人工智能,什么是强化学习?
强化学习已成为机器学习中一个很有前途的领域,可以解决通常处于不确定性状态的顺序决策问题。这方面的例子包括多梯队和多个供应商的库存管理,交货时间在需求不确定的情况下;控制问题,如自主制造操作或生产计划控制;以及财务或运营中的资源分配问题。
强化学习是一种学习范式,用于学习优化顺序决策,这些决策是跨时间步长重复做出的决策,例如,在库存控制中做出的每日库存补货决策。在高层次上,强化学习模仿了我们人类的学习方式。人类有能力学习帮助我们掌握复杂任务的策略,如游泳、体操或参加考试。强化学习广泛地从这些人类能力中寻求灵感,以学习如何行动。但更具体地说,对于强化学习的实际用例,它试图获得在不确定性下的动态系统中跨时间重复做出顺序决策的最佳策略。它通过与感兴趣的随机动态系统(也称为环境)的模拟器进行交互来学习此类制胜策略。在动态系统中跨时间重复做出顺序决策的策略也称为策略。强化学习试图学习制胜策略,即如何在动态系统的不同状态下采取行动的制胜秘诀。
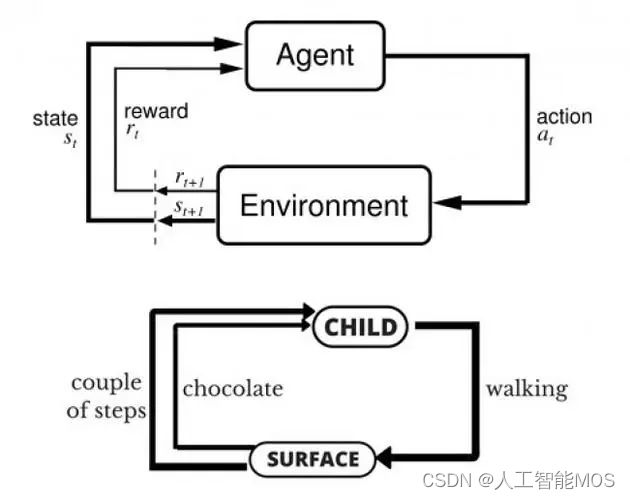
强化学习在数学框架中的工作
- 状态空间(或观察空间):对做出决策有用的所有可用信息和问题特征。这包括完全已知或测量的变量(例如,库存控制中的当前库存水平)以及您可能只有信念或估计的未测量变量(例如,对未来一天或一周的需求预测)。
- 操作空间:在系统的每个状态下可以做出的决策。
- 奖励信号:一种标量信号,提供有关性能的必要反馈,因此有机会了解在任何给定状态下哪些操作是有益的。学习本质上是局部的,学习眼前的收益和长期的收益,因为在任何状态下采取的行动都会导致未来的状态,在该状态中采取另一种行动,依此类推。折扣累积奖励信号是强化学习的优化目标,使其专注于产生最佳累积奖励的长期策略。
大多数动态优化问题以及一些确定性离散(组合)优化问题都可以在状态-动作-奖励框架中自然地表达。当在任何状态下采取行动以收集局部奖励并推动系统及时前进时,动态系统会在状态空间中经历(不确定的)转换。例如,马尔可夫决策过程(MDP)模型将动态系统中不确定的转换和奖励下的顺序决策形式化,并采取状态-行动-奖励模型的形式。
在不确定的转换和不确定的奖励下,在动态系统中通过强化学习结合了两个相辅相成的思想:探索新的状态和新的状态-动作组合,并利用由此产生的经验来改进决策。这是强化学习的两个基本思想,即探索和利用。如果有足够的时间(即足够的经验积累),强化学习可以产生一个成功的策略(或策略),你可以在重复的决策问题中将其用于长期决策。
强化学习与机器学习
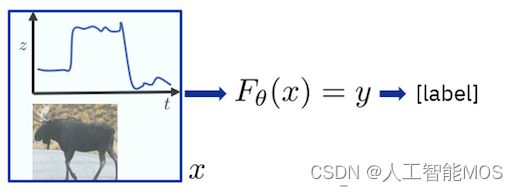
它有助于将强化学习与经典监督机器学习进行对比,以更好地了解强化学习。在监督式机器学习中,你专注于预测你不知道的东西。在独立且相同分布的输入数据(i.i.d 输入数据)的统计假设下,它效果最好。简单来说,这意味着假定每个输入数据记录都独立于其他每个记录,并且每个输入数据记录都是从某个单一的、通用的基础输入数据分布模型中实现的。当用作决策模型时,监督预测模型是一次性决策或预测,它只关注给定的输入数据记录,并与所有其他输入数据记录分离。预测模型的学习是通过监督进行的,使用预测精度最大化作为学习目标。您可以访问与用于训练的每个数据输入记录相对应的地面实况预测。下图抓住了这种可以称为“学习预测”的范式。
相比之下,强化学习是一个基于学习的决策框架,在这个框架中,你不再有一个带有地面实况标签的i.i.d数据表。取而代之的是,你拥有“当前状态-操作-下一个状态-奖励”组合形式的元组轨迹,这些组合是串行相互依赖的,也就是说,数据不再是静态的表格数据集,这与监督式机器学习不同。学习的目标是生成一个策略,即计算下一个最佳操作的映射或策略,并了解您采取的任何操作都会影响未来对策略映射的输入,以计算下一个最佳操作等。这使得学习不再只关注当前状态,而是关注当前行动下游对未来状态的长期影响。
这方面与使用仅使用当前输入的预测模型的单次焦点不同。最后,与监督式机器学习不同,没有可用的基本事实或监督。取而代之的是,学习是以“状态-行动-下一个状态-奖励”元组的串行耦合动态序列的形式从经验中学习的,也就是说,以受控动态轨迹的形式获得经验,以及状态空间中的奖励,并提炼该经验以学习如何最佳行动。下图抓住了这种可以称为“学习行动”的范式。
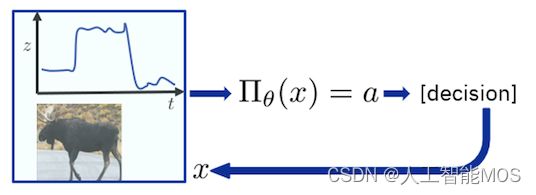
状态-行动-奖励框架:一个建模模板
可帮助您对问题进行“建模”
如前所述,强化学习允许为顺序问题提供非常通用的建模模板。这些问题涉及一个系统(例如,物理动态系统),该系统在系统随机性下采取行动时会从一个状态转换到另一个状态。作为解决方案开发人员,您可以通过为问题选择以下选项来对问题进行建模:
- State-space:对做出决策有用的所有可用信息和问题特征
- 行动空间:您可以做出的决定
- 奖励:您关心的兴趣的关键绩效指标,例如收入
- 约束:您可以对违反每个利益约束的行为进行负惩罚,以增加奖励
- 不确定性:系统随机性超出您的控制范围
举一个有启发性的例子,考虑库存控制,其中零售商需要在需求和供应交货时间不确定的情况下每周从供应商那里做出补货决策。状态空间可以包括以下各项:每周结束时的当前库存、过去几周内看到的需求以尝试了解需求模式、过去几周为考虑供应商交货时间随机性而采取的过去补货行动,以及下周估计的需求预测。这既包括可直接测量的已知变量,也包括感兴趣的估计信念变量(如预测)。
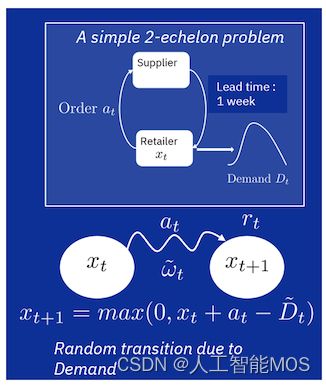
行动空间可以包括每周结束时要收到的补货订单,并有一定的提前期。最后,系统中的不确定性在于需求不确定性和供应商交货时间的不确定性。您可以设置约束条件来惩罚库存水平的过冲或过低,在此示例中,库存水平在不确定性下会演变。为了简单起见,下图描述了这个 2 级问题的简化版本中的转换,其中所选状态空间 (x) 在采取补货行动 (a) 并获得本地奖励 (r) 时跟踪需求不确定性(ω 或 D)下的库存水平,假设固定且已知的提前期为一周。
强化学习的类型:在线和离线(批处理)
强化学习技术可以根据在线技术与离线技术进行广泛而有用的组织。在在线强化学习中,您可以访问一个实时或模拟系统,该系统表示(或通过模拟编码)系统的动态,即系统在采取允许的行动后如何从一个状态演变到另一个状态,并且通常在不确定性下。此外,它还在每个时间步中提供奖励信号。该信号可能是空的或空的,更一般地说,它可能是多变量的,也就是说,不止一个这样的关键性能指标。在线强化学习算法(或代理)通过与这种响应式在线系统交互来学习。相比之下,离线强化学习(或批量强化学习)是一种补充设置,您无法访问这种响应迅速的交互式系统。相反,离线强化学习只能访问过去操作、过去状态转换和相应奖励的历史日志,并从这些历史数据中学习策略。此学习路径随附的 IBM Developer API Hub 上的软件即解决方案 (SaaS) 产品的当前发行版(版本)解决了在线环境中强化学习的自动化问题。
实践中的强化学习挑战
尽管强化学习作为一种将自动化人工智能用于决策的方法很有前途,但在将其应用于现实的工业问题时,它在实践中充满了一些挑战。首先,文献以学术基准问题为主,研究人员正在积极推动有效算法的最新技术。这样一来,您就没有太多的参考示例来寻求建模灵感,并确信它是解决感兴趣的工业问题的可行方法。
其次,有许多算法,如基于价值函数的技术(如Q学习、DQN)、基于政策映射的技术(如政策学习和PPO)及其组合(如演员-批评方法、A2C 和 SAC)。要充分了解这些算法的内部工作原理,您需要在马尔可夫决策过程、马尔可夫链、蒙特卡洛技术、动态规划和贝尔曼递归等主题上投入一些数学努力和培训,这对许多数据科学家来说可能并不实用。此外,还有几个开源框架及其各自实现这些不同的算法,如 stable-baselines、RLLib、d3rlpy、Coach 和 Keras RL。熟悉这些实现以及如何有效地使用它们还需要陡峭的学习曲线,这在实践中可能会限制解决方案开发人员。
接下来,这些算法及其实现中的每一种都允许几个可调的超参数,并带有一些默认值,但众所周知,强化学习的性能对初始选择非常敏感,并且随着训练和学习的进行,这些选择会动态重新调整。这种三维诅咒(框架数量、代理数量、超参数数量)需要进行大规模、分布式和计算密集型的实验,以调查和搜索最佳算法及其可能产生的获胜策略。虽然开源中有一些分布式框架,如 Ray 和 Ray Tune,但它们也需要特殊的专业知识来配置计算集群,并有效地使用它们。
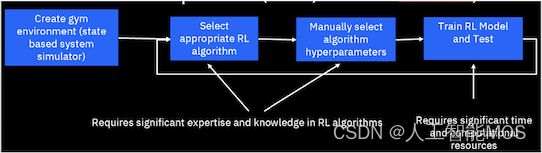
最后,深度强化学习使用深度神经网络表示来捕获值函数和策略映射,这为神经架构提供了更多选择。总体而言,在实践中使强化学习发挥作用所需的专业领域和流利程度的学科领域的广度和深度是其在现实生活中采用的严重限制因素。这在实践中就更成问题了,因为强化学习尽管有前途,但是一项冒险的工作,没有正式的保证团队为获得这些技能而可能付出的所有努力和投资都会产生有用的解决方案。下图显示了当今从业者在强化学习中费力且耗时的工作流程。用于决策的自动化 AI API 提供了一种解决方案,可显著自动化此工作流,并为具有广泛专业知识的数据科学家和解决方案开发人员实现强化学习的普及。
总的来说强化学习时人工智能学习中必不可少的一部分,也是十分重要的一部分。如果你觉得本文对你有一点帮助,帮忙点点赞,关注!谢谢您的观看。