yolov5 网络结构
YOLOv5(You Only Look Once version 5)是目标检测任务中的一种深度学习模型,其网络结构相对简单,但非常有效。下面是一个大概思路,用于明白整个流程,但是我们讲解不按这个走哦。
输入层(Input Layer): YOLOv5的输入层接受图像数据,通常是固定大小的图像。输入图像会经过一系列的卷积和下采样操作,最终生成不同尺度的特征图。
特征提取网络(Backbone): YOLOv5采用CSPDarknet53作为特征提取网络,其中包含了一系列卷积层、批次归一化层和Leaky ReLU激活函数。这一部分负责从输入图像中提取高级特征。
下采样层(Downsampling): 在CSPDarknet53中,包含了多个下采样操作,使得特征图的尺寸逐渐减小。
Neck(特征融合部分): YOLOv5引入了PANet(Path Aggregation Network)用于特征融合,以更好地处理不同尺度的目标。PANet用于合并来自不同层次特征图的信息,提高了模型的性能。
检测头(Detection Head): YOLOv5的检测头包括多个输出层,每个输出层负责检测不同尺寸的目标。每个输出层生成预测框的边界框坐标、类别概率以及目标存在的置信度。
Anchor Boxes(锚框): YOLOv5使用锚框(anchors)作为预测框的基准,不同尺度的特征图对应不同大小的锚框。
激活函数(Activation Function): YOLOv5中使用的激活函数是Leaky ReLU,它在隐藏层中引入非线性。
损失函数(Loss Function): YOLOv5使用的损失函数包括目标位置的均方误差、目标存在的二值交叉熵(BCE)以及类别概率的交叉熵。
YOLOv5的结构遵循先进的目标检测思想,通过使用不同尺度的特征图和锚框,以及引入特征融合的机制,实现对不同尺寸目标的有效检测。这种网络结构使得YOLOv5在速度和准确性之间取得了平衡,适用于多种目标检测任务。
下面我们一点一点攻破这个难题。
1.yolov5网络
基于深度学习的目标检测主要包含三个部分:
骨干网络(Backbone):用于特征提取,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等
颈部网络(Neck):主要用于预测目标的种类和位置(bounding boxes)
头部网络(Head):在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层。
基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出。
下面就是yolov5的主要网络结构:
- 骨干网络(Backbone): New CSP-Darknet53
- 颈部网络(Neck): SPPF, New CSP-PAN
- 头部网络(Head): YOLOv3 Head
参考博客:YOLOv5【网络结构】超详细解读总结!!!建议收藏✨✨!_yolov5网络结构详解-CSDN博客
yolov5官网给出了5中模型,我们下面就以yolov5s.yaml举例


以上数据在官网,大家可以按需索取
一般来说,map越高,参数量(params)越大,速度(speed)越慢,效果越好(需要根据具体模型,具体实验),模型的内存越大。
有一个问题,那就是下面的size变大了,为什么后面那些参数都比上面的大呢,先埋个坑,后面回答。还有那个TTA是什么呢。(可以先跳转到2.3部分看回答)
2.yolov5s.yaml配置部分
这个模型一共有25个模块。
# YOLOv5 by Ultralytics, GPL-3.0 license
# Parameters V4.0和5.0
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple 层缩放系数
width_multiple: 0.50 # layer channel multiple 通道缩放系数
anchors:
- [10,13, 16,30, 33,23] # P3/8 其中P表示特征图的层级,P3/8该层特征图缩放为1/8,是第3层特征
- [30,61, 62,45, 59,119] # P4/16 表示[10,13],[16,30], [33,23]3个anchor
- [116,90, 156,198, 373,326] # P5/32 宽高 为什么是P3,4,5呢???
# YOLOv5 backbone
backbone:
# [from, number, module, args] from: 输入来自哪一层 , -1代表上一层 n: 层数 params: 参数量 module :模块名称 arguments:模块参数,包括channel,kernel_size,stride,padding,bias等
[[-1, 1, Focus, [64, 3]], # 0-P1/2 后面的0-,这个0代表第几层,说明该模型,一共有25层。
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]], #1024是通道数,5,9,13代表多尺度池化核大小
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4 【1】就是维度
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.1 nc
nc就是你训练的类啦,这里默认是80类,因为默认的是coco训练集,一共80个类。
当与实际(coco128.yaml)不符合时,会自动用coco128.yaml中的nc替代yolov5s.yaml的nc。
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value yolo.py中
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='dataset.yaml path') #这个文件 train.py中 ![]()
2.2 depth_multiple和width_multiple
这说明这两个参数之前,我们需要了解一下模型的宽度和深度。
宽度:就是通道数
深度:网络层数
要解决比较复杂的问题, 要么增加深度, 要么增加宽度, 而增加宽度的代价往往远高于深度。深度越深,一层网络做的事情也就更简单。
深度在一定程度上能够表现出更好的性能, 而宽度则起到另一个作用。那就是让每一层学习到更加丰富的特征, 比如不同方向, 不同频率的纹理特征。
参考:深度学习的深度和宽度的理解_宽度和深度是什么意思-CSDN博客
depth_multiple默认值是0.33 就是减少模型层数。就是决定下一个模块的重复次数。
width_multiple默认值是0.5,就是减少通道数。
#yolo.py
def parse_model(d, ch):
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
#深度拷贝yolov5s.yaml中的参数
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
#更新下一个模型深度,不满1,以1补
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv,
MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, DCnv2]:
c1, c2 = ch[f], args[0] #c1上一层通道数,c2控制是否到达最后一层,最后一层为no
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8) #让c2能够被8整除,为了快2.3anchor
anchor是在图像上预设好的不同大小,不同长宽比的参照框。
在训练的时候,需要anchor的大小和长宽比与待检测的物体尺度基本一致,才可能让anchor与物体的IoU大于阈值,成为正样本,否则,可能anchor为正样本的数目特别少,就会导致漏检很多。
anchors: #其中P表示特征图的层级,P3/8该层特征图缩放为1/8
- [10,13, 16,30, 33,23] # P3/8 640/8=80
- [30,61, 62,45, 59,119] # P4/16 640/16=40
- [116,90, 156,198, 373,326] # P5/32 640/32=20
P3/8的第一个锚框的尺寸为[10, 13],表示其宽度为10,高度为13。
P3/8的第二个锚框的尺寸为[16, 30],表示其宽度为16,高度为30。不知道大家有没有注意上面那个总的yaml文件上面有一个问题, 为什么是P3,4,5呢??????2和6不行吗。
这个问题是因为没有搞懂P和3代表什么。P代表该特征层的层级,3代表的是卷积的二倍下采样次数,P3也就是代表在这个特征图上进行2*2*2的下采样,也就是缩放了8倍。那P5就是2*2*2*2*2,就是缩放了32倍。如果要是2或者6的话就太大或太小了,6的话在s6系列有(size大),在此处不合适了,所以这样子是最合适的。(参考来源,下面的问题与回复)
从上往下看,第一行缩放倍数是8,相对与下面的比较小,得到的尺寸比较大,所以感受野比较小,就适合去检测大物体。第二行适合中等物体。第三行适合小物体。这样子解释就好理解下面结论啦。
anchors参数共有三行,每行9个数值;且每一行代表应用不同的特征图;
1、第一行是在最大的特征图上的锚框
2、第二行是在中间的特征图上的锚框
3、第三行是在最小的特征图上的锚框
好啦,正好讲完了P和3的意思 来埋第一部分的坑啦。

anchors:
- [19,27, 44,40, 38,94] # P3/8
- [96,68, 86,152, 180,137] # P4/16
- [140,301, 303,264, 238,542] # P5/32
- [436,615, 739,380, 925,792] # P6/64- 首先为什么叫yolov5s6呢是因为基于pytorch1.6实现的,所以起名为6。、
- 为什么size越大各个指标越好呢。首先size大代表他的像素多,进行检测的时候当然好。就相当于同等清晰度的大图和小图一样,当然看大图更容易。其次他又进行了四轮anchor,更容易检查小物体。这个效果当然up!up!up!啊。
- 那个TTA是什么?YOLOv5 TTA是YOLOv5在测试阶段使用的一种技术,TTA是Test Time Augmentation的缩写。 它是一种数据增强的方法,在模型推理的过程中对输入图像进行多次扰动,然后将多次扰动后的结果进行平均或者投票等操作得到最终的预测结果。 YOLOv5 TTA的使用可以提高模型的推理精度。
具体怎么使用的见3.1.15 detect部分。
2.4backbone
2.4.1 focus模块(第一模块)
focus模块用于对图片进入切片工作,这个可以保证在不损失信息基础上,更快。

将yolov3的三层并为一层,主要还是为了提速!!!

以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:


该图片转自这个博客
class Focus(nn.Module):
# Focus wh information into c-space 图片进入backbone前,对图片进行切片操作
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))focus的结构如下:

因为在focus调用了conv。下面又从Conv模块调用了上面图的三个函数,下面就来一一讲解。
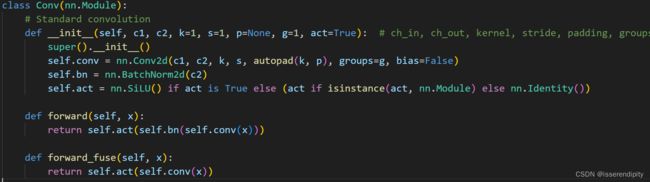
- 第一步:conv 就是卷积。 先进行一个卷积操作下面就是他的参数解释。进去的通道数是12就是focus切片完的,输出的通道数是32,是一共有32组卷积核,卷完之后就是32。

- 第二步:bn 即BatchNorm2d。 应用批归一化即对小批量(mini-batch)数据组成的输入数据进行批标准化(Batch Normalization)操作,通过减少内部协变量偏移来加速深度网络训练。 代码中描述的公式。



来看看这个参数是什么意思吧,
num_features 为出入通道数,即第一步卷积完的的32
momentum 用于计算上面的期望和方差的值。 可以将累积移动平均线(cumulative moving average)(即简单平均线 simple average)设置为“无”。 默认值:0.1
eps 为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
affine 当设为true时,会给定可以学习的系数矩阵gamma和beta
- 第三步 act即激活函数Silu()。激活函数(activation functions)的目标是,将神经网络非线性化。激活函数是连续(continuous),且可导的(differential)。相对于ReLU函数,SiLU函数在接近零时具有更平滑的曲线,并且由于其使用了sigmoid函数,可以使网络的输出范围在0和1之间。与sigmoid函数相比,在负数时导数更大,有助于缓解梯度消失问题。该函数实在Sigmoid激活函数做的一个改进。公式为silu (x)=x∗ sigmoid(x)


2.4.2 Conv(第二模块)
经过第一轮输出现在的应该是32*320*320的特征图。

纯纯卷积,重复上一部分,那个激活函数我改了,默认应该是SiLU激活函数。
现在输出层为64*160*160。
2.4.3 C3(第三模块)
在yolov5中,c3是一个重要模块,是一种CSP(Cross Stage Partial)瓶颈块,用于特征提取的重复模块。它基于瓶颈结构,并包含三个卷积层以及多个Bottleneck模块(数量由配置文件.yaml的n和depth_multiple参数乘积决定)下面是他的具体代码:
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))c_作为隐藏通道,三次参与卷积,旨在降低特征的通道数,并生成两个具有较小通道数的特征张量cv1,cv2。cv3将两个特征图压缩为输出通道数,输入通道数是隐藏通道数的二倍,输出通道数c2,接下来这两个特征张量(cv1,cv2)被用作输入,通过一系列堆叠的瓶颈块(Bottleneck)进行处理。每个瓶颈块由一次1x1卷积和一次3x3卷积组成,它们的目标是进一步提取和增强特征信息。下面来看看BottleNeck代码:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))最后,经过一系列的瓶颈块之后,两个特征张量被拼接在一起,并通过一个1x1卷积层来融合它们。这样,C3模块的输出特征张量就得到了,可以继续用于后续的处理。
总的来说,C3模块在YOLOv5中起到了提取丰富特征并增强特征表达能力的作用。它通过使用瓶颈块和1x1卷积层的组合来实现这一目标,并在保持计算效率的同时提高了模型的性能。
下面这个图为Bottleneck的完整流程。上面是一个卷积层干的事,下面是这个Bottleneck层将两个卷积层特征值对应相加。图来源

参考博客

m就代表着BottleNeck。那个(0)就代表只进行一次BottleNeck。一次里面进行两次卷积。
C3不改变维度,应该还是64*160*160。
2.4.4 Conv(第四模块)
上面已经分析的很详细啦,我们就贴个流程图,写个输入输出就够啦。

输入为64*160*160,输出为128*80*80。
2.4.5 C3(第五模块)
输入为128*80*80,输出为128*80*80。
结构如下图,n=3,重复3次BottleNeck操作。
C3(
(cv1): Conv(
(conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
(cv2): Conv(
(conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
(cv3): Conv(
(conv): Conv2d(192, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
(m): Sequential(
(0): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
)
(1): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
)
(2): Bottleneck(
(cv1): Conv(
(conv): Conv2d(96, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
(cv2): Conv(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(act): ReLU()
)
)
)
)
![]()
2.4.6 Conv(第六模块)
输入为128*80*80,输出为256*40*40。
2.4.7 C3(第七模块)
输入256*40*40,输出256*40*40。
2.4.8 Conv(第八模块)
输入256*40*40,输出512*20*20。
2.4.9 SPP(第九模块)
SPP是Spatial Pyramid Pooling(空间金字塔池化),用于自适应尺寸的输出。因为最后做全连接层实现分类的时候需要指定全连接的输入,所以我们需要一种方法让神经网络在某层得到一个固定维度的输出。

SPP模块通常由三个步骤组成:
- 池化:将输入特征图分别进行不同大小的池化操作,以获得一组不同大小的特征图。
- 连接:将不同大小的特征图连接在一起。
- 全连接:通过全连接层将连接后的特征向量降维,得到固定大小的特征向量。
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k]) #使用了最大池化
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1)) #cat 进行通道拼接,add进行特征数据相加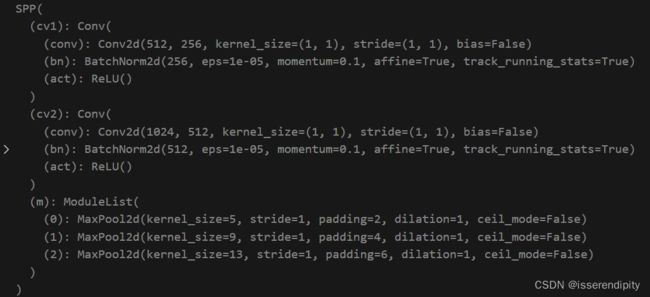
SPP不改变维度, 输入为512*20*20,输出为512*20*20。
2.4.10 C3(第十模块)
输入为512*20*20,输出为512*20*20。
总结:

对比一下,输出的值。下面这个图,第一列为层数索引值,第二列是来自上一层的意思,n代表进行几次该模块操作。是上面的n经过width_multiple计算得来的。params是模型参数量。module表示进行的是哪一个模块。arguments是依次代表input_chanel,output_chanel,kernel_size,stride。

![]()
params参数量就是通过上面式子一个一个卷积调用相加得到的。
2.3.neck
2.3.1 Conv(第十一模块)

大家注意看哦,这里使用了1*1的卷积核,可以有效的降低参数,不改变特征图的尺寸下,降低通道数。下面这个图是将通道数减少为原来的3倍,而我们上面是减少为原来的2倍。具体减少了几倍应该是我们给出了输入输出通道数和卷积核大小步长,计算机自己判断给出多少组卷积核能较少或增加到输出通道的。(参考博客)

减少计算量:
输入为512*20*20,输出位256*20*20。
2.3.2 nn.Upsample (第十二模块)
nn.Upsample为上采样,即放大图片。
torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
size:据不同的输入制定输出大小;
scale_factor:指定输出为输入的多少倍数;
mode:可使用的上采样算法,有nearest,linear,bilinear,bicubic 和 trilinear。默认使用nearest;
align_corners :如果为 True,输入的角像素将与输出张量对齐,因此将保存下来这些像素的值。
这里输出为输入尺寸的2倍,使用最近邻插法。不是改变通道数哦![]()
![]()
输入为256*20*20,输出为256*40*40。
2.3.3 Concat(第十三模块)
concat是指在网络的不同层之间进行张量拼接操作。YOLOv5使用了混合尺度特征融合的方式进行目标检测,其中concat操作是将不同尺度的特征图在通道维度上进行拼接,以提高目标检测的精度。
将输出通道数变为上一层和第7层想加了,即512。通过将低分辨率(上一层)但具有丰富语义信息的特征图与高分辨率但语义信息较少(第7层)的特征图进行concat操作,concat将输入特征图的维度连接起来,形成一个更大的输出特征图,这种跨层连接可以同时兼顾细节和感知范围,从而提高目标检测的准确性。
输入为256*40*40*2(两层),输出为512*40*40。

class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)2.3.4 C3 (第十四模块)
这里注意了哦,上面说不改变输出维度基于给出的配置文件的输出通道数正好是输入通道数的2倍,当不是二倍的时候就会变得,但是尺寸不变。

输入为512*40*40,输出为256*40*40。(如果上面是1024,输出通道数就不变了)
2.3.5 Conv(第十五模块)
输入为256*40*40,输出为128*40*40。
2.3.6 nn.Upsample (第十六模块)
输入为128*40*40,输出为128*80*80。
2.3.7 Concat(第十七模块)
输入为128*80*80*2,输出为256*80*80。
2.3.8 C3 (第十八模块)
输入为256*80*80,输出为128*80*80。
2.3.9 Conv(第十九模块)
输入为128*80*80,输出为128*40*40.。
2.3.10 Concat(第二十模块)
输入为128*40*40*2,输出为256*40*40。
2.3.11 C3 (第二十一模块)
输入为256*40*40,输出为256*40*40。
2.3.12 Conv(第二十二模块)
输入为256*40*40,输出为256*20*20.。
2.3.13 Concat(第二十三模块)
输入为256*20*20*2,输出为512*20*20。
2.3.14 C3 (第二十四模块)
输入为512*20*20,输出为512*20*20。
2.4.head
2.3.15 Detect(第二十五模块)
Detect 模块定义了一个带有锚框的检测层,应用了卷积操作,并处理输出以获得边界框坐标、目标置信度和类别概率。在推断阶段,对原始预测进行后处理以生成最终的边界框预测。
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers 3组
self.na = len(anchors[0]) // 2 # number of anchors 3个
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2) #初始化为1*3*2
self.register_buffer('anchors', a) # shape(nl,na,2) #register_buffer保存参数 一个存储每个检测层锚框宽度和高度的缓冲区。
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2) 高维向低维 一个存储锚框的网格格式的缓冲区。
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv 此输出表示边界框坐标、目标置信度和类别概率的预测。
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4] or self.onnx_dynamic:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
# return x
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()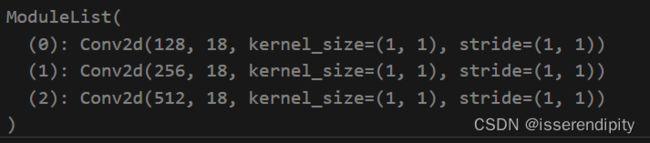
这个输出18,意思是包含三组类别,锚框坐标和置信度信息的值。
2.5. 总结
这个是最后输出的参数。最后一行是总结,说明包含了283层,7063542个参数,7063542个梯度用于更新权重参数的值。

3.前向传播
3.1 model代码
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg,encoding='UTF-8') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)
# LOGGER.info([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward 计算三个feature map下采样的倍率 [8, 16, 32]
m.anchors /= m.stride.view(-1, 1, 1) #torch.Size([3, 3, 2])
check_anchor_order(m) #检查 YOLOv5 中 Detect() 模块中的锚框顺序是否与步长顺序一致,是否满足小anchor检查大物体
self.stride = m.stride
self._initialize_biases() # only run once 计算bias
# LOGGER.info('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
LOGGER.info('')
def forward(self, x, augment=False, profile=False, visualize=False):
if augment: # 是否在测试时也使用数据增强 Test Time Augmentation(TTA)
return self.forward_augment(x) # augmented inference, None
return self.forward_once(x, profile, visualize) # single-scale inference, train 1*3*256*256
def forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
def forward_once(self, x, profile=False, visualize=False): #x图像,profile性能评估,visualize特征可视化
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer s全是-1 #如果不是,将从save的y中读取到,并改成列表的格式
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
c = isinstance(m, Detect) # copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
x = m(x) # run 相当于又进行了一轮模块
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if profile:
LOGGER.info('%.1fms total' % sum(dt))
return x
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
LOGGER.info(
('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
def autoshape(self): # add AutoShape module
LOGGER.info('Adding AutoShape... ')
m = AutoShape(self) # wrap model
copy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributes
return m
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)前向传播,调用上面的model,产生下面的输入输出。
前向传播就是将上一层的输出作为下一层的输入,并计算下一层的输出,一直到运算到输出层为止。
# Forward
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.3.2 输入输出
传进去的值为16*3*256*256,再经过上面25层模块,在这边我们单独列出来(与上面输出结果的一致,验证我们的推理结果),输出的值分别为:
backbone
Focus;1*32*128*128 torch.Size([16, 32, 320, 320])
Conv:1*64*64*64 torch.Size([16, 64, 160, 160])
C3:1*64*64*64 torch.Size([16, 64, 160, 160])
Conv:1*128*32*32 torch.Size([16, 128, 80, 80])
C3:1*128*32*32 torch.Size([16, 128, 80, 80])
Conv:1*256*16*16 torch.Size([16, 256, 40, 40])
C3:1*256*16*16 torch.Size([16, 256, 40, 40])
Conv:1*512*8*8 torch.Size([16, 512, 20, 20])
SPP:1*512*8*8 torch.Size([16, 512, 20, 20])
C3:1*512*8*8 torch.Size([16, 512, 20, 20])
neck
Conv:1*256*8*8 torch.Size([16, 256, 20, 20])
nn.Upsample:1*256*16*16 torch.Size([16, 256, 40, 40])
Concat:512*16*16 torch.Size([16, 512, 40, 40])
C3:1*256*16*16 torch.Size([16, 256, 40, 40])
Conv:1*128*16*16 torch.Size([16, 128, 40, 40])
nn.Upsample:1*128*32*32 torch.Size([16, 128, 80, 80])
Concat:1*256*32*32 torch.Size([16, 256, 80, 80])
C3:1*128*32*32。 torch.Size([16, 128, 80, 80])
Conv:1*128*16*16 torch.Size([16, 128, 40, 40])
Concat:1*256*16*16 torch.Size([16, 256, 40, 40])
C3:1*256*16*16 torch.Size([16, 256, 40, 40])
Conv:1*128*8*8 torch.Size([16, 256, 20, 20])
Concat:1*256*8*8 torch.Size([16, 512, 20, 20])
C3:1*256*8*8 torch.Size([16, 512, 20, 20])
head
Detect:在推断阶段,对原始预测进行后处理以生成最终的边界框预测。
在推理阶段,使用anchor对不同大小的图片进行预测,一共三组anchor,所以x就是3个维度。后面size依次代表着,1张图片,3通道(RGB通道),80*80的图片尺寸,6个特征值(类别(这里是1)+置信度+xywh四个坐标值)

注意:这里看输出的通道数一定要结合yaml给出的通道数看,有时候C3不改变通道数,有时候Conv不改变通道数,一定要注意看,尺寸大小一般根据卷积核大小和步长来确定和通道数没有太大关系。
3.3 总结
主要组成部分:
-
主干网络 (Backbone):
- 该网络负责从输入图像中提取特征。
- 使用一系列不同的卷积模块,如 Focus、Conv、C3、SPP 等。
- 主干网络将输入图像逐步下采样为不同尺度的特征图(P1/2,P2/4,P3/8,P4/16,P5/32)。
-
头部网络 (Head):
- 头部网络接收来自主干网络不同层级(P3,P4,P5)的特征图。
- 对特征图进行进一步处理,包括上采样、特征融合(Concat)、卷积操作(C3)等。
- 头部网络的最后一层是
Detect模块,用于目标框的检测,其中包含了目标类别数量(nc)和锚框的信息(anchors)。
构建流程:
-
Backbone 构建:
- 使用不同的卷积模块构建主干网络,逐步提取图像特征。
- 在每个阶段(P1/2,P2/4,P3/8,P4/16,P5/32)生成相应的特征图。
-
Head 构建:
- 将主干网络的不同层级的特征图输入头部网络。
- 头部网络进行特征处理,包括上采样和特征融合等。
- 最后一层是
Detect模块,用于最终目标框的预测。
-
Detect 模块:
Detect模块接收来自不同层级的特征图,执行目标框的预测。- 模块的参数包括目标类别数量 (
nc) 和锚框信息 (anchors)。
总体而言,该模型通过主干网络提取图像特征,然后通过头部网络进行进一步处理和特征融合,最终使用 Detect 模块预测目标框。
4.反向传播
根据预测框和真实框之间的差异计算出损失函数值,然后通过反向传播来更新网络参数(调用优化器)。
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size这个返回的这个loss,然后进行反向传播,将结果传到优化器中,优化器再更新参数。
# Backward
scaler.scale(loss).backward()
# Optimize
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni5.冻结权重
冻结训练是迁移学习常用的方法,当我们在使用数据量不足的情况下,通常我们会选择公共数据集提供权重作为预训练权重,我们知道网络的backbone主要是用来提取特征用的,一般大型数据集训练好的权重主干特征提取能力是比较强的,这个时候我们只需要冻结主干网络,fine-tune后面层就可以了,不需要从头开始训练,大大减少了实践而且还提高了性能。(参考)
迁移学习是一种有用的方法,可以在新数据上快速重新训练模型,而无需重新训练整个网络。取而代之的是,部分初始权重被冻结在原地,其余权重用于计算损失,并由优化器更新。与正常训练相比,这需要更少的资源,并允许更快的训练时间,尽管这也可能导致最终训练准确性降低。(issue#1314)
"Freezing"(冻结)在深度学习中通常指的是固定模型的一部分参数,使其在训练过程中不再更新。在目标检测任务中,常见的是冻结模型的骨干(backbone)部分,而让其他部分(例如头部,即用于检测目标的最后几层)继续训练。需要根据具体实例来选择。
在yolov5中,通过下面实验来看,在backbone里面冻结比较好,精度下降不是太大,而且时间效率高。
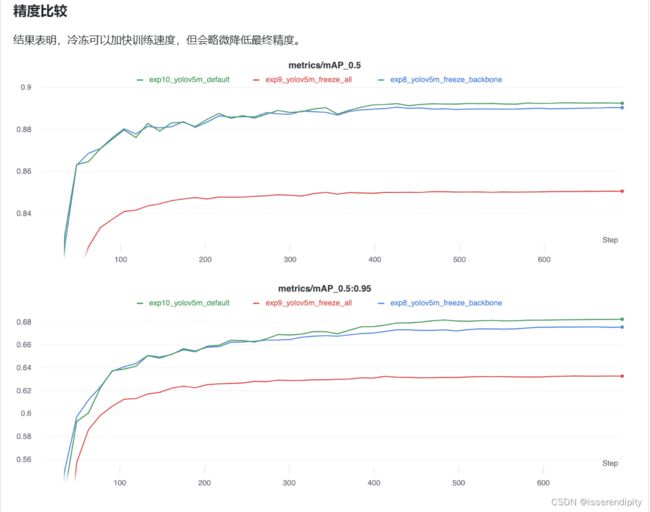
通过上面实验,我们就可以吧freeze改为10,进行冻结(学习率和bs可以设大一点)。即通过设置requires_grad=false,不再更新权重。
# Freeze 冻结权重层 冻结可以大幅加快训练速度且节省GPU显存,但会稍微降低最终精度。
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze 默认是0
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
print(f'freezing {k}')
v.requires_grad = False6.优化器(SGD)
yolov5,默认使用SGD。optim.SGD是PyTorch中的一个优化器,其实现了随机梯度下降(Stochastic Gradient Descent,SGD)算法。在深度学习中,我们通常使用优化器来更新神经网络中的参数,用来更新和计算影响模型训练和模型输出的网络参数,使其逼近或达到最优值,以使得损失函数尽可能地小。
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
params:需要更新的参数,通常为模型中的权重和偏置项。lr:学习率,即每次参数更新时的步长。momentum:动量,用来加速模型收敛速度,避免模型陷入局部最优解。dampening:动量衰减,用来控制动量的衰减速度。weight_decay:权重衰减,用来防止模型过拟合,即通过对权重的L2正则化来约束模型的复杂度。nesterov:是否使用Nesterov动量
![]()
下面这个图是我们总体的网络框架图。

欢迎大家点赞,关注,订阅本专栏。后续还会出更多关于yolov5的内容哦!