MyBatis:使用 MyBatis 实现多表查询(多对一和一对多)、动态 SQL、缓存
文章目录
- MyBatis:Day 03
- 一、复杂查询的环境搭建
- 二、多表查询
-
- 1. 多对一:关联
-
- (1)联表查询
- (2)子查询
- 2. 一对多:集合
-
- (1)联表查询
- (2)子查询
- 3. 总结
- 三、动态 SQL 的环境搭建
- 四、动态 SQL
-
- 1. if
- 2. choose、when、otherwise
- 3. where、set
- 4. foreach
- 5. SQL 片段
- 6. 总结
- 五、缓存
-
- 1. 简介
- 2. 一级缓存
- 3. 二级缓存
- 4. 缓存原理
- 注意:
MyBatis:Day 03
一、复杂查询的环境搭建
复杂查询的环境搭建:为接下来的多对一和一对多的处理做准备。
总体步骤为:
- 在
pom.xml中导入所需要的依赖; - 建立 MyBatis 核心配置文件:
mybatis-config.xml; - 工具类:
MybatisUtils.java; - 实体类:
Teacher.java和Student.java; - 接口:
TeacherMapper.java和StudentMapper.java; - 实现类:
TeacherMapper.xml和StudentMapper.xml; - 测试。
需要提前建立两张表:student 和 teacher 表。
-- 创建数据库 mybatis01
CREATE DATABASE IF NOT EXISTS `mybatis01`;
USE `mybatis01`;
-- 创建 teacher 表
CREATE TABLE IF NOT EXISTS `teacher` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
-- 插入数据
INSERT INTO `teacher` (`id`, `name`) VALUES (1, '张老师'), (2, '王老师');
-- 创建 student 表
CREATE TABLE IF NOT EXISTS `student` (
`id` INT(10) NOT NULL,
`name` VARCHAR(30) DEFAULT NULL,
`tid` INT(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fktid` (`tid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
-- 插入数据
INSERT INTO `student` (`id`, `name`, `tid`) VALUES
(1, '小明', 1),
(2, '小红', 1),
(3, '小张', 2),
(4, '小李', 2),
(5, '小王', 2);

环境搭建显示

注意:这里把实现类
Mapper.xml放入了资源文件夹下,但经过编译后仍在dao包下,所以在核心配置文件中的资源路径为:resource="com/Sun3285/dao/StudentMapper.xml"。
生成的 target 文件夹

二、多表查询
最佳实践:最好逐步建立结果映射。单元测试可以在这个过程中起到很大帮助。 如果你尝试一次性创建复杂的结果映射,不仅容易出错,难度也会直线上升。 所以,从最简单的形态开始,逐步迭代。而且别忘了单元测试! 有时候,框架的行为像是一个黑盒子(无论是否开源)。因此,为了确保实现的行为与你的期望相一致,最好编写单元测试。 并且单元测试在提交 bug 时也能起到很大的作用。
1. 多对一:关联
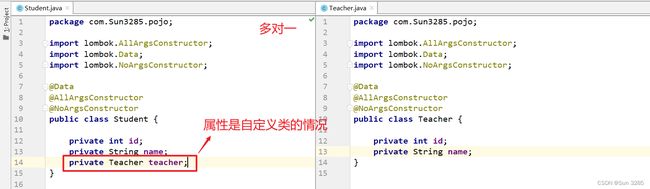
举例:查询全部学生(多)对应的老师(少)。
(1)联表查询
思路:
- 联表查询是按照结果嵌套处理;
- 步骤:先写出 SQL 语句,保证可以执行,然后在
Mapper.xml中用resultMap进行结果集映射,最后测试。
- SQL 语句:
SELECT s.`id` AS '学生id', s.`name` AS '学生姓名', s.`tid` AS '老师id', t.`name` AS '老师姓名'
FROM `student` AS s
INNER JOIN `teacher` AS t
ON s.`tid` = t.`id`;

- 在
Mapper.xml中用resultMap进行结果集映射:
<select id="getAllStudents" resultMap="studentResultMap">
SELECT s.`id` AS '学生id', s.`name` AS '学生姓名', s.`tid` AS '老师id', t.`name` AS '老师姓名'
FROM `student` AS s
INNER JOIN `teacher` AS t
ON s.`tid` = t.`id`;
select>
<resultMap id="studentResultMap" type="Student">
<result property="id" column="学生id"/>
<result property="name" column="学生姓名"/>
<association property="teacher" javaType="Teacher">
<result property="id" column="老师id"/>
<result property="name" column="老师姓名"/>
association>
resultMap>

- 测试:

(2)子查询
思路:子查询是按照查询过程嵌套处理;
<select id="getAllStudents" resultMap="studentResultMap">
select * from `student`;
select>
<resultMap id="studentResultMap" type="Student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<association property="teacher" column="tid" javaType="Teacher" select="getTeacher"/>
resultMap>
<select id="getTeacher" resultType="Teacher">
select * from teacher where `id` = #{tid};
select>
2. 一对多:集合
举例:查询全部老师(少)包含的学生(多)。

(1)联表查询
思路:
- 联表查询是按照结果嵌套处理;
- 步骤:先写出 SQL 语句,保证可以执行,然后在
Mapper.xml中用resultMap进行结果集映射,最后测试。
- SQL 语句:
SELECT t.`id` AS '老师id', t.`name` AS '老师姓名', s.`id` AS '学生id', s.`name` AS '学生姓名'
FROM `teacher` AS t
INNER JOIN `student` AS s
ON t.`id` = s.`tid`;

- 在
Mapper.xml中用resultMap进行结果集映射:
<select id="getAllTeachers" resultMap="teacherResultMap">
SELECT t.`id` AS '老师id', t.`name` AS '老师姓名', s.`id` AS '学生id', s.`name` AS '学生姓名'
FROM `teacher` AS t
INNER JOIN `student` AS s
ON t.`id` = s.`tid`;
select>
<resultMap id="teacherResultMap" type="Teacher">
<result property="id" column="老师id"/>
<result property="name" column="老师姓名"/>
<collection property="studentList" ofType="Student">
<result property="id" column="学生id"/>
<result property="name" column="学生姓名"/>
collection>
resultMap>

- 测试:

(2)子查询
This part is too complex, let’s use linked table queries instead!
3. 总结
-
当查询出来的字段名与属性名不一致时,需要进行结果集映射
resultMap。 -
使用结果集映射
resultMap时,属性名和查询到的字段名要一一映射:- 简单的属性(只是属性名和字段名不一致),直接映射;
- 复杂的属性(如自定义对象、集合)需要单独处理(嵌套处理):
- 属性是自定义对象:用 association,其中 javaType 为属性中自定义的类;
- 属性是集合:用 collection,其中 ofType 为属性中集合的泛型约束类型。
-
要保证 SQL 的可读性,通俗易懂。
-
排查错误可以使用日志。
三、动态 SQL 的环境搭建
动态 SQL 的环境搭建:为接下来的动态 SQL 学习做准备。
总体步骤为:
- 在
pom.xml中导入所需要的依赖; - 建立 MyBatis 核心配置文件:
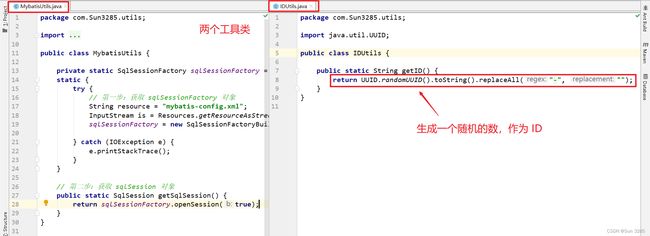
mybatis-config.xml; - 工具类:
MybatisUtils.java以及IDUtils.java(用来产生一个唯一的 ID); - 实体类:
Blog.java; - 接口:
BlogMapper.java; - 实现类:
BlogMapper.xml; - 测试。
需要提前建立一张表:blog 表。
-- 创建数据库 mybatis02
CREATE DATABASE IF NOT EXISTS `mybatis02`;
USE `mybatis02`;
-- 创建表 blog
CREATE TABLE IF NOT EXISTS `blog`(
`id` VARCHAR(50) NOT NULL COMMENT '博客id',
`title` VARCHAR(100) NOT NULL COMMENT '博客标题',
`author` VARCHAR(30) NOT NULL COMMENT '博客作者',
`create_time` DATETIME NOT NULL COMMENT '创建时间',
`views` INT(30) NOT NULL COMMENT '浏览量'
)ENGINE=INNODB DEFAULT CHARSET=utf8mb4;
测试:插入数据。
环境搭建过程



四、动态 SQL
动态 SQL:根据不同的条件生成不同的 SQL 语句,在 SQL 层面执行一些逻辑代码。
实质:拼接 SQL 语句,只要保证 SQL 的正确性,按照 SQL 的格式去排列组合就可以。
建议:先写出完整的 SQL,然后再对应地去修改成为动态 SQL。
1. if
<select id="方法名" parameterType="参数类型" resultType="返回值类型">
select 查询语句
<where>
<if test="判断语句1(结果为布尔值类型)">
sql 语句
if>
<if test="判断语句2(结果为布尔值类型)">
sql 语句
if>
where>
select>
2. choose、when、otherwise
如果有多个 IF 语句,会从上到下依次对每个条件进行判断。有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
<select id="方法名" parameterType="参数类型" resultType="返回值类型">
select 查询语句
<where>
<choose>
<when test="判断语句1(结果为布尔值类型)">
sql 语句
when>
<when test="判断语句2(结果为布尔值类型)">
sql 语句
when>
<otherwise>
sql 语句
otherwise>
choose>
where>
select>
注意:
choose元素,类似于 Java 中的 switch 语句:
- choose 等同于 switch;
- when 等同于 case;
- otherwise 等同于 default。
3. where、set
where 元素作用:
- 至少有一个子元素的条件返回 SQL 子句的情况下才插入 “WHERE” 子句;
- 如果子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
set 元素作用:
- 会动态地在行首插入 SET 关键字;
- 会删掉额外的逗号(这些逗号是在使用条件语句给列赋值时引入的)。
4. foreach
foreach:用来对集合进行遍历(尤其是在构建 IN 条件语句的时候)。
可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。
当使用可迭代对象或者数组时:
-
collection:指传递的集合参数,如果parameterType为 Map 集合,这里就是指键名; -
item:每次迭代获取到的元素; -
open:以 xxx 为开始; -
separator:分隔; -
close:以 xxx 为结束。
<select id="方法名" parameterType="map" resultType="返回值类型">
select 查询语句
<where>
<foreach collection="传递的集合参数" item="每次迭代获取到的元素"
open="开始" separator="分隔" close="结束">
`id` = #{id}
foreach>
where>
select>
举例:查询指定 ID 的博客信息。


5. SQL 片段
有的时候,我们可能会将一些公共部分抽取出来,方便复用,如下所示:
<sql id="SQL 片段的 id(自由取)">
公共的 SQL 片段
sql>
引用 SQL 片段时,如下所示:
<select id="方法名" parameterType="map" resultType="返回值类型">
select 查询语句
<where>
<include refid="SQL 片段的 id">include>
where>
select>
注意:
- 最好基于单表来定义 SQL 片段;
- SQL 片段中不要存在 where 标签。
6. 总结
-
多个
IF语句会从上到下依次对每个条件进行判断; -
choose元素,像 Java 中的 switch 语句,从上到下执行,只要有一个符合就停止执行; -
foreach元素是遍历循环,集合参数为可迭代对象(如 List、Set 等)、Map 对象或者数组对象; -
最好将 SQL 中的 where 用
where标签代替; -
判断
test时,里面的语句为 Java 语句,其中对字符串的判断,要用单引号套双引号的形式,因为 MyBatis 是使用 OGNL 表达式来进行解析的。
<where>
<if test='author == "Sun3285"'>
SQL 语句
if>
where>
五、缓存
1. 简介
缓存:Cache,存在内存中的临时数据。
- 作用:将用户经常查询的数据放在缓存中,用户去查询数据就不用从磁盘上查询,而是从缓存中查询;
- 优点:减少了和数据库的交互次数,提高了查询效率,解决了高并发系统的性能问题;
- 使用缓存的数据:经常查询并且不经常改变的数据。
MyBatis 缓存:包含了一个非常强大的缓存特性,可以非常方便地定制和配置缓存。默认定义了两级缓存:
- 一级缓存:也叫本地缓存,是
sqlSession级别的缓存。默认情况下,只有一级缓存开启,仅仅对一个会话中的数据进行缓存。 - 二级缓存:是
namespace级别的缓存。需要手动开启和配置,MyBatis 定义了缓存接口Cache,可以实现接口来定义二级缓存。
注意:二级缓存只作用于 cache 标签所在的映射文件中的语句。
2. 一级缓存
-
一级缓存是
sqlSession级别的缓存,默认情况下,只有一级缓存开启; -
仅仅对一个会话中的数据进行缓存(
sqlSession从得到到关闭这一段期间的数据)。
测试一级缓存。

缓存失效的情况:
- 查询不同的数据;
- 进行了增、删、改操作,必定会刷新缓存,因为可能改变了原来的数据;
- 查询不同的实现类
Mapper.xml; - 手动清理缓存:
sqlSession.clearCache();。
注意:一级缓存相当于一个 Map 集合。
3. 二级缓存
二级缓存是 namespace 级别的缓存,会在整个 Mapper.xml 中生效。需要手动开启和配置。
工作机制:当关闭会话时,一级缓存中的数据才会被保存到二级缓存中,新的会话查询信息时,就可以从二级缓存中获取内容。
开启二级缓存步骤:
- 在 MyBatis 核心配置文件中进行设置(settings),开启全局缓存;
- 在要使用二级缓存的
Mapper.xml中加cache标签。

测试二级缓存。

注意:实体类需要序列化。
4. 缓存原理
在缓存中查询的顺序:
- 先看二级缓存中有没有之前查过的数据;
- 再看一级缓存中有没有之前查过的数据;
- 如果都没有,则查询数据库。
举例:
查询一个数据 --> 二级缓存中没有 --> 一级缓存中没有 --> 连接数据库,查询数据库 --> 查询到结果,结果保存到一级缓存中 --> 关闭会话,此时一级缓存中的数据保存到二级缓存中;
再次查询同一个数据 --> 二级缓存中存在 --> 从二级缓存中直接拿到数据(不会连接数据库)。
注意:
- Java 代码先编译为 class 文件,然后对 class 文件进行执行。
- 编译前,代码按照功能分类;编译后,代码按照包名分类。
- xml 文件中路径和全限名依据编译后
target文件中的路径和全限名。 - 一定要注意
resultType和resultMap别写错。 - 实体类最好序列化:实体类实现
Serializable接口。