14、加州大学圣地亚哥分校、微软公司共同提出:SCHEME Former Backbone 位于孤山之巅的阿肯宝钻
本文由加州大学圣地亚哥分校和美国微软公司于2023年12月1日,在《Computer Science 》期刊上发表,学校和公司已是如雷贯耳,在此不多介绍,老样子,我先对文章模型做一个简单的解说,占个首创位置。
两家单位共同提出一种可扩展通道混合器(SCHEME),可以插到任何的ViT构架中(注意是任何昂!!),原论文及我个人浅显解读如下:

论文链接:[2312.00412] SCHEME: Scalable Channer Mixer for Vision Transformers (arxiv.org)
0、Abstract:
视觉 Transformer (Vision Transformers)因其出色地在许多视觉任务上的表现而受到了广泛关注。尽管 Token 混合器或注意力模块已经得到了深入的研究,但通道混合器或特征混合模块(FFN或MLP)尚未被深入研究,尽管它占模型参数和计算的大部分。
在本工作中,作者研究了稀疏特征混合是否可以取代密集连接,并确认了这一点,使用改进了准确性的块对角MLP结构,该结构支持更大的扩展比。为了进一步改善由这种结构形成的特征簇,从而进一步提高准确率,引入了一种轻量级、无参数、通道协方差注意力(CCA)机制作为训练期间的并行分支。这种CCA机制的设计使得在训练期间可以逐渐混合通道组中的特征,其贡献随着训练的进行而衰减到零。这使得在推理时可以丢弃CCA块,从而实现无需额外计算成本的增强性能。
可扩展通道混合器(SCHEME)可以插到任何ViT架构中,以获得在复杂性和性能之间具有不同权衡的各种模型。通过控制MLP中的块对角结构大小,实现这一目标。这通过引入一组新的SCHEME-former模型得到证明。
作者使用不同的ViT Backbone 进行图像分类、目标检测和语义分割的实验,实验结果始终显示出相对于现有设计的显著准确率提升,特别是在低FLOPs的范围内。例如,SCHEME-former在ImageNet-1K上使用纯注意力混合器,在1.77G FLOPs下建立了新的SOTA,即79.7%的准确率。
1、Introduction
近年来,视觉 Transformer (ViTs)已在计算机视觉领域变得无处不在。在这种架构下,一张图像被分解成一组patch,这些patch被视为token,并输入到一个由两个主要组成部分组成的 Transformer 模型:一个_空间注意力_模块,该模块根据每个token与其他从图像中提取的token的相似度重新加权每个token,从而实现信息融合,跨越大型空间距离;一个_通道混合器_,它使用多层感知器(MLP或FFN)将所有patch提取的特征通道组合在一起。这种模型的瓶颈是注意力机制在patch数量上的二次复杂度。
近年来,为了提高复杂性和/或准确率,提出了许多ViT变体。这些可以分为
-
改进的注意力机制
-
替换注意力或将其与卷积相结合的混合架构
关于通道混合器的研究较少。大多数模型简单地采用MLP块,该块由两个层组成,其中通道首先通过指定的_扩展比例_进行扩展,然后压缩到原始尺寸。这有点令人惊讶,因为混合器对好的 Transformer 性能至关重要。例如,Dong等人[14]表明,没有MLP或残差连接的纯注意力会以指数级别双倍衰减到秩一矩阵。Yu等人[57]也表明,如果没有残差连接或MLP,模型无法收敛。DaViT表明,用更多计算复杂性相当的注意力块(空间和通道注意力)替换MLP,可以降低 Transformer 精度。这些观察表明,通道混合器是ViTs不可或缺的组成部分。
在本工作中,作者研究了通道混合器模块,旨在量化其对ViT性能的贡献,并提高 Transformer 模型复杂性与准确性权衡。作者首先研究了混合器中执行的通道扩展的影响,通过改变其扩展比例。结果表明,当扩展比例超过8时,Transformer性能增加,直到达到饱和。然而,由于混合器(MLP)在中间表示维数上的复杂性为线性,当扩展比例大于4时,使用大于4的扩展比例进行通道扩展会导致参数和计算的爆炸,从而导致复杂度过高的模型和容易过拟合。
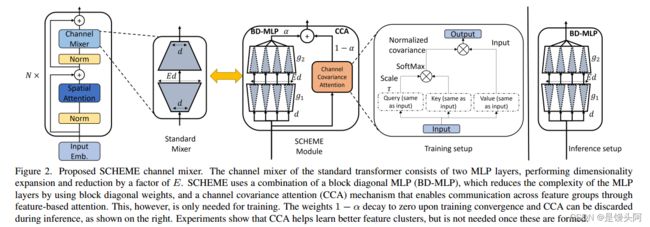
为了在维数和计算之间实现更好的权衡,作者寻求利用具有块对角结构的硬件高效的混合器。这包括将网络层输入和输出特征向量分解为不重叠的组,并在每个组内仅执行矩阵乘法,如图2所示。作者称 resulting MLP 块为 块对角 MLP (BD-MLP)。尽管不同组之间没有特征混合,但作者发现,配备 BD-MLP 和较大扩展比例(以匹配参数计数和计算)的 Transformer 模型与基线(使用密集 MLP)相比,可以达到可比或略高的准确性。这表明,稀疏块对角操作的较低准确性被较大扩展比例的收益所抵消。进一步分析 BD-MLP 学习到的不同组的特征,作者观察到它们形成了具有识别目标类相似判别能力的特征簇。
为了学习更好的特征簇,作者寻求一种能够在训练期间仅在参数和计算成本不增加的情况下恢复组间特征通信的机制。为此,作者提出使用特征之间的通道相关性。这是通过引入一个计算 BD-MLP 输入特征的通道协方差矩阵的通道注意力分支来实现的,该分支用于重新加权其输出特征,如图2所示。这种注意力机制被称为 通道协方差注意力 (CCA) 块。然后,通过使用学习的权重(a,1-a)进行加权残差加法,将重新加权的特征与 BD-MLP 输出融合。
总体设计,结合 BD-MLP 的稀疏块对角结构以及无参数的 CCA 注意力模块,在参数方面非常高效。实验也表明,CCA 分支中学习的融合权重,如图2中定义为1-a ,在训练过程中会逐渐衰减到零。这一现象在模型所有层和模型架构之间是一致的。虽然 CCA 对训练期间形成良好的特征簇非常重要,但在推理时可以将其删除,如图2所示,而不会造成任何损失。因此,使用 BD-MLP 混合器的模型精度会提高,但模型推理的计算复杂性不会改变。这导致了在参数和 FLOPs 方面都极其高效的推理设置。作者通过分析训练期间注意力分支权重的演变和学习到的特征组的类别可分离性来验证这个假设。
由于将 BD-MLP 和 CCA 相结合,可以实现具有较大扩展比例的模型设计,作者称该结果为 可扩展通道混合器 (SCHEME)。SCHEME 是一种通用的通道混合器,可以用于现有 ViT 变体,实现更大的扩展比例,并获取有效的缩小或放大模型版本。作者将 MetaFormer-PPAA-S12 模型中的通道混合器替换为 SCHEME,以获得一组 SCHEMEformer 模型,其准确率/复杂性权衡得到改善。
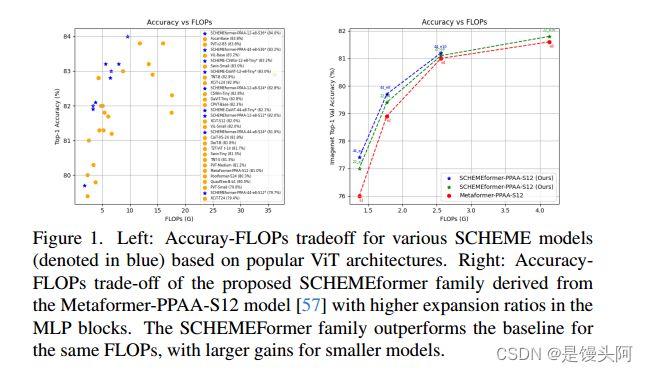
如图1的右侧所示。对于相同的参数数量和 FLOPs,SCHEME 通过使用更大的 MLP 扩展比例,比基线模型获得更好的准确性。对于较小的模型,这种收益尤其大。例如,SCHEMEformer 家族在 1.77 G FLOPs 下,使用自注意力混合器的 ViTs 中实现了 SOTA 结果,即 79.74% 的准确率。
图1的左侧表明,基于流行 ViT 架构的 SCHEME 模型比基线模型在准确性-FLOPs 权衡方面具有更好的权衡。大多数 SCHEMEformer 模型位于准确率与复杂性之间的帕累托前沿,表明 SCHEME 允许对这两个变量进行细粒度控制,同时保证 SOTA 性能。这些特性还延伸到目标检测和语义分割任务,以及不同的架构,如 T2T-ViT 、CoAtNet、Swin Transformer、CSWin 和 DaViT。
总之,作者的贡献如下:
-
研究了 MLP 在 ViT 中的通道混合器,并表明可以被更高内部特征维度的稀疏特征混合所替代,从而提高准确性。
-
提出了 SCHEME 模块,该模块结合了以下两个方面:
-
一个 BD-MLP,以实现比之前 MLP 块更大的内部特征表示
-
CCA,以在不牺牲推理成本的情况下学习这些表示
-
-
SCHEME 表明它是通用的,可以轻松地插入手头的 ViTs 并获得一系列改进性能的模型。作者使用它来引入一组具有比以前 ViTs 更好的准确性/复杂性权衡的 SCHEMEformer 模型。
-
在图像分类、目标检测和语义分割等实验中,作者一致观察到在固定计算和模型大小下,准确率得到了提高.
2、The SCHEME module
图2描绘了在ViTs中进行特征混合的SCHEME模块。如图所示,标准的通道混合器由两个MLP层组成,扩展输入特征的维数,然后将其减少到原始大小。令x表示包含来自N个图像块的N个d-维输入特征向量的矩阵。混合器根据如下方式计算中间表示z和输出表示y:


其中,W1,W2,b1,b2是包含所有元素的N维向量,E是扩展因子(论文说通常=4)
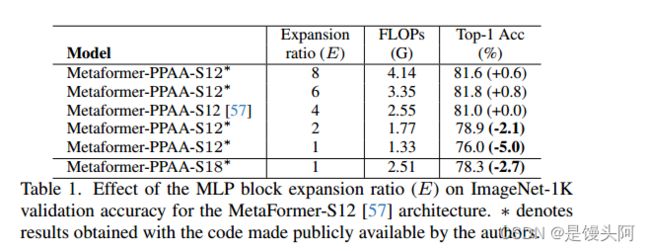
Table 1详细地描述了混合器对整体 Transformer 性能的影响,通过评估扩展因子E对 MetaFormer-PPAA-S12(Pooling, Pooling, Attention, Attention)架构在 ImageNet-1K 上的性能的影响。分类准确率从 76.0 增加到 81.8,当E范围从 1 到 6 时,降低到E=8 ,这表明过拟合。
表格还表明,这些收益并非微不足道。没有扩展(E=1)的 MetaFormer-S18 具有显著更低的准确率 78.3%,尽管它有更多的 Transformer 层并且与 MetaFormer-S12(E=4)的复杂性相当。
总之,对于给定的计算预算,在通道混合器中权衡 Transformer 深度与维数扩展是有益的。这表明这种扩展是 Transformer 架构的关键组件。另一方面,无限制地扩展 E到 6 会使参数和计算成本显著增加,导致过拟合并且对于许多应用是不切实际的。
2.1 Scalable Channel Mixer(SCHEME)
为了有效地实现更高中间 MLP 特征维数的增益,作者提出 SCHEME 模块,该模块包括 BD-MLP 和 CCA 块,其中 CCA 分支仅在训练期间使用。以下各节详细描述了这些。
2.1.1 块对角MLP(BD-MLP):

块对角矩阵之前已经被提出,用于有效地逼近密集矩阵。在卷积神经网络(CNNs)中,组通道操作经常用于设计轻量级的移动模型,具有改进的准确率-计算权衡。这包括将(1)-(2)中的特征向量(1)-(2)分组,如图 2 所示,根据每个组分别实现(1)-(2)中的 MLP。这里可以详细的看原论文,博客打入公式还需要以代码形式对应输入,所有公式符号做解释叫麻烦,在此省略。
2.1.2 通道协方差注意力(CCA):
虽然引入了组,使得由于 g1+g2 倍的扩展因子,准确率得到提升,但导致了亚最优特征的生成。这是因为(3)-(4)中不同组的特征是独立处理的,即没有组间特征融合。这降低了 BD-MLP 的效率。为了在所有特征通道之间实现特征混合,从而诱导形成更好的特征簇,作者在并行分支中引入了一个协方差注意力机制,如图 2 所示。输入特征首先转置得到 d*d的协方差矩阵 。然后,使用其他特征通道与输入特征的协方差来重新加权输入特征。

在矩阵行上应用 softmax 操作, r 是一个平滑因子。通道混合器块的输出是由 BD-MLP 和 CCA 分支的加权求和得到的,按照如下方式:

在所有样本之间学习的混合权重 。第 4.2 节中还讨论了各种其他设计选择。
2.1.3 CCA 作为一个正则化器:
使用无参数注意力分支和静态权重 的设计选择允许模型在训练期间形成更好的特征簇,并在特征簇形成后逐渐衰减 CCA 分支的贡献。这可以在图 4a 中看到,该图显示了在 ImageNet-1K 上所有 Transformer 层中学习的混合权重作为训练周期的函数。
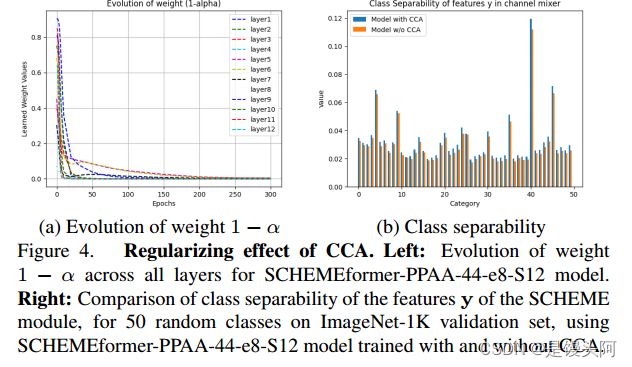
这些图是作者观察到的所有 Transformer Backbone 和架构的典型行为。显然, 1-a开始时很高到中等的值,表示信息通过混合器两个分支的流,但当训练收敛时,1-a 衰减到 0 。因此,在推理时如果删除了 CCA 分支,不会出现退化。这消除了推理期间的大量计算,导致图 2 中的训练和推理设置,其中在推理时没有使用 CCA。
作者通过猜想解释这种行为,即 BD-MLP 的计算效率低下是由于独立的通道组处理带来的更难的学习问题。这导致了成本函数的对称性,例如特征组的顺序不重要,并且需要一个可能产生更多局部极小值的特征聚类操作。CCA 分支通过允许组间通信在训练期间平滑成本函数,而特征组尚未建立。然而,一旦找到了正确的特征分组,CCA 就不需要了,简单地使用 BD-MLP 混合器与标准 MLP 没有性能损失。
2.2 The SCHEMEformer family
提出的 SCHEME 模块可以插入到任何 ViT 架构中,通过混合器超参数 g1、g2和E有效地控制模型复杂性。表 1 显示,仅仅通过降低 E来减小 ViT 模型会导致显著的准确率损失。SCHEME 模块允许更有效地控制准确率/复杂性权衡,在固定的计算预算下产生更好的性能模型。这通过引入一组新模型来证明,这些模型被称为 SCHEMEformer,通过用 SCHEME 模块替换 Metaformer-PPAA 架构的通道混合器得到。

3、Experimental Results
在本节中,作者讨论了在图像分类(ImageNet-1K)、目标检测(COCO-17)和语义分割(ADE-20K)基准测试上对 SCHEME 模块的评估。
3.1 Comparisons to the state of the art
实现细节: 对于图像分类,作者使用批大小为 1024,根据内存可用性进行调整,并在 8 个 GPU 上训练所有模型,使用 AdamW 优化器和余弦退火学习率时间表,学习率为 1e-3。在第一五个周期中应用 Warm up 学习。目标检测基于设置,其中所有 Backbone 都使用 RetinaNet 和 Mask-RCNN 检测Head进行训练,以与先前的方法进行公平比较。使用 1x 学习时间表(使用 AdamW 优化器和初始学习率 1e-4,12 个周期),并使用 mmdetection 代码库,将输入大小限制为较短边为 800,较长边为 1333。
对于语义分割,遵循先前的方法 [4, 24, 57],作者使用批大小为 16,进行 80,000 迭代,使用 AdamW 优化器,初始学习率为 2e-4。作者使用 mmsegmentation 代码库,训练输入大小为512*512 ,测试时将较短边缩小到 512 像素。对于检测和分割,作者使用 ImageNet 预训练模型来初始化 Backbone 。
图像分类: 在 Imagenet-1K 上评估图像分类,不使用额外的数据。作者报告了在 224*224 输入分辨率下的单裁剪 top-1 准确率。报告了各种 Backbone 和超参数配置的结果,以显示 SCHEME 模块的普遍适用性。作者评估了基于 Metaformer-PPAA-S12 的 SCHEMEformer 模型家族,该模型通过用 SCHEME 模块替换原始模型的 MLP 得到。此外,作者将 Metaformer-PPAA-S12 的第一和第二阶段的池化替换为卷积,以评估 SCHEME-CAformer 模型。

Table 3 比较了 SCHEME 模型与文献中各种 SOTA 模型,按token mixers 类型和准确性分组。SCHEME 模型用蓝色突出显示,它们的基础基线模型用 cyan 表示。虽然表按照准确性增加的顺序排序,但必须考虑准确性和参数大小或 FLOPs,因为模型具有非常不同的尺寸。SCHEMEformer 家族通过使用更大的内部特征维度为 MLP,在较小的模型中获得了更大的收益,其性能并未接近饱和。
例如,如红色粗体所示,在相同的计算和参数成本下,SCHEMEformer-PPAA-44-e8-S12 相对于基线 MetaFormer-PPAA-11-e2-S12 提高了 +0.8%,并实现了在 1.77G FLOPs 下达到 SOTA 的 top-1 准确性结果,即 79.7%。
该表还显示了将 SCHEME 模块应用到其他流行的 ViT 架构(如注意力混合器类别中的 T2T-ViT、Swin、CSWin、Da-ViT 和卷积+注意力混合器类别中的 CoatNet、CAformer)的结果,这些模型具有可比或更好的准确性,与相同参数和 FLOPs 相当。例如,SCHEME-CoAtNet-12-e8-0 相对于基线 CoAtNet-0(用棕色突出显示)在 **1M 更少的参数和 0.1G 更少的 FLOPs 下实现了 81.6% 的准确性。SCHEME-CSWin-12-e8-Tiny(蓝色)在仅有 29M 参数和 5.6G FLOPs 的情况下,实现了 83.2% 的准确率,位于 CSWin-Tiny(82.8%)和 CSWin-Small(83.6%)之间。
3.2 目标检测:
表 4 将 SCHEMEformer 模型与 COCO-17 目标检测和实例分割基准上相似复杂度的模型进行了比较,包括 Retinanet 和 Mask-RCNN 检测Head。再次,SCHEMEformer 模型在相同或较小的模型中优于所有其他模型。

例如,SCHEMEformer-44-e8-S12 仅使用 Retinanet 头就实现了 38.3% 的整体 mAP,仅需要 21M 的参数,比具有可比大小的模型提高了超过 2%,并实现了与具有两倍大小模型相当的性能。对于基于 Mask-RCNN 的 SCHEMEformer-44-e8-S12,类似的优势也得到了实现。这些结果表明,SCHEME 模块也可以改进目标检测。
3.3 语义分割:
表 5 将 SCHEMEformer-44-e8 S12 和 S24 模型与 ADE20K 语义分割基准上相似复杂度的模型进行了比较。与目标检测类似,SCHEMEformer 模型在相同或较小的模型中优于所有其他模型。
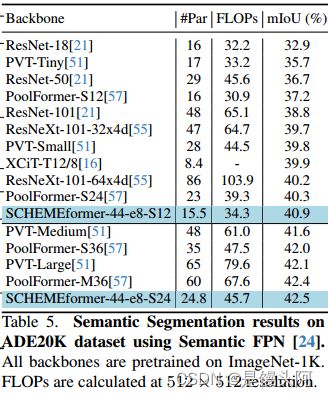
例如,SCHEMEformer-44-e8-S12 实现了 40.9% 的 mIoU,比大多数可比大小的模型提高了 5.2%,例如 PvT-Tiny。同样,S24 模型仅使用 41% 的参数就超过了 PoolFormer-M36。总的来说,语义分割获得的收益比目标检测更高,这表明块对角结构形成的特征簇对密集预测任务具有更大的好处。
4、Ablation Studies
在本节中,作者讨论了 BD-MLP 和 CCA 分支的贡献,通道混合器的其他设计方案,以及 CCA 的正则化效果。
4.1 BD-MLP 和 CCA 分支的贡献:
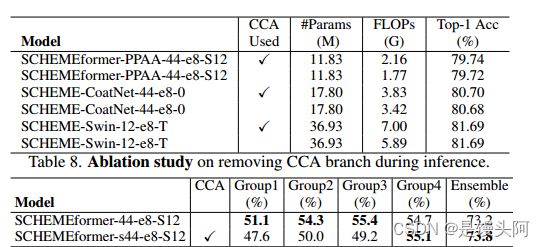
表 6 显示了 BD-MLP 和 CCA 分支对 Transformer 性能的贡献。从 Metaformer-PpAA-11-e2-S12 开始,具有扩展比例 和密集 MLP,作者用 SCHEME 的通道混合器替换,得到 SCHEMEformer-PpAA-44-e8-S12,其中g1=g2=4 ,E=8,保持参数数量和 FLOPs 固定。

4.2 通道混合器的其他设计:
作者研究了是否有其他选择可以更有效地实现这一目标。表 7 比较了用其他特征混合操作替换 CCA 的模型的性能:ShuffleNet 的通道Shuffle操作、一个挤压和增强(SENet)网络、一个单层卷积,以及一个动态版本的 CCA(DyCCA),其中(6)中的权重 使用 GCT 注意力 [35] 动态预测。表中显示 CCA 获得了最佳结果。
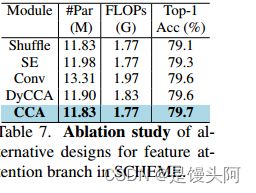
值得注意的一点是,虽然 CCA 比一些这些替代方案需要更多的计算,但在推理时并不需要。作者发现对于这些替代方案,训练收敛后产生的权重在推理时更加平衡,并且不能在推理时被丢弃,否则会导致性能下降。作者猜想,因为这些替代方案都有可学习的参数,网络会学习利用它们来提取互补特征,这些特征必须在推理时与 BD-MLP 分支产生的特征融合。因此,尽管这些替代设计是非常小的模块,但会增加额外的计算成本。CCA 不会,在推理时实现最佳性能且不增加成本。
4.3 CCA正则化作用(重点)
图 3(a) 显示了(6)中 CCA 分支权重 1-a 的训练过程中演变情况。虽然最初较大,但随着训练进行,它逐渐衰减到零。图 3(a) 表明,这一过程对于所有网络层都成立。因此,在推理时可以丢弃 CCA。附录中的图 5 绘制了训练收敛时 SCHEMEformer-PPAA-44-e8 模型系列中 1-a 权重,证实了所有层权重确实非常接近零。
5、Conclusion
在本工作中,作者提出了 SCHEME 模块,使用稀疏特征混合来提高 ViTs 的性能。该模块使用加权融合 BD-MLP 分支,该分支抽象了具有块对角结构的现有 MLP,以及一个无参数的 CCA 分支,在训练期间帮助将特征分组。CA 分支在训练时改善了训练,但在推理时不需要。
实验表明,它确实改善了 BD-MLP 分支内部特征表示的类别可分性,有助于创建关于图像类的特征簇。标准 Transformer 模块中的 MLP 被 SCHEME 模块替换,得到一组新的 SCHEMEformer 模型,这些模型在分类、检测和分割方面,对于固定参数和 FLOPs 具有有利的延迟,表现良好。SCHEME 表明对各种 ViT 架构有效,并提供了灵活的方法来扩展模型,始终优于具有相同复杂性的较小 MLP 扩展比例的模型。
6、夹子猫-布莱克教授
自从布莱克学者英勇的做完节育手术后,嗓子一天比一天夹,布莱克教授在探索AI夹子音的研究方向上成果斐然,效果显著。Dog.Black 教授发明的 Clipboard Sound Model已被中科院1区期刊接收,之后该模型有望应用于喵喵星球的夹子产业化的发展。

Professor Cat.Black's Picture