《MySQL》索引篇:索引失效情况
索引失效情况
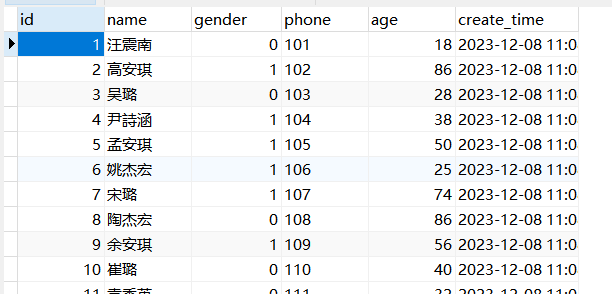
设计表,模拟1000条数据。
建表语句:
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`gender` tinyint(4) NULL DEFAULT NULL,
`phone` varchar(30) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`create_time` datetime NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`) USING BTREE,
INDEX `inde_name`(`name`) USING BTREE,
INDEX `index_phone`(`phone`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2001 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
部分数据如下:
对索引使用左模糊或左右模糊匹配
使用
like %xx或like %xx%都会使索引失效。
name字段为二级索引。
下面是使用左模糊匹配分析,使用的是全表扫描 type = ALL(左右模糊结果和这个相同)

下面是使用右模糊匹配分析,走的是索引。

对索引使用函数

原因:索引保存的是索引字段原始的值,函数计算后的值和索引中值无关,自然不会走索引了。
ps:但是MYSQL8开始,新增了函数索引,即可以对函数计算后的结果建立一个索引。
对索引进行表达式的计算
使用id - 1 = 20走全表

使用id = 20 + 1走索引

原因和使用函数一个道理。
对索引进行隐式转换
当索引字段是字符串类型,但是接收数据是整型,索引会失效。
验证:
对字符串字段转入整型。索引失效,走全表扫描

对整型字段转入字符串。索引没有失效。

原因:
MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。
相当于在索引字段使用函数来进行转型,回到之前使用函数使索引失效的情况。
EXPLAIN SELECT * FROM t_user WHERE phone = 101;
-- 上面的查询语句就会等价于
EXPLAIN SELECT * FROM t_user WHERE CAST(phone AS signed INT) = 101;
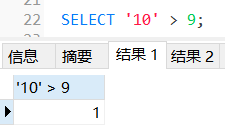
PS:是字符串转整型,还是整型转字符串,可以通过
SELECT '10' > 9进行验证。
如果都转为字符串进行比较(
'10' > '9'比较第一个字符 ),返回的是0。如果都转为整型进行比较,返回的是1。
结果是1,说明转为整型比较。
联合索引没有使用最左匹配
建表语句如下,给a,b建立联合索引,插入100条数据。
DROP TABLE IF EXISTS `t_ab`;
CREATE TABLE `t_ab` (
`a` int(11) NULL DEFAULT NULL,
`b` int(11) NULL DEFAULT NULL,
INDEX `index_a_b`(`a`, `b`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
对于联合索引,从左到右,先按照第一个字段排序,第一个字段相同情况下再按照第二个字段排序,以此类推。
当我们使用联合索引时,没有按照上面的规则,也称为【最左匹配原则】,联合索引就会失效(注意这里强调的是联合索引,因为实际情况字段都在联合索引里面,但是其中部分字段生效了,部分字段没生效,所以不能说索引失效)。
总结:使用联合索引时,要想某个字段索引生效,就必须让该字段在查询区间里面是有序的。
比如说,对于第一个字段a,此时的查询区间就是整个B+树,肯定a字段在这里面是有序的。
对于第二个字段b,此时的查询区间是根据a字段的条件筛选出来的,如果可以确保在整个查询区间或查询区间开始的某一段连续区间,字段b在其中是有序的,那么字段b的索引就会生效。
例如 WHERE a = 4 AND b = 78;字段b的查询区间是根据a = 4筛选出的结果,很明显b在其中是有序的,所以字段b会用到索引。(根据key_len可以看出字段b是否被使用)

例如 WHERE a > 4 AND b = 78; 字段b的查询区间是根据a > 4筛选出的结果,不能确保b在其中有序,所以字段b没用到索引。

例如 WHERE a >= 4 AND b = 78;字段b的查询区间是根据a >= 4筛选出的结果,可以确保一开始的时候字段b在a = 4的情况下,字段b是有序的,所以也会使用到索引。(类似还有联合索引 (name,age),WHERE name like '王%' AND age = 60;)

索引下推:
当执行 select * from table where a > 4 and b = 78 语句时,字段a可以用到联合索引,字段b是去主键索引回表判断?还是在联合索引中判断?
- MySQL5.6之前是通过去主键索引查询(回表)做判断。
- MySQL5.6引入索引下推优化,在联合索引遍历过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足的条件的记录,减少回表次数。
索引字段和非索引字段用OR连接
验证:

原因:使用OR意味着两者满足其一即可,其中有个是索引字段,假设走索引去查,另一个不是索引字段,只能通过全表扫描。
这相当于走一次索引+走一次全表,那不如一开始就是全表扫描。