新生赛题解大全(dp,bfs,dfs,二分,前缀和,高精度.......)
新生赛题解大全
(按照本菜狗心目中的难易顺序…)
一:题号:H
链接:https://ac.nowcoder.com/acm/contest/72175/H
题目描述
小猴有两个数a,b他想知道两个数相乘后末尾0的个数,快来编写代码帮帮他吧!
输入描述:
a b
数据范围:
0≤a,b≤10^4
输出描述:
输出答案
输入
50 2
输出
2
说明
50×2=100
有两个0,故答案为2.
解题代码:
#include 纯签到题,不做解释…
二:题号:I
链接:https://ac.nowcoder.com/acm/contest/72175/I
题目描述:
如题还是上一题的找0,但是
0≤a,b≤10^14
输入描述:
a b
输出描述:
输出答案
输入
30 50
输出
2
解题代码:
#include 高精度模板,以前发过了,就不解释了…
再补充一个办法:
#include 我们也可以不用使用高精度算法 我们只需查找 a, b 两数中有多少对 2 和 5 的因子,因为一对 2,5 因子相乘等 于 10. 也就是一对就一定有一个末尾0。
三:题号:M
链接:https://ac.nowcoder.com/acm/contest/72175/M
题目描述
WZ 学长最近迷恋上了泡养生茶,他买了枸杞,决明子,菊花,栀子,桑葚,桑叶,蒲公英,金银花,茯苓,人参… 某天他突发奇想,是不是把两杯液体重量一样的养生茶倒到其中一个杯子里面再喝下去,就会获得双倍的效果还能少喝一杯茶!(智慧的眼神)
说干就干!假设 WZ 学长一共有 n 杯养生茶,每个杯子无限大并且初始只有 1 升养生茶。WZ 学长每次只会把两杯质量一样的茶倒进其中一个杯子(别问我为什么要一样多),而他每次最多只愿喝 m 杯,那么他最少还需要再调配多少杯养生茶。
(放心如果要喝的养生茶超过 1 升,那么 WZ 就会把多的都送给 Jiejie 学长并且看着他喝完!)
输入描述:
输入第一行两个整数n和m,n 为 WZ 已有的养生茶杯数,m 为他愿意最多喝的养生茶数量
(0<m<n<100000000)
输出描述:
输出一行最少还需要再买多少杯
输入
3 1
输出
1
解题代码:
#include 题解:
利用一个栈,每次入栈时都判断一下是否可以合并,如果可以,就循环至不可合并的时候,最后比较栈的大小与给定杯数的差值,如果大,就输出0,如果小,就重复入栈的操作直至满足,在过程中记录操作次数就行。
四:题号:A
链接:https://ac.nowcoder.com/acm/contest/72175/A
题目描述
你得到一个正 N 边多边形。将任意一条边标记为边 1,然后按顺时针顺序将下一条边标记为边 2、3、N。在 i 侧有 Ai个特殊点。这些点的位置使得边 i 被分成长度相等的 Ai+1段。
您希望创建尽可能多的满足条件的三角形,同时满足以下要求。
- 每个三角形由 3 个不同的特殊点组成(不一定来自不同的边)作为它的角。
- 每个特殊点只能成为最多 1 个三角形的角。
- 所有的三角形不能互相相交。
请你数一数可以创建的满足条件的三角形的最大数量。
输入描述:
数据范围
3≤N≤200000 1≤Ai≤2⋅10^9
输出描述:
输出一个整数,表示可以创建的三角形的最大数量。
输入
4
3 1 4 6
输出
4
说明
例如样例一,有一个正四边形。假设最上面的一条边被标记为边 1,下图显示了当 A=[3,1,4,6]时特殊点如何位于每一边内及一种可行的方案
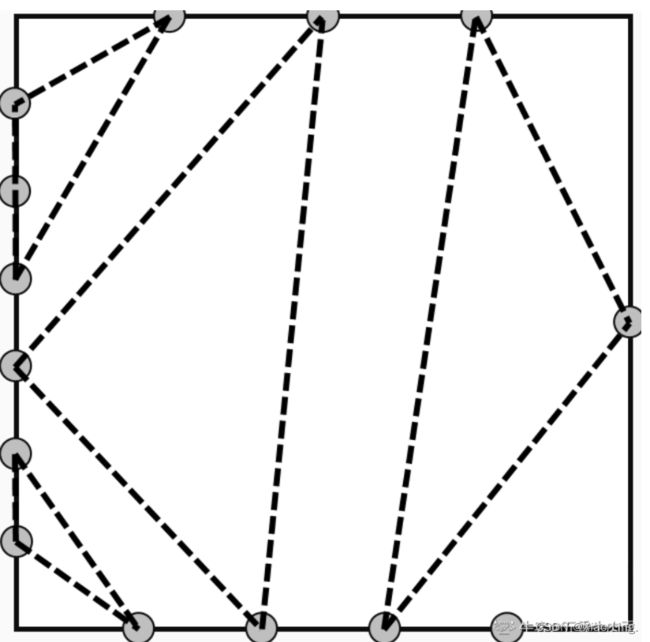
解题代码:
先来一个偷鸡版:
#include 是不是很神奇,但是好像又有点道理,每个点不能重复,那我直接用点的总数除以3不就好了,这好吗?这不好,因为要是所有点都在一条边上,那么答案一定是0,但是这种错误的解法居然能过,早知道比赛时试一下了,这都是ACM的错…
好,那来看看正式版:
#include 这个代码主要逻辑与第一种相似,但是多了一种处理方式,即当一条边特殊点的数量远远多于其他边的时候,这个时候只有除了这条边 之外的点 可以和这个边能构成三角形,构成的三角形个数是点的总数减去最多的那一条边上的点的数量,然后取这两种办法的最小值,比如,所有点都在一条边上,那么的总数减去最多的那一条边点的数量就是0,即是这种情况下的正确答案。
五:题号:B
链接:https://ac.nowcoder.com/acm/contest/72175/B
钟女士最近在备战六级,她在写好一篇作文后才发现自己的大小写做的一团糟,你能帮她统计批改大小写错误吗?
为了便于计算我们对大小写只做如下要求:
- 句子开头的第一个字母要大写
- 一个句子除了句首单词和“I (我)”,句中都不需要大写
- “I(我)”在句中任何位置都要大写
输入描述:
第一行n为单词个数,接下来为n个单词,每个单词以空格或回车隔开。
数据范围:1≤n≤1000
输出描述:
输出错误个数
输入
8
welcoMe To programming contest. wish you every success.
输出
4
说明
welcoMe w需要大写,M需要小写
To 处于一句话中需要小写
wish w是新一句话的开头需要大写
解题代码:
#include题解:
不是,这么简单一个题,考场上我没有做出来我是真的难崩,(主要是没看到还允许有换行)。
- 首先,程序从用户那里获取一个整数
n,这个整数表示将要输入的字符串的数量。 - 然后,程序进入一个循环,循环
n次。在每次循环中,程序都会获取一个字符串str。 - 对于每个输入的字符串,程序会检查以下几种情况:
- 如果字符串是"I"或"I.",或者是句子的开头(由
head变量表示),并且字符串的第一个字符是小写字母,那么ret就会增加1。 - 如果字符串是"i"或"i.",那么
ret就会增加1。 - 如果字符串的head为0且第一个字符是大写字母,那么
ret就会增加1。 - 对于字符串中的每个字符,如果它是大写字母,那么
ret就会增加1。
- 如果字符串是"I"或"I.",或者是句子的开头(由
- 如果字符串的最后一个字符是".",那么
head就会被设置为1,表示下一个字符串应该是句子的开头。 - 最后,程序会打印出
ret的值,也就是违反英文句子大小写规则的情况的总数。
好,现在开始加难度~
六:题号:D
链接:https://ac.nowcoder.com/acm/contest/72175/D
题目描述:
有两个长度相等的字符串 a,b,它们只包含字符 0 或 1; 两个字符串都以字符 0 开始,以字符 1 结束。
您可以执行以下操作任意次数(可能为零):
选择其中一个字符串和两个相同的字符; 然后将它们之间的所有字符替换为这个字符。
输入描述:
T为测试用例数量,每个测试用例由 a,b两行组成
a,b都以字符 0 开始,以字符 1 结束
数据范围
2≤∣a∣=∣b∣≤5 0002,1≤T≤2 000
∑T(i=1)∣ai∣≤50 000
输出描述:
对于每个测试用例,如果可以使两个字符串相等,则打印YES否则,打印NO。
输入
7
01010001
01110101
01001
01001
000101
010111
00001
01111
011
001
001001
011011
010001
011011
输出
YES
YES
YES
NO
NO
NO
YES
解题代码:
#include题解:
如果答案是 YES ,那么我们总能把两个字符串都变成 00…01…11 的形式,比如,对于其中的一个字符串,我们知道给定的字符串一定是有0在左,有1在右,如果其中不含任何一个0,或者不含任何一个1,那么他已经是000…01…11的形式,而中间只要存在01这样的子串,假如0是第n个,那么我们可以把1-n全部变成0,n+1到最后一个1全部变成1,而两个字符串相等,那么一定可以都变成00…01…11 的形式,所以我们只需要找是否存在这样的同下标的01字串就xin。
七:题号:C
链接:https://ac.nowcoder.com/acm/contest/72175/C
题目描述
给你一个长度为 N,仅包含小写字母的字符串 s,现要求你回答 Q 个询问:
- 每个询问给出一对整数 l,r,由 slsl+1⋯sr−1sr构成的字符串中,包含多少个子串为 ‘‘acm"。

输入描述:
数据范围:
2≤N≤10^6
1≤Q≤10^6
0≤l<r<N
注意:数据输入量可能过大,请使用更快的读入方式。对于 C++,请在调用 std::cin 前加入如下两行代码:
std::cin.tie(0);
std::ios::sync_with_stdio(0);
输出描述:
输出 Q 行,第 i 行表示第 i 个询问的答案。
输入
7 2
swpuacm
0 4
4 6
输出
0
1
解题代码:
#include 题解:
首先,其实上面的题解是错误的,but我不认为他有错,因为让我们来看看正确的题解:
#include 发现区别了吗,正确的仅仅比错误的少了一个优化:
if(r-l<2){
printf("0\n");
}
但是,我就纳闷了,对于一个询问,我们知道acm长度为3,那么如果右边界减去左边界小于2的话,那不一定就是0吗,不明白,真的不明白…
本题主要是运用了前缀和的算法,记录从第一个字符到最后一个字符其中第n个字符之前已经出现了多少acm,这样查询区间时,用右边减去左边就行,比如,它的储存可能是0 0 1 1 1 1 2,即对应字符串acmkacm,这样对于输入的一个询问,例如,2,6,就可以快速相减得到答案,就是2-1=1,注意本题是如何处理边界条件,减去的是ans[l+1],因为如果输入1,6,那么直接减去答案是2,而事实上答案应该是1,而对于a,反正+1也是c,而c也是0,不影响正确答案。
八:题号:J
链接:https://ac.nowcoder.com/acm/contest/72175/J
题目描述
WZ 最近迷恋上了塔防益智小游戏,目标是尽可能多的净化敌方的区域,整个地图由“*”构成,敌方的地盘用“#”表示。每块敌方的地区 WZ 都需要派遣一位白骑士去净化,但是敌方为了保护自己的地盘建立了多个碉堡,每个碉堡用“!”表示。WZ 只能攻占一片敌方的区域,而这片区域每拥有一个碉堡 WZ 就需要多派一个白骑士去净化。问 WZ 想要尽可能多的净化敌方区域至少需要派遣多少个白骑士。
输入描述:
第一行,输入两个整数 n 和 m 代表整张地图的大小
接下来 n 行,每行将输入 m 个字符代表当前位置情况
1≤n,m≤500
输出描述:
x 代表 WZ 可以占领的敌方区域大小,y 代表 WZ 至少需要派遣多少个白骑士
输入
4 4
#!**
!#**
*#*#
*#*!
输出
6 8
解题代码:
#include 题解:
标标准准的bfs,有点类似染色法,都这个不一样,他可能从内部某个点开始,所以只需要暴力从第一个点遍历一次就行,而事实上,对于state数组的状态,不需要回溯,因为本题是清扫一片区域,因此是一个连通图,对于最大范围中的每个点,彼此相互可达,所以没有必要再走一遍,而我们为了不走到其他的区域,我们把*视为障碍即可。最后把每一个连通区域都走一次,比较出最大值就行。
九:题号:K
链接:https://ac.nowcoder.com/acm/contest/72175/K
题目描述
WZ 最近想要学卷积神经网络了!但是因为这是他第一次做这种项目,于是乎,,,一个拥有数不清 bug 的屎山就诞生了! 虽心有余想要全部删了重构,然而项目就快要结题了,只好央求我们英俊潇洒风流倜傥的 Jiejie 学长来挽救于危难之间。Jiejie 虽然看不懂问题到底出在了哪里,但他发现 WZ 的 bug 出现的很有规律,每个 bug 只会影响当前行的代码,为了 debug 的舒服他决定数行数行的进行修改。于是他决定帮 WZ 重构 mmm 个片段(即从一个 bug 到另一个 bug 算一个片段),于是想问 Jiejie 学长最少需要重构多少行代码。
输入描述:
第一行输入代码总长度 x 和 n 个 bug 以及 Jiejie 愿意重构 m 个片段数
第二行一共有 n 个数字代表每个 bug 的位置
数据范围:
1≤ai≤x1
1≤x,n,m≤10000
输出描述:
Jiejie 学长最少需要更改的行数
输入
11 5 2
2 4 6 9 10
输出
5
说明
对于样例的一些解释:即2到4需要改4-2行代码,4到6需要改2行代码,6到9需要改3行代码,9到10需要改1行代码,因此为了尽可能少的修改,删去6到9的3行,改2+2+1=5行。
解题代码:
#include 题解:
将所有 bug 的位置进行排序后,求出每两个 bug 差即为 需要修改的行数。因为需要修改的段落尽可能的少,所以再次进行排序后从修 改行数第 m+1 多的位置开始累加即为答案。
难度又增加了哦…
十:题号:E
链接:https://ac.nowcoder.com/acm/contest/72175/E
题目描述
我们有一个盒子,初始时是空的。 让我们按照输入中给出的顺序执行以下两种类型的一共Q操作。
x 类型1:向盒子里放入一个写有整数x的球。
x 类型2:从盒子里取出一个写有整数x的球。 保证在执行操作前盒子里已经有一个写有整数x的球。
对于每次操作后的盒子,解决以下问题。
找到从盒子里取出一些球整数之和为K的方案数,模998244353。 盒子里所有的球都是可以区分的。
输入描述:
所有输入值都是整数。
1≤Q≤5000 1≤K≤5000
对于每种类型的操作
- x 表示从盒子取出一个x小球
+ x 表示从盒子加入一个x小球
1≤x≤5000
所有的操作都满足问题陈述中的条件。
输出描述:
盒子里取出一些球整数之和为K的方案数%998244353
输入
15 10
+ 5
+ 2
+ 3
- 2
+ 5
+ 10
- 3
+ 1
+ 3
+ 3
- 5
+ 1
+ 7
+ 4
- 3
输出
0
0
1
0
1
2
2
2
2
2
1
3
5
8
5
解题代码:
#include
#include
const int mod = 998244353;
using namespace std;
int main() {
long long int n, k;
cin >> n >> k;
vectordp(k + 1);
dp[0] = 1;
while (n--) {
char c;
cin>>c;
int ball;
cin>>ball;
if (c == '-') {
for (int i = ball; i <= k; i++) {
(dp[i] -= dp[i - ball]) %= mod;
}
}
else {
for (int i = k; i >= ball; i--) {
(dp[i] += dp[i - ball]) %= mod;
}
}
cout << (dp[k] + mod) % mod << endl;
}
return 0;
}
题解:
我们定义一个数组dp,其中dp[i]表示整数之和为i的方案数。初始时,dp[0]为1,表示没有取出任何球的方案数为1。
然后,对于每一个操作,我们都会更新dp数组:
- 如果操作是向盒子里放入一个写有整数
x的球,我们就需要更新dp[j+x],其中j从k-x到0。这是因为,现在我们有了一个新的球,可以用来组成新的整数之和。所以,对于所有小于或等于k-x的j,我们都可以通过在原来的方案中加上这个新的球,得到一个整数之和为j+x的新方案。因此,我们需要将dp[j]加到dp[j+x]上。 - 如果操作是从盒子里取出一个写有整数
x的球,我们就需要更新dp[j],其中j从x到k。这是因为,我们失去了一个可以用来组成整数之和的球。所以,对于所有大于或等于x的j,我们都需要从dp[j]中减去那些包含这个球的方案。因此,我们需要将dp[j-x]从dp[j]中减去。
最后,dp[k]就是我们想要的答案,即从盒子里取出一些球,使得这些球的整数之和为K的所有可能方案数。
来看看更容易理解的题解:
比如这个球的大小是100,然后我们想要找到组合为20的情况,对于20到100的区间,我们压根不需要更新,因为这个100完全影响不了取出的总和是20的情况,而如果这个球是10,那我们也不用考虑,从0到10的所有情况,因为组合为0到10,这个球一定也没有参与,所以我们只用更新10到20的情况,而对于10到20这一个区间,我们如何做到更新呢?我们可以很容易的知道,我们需要达成一个等式,该等式满足,更新前为k的方案总和等于不加这个球的方案总和加上这个球参与的方案总和,而我们可以想得到,不加这个球的方案组合,那就做减法,减去所有包含这个球的和为k的方案数就行。我们可以举个例子,对于区间内构成16的方案总和,我们现在移除了一个球6,我们原本得到16的方案,如果6号球一定要参与的话,那么它就会关联到构成方案为10的情况,所以对于16移除6的操作,我们就让他减去构成为10的方案就行。例如,有四个球,6,10,5,5原本有两种方法构成16,现在移除了6,那么,原本需要构成16的10的方案组合,全都无效了,就要减去dp[10],同理,对于加进来一个球,那么我们也只需要更正,从那个球到目标值k之间的情况,并且相反操作就行了。
十一:题号:L
链接:https://ac.nowcoder.com/acm/contest/72175/L
题目描述
给定一个网格,某机器人从网格的左上角出发,它只能向下走或向右走。机器人很傻,它只会遵循设定好的策略,严格按照某种概率来决定往哪个方向走。比如在样例中的起点位置,机器人有0.3的概率向下走,有0.7的概率向右走。每个网格有一定的价值,机器人每到达一个网格可以收割该网格的价值。现在问你,机器人从出发到离开网格,它能收割价值的期望是多少?
输入描述:
第一行输入正整数n, m代表网格是n行m列的
接下来n行,每行输入m个整数,对于每个整数v,它代表每个网格的价值
接下来n行,每行输入m个整数,对于每个整数p,它代表机器人在该网格向下走的概率是p / 100
输出描述:
输出共一行,输出机器人能收割价值的期望,四舍五入保留到整数
1≤n,m≤1000
0≤v≤1000
0≤p≤1000
对于任意一个网格,机器人向下走的概率和向右走的概率之和为1
输入
2 2
15 7
21 99
30 10
50 40
输出
48
说明
一共有六种可能的路径:
15 -> 7 -> right,这条路径的价值为15 + 7 = 22,概率为0.7 * 0.9 = 0.63
15 -> 7 -> 99 -> right,这条路径的价值为15 + 7 + 99 = 121,概率为0.7 * 0.1 * 0.4 = 0.028
15 -> 7 -> 99 -> down,这条路径的价值为15 + 7 + 99 = 121,概率为0.7 * 0.1 * 0.6 = 0.042
15 -> 21 -> down,这条路径的价值为15 + 21 = 36,概率为0.3 * 0.5 = 0.15
15 -> 21 -> 99 -> down,这条路径的价值为15 + 21 + 99 = 135,概率为0.3 * 0.5 * 0.4 = 0.06
15 -> 21 -> 99 -> right,这条路径的价值为15 + 21 + 99 = 135,概率为0.3 * 0.5 * 0.6 = 0.09
所以期望 = 22 * 0.63 + 121 * 0.028 + 121 * 0.042 + 36 * 0.15 + 135 * 0.06 + 135 * 0.09 = 47.98
解题代码:
#include题解:
dfs超时,bfs超空间,只能用dp来做了,我是真讨厌dp啊
对于目标期望,我们选择从最后一点往前计算,这样不会覆盖掉前面的值,对于每个点 (i, j),我们有两种可能的移动方式:向右和向下。如果我们向右移动,那么我们会加上 dp[i][j+1] * (1 - parr[i][j] / 100.0) 到 dp[i][j]。这个表达式的含义是,如果我们向右移动,那么我们会到达点 (i, j+1),从这个点到终点的所有可能路径的期望之和是 dp[i][j+1],而向右移动的概率是 1 - parr[i][j] / 100.0,所以我们需要将 dp[i][j+1] 乘以这个概率。同理,如果我们向下移动,我们需要将 dp[i+1][j] * (parr[i][j] / 100.0) 加到 dp[i][j]。最后,我们需要加上当前点的值 values[i][j],因为无论我们选择哪种移动方式,我们都会经过当前点。而仔细观察我们可以发现,我们可以把二维数组开的大一些,并把点之外的值设置为0,这样就可以合并两种情况,反正为期望0,不会影响到那一部分的计算。而为什么要加上values[i][j],很简单,对于每一步,他只存在两种走法,且都会经过它本身,所以对于该点,它的概率为1,期望就是它本身。
好好好,接下来就是最难的两个题了:
十二:题号:F
链接:https://ac.nowcoder.com/acm/contest/72175/F
题目描述
给定N个在二维平面上的不同点。第i个点(1≤i≤N)的坐标为(xi, yi)。
我们定义两点i和j之间的距离为min(∣xi−xj∣,∣yi−yj∣):x坐标和y坐标差值中的较小者。
找出两个不同点之间的最大距离。
输入描述:
2≤N≤200000
0≤xi,yi≤10^9
(xi,yi) ≠ (xj,yj) (i≠j)
所有输入值都是整数。
输出描述:
打印两个不同点之间的最大距离。
输入
3
0 3
3 1
4 10
输出
4
解题代码:
#include 题解:
struct pos:定义了一个结构体来表示点,包含x和y两个坐标。compare函数:这是一个比较函数,用于sort函数。它比较两个点的x坐标,如果点a的x坐标小于点b的x坐标,就返回true。check(int mid):这个函数用于检查是否存在两个点,它们之间的距离大于或等于mid。函数首先初始化最小值mmin和最大值mmax,然后遍历所有的点。对于每一个点,它会检查是否存在一个j(j < i),使得all[i].x - all[j].x >= mid。如果存在,那么就更新mmin和mmax,并且检查all[i].y - mmin >= mid或者mmax - all[i].y >= mid是否成立。如果成立,那么就返回false,否则继续检查下一个点。main():主函数首先读入点的数量n,然后读入每一个点的坐标。接着,它会根据x坐标对所有的点进行排序。然后,使用二分查找的方法来找出最大的距离。具体来说,它会不断地取中间值mid,并使用check(mid)来检查是否存在两个点,它们之间的距离大于或等于mid。如果存在,那么就更新右边界r,否则就更新左边界l。最后,输出左边界l,这就是两个不同点之间的最大距离。
下面是一些更通俗的解释:
首先是main函数之间的while循环,因为我们知道所有点的x坐标和y坐标都是大于零的,并且所有点的x坐标和y坐标都是小于10的9次方,所以最大距离不会超过十的9次方,那么,这个while循环事实上是对最大距离的一个循环,通过每次二分距离,然后使用check函数,如果中间值mid的,满足最大值的情况,那么,此时我们也不能确定这个mid的就是最大值,我们就要继续检查左边界到mid的这一个区间,如果不满足,说明还不够大,我们就要检查mid的到右边界r这一个区间,一直循环,直到l和r相等。
而对于check函数,它的逻辑如下,类似于暴力的遍历,首先外面一个i的for循环,从0循环到n,然后定义一个j,从0循环到i,再定义mmin,mmax,并且初始化为最大最小值为理论上不可能的最大最小值,如果j小于i,并且他们之间的x距离要大于中间值,开始进入循环,并且对最大最小值赋值,注意这个循环中的最大最小值指的是y轴的最大最小值,因为本题的逻辑是,两点之间的距离为x轴距离和y轴距离之间的最小值,所以不但要求x轴之间的距离要大于mid,并且y轴之间的距离也要大于mid,才能说明mid找小了,如果成功大于说明mid不够小,返回假,否则返回真。
本题的优化为i,j的x坐标之差,注意,我们已经对结构体数组进行了按照x从小到大的排序,所以在每一次i循环中,j首先是为0的,而j要遍历到i,所以第一次相减就是他们x之间差的最大值,如果连第一次都不会大于中间值,那么后面的一定不会大于中间值,所以就直接进行下一轮循环,其次,因为最大最小值被初始化为了理论不可能的最大最小值,所以如果不会进入内层的while循环,那么相减一定是不可能大于mid的,也就是一定是不可能返回false的。最后直接输出l或者r就行。
十三:题号:G
链接:https://ac.nowcoder.com/acm/contest/72175/G
题目描述
给出一个长度为n的a数组 你有k次机会可以对其中任一元素±1 问最长的公差为114514的等差数列长度
输入描述:
n为数组长度,k为机会次数,ai为长度为n的数组中的元素1≤n≤2×10^5
0≤k≤10^15
0≤ai≤10^9
输出描述:
一个数 表示能找到公差为114514的等差数列的最长长度
输入
7 572570
7 2 5 5 4 11 7
输出
4
这个题我只能说,我确实是做不出来,索性就直接把学长的代码放在这里了…我是真的菜啊,晕死
大佬代码:
#include 下面是这个程序的主要部分的解释:
-
数据结构:这个程序使用了一个名为
node的结构体来存储线段树的节点信息,包括左端点l,右端点r,区间和v和区间内元素个数cnt。线段树是一种用于存储区间或线段信息的数据结构,可以高效地进行区间查询和更新操作。 -
预处理:在
solve函数中,首先读入数组的长度n和可以改变的次数m,然后读入数组a。接着,对数组a进行预处理,将每个元素减去其下标,然后将处理后的元素存入一个映射mp中。 -
构建线段树:然后,构建线段树,用于存储数组中的元素信息。
-
主循环:在主循环中,遍历数组中的每个元素,对每个元素进行查询和修改操作,以找出最长的满足条件的等差数列长度。具体来说,对于每个元素,首先将其加入线段树,然后查询线段树中的信息,如果满足条件(即改变元素的次数不超过
m),则更新答案,否则将元素从线段树中移除。 -
输出结果:最后,输出找到的最长等差数列的长度。
这个题解的关键思想是将原问题转化为寻找最长的公差为0的等差数列,然后利用线段树进行高效的区间查询和更新操作。
原问题是寻找最长的公差为114514的等差数列,但是如果直接解决这个问题可能会比较复杂。因此,题解首先对数组进行预处理,将每个元素减去其下标,这样就将原问题转化为寻找最长的公差为0的等差数列。这样做的好处是,公差为0的等差数列就是所有元素都相等的序列,这样就可以利用线段树进行高效的查询和更新操作。