docker-compose观察实时日志_Flink方案 | 基于 Flink SQL CDC 的实时数据同步方案
传统数据同步方案
基于 Flink SQL CDC 的数据同步方案(Demo)
Flink SQL CDC 的更多应用场景
Flink SQL CDC 的未来规划
直播回顾:
https://www.bilibili.com/video/BV1zt4y1D7kt/
传统的数据同步方案与
Flink SQL CDC 解决方案
业务系统经常会遇到需要更新数据到多个存储的需求。例如:一个订单系统刚刚开始只需要写入数据库即可完成业务使用。某天 BI 团队期望对数据库做全文索引,于是我们同时要写多一份数据到 ES 中,改造后一段时间,又有需求需要写入到 Redis 缓存中。
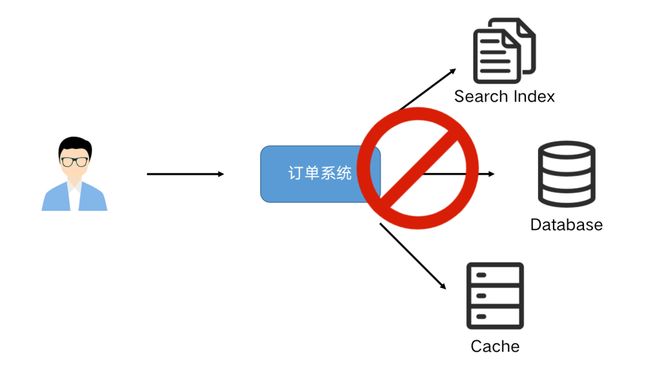

Flink SQL CDC 数据同步与原理解析
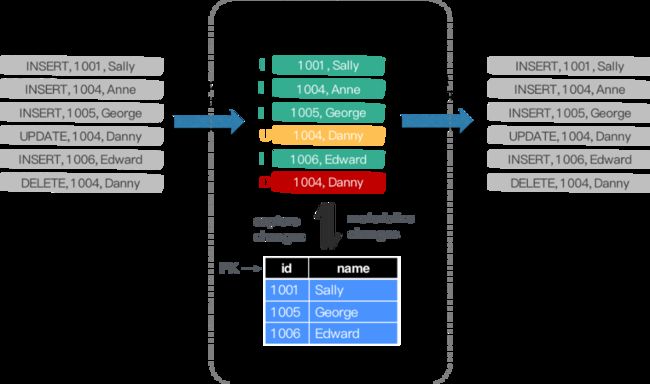
CDC 全称是 Change Data Capture ,它是一个比较广义的概念,只要能捕获变更的数据,我们都可以称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。| 基于查询的 CDC | 基于日志的 CDC | |
| 概念 | 每次捕获变更发起 Select 查询进行全表扫描,过滤出查询之间变更的数据 | 读取数据存储系统的 log ,例如 MySQL 里面的 binlog持续监控 |
| 开源产品 | Sqoop, Kafka JDBC Source | Canal, Maxwell, Debezium |
| 执行模式 | Batch | Streaming |
| 捕获所有数据的变化 | ❌ | ✅ |
| 低延迟,不增加数据库负载 | ❌ | ✅ |
| 不侵入业务(LastUpdated字段) | ❌ | ✅ |
| 捕获删除事件和旧记录的状态 | ❌ | ✅ |
| 捕获旧记录的状态 | ❌ | ✅ |
- 能够捕获所有数据的变化,捕获完整的变更记录。在异地容灾,数据备份等场景中得到广泛应用,如果是基于查询的 CDC 有可能导致两次查询的中间一部分数据丢失
- 每次 DML 操作均有记录无需像查询 CDC 这样发起全表扫描进行过滤,拥有更高的效率和性能,具有低延迟,不增加数据库负载的优势
- 无需入侵业务,业务解耦,无需更改业务模型
- 捕获删除事件和捕获旧记录的状态,在查询 CDC 中,周期的查询无法感知中间数据是否删除


选择 Flink 作为 ETL 工具
当选择 Flink 作为 ETL 工具时,在数据同步场景,如下图同步结构: 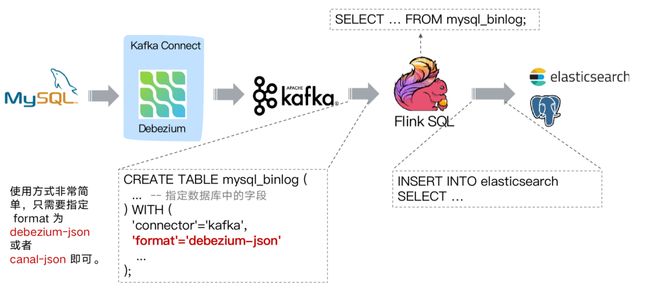

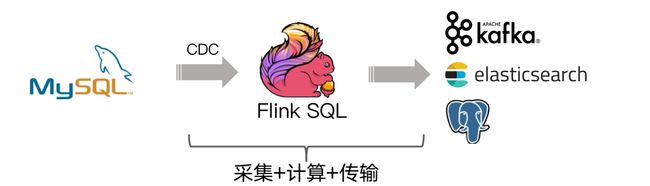
https://github.com/ververica/flink-cdc-connectorsflink-cdc-connectors 可以用来替换 Debezium+Kafka 的数据采集模块,从而实现 Flink SQL 采集+计算+传输(ETL)一体化,这样做的优点有以下:
- 开箱即用,简单易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯*
基于 Flink SQL CDC 的
数据同步方案实践
下面给大家带来 3 个关于 Flink SQL + CDC 在实际场景中使用较多的案例。在完成实验时候,你需要 Docker、MySQL、Elasticsearch 等组件,具体请参考每个案例参考文档。
案例 1 : Flink SQL CDC + JDBC Connector
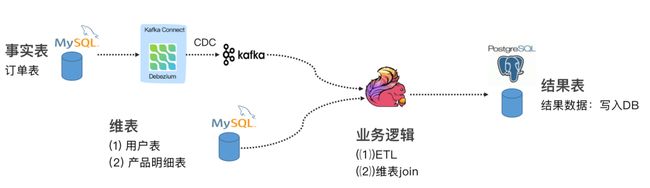
这个案例通过订阅我们订单表(事实表)数据,通过 Debezium 将 MySQL Binlog 发送至 Kafka,通过维表 Join 和 ETL 操作把结果输出至下游的 PG 数据库。具体可以参考 Flink 公众号文章:《Flink JDBC Connector:Flink 与数据库集成最佳实践》案例进行实践操作。https://www.bilibili.com/video/BV1bp4y1q78d
案例 2 : CDC Streaming ETL
模拟电商公司的订单表和物流表,需要对订单数据进行统计分析,对于不同的信息需要进行关联后续形成订单的大宽表后,交给下游的业务方使用 ES 做数据分析,这个案例演示了如何只依赖 Flink 不依赖其他组件,借助 Flink 强大的计算能力实时把 Binlog 的数据流关联一次并同步至 ES 。 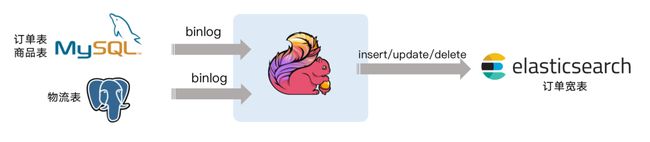
CREATE TABLE orders ( order_id INT, order_date TIMESTAMP(0), customer_name STRING, price DECIMAL(10, 5), product_id INT, order_status BOOLEAN) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'localhost', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'mydb', 'table-name' = 'orders');SELECT * FROM orders视频链接: https://www.bilibili.com/video/BV1zt4y1D7kt 文档教程: https://github.com/ververica/flink-cdc-connectors/wiki/中文教程
案例 3 : Streaming Changes to Kafka
下面案例就是对 GMV 进行天级别的全站统计。包含插入/更新/删除,只有付款的订单才能计算进入 GMV ,观察 GMV 值的变化 。 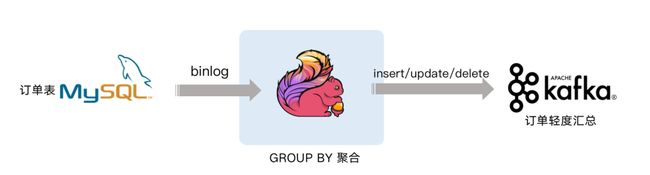
视频链接:
https://www.bilibili.com/video/BV1zt4y1D7kt
文档教程:
https://github.com/ververica/flink-cdc-connectors/wiki/中文教程
Flink SQL CDC 的更多应用场景
Flink SQL CDC 不仅可以灵活地应用于实时数据同步场景中,还可以打通更多的场景提供给用户选择。Flink 在数据同步场景中的灵活定位
- 如果你已经有 Debezium/Canal + Kafka 的采集层 (E),可以使用 Flink 作为计算层 (T) 和传输层 (L)
- 也可以用 Flink 替代 Debezium/Canal ,由 Flink 直接同步变更数据到 Kafka,Flink 统一 ETL 流程
- 如果不需要 Kafka 数据缓存,可以由 Flink 直接同步变更数据到目的地,Flink 统一 ETL 流程
Flink SQL CDC : 打通更多场景
- 实时数据同步,数据备份,数据迁移,数仓构建优势:丰富的上下游(E & L),强大的计算(T),易用的 API(SQL),流式计算低延迟
- 数据库之上的实时物化视图、流式数据分析
- 索引构建和实时维护
- 业务 cache 刷新
- 审计跟踪
- 微服务的解耦,读写分离
- 基于 CDC 的维表关联
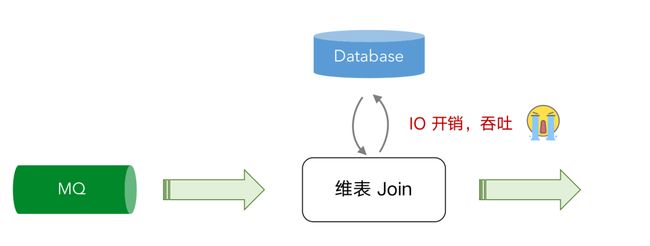
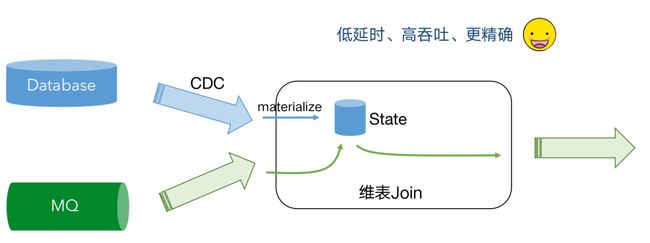
未来规划
- FLIP-132 :Temporal Table DDL(基于 CDC 的维表关联)
- Upsert 数据输出到 Kafka
- 更多的 CDC formats 支持(debezium-avro, OGG, Maxwell)
- 批模式支持处理 CDC 数据
- flink-cdc-connectors 支持更多数据库
总结
本文通过对比传统的数据同步方案与 Flink SQL CDC 方案分享了 Flink CDC 的优势,与此同时介绍了 CDC 分为日志型和查询型各自的实现原理。后续案例也演示了关于 Debezium 订阅 MySQL Binlog 的场景介绍,以及如何通过 flink-cdc-connectors 实现技术整合替代订阅组件。 除此之外,还详细讲解了 Flink CDC 在数据同步、物化视图、多机房备份等的场景,并重点讲解了社区未来规划的基于 CDC 维表关联对比传统维表关联的优势以及 CDC 组件工作 。 希望 通过这次分享,大家对 Flink SQL CDC 能有全新的认识和了解,在未来实际生产开发中,期望 Flink CDC 能带来更多开发的便捷和更丰富的使用场景。Q & A
1、GROUP BY 结果如何写到 Kafka ?
因为 group by 的结果是一个更新的结果,目前无法写入 append only 的消息队列中里面去。更新的结果写入 Kafka 中将在 1.12 版本中原生地支持。在 1.11 版本中,可以通过 flink-cdc-connectors 项目提供的 changelog-json format 来实现该功能,具体见文档。
文档链接:
https://github.com/ververica/flink-cdc-connectors/wiki/Changelog-JSON-Format
2、CDC 是否需要保证顺序化消费?
是的,数据同步到 kafka ,首先需要 kafka 在分区中保证有序,同一个 key 的变更数据需要打入到同一个 kafka 的分区里面。这样 flink 读取的时候才能保证顺序。 Flink Forward Asia 2020 官网上线啦 洞察先机,智见未来, Flink Forward Asia 2020 盛大开启!诚邀开源社区的各方力量与我们一起,探讨新型数字化技术下的未来趋势,共同打造 2020 年大数据领域的这场顶级盛会! 大会官网已上线,点击「 阅读原文 」即可预约峰会报名~
Flink Forward Asia 2020 官网上线啦 洞察先机,智见未来, Flink Forward Asia 2020 盛大开启!诚邀开源社区的各方力量与我们一起,探讨新型数字化技术下的未来趋势,共同打造 2020 年大数据领域的这场顶级盛会! 大会官网已上线,点击「 阅读原文 」即可预约峰会报名~  (点击可了解更多议题投递详情) 戳我报名!
(点击可了解更多议题投递详情) 戳我报名! 