【2023-Pytorch-检测教程】手把手教你使用YOLOV5做麦穗计数
小麦是世界上种植地域最广、面积最大及产量最多的粮食作物,2021年世界小麦使用量达到7.54亿吨。小麦产量的及时预估对作物生产、粮食价格及粮食安全产生重大影响,单位面积穗数是小麦产量预估研究中的难点及重中之重。当前,人工估产方法依据专家目测估计产量,准确率得不到保证。取样估产方法通过采集部分区域,进行人工计数、称重,费时费力。随着计算机视觉技术的发展,大量研究致力于统计单幅图像中麦穗数进而实现估产,此类研究利用卷积神经网络强大的特征自学习能力,对麦穗进行特征提取,通过大量数据训练模型,进而成功实现对图像中麦穗计数,为后续小麦估产提供数据参考。然而部分现有的麦穗计数研究基于通用的原始计数网络,未考虑小麦尺度不一、密集等特点进行优化,准确率有待提升。
本期我们将深度学习算法YOLOV5和农业进行结合,通过目标检测的方式来统计一片区域中的麦穗数量。废话不多说,先看效果。



注意事项
- 尽量使用英文路径,避免中文路径,中文路径可能会导致代码安装错误和图片读取错误。
- pycharm运行代码一定要注意左下角是否在虚拟环境中。
- 库的版本很重要,使用本教程提供的代码将会事半功倍
前期准备
电脑的基础设置以及软件的安装这边不再做赘述,前期的准备工作参考下面博客的内容。
【2023-Pytorch-检测教程】手把手教你使用YOLOV5做电线绝缘子缺陷检测_肆十二的博客-CSDN博客
环境配置
OK,来到关键环境配置的部分,首先大家下载代码之后会得到一个压缩包,在当前文件夹解压之后,进入CMD开始我们的环境配置环节,大家这里应该是yolov5-wheat,我这边用的之前的图,项目名称上有一些差别,大家注意在你麦穗计数的文件中打开即可。

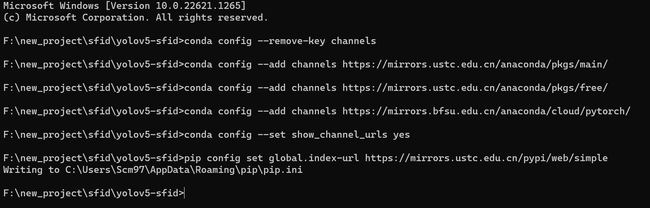
为了加快后期第三方库的安装速度,我们这里需要添加几个国内的源进来,直接复制粘贴下面的这些指令到你的命令行即可。
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
执行完毕大概是下面这个样子,后面你就可以飞速下载这些库了。
创建虚拟环境
首先,我们需要根据我们的项目来创建一个虚拟环境,通过下面的指令创建并激活虚拟环境。
我们创建一个Python版本为3.8.5,环境名称为yolo的虚拟环境。
conda create -n yolo python==3.8.5
conda activate yolo

切记!这里一定要激活你的虚拟环境,否则后续你的库会安装在基础环境中,前面的小括号表示你处于的虚拟环境。
Pytorch安装
注意Pyotorch和其他库不太一样,Pytorch的安装涉及到conda和cudnn,一般而言,对于30系的显卡,我们的cuda不能小于11,对于10和20系的显卡,一般使用的是cuda10.2。下面给出了30系显卡、30系以下显卡和cpu的安装指令,请大家根据自己的电脑配置自行下载。笔者这里是3060的显卡,所以执行的是第一条指令。
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 10系和20系以及mx系列的执行这条
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
安装之后,可以和笔者一样,输入下面的指令测试以下gpu是否可用,如果输出的是true表示GPU是可用的。

其余库安装
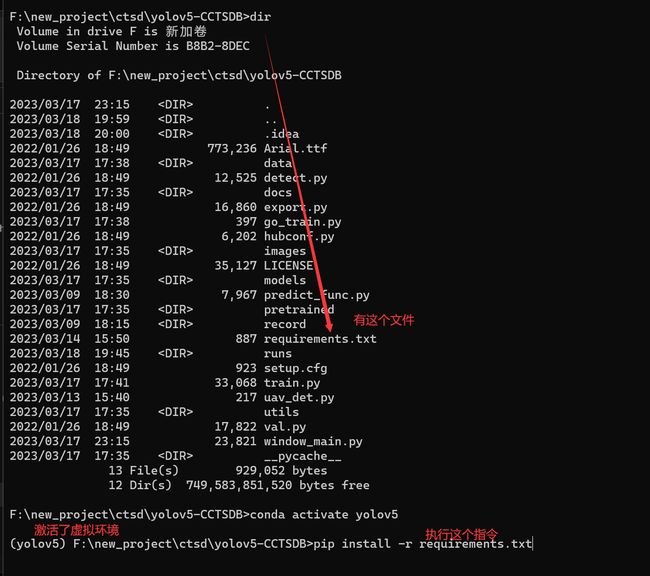
其余库的安装就非常简单了,我们通过pip来进行安装,注意这里一定要确保你执行的目录下有requirements.txt这个文件,否则你将会遇到文件找不到的bug,你可以通过dir指令来查看是否有这个文件。
pip install -r requirements.txt
Pycharm中运行
一是为了查看代码方便,二是为了运行方便,这里我们使用Pycharm打开项目,点击这里右键文件夹直接打开项目即可非常方便。
打开之后你将会看到这样的一个界面,其中左侧是文件浏览器,中间是编辑器,下方是一些工具,右下角是你所处的虚拟环境 。

之后,我们就需要为当前的项目选择虚拟环境了,这一步非常重要,有的兄弟配置好了没选环境,你将会遇到一堆奇怪的bug,选环境的步骤如下。
首先点击,添加解释器。

三步走选择我们刚才创建的虚拟环境,点击ok。


之后你可以你可以右键执行main_window.py这个文件,出现下面的画面说明你就成功了。

数据集准备
数据集这里我放在了CSDN中,大家可以执行标注准备数据集,或者使用这里我处理好的数据集,数据集下载之后放在和代码目录同级的wheat_yolo_format目录下。
数据集打开之后你将会看到两个文件夹,images目录存放图片文件,labels目录存放标签文件。

之后记住你这里的数据集路径,在后面的训练中我们将会使用到,比如笔者这里的F:/new_project/02mai/wheat_yolo_format。
训练和测试
注:这里你可以选择去自己尝试以下,笔者在runs的train目录下已经放了训练好的模型,你是可以直接使用。

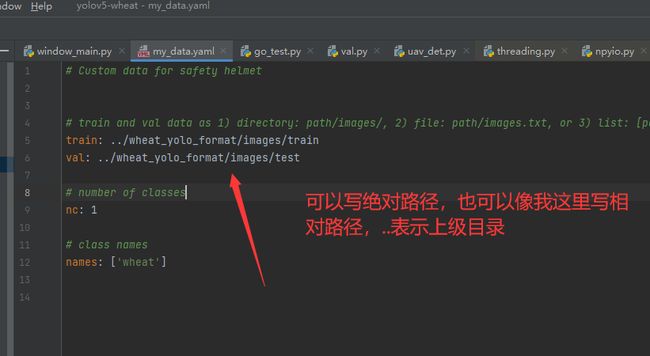
下面就是训练的过程,笔者这里已经将数据集和模型的配置文件写好了,你只需要将数据集中的数据路径替换成你的路径,执行go_train.py即可开始训练了。
执行go_train.py文件中,包含三条指令,分别表示yolov5中small模型、medium模型和large模型,比如我这里要训练s模型,我就将其他两个模型训练的指令注释掉就好了。

运行之后,下方会输出运行的信息,这里的红色只是日志信息,不是报错,大家不要惊慌。

以笔者这里的s模型为例,详细含义如下。

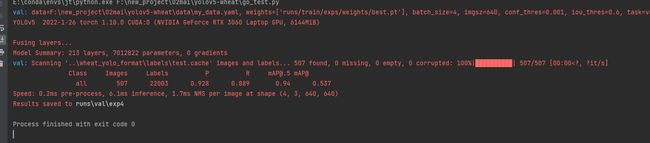
如果大家要测试的话就使用go_test.py,其中三行分别表示s模型、m模型和l模型的测试指令。

测试结果如下:
图形化程序
最后就是执行我们的图形化界面程序了。

直接右键执行window_main.py执行即可,这里上两章效果图。
