否有钱,其中“年龄大于等于18岁”和“是否有钱”这两个条件的逻辑运算符=且,表示两个条件均需满足。
实际的计算过程中,第3、4两种条件下,对象年龄小于18岁的时候,就会造成短路运算,不会再去判断是否有钱。
所以,由上面这个例子可以得出,规则的本质其实就是在处理条件语句。理解了这个大前提之后,风控决策引擎设计上就已经了解了一大半了。
五、功能模块
了解完规则之后,我们来聊下有哪些具体的功能模块以及对应的设计。
风控决策引擎主要由特征管理、规则管理、规则集管理、评分卡管理、决策流管理和历史决策管理组成,在此之上可能迭代出其他模块,但是我是觉得这几个模块是从0开始必须的。
1. 特征管理
系统中的所有基础特征都是需要进行定义的,因此再提交开发之前需要将特征的取值和计算逻辑和开发沟通清楚。在基础特征之外,系统可设计对应衍生特征的简单配置,比如加减乘除、最大、最小值之类的,可以在前端提供给也业务方使用,减少开发的工作量。
在特征管理中着重说明下特征类型和特征来源这两个字段。
a)特征类型
在上文中也说明了每个特征都是有具体的类型的,我在处理的时候做了一层归集,减少了类型数,分为了数值型、枚举型和字符串型。
其中数值型又拆分成普通数值型和汇总数值型,二者主要区别是不同时间维度下的是否存在不同的统计值,最终体现在前端的是是否有时间维度的选择 。
例如“年龄”,年龄的具体数字根据规则执行节点的年月日和出生日期的差值计算得出,在不同的时间维度下年龄是不会有区别的(比如近3个月),所以年龄属于普通数值型;而“月均收入”是根据计算月份的总收入/计算总月份计算得出,所以不同时间维度下是有区别的(比如近3个月和近6个月)。
另外不同类型的特征也绑定了特定的运算符,这样在规则配置的时候也会更简洁点。
- 数值型:绑定了大于、大于等于、小于、小于等于、等于等运算符,阈值需要是数值。
- 枚举型:绑定了在集合内、不再集合内的运算符,阈值需要是一个集合。
- 字符串型:绑定了等于、不等于、在集合内、不在集合内等运算符,阈值需要是一个字符串。
具体的比较运算符的绑定,可以采取先配置基础的运算符,然后根据实际的业务需求再做加法。
b)特征来源
同一个特征,可能会对接不同数据供应商(成本考虑)。比如企业法人信息变更,就可能来自两个不同的供应商,那么,就需要根据特征来源对供应商进行判断。
2. 规则管理
了解规则是由特征、逻辑运算符、比较运算符、阈值和触发结果组成,以及规则其实是在处理条件语句的本质之后,那么前端设计就万变不离其宗了。
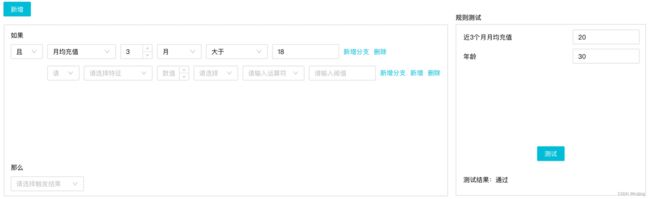
上图就是规则管理的部分页面内容,其中比较重要的功能是规则测试。规则测试主要面向对象是业务和测试人员。
- 业务人员:能够就配置的规则,立马知道规则执行是否有问题。
- 测试人员:上文说过特征来源可能是自有数据,也有可能是供应商的数据。规则的测试分为取值正确性和规则逻辑性验证。规则测试主要解决规则逻辑性验证,确定好这部分正确后,就可着重对取值进行验证,在规则的验证过程中有的放矢。
另外在触发结果上,一般是有“通过”、“拒绝”、“记录”、“转人工”等选择。因为规则设计都是顺序执行,所以在遇到“拒绝”结果上,整条规则就会中断执行并输出结果;“记录”结果可以认为是一个中性结果,用作规则调试;“转人工”结果就会将案件转人工,由人工介入二次审批。
触发结果除了上述的结果,还有可能输出某一变量的值。比如输出的是“会员等级”这一变量值,根据具体的规则输出金牌、银牌、铜牌这个变量值。
触发结果有哪些、形式是怎样以及对应的逻辑处理,读者可根据实际的业务背景进行定义。
3. 规则集管理
规则集是将多条规则组合成一条规则集合,其本质上还是在执行规则。下图是规则集配置的部分前端页面:
因为规则集也是顺序执行,并且包含了多条规则,在设计上可以加上一些快速变更执行规则顺序的操作。
另外,类似的还有规则表和规则树。
a)规则表

规则表由条件列和结果列构成,上图中的贷款主体变更次数和欠缴费总金额为条件列,最右侧的触发结果为结果列,总共规则数为两个条件列的乘积。
b)规则树

规则树的设计上是按照横向的树叶分支结构。
所以,从上面的额介绍可以得出规则集、规则表和规则树都是规则的聚合,本质上都是在执行规则。
但是在使用体验上还是有差异的:
- 规则集:规则复用性高,可以复用已经配置好的规则;
- 规则表:可以额外增加一些表格导入规则的操作;
- 规则树:树状结构使用上我觉得是最直观的。
4. 评分卡管理
评分卡本质上也是一种规则的变体,在规则中输出的是一个是否通过的结果,而评分卡输出的是一个分数结果。例如针对“年收入”这个特征,可能设置的评分卡如下:
- 年收入小于5万,得10分
- 年收入大于等于5万,小于20万,得20分
- 年收入大于等于20万,得30分
这个例子就是一个评分卡,理解了这个例子就理解了评分卡。

上图是评分卡管理部分的前端页面,其中不同的特征维度之间可能还会有「权重」的设置,比如年收入相较于年龄,设置的权重要更高点,在这样的业务背景下,前端就需要有配置的权重的功能。点击「设置权重」,展示对应权重列,可对某一特征进行设置权重值。那么,最终的评分=特征评分1*权重值1+特征评分2*权重值2+…
在设计评分卡的过程中,要着重注意缺失值 的处理,也就是要有个兜底的区间,保证对应的条件都能取到分值。
5. 决策流管理
决策流类似工作流,能将规则、规则集、评分卡编排,实现一个较大的业务决策流程。
决策流由开始、规则节点、决策和结束构成。规则节点包含规则、规则集和评分卡等工具。
决策就是拿着上一个规则节点的结果进行判断,是选择结束,还是去往下一个规则节点。

6. 历史决策管理
历史决策管理中主要管理决策引擎中的历史决策,可查看历史决策的执行路径、明细和结果。

上图是历史决策详情的部分前端页面,针对历史决策,还需要有重新执行、决策回溯之类的操作,以满足业务需要。
- 重新执行:在进行决策时,会调用大量的内外部接口进行计算,计算的过程中可能会接口错误导致决策停止,针对异常情况,需要有对应的重新执行的操作。
- 决策回溯:业务是动态变化的,因此针对历史的决策,能回溯重测。
六、贷前应用场景
a)决策模型及规则介绍
贷前模型:
预授信:常使用模型或者评分卡。通常用于白名单营销,在我对接的资金方中,网商和京东有采取预授信,通过主体的基础信息和经营信息,可以预授信出对应的额度,可用于白名单营销。正式进件之后,会再执行准入、反欺诈之类的策略。
准入:常使用规则。一般使用平台自有数据、工商数据、司法数据、纳税数据、发票数据、多头借贷数据。
- 平台自有数据:年龄、加盟商状态、加盟时长、发货数量、充值金额…
- 工商数据:成立年限、经营状态、法人变更、股东变更…
- 司法数据:被列入失信被执行人、限高、被执行案件数量…
- 纳税数据:纳税年限、纳税登记水平、欠缴税金额….
- 发票数据:开票月份数、最近一次开票月份距今、开票金额…
- 多头借贷数据:不同时间纬度下的平台申请数、非银机构逾期记录、非银机构申请数…
反欺诈:常使用规则和评分卡。一般使用平台自有数据、运营商数据。
- 平台自有数据:三要素/四要素、在网异常、入网时间…
- 运营商数据:提交时间异常、MAC值变化情况…
授信评级:常使用评分卡。
定额定价:常使用评分卡。
模型的使用不同机构间可能不同,以实际业务为准。
b)数据使用原则(主打一个降本~)
- 优先使用自有数据源:对于同一个特征可能自有和外部供应商都能提供接口查询,应该优先使用自有数据源。
- 优先使用低成本数据源:对于同一个特征,可能有多个外部供应商提供接口查询,在选择时应该选择费用较低的数据源。
- 外部数据及时入库:外部供应商的数据接口查询一般分为查询和查得两种,针对请求回来的供应商的数据要及时入库,在一定周期内是可以重复使用的,避免重复调用供应商接口产生不必要的费用。