联邦学习-安全树模型SecureBoost之Decision Tree
联邦学习-安全树模型 SecureBoost之Desicion Tree
文章目录
- 联邦学习-安全树模型 SecureBoost之Desicion Tree
- 1 联邦学习背景
- 2 Decision Tree
-
- 2.1 决策树的定义
- 2.2 决策树基础
-
- 2.2.1 熵
- 2.2.2 条件熵
- 2.2.3 信息增益
- 2.3 剪枝策略
- 2.4 ID3算法
-
- 2.4.1 ID3算法构建决策树方案
- 2.4.2 ID3算法优缺点总结
- 2.5 C4.5算法
-
- 2.5.1 C4.5算法构建决策树方案
- 2.5.2 C4.5算法优缺点总结
- 2.6 CART算法
-
- 2.6.1分类树
-
- 2.6.1.1 基尼指数
- 2.6.1.2 分类树的生成
- 2.6.2 回归树
- 3 自我介绍
1 联邦学习背景
鉴于数据隐私的重要性,国内外对于数据的保护意识逐步加强。2018年欧盟发布了《通用数据保护条例》(GDPR),我国国家互联网信息办公室起草的《数据安全管理办法(征求意见稿)》因此数据在安全合规的前提下自由流动,成了大势所趋。这些法律法规的出台,不同程度的对人工智能传统处理数据的方式提出更多的挑战。
AI高度发展的今天,多维度高质量的数据是制约其进一步发展的瓶颈。随着各个组织对于数据的重视程度的不断提升,跨组织以及组织内部不同部门之间的数据合作将变得越来越谨慎,造成了数据大量的以孤岛的形式存在

联邦学习的本质是基于数据隐私保护一种分布式机器学习技术或机器学习框架。它的目标是在保证数据隐私安全及合法合规的基础上,在模型无损的前提实现共同建模,提升AI模型的效果,进行业务的赋能。
那么既然是建模,在工业界最近若干年比较出名的大致可以分为GBDT和神经网络了,但是由于联邦学习的特性,需要对用户的特征与Label进行隐私安全保护,所以需要采用同态加密、秘钥分享、差分隐私等隐私计算手段保障安全。但是基于此带来了比较大的挑战,神经网络的复杂运算,指数、对数等会给建模提出非常大的难题,以目前的硬件与软件加密技术还是非常困难的,但是对于GBDT来说,只需要进行简单的同态运算就解决,所以本篇文章会和大家分享下联邦学习的安全树模型-Secure Boost。
BTW,目前神经网络虽然比较难做安全屏障,无法很好的做到计算性能与模型性能的Balance,但是经过笔者长期的思考,已经有了一个自己认为靠谱的方案,后续会逐步验证,如果最终验证靠谱,会和大家Share出来一起分享。
由于树模型相对来说知识较多,所以无法一步到位解决清晰SecureBoost,故本文章分成以下主题来进行,主要的脉络就是:决策树 -> 集成方法Bagging & Boosting -> GBDT -> XGBoost -> Secure Boost Tree。希望读者可以通过这一系列文章,对联邦学习的SecureBoost方法有一个整体的全方位的掌握。
其实,对于树模型系列来说,笔者以前做算法的时候,也在大量的使用,并且觉得自己是理解到位的,但是在我写联邦学习安全树模型的时候,发现很多的地方并没有理解透彻,有很多细节是没有考虑到的,写着写着就会发现自己的理论厚度不够,细节没有吃透。后来也花了大量的精力和时间去充电,这个事情也让我明白了,很多东西你看起来懂了,其实并没有懂,只有去真正的用心的去做过一遍,你才有些懂了,无论做什么事情脚踏实地才是最重要的。
2 Decision Tree
2.1 决策树的定义
什么是决策树呢?决策树是一种监督学习方法,既可以用来处理分类问题也可以处理回归问题。
以职场为例吧,目前整个公司有一个比较难的行业技术领域要破局,这个时候职场里面很多没有躺平的同事都希望自己可以能够解决这个问题,但是既然是行业技术难题,就不是所有人可以解决的。基于此首先要考虑的是这个事情,自己是否有勇气去做,然后考虑自己是否有能力去做,如果自己没有能力去做,自己是否可以和牛人一起合作去做这个事情,如果牛人自己就搞定,那就没他什么事情了。

下面笔者分别介绍下决策树相关的知识。
2.2 决策树基础
为了下面更好的描述生成决策树的相关算法,先介绍下一些基本概念。
2.2.1 熵
熵这个词在各个学科都有涉及,熵的概念是由德国物理学家克劳修斯于1865年所提出,泛指某些物质系统状态的一种量度,某些物质系统状态可能出现的程度。在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的变量。假设X是个取有限个值的离散型的随机变量,其概率分布为
P ( X = x i ) = p i , i = 1 , 2 , . . . , n P(X=x_i) = p_i, i=1,2,...,n P(X=xi)=pi,i=1,2,...,n
那么随机变量X的熵的定义为:
H ( X ) = − ∑ i n p i l o g p i H(X) = -\sum_i^np_ilogp_i H(X)=−i∑npilogpi
从上的定义可知,熵越大随机变量的不确定性越强,那么从特征重要度的角度来说,该特征越不具备较强的表征分裂能力。

2.2.2 条件熵
假设随机变量(X,Y),他们的联合分布如下:
P ( X = x i , Y = y j ) = p i j , i = 1 , 2 , . . . , n ; j = 1 , 2 , . . . , m P(X=x_i, Y=y_j)=p_{ij}, i = 1,2,...,n; \quad j=1,2,...,m P(X=xi,Y=yj)=pij,i=1,2,...,n;j=1,2,...,m
那么,我们定义条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性,也就说在X给定条件下Y的条件概率分布的熵对X的数学期望:
H ( Y ∣ X ) = ∑ i n p i H ( Y ∣ X = x i ) H(Y|X)=\sum_i^np_iH(Y|X=x_i) H(Y∣X)=i∑npiH(Y∣X=xi)
2.2.3 信息增益
特征A对训练数据集D的信息增益g(D,A),那么信息增益定义为集合D的经验熵H(D)与特征A给定条件下关于D的条件熵H(D|A)之差,即
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D) - H(D|A) g(D,A)=H(D)−H(D∣A)
如果信息增益越大,那么就是指分完之后的信息熵越小,那也就意味着分完之后的数据趋向于稳定,而越稳定的数据,意味着我们能更好地预测数据。
设训练数据集为D,则|D|表示样本容量,即样本的个数。
假 设 该 批 样 本 总 共 有 K 个 分 类 定 义 为 c k , k = 1 , 2 , . . . , K , 则 ∣ C k ∣ 定 义 为 属 于 C k 的 样 本 个 数 , 则 ∑ k = 1 K ∣ C k ∣ = ∣ d ∣ , 设 假设该批样本总共有K个分类定义为c_k,k=1,2,...,K,则|C_k|定义为属于C_k的样本个数,则\sum_{k=1}^K|C_k|=|d|,设 假设该批样本总共有K个分类定义为ck,k=1,2,...,K,则∣Ck∣定义为属于Ck的样本个数,则k=1∑K∣Ck∣=∣d∣,设
特 征 A 有 n 个 不 同 的 取 值 , a 1 , a 2 , . . . , a n 。 则 根 据 特 征 A 的 取 值 将 D 划 分 成 n 个 子 集 D 1 , D 2 , . . . , D n , ∣ D i ∣ 为 D i 的 样 本 特征A有n个不同的取值,{a_1,a_2, ...,a_n}。则根据特征A的取值将D划分成n个子集D_1,D_2,...,D_n,|D_i|为D_i的样本 特征A有n个不同的取值,a1,a2,...,an。则根据特征A的取值将D划分成n个子集D1,D2,...,Dn,∣Di∣为Di的样本
个 数 , ∑ i = 1 n ∣ D i ∣ = ∣ D ∣ 。 同 时 定 义 子 集 D i 中 属 于 C k 的 样 本 的 集 合 为 D i j , 则 D i j = D i ∩ C k , 个数,\sum_{i=1}^n|D_i|= |D|。同时定义子集D_i中属于C_k的样本的集合为D_{ij},则D_{ij} = D_i \cap C_k, 个数,i=1∑n∣Di∣=∣D∣。同时定义子集Di中属于Ck的样本的集合为Dij,则Dij=Di∩Ck,
∣ D i k ∣ 定 义 为 D i k 的 样 本 个 数 。 |D_{ik}|定义为D_{ik}的样本个数。 ∣Dik∣定义为Dik的样本个数。
那么根据上述描述,特征A对数据集D的经验条件熵H(D|A)
H ( D ∣ A ) = − ∑ i = 1 n D i D ∑ k = 1 K D i k D i log 2 D i k D i H(D|A) = - \sum_{i=1}^n \frac{D_i}{D}\ \sum_{k=1}^K \frac{D_{ik}}{D_i} \ \log_2{ \frac{D_{ik}}{D_i} \ } H(D∣A)=−i=1∑nDDi k=1∑KDiDik log2DiDik
信息增益准则的一个问题在于它会偏爱那些具有很多取值的特征,而忽略其与分类的相关性。例如,考虑这么一个场景,假设我们在处理一个二分类的任务,且每个样本有一个唯一的ID。此时若选择这个ID作为特征进行节点分裂的时候,将会获得较大的信息增益,因为他能准确的分类所有的训练样本,但是,这样的分类结果却无法泛华,不能对位置样例进行预测。这个时候就可以采用信息增益率来解决。ID3算法采用的是信息增益,而C4.5采用的是信息增益率,后续会详细介绍。
2.3 剪枝策略
对于决策树来说,经常可以观察到这样一种现象:相对于一棵在训练集表现的不是那么好的决策树,一棵在训练集上表现的十分完成的决策树的泛化能力更差。这种现象就是“过拟合”,本质原因在于学习器在学习的过程中把训练特征中的一个非朴素特质当做了潜在的真实分布造成的。也就是说,学习器学习的太好了,把一些噪音也血流量进去。
针对决策树来说,为了防止“过拟合”造成较差的泛化能力,常用策略就是使用“剪枝”老进行去噪,进而学到更加朴素的特质,学到数据的本质。常用的剪枝方案有以下两种:
- 预剪枝:在树的生成阶段进行剪枝。
- 后剪枝:在树生成后,在检查需要去掉哪些分支。
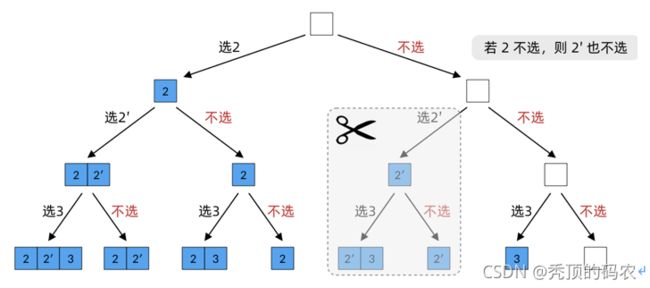
2.4 ID3算法
ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
决策树的技术核心在于树的节点的分裂思想,ID3算法采用在分裂节点采用信息增益准则进行特征选择,进而递归的进行整棵树的构建。ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
2.4.1 ID3算法构建决策树方案
- 首先,从根节点开始,针对节点计算所有可能特征的信息增益。
- 然后,选择信息增益最大的特征作为节点的特征进行分裂。
- 然后,针对这个信息增益最大的特征,根据盖特征的不同取值简历子节点。
- 然后,在对子节点重复上面的过程。
- 最后,知道所有特征的信息增益均很小达到阈值或者没有特征可以选择为止。
2.4.2 ID3算法优缺点总结
- 模型结构:N叉树,如果特征的取值较多,计算量非常可观。
- 模型目标:适合处理分类问题。
- 特征相关:没有给出连续型特征的处理方法,适合处理离散型特征,对于缺失的特征没有需要在预处理阶段自行解决缺失值问题。
- 模型优化:没有模型的剪纸优化操作,容易发生过拟合。
- 内存消耗:随着样本的特征空间维度迅速膨胀。
- 计算效率:N叉树,随着样本的特征空间进行分支,计算耗时较高。
2.5 C4.5算法
C4.5算法是由Ross Quinlan开发的用于产生决策树的算法。该算法是对Ross Quinlan之前开发的ID3算法的一个扩展。C4.5算法产生的决策树可以被用作分类目的,因此该算法也可以用于统计分类。C4.5算法与ID3算法类似,如上面所说,C4.5相对于ID3算法进行了改进,在数的生成过程中使用了信息增益比进行特征的选择,其他的基本是一致的。
2.5.1 C4.5算法构建决策树方案
请参考ID3算法,有些不一样的地方是对连续特征进行离散化。
2.5.2 C4.5算法优缺点总结
- 模型结构:N叉树,如果特征的取值较多,计算量非常可观。
- 模型目标:适合处理分类问题。
- 特征相关:连续特征离散化(离散化的方法,针对M个特征,有M-1个特征选择,也要进行特征取值排序,每个候选的分割阈值点的值为上述排序后的属性值中两两前后连续元素的中点,相当于离散特征变多)。支持处理离散型特征,对于缺失的特征征值以一定的概率划分到不同的节点。
- 模型优化:悲观剪枝策略进行树的剪枝。
- 内存消耗:需要对特征值进行排序,内存操作,容易OOM。
- 计算效率:N叉树,随着样本的特征空间进行分支,并且需要多次扫描与排序,计算耗时较高。
2.6 CART算法
熟悉机器学习算法与框架的朋友,都会有这样的感受,那就是很多算法都是在寻求算法和工程的平衡,既要良好的算法效果,也有较高的计算效率,二者是缺一不可的。
CART树相对于ID3和C4.5做了一些简化处理,它使用了了二叉树而不是多叉树,进而提高生成决策树的效率,减少运算量。并且分类树通过Gini系数作为变量的不纯度量,减少大量的对数运算耗时。
2.6.1分类树
下面我来介绍下基于CART的分类树。CART作为分类树时,特征属性可以是连续类型也可以是离散类型,树的节点分裂策略基于基尼指数,接下来就先介绍下基尼指数。
2.6.1.1 基尼指数
定义:在分类问题中,假设有K个类,样本点属于第K个类的概率为pk,则概率分布的基尼指数为
G i n i ( p ) = ∑ k = 1 K p k ( 1 − P k ) = 1 − ∑ k = 1 K p k 2 Gini(p) = \sum_{k=1}^Kp_k(1-P_k) = 1 - \sum_{k=1}^K{p_k}^2 Gini(p)=k=1∑Kpk(1−Pk)=1−k=1∑Kpk2
对于给定的样本集合D来说,其基尼指数为:
G i n i ( D ) = 1 − ∑ k = 1 K ( ∣ C K ∣ ∣ D ∣ ) 2 Gini(D) = 1 - \sum_{k=1}^K{( \frac{|C_K|}{|D|} \ )}^2 Gini(D)=1−k=1∑K(∣D∣∣CK∣ )2
那么,在特征A条件下,结合D的基尼指数为,D1和D2为按照特征A的某个取值进行切分后的两个范围。
KaTeX parse error: Undefined control sequence: \ at position 74: …|D|} Gini(D_2) \̲ ̲
基尼指数Gini代表数据的不确定性,Gini(D,A)表示经过特征A=a分裂后集合D的不确定性,那么和信息增益不一样的是,基尼指数越小代表模型的不纯度却低,特征约好。
2.6.1.2 分类树的生成
CART分类树采用基尼指数进行二叉树的分裂,枚举所有特征的所有可能切分点进行计算,选取基尼指数最小的分裂点,降低模型的不纯度。同时对于决策树建立后做预测的方式,CART分类树采用叶子节点里概率最大的类别作为当前节点的预测类别。
2.6.2 回归树
回归树的特征基本是连续型的,利用平方误差最小化准则。
流程如下: 对于任意特征A,依次计算所有可能的分裂点取值,通过该取值将样本数据划分成D1和D2两部分,通过MSE的方式计算各自的Loss并相加(回归树输出不是类别,它采用的是用最终叶子的均值或者中位数来预测输出结果。),进而选择损失最小的特征取值,然后进行节点分裂,并且重新划分各自节点的数据集,然后递归执行本过程即可。
min j , s [ min C 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + min C 1 ∑ x i ∈ R 2 ( j , s ) ( y j − c 2 ) 2 ] \min\limits_{j,s}[\min\limits_{C1}\sum_{x_i \in R_1(j,s)}(y_i - c_1)^2 + \min\limits_{C1}\sum_{x_i \in R_2(j,s)}(y_j - c_2)^2 ] j,smin[C1minxi∈R1(j,s)∑(yi−c1)2+C1minxi∈R2(j,s)∑(yj−c2)2]
其中,气氛便利为j,切分点为s,将数据集切分为C1和C2两部分,我们通过上述算法找到损失最小的。
CART树的优缺点
- 模型结构:使用二叉树的形式,提升决策树整理效率。
- 模型目标:支持分类树与回归树。
- 特征相关:采用代替测试来估计缺失值,并且特征可以在各层之间反复使用。
- 模型优化:使用剪枝践行优化,基于代价复杂度的方式进行剪枝。
- 计算代价:分类树采用Gini系数的方式减少复杂运算。
3 自我介绍
个人介绍:杜宝坤,京东联邦学习从0到1构建者,带领团队构建了京东的联邦学习解决方案,实现了电商营销领域支持超大规模的工业化联邦学习解决方案,支持超大规模样本PSI隐私对齐、安全的树模型与神经网络模型等众多模型,建模不受限,同时带领团队实现了业务侧的落地,开创了新的业务增长点,产生了显著的业务经济效益。
个人喜欢研究技术。基于从全链路思考与决策技术规划的考量,研究的领域比较多,从架构、大数据到机器学习算法与框架均有涉及。欢迎喜欢技术的同学和我交流,邮箱:[email protected]