【论文笔记四2019 CVPR】Domain-Symmetric Networks for Adversarial Domain Adaptation (SymNets) 用于对抗域自适应的域对称网络
摘要
深度网络通过对抗训练学习域不变性特征,但域自适应技术在源域和目标域实现类别层级的对齐仍然是有限的。本文提出了SymNets模型在对齐源域和目标域的边缘分布的同时也增强了对两个域中条件分布的对齐,从而实现类别层级的对齐。在领域自适应中源域和目标域上的任务是一致的,为此SymNets设计了一个对称的任务分类器结构,也就是说传统的分类器是有K个神经元对应K个类别,而SymNets为源域和目标域分别设计K个神经元。此外,利用这个对称结构可以构建一个和这两个分类器共享权重的额外分类器(域辨别器)。本文设计了6个loss函数进行模型的训练(这容易导致模型训练难收敛的问题)。在模型的域混淆训练中设计了两个层级的混淆,其中类别级的混淆损失助于特征提取器学习两个领域相对应类别的域不变性特征;域级的混淆损失助于特征提取器学习两个领域整体的域不变性特征。由于目标域无标签,对于目标域的分类器的有监督训练部分,本文提出用源域的有标签数据帮助学习出。
SymNet的架构和目标函数
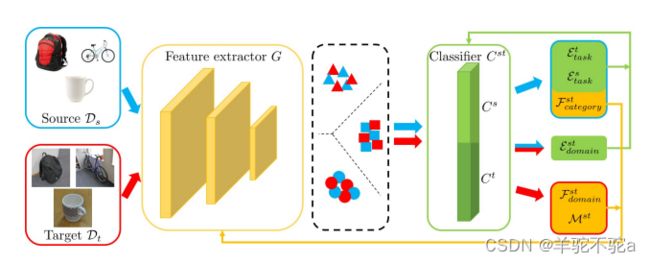
提出的SymNet的架构,它包括一个特征提取器G和三个分类器
、
和
。分类器
在SymNets网络中,分类器C有两个并行的任务分类器![]() 和
和![]() ,它们都拥有K个神经元对应类别数,此外,本文还设计了一个与
,它们都拥有K个神经元对应类别数,此外,本文还设计了一个与![]() 和
和![]() 共享神经元的分类器
共享神经元的分类器![]() ,它拥有2K个神经元。(PS:其实就是一个拥有2K个神经元的分类器模型同时干了三件事情)。注意这里,在本文设计的网络中没有一个明确的域辨别器,域辨别和域混淆是通过对分类器Cst设计损失函数实现的,下面我们先讲解一下怎么训练
,它拥有2K个神经元。(PS:其实就是一个拥有2K个神经元的分类器模型同时干了三件事情)。注意这里,在本文设计的网络中没有一个明确的域辨别器,域辨别和域混淆是通过对分类器Cst设计损失函数实现的,下面我们先讲解一下怎么训练![]() 和
和![]() 分类器。
分类器。
源任务分类器和目标任务分类器的对称设计
1)首先,对于![]() ,就是利用源域数据做有监督分类的交叉熵损失:
,就是利用源域数据做有监督分类的交叉熵损失:
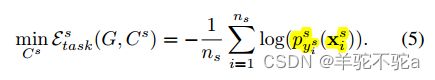
2)由于目标样本是未标记的,因此不存在用于学习任务分类器![]() 的直接监督信号。所以本文借助有标签的源域数据对目标域上的分类器计算交叉熵损失:
的直接监督信号。所以本文借助有标签的源域数据对目标域上的分类器计算交叉熵损失:
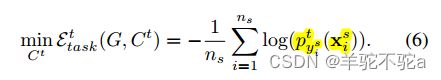
利用源域有标签样例训练目标域分类器。形式上看上去和式子(5)没有区别。但是通过![]()
实现与源域分类器的区分。同时,建立了源域目标域分类器之间神经元的对应关系是后续类别级对齐的基础。
3)通过设计一个与源域目标域分类器共享神经元的![]() 来区分样例的不同域。对于
来区分样例的不同域。对于![]() 可以当作域辨别器,为此本文设计域辨别损失进行训练达到域辨别的效果,通过一个双向交叉熵损失来表示:
可以当作域辨别器,为此本文设计域辨别损失进行训练达到域辨别的效果,通过一个双向交叉熵损失来表示:
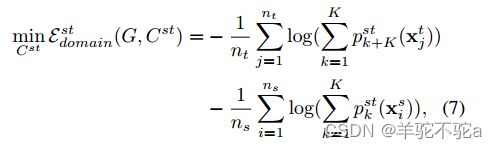
其中![]() 和
和![]() 分别代表样本被分为目标域或源域的概率。可以理解为对于源域数据,它希望让分类器
分别代表样本被分为目标域或源域的概率。可以理解为对于源域数据,它希望让分类器![]() 上半部分所占的概率尽可能大,对于目标域数据,它希望让分类器
上半部分所占的概率尽可能大,对于目标域数据,它希望让分类器![]() 下半部分所占的概率尽可能大。 直观图域对称网络的两级域混淆训练
下半部分所占的概率尽可能大。 直观图域对称网络的两级域混淆训练
理想情况下,对于
,
的概率将大于
。类似地,对于类别k的目标样本
,
上述三个损失主要作用就是训练两个分类器Cs和Ct,和这个共享权重的分类器Cst。
域对称网络的两级域混淆训练
所提出的两级损失旨在最大限度地“混淆”这两个领域,以使特征和类别在它们之间的联合分布保持一致。
4)对于类别级混淆损失,本文这里使用的是有标签的源域样本来计算类别级混淆损失, 对于类别k的源样本,我们识别其在![]() 中对应的第k个和第(k+K)个神经元对,并使用该神经元对的预测和均匀分布之间的交叉熵,可以理解为让分类器Cst在源域和目标域上对应的预测类别概率都尽可能大:
中对应的第k个和第(k+K)个神经元对,并使用该神经元对的预测和均匀分布之间的交叉熵,可以理解为让分类器Cst在源域和目标域上对应的预测类别概率都尽可能大:

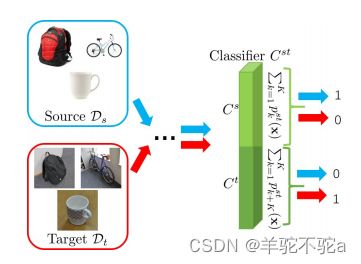
5)为了产生域级别的混淆损失,我们使用未标记的目标样本,因为在域级别混淆不需要标签信息。对于目标样本,我们简单地使用来自![]() 中两个半组神经元的聚合预测和均匀分布之间的交叉熵,这给出了学习特征提取器G的以下目标:
中两个半组神经元的聚合预测和均匀分布之间的交叉熵,这给出了学习特征提取器G的以下目标:
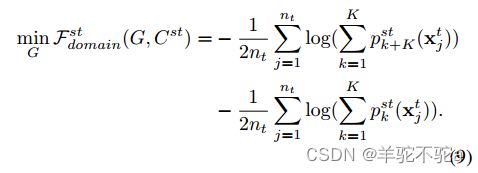
6)此外,我们提出了以下熵最小化目标,提升目标域上相应类别预测的置信度,该目标通过对![]() 中每对类别对应神经元的概率求和来增强任务类别之间的区分:
中每对类别对应神经元的概率求和来增强任务类别之间的区分:
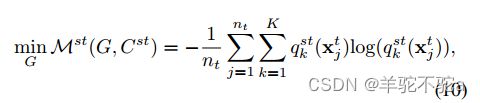
其中![]() ,这里这个损失本文没有让它更新分类器,只更新特征提取器。因为在训练的早期阶段,由于域之间较大的差异,目标域的数据可能会被卡在某个错误的类别中很难再纠正过来了。
,这里这个损失本文没有让它更新分类器,只更新特征提取器。因为在训练的早期阶段,由于域之间较大的差异,目标域的数据可能会被卡在某个错误的类别中很难再纠正过来了。
域对称网络的总体训练目标
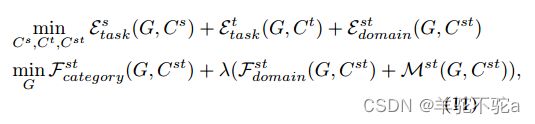
结合损失(5),(6)和(7)来更新分类器,类别和领域级别混淆的损失(8)和(9)来更新特征提取器G以及正则器(10) 。
总结
我们提出了一种新的对抗性学习方法,称为域对称网络(SymNets),以克服通过两级域混淆损失来调整特征和类别在域之间的联合分布的限制。类别级别的混淆损失通过驱动中间网络特征的学习在两个域的相应类别上是不变的而在域级别上有所改善。作为SymNets的一个组成部分,通过跨域训练方案学习显式目标任务分类器。在三个基准数据集上的实验验证了我们提出的SymNets的有效性。
train.py
import time
import torch
import os
import math
import ipdb
import torch.nn.functional as F
def train(source_train_loader, source_train_loader_batch, target_train_loader, target_train_loader_batch, model, criterion_classifier_source, criterion_classifier_target, criterion_em_target, criterion, optimizer, epoch, epoch_count_dataset, args):
batch_time = AverageMeter()
data_time = AverageMeter()
losses_classifier = AverageMeter()
losses_G = AverageMeter()
top1_source = AverageMeter()
top1_target = AverageMeter()
model.train()
new_epoch_flag = False
end = time.time()
try:
(input_source, target_source) = source_train_loader_batch.__next__()[1]
except StopIteration:
if epoch_count_dataset == 'source':
epoch = epoch + 1
new_epoch_flag = True
source_train_loader_batch = enumerate(source_train_loader)
(input_source, target_source) = source_train_loader_batch.__next__()[1]
try:
(input_target, _) = target_train_loader_batch.__next__()[1]
except StopIteration:
if epoch_count_dataset == 'target':
epoch = epoch + 1
new_epoch_flag = True
target_train_loader_batch = enumerate(target_train_loader)
(input_target, _) = target_train_loader_batch.__next__()[1]
data_time.update(time.time() - end)
'''cst中下半部分目标分类器的标签'''
target_source_temp = target_source + args.num_classes
target_source_temp = target_source_temp.cuda(async=True)
target_source_temp_var = torch.autograd.Variable(target_source_temp) #### labels for target classifier
'''cst中上半部分源分类器的标签'''
target_source = target_source.cuda(async=True)
input_source_var = torch.autograd.Variable(input_source)
target_source_var = torch.autograd.Variable(target_source) ######## labels for source classifier.
############################################ for source samples
output_source = model(input_source_var) #维度(batch_size,num_classes*2)
'''loss_task_s_Cs将前args.num_classes个类别的预测与源标签进行交叉熵计算;
loss_task_s_Ct将后args.num_classes个类别的预测与源标签进行交叉熵计算'''
loss_task_s_Cs = criterion(output_source[:,:args.num_classes], target_source_var)
loss_task_s_Ct = criterion(output_source[:,args.num_classes:], target_source_var)
loss_domain_st_Cst_part1 = criterion_classifier_source(output_source)
loss_category_st_G = 0.5 * criterion(output_source, target_source_var) + 0.5 * criterion(output_source, target_source_temp_var)
input_target_var = torch.autograd.Variable(input_target)
output_target = model(input_target_var)
loss_domain_st_Cst_part2 = criterion_classifier_target(output_target)
loss_domain_st_G = 0.5 * criterion_classifier_target(output_target) + 0.5 * criterion_classifier_source(output_target)
loss_target_em = criterion_em_target(output_target)
lam = 2 / (1 + math.exp(-1 * 10 * epoch / args.epochs)) - 1
if args.flag == 'no_em':
loss_classifier = loss_task_s_Cs + loss_task_s_Ct + loss_domain_st_Cst_part1 + loss_domain_st_Cst_part2 ### used to classifier
loss_G = loss_category_st_G + lam * loss_domain_st_G ### used to feature extractor
elif args.flag == 'symnet': #
loss_classifier = loss_task_s_Cs + loss_task_s_Ct + loss_domain_st_Cst_part1 + loss_domain_st_Cst_part2 ### used to classifier
loss_G = loss_category_st_G + lam * (loss_domain_st_G + loss_target_em) ### used to feature extractor
else:
raise ValueError('unrecognized flag:', args.flag)
# mesure accuracy and record loss
prec1_source, _ = accuracy(output_source.data[:, :args.num_classes], target_source, topk=(1,5))
prec1_target, _ = accuracy(output_source.data[:, args.num_classes:], target_source, topk=(1,5))
losses_classifier.update(loss_classifier.data[0], input_source.size(0))
losses_G.update(loss_G.data[0], input_source.size(0))
top1_source.update(prec1_source[0], input_source.size(0))
top1_target.update(prec1_target[0], input_source.size(0))
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
'''获取output中每个样本的前maxk个预测结果,并将结果按大小排序
返回两个张量,第一个是每个样本前k个预测结果的概率值,第二个是其索引'''
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
'''将前k个预测结果的准确率通过view(-1)方法将数据展平成一维张量,然后进行求和,得到正确的预测数量。最后返回不同topk值下的准确率列表'''
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return resmain.py
import json
import os
import shutil
import time
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim
from data.prepare_data import generate_dataloader # Prepare the data and dataloader
from models.resnet import resnet # The model construction
from opts import opts # The options for the project
from trainer import train # For the training process
from trainer import validate # For the validate (test) process
from trainer import adjust_learning_rate
from models.DomainClassifierTarget import DClassifierForTarget
from models.DomainClassifierSource import DClassifierForSource
from models.EntropyMinimizationPrinciple import EMLossForTarget
import ipdb
best_prec1 = 0
def main():
global args, best_prec1
current_epoch = 0
epoch_count_dataset = 'source' ##
args = opts()
if args.arch == 'alexnet':
raise ValueError('the request arch is not prepared', args.arch)
# model = alexnet(args)
# for param in model.named_parameters():
# if param[0].find('features1') != -1:
# param[1].require_grad = False
elif args.arch.find('resnet') != -1:
model = resnet(args)
else:
raise ValueError('Unavailable model architecture!!!')
# define-multi GPU
#分块在指定设备之间拆分输入来并行化给定模块的应用进程。
model = torch.nn.DataParallel(model).cuda()
print(model)
criterion_classifier_target = DClassifierForTarget(nClass=args.num_classes).cuda()
criterion_classifier_source = DClassifierForSource(nClass=args.num_classes).cuda()
criterion_em_target = EMLossForTarget(nClass=args.num_classes).cuda()
criterion = nn.CrossEntropyLoss().cuda()DomainClassifierSource.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
def _assert_no_grad(variable):
assert not variable.requires_grad, \
"nn criterions don't compute the gradient w.r.t. targets - please " \
"mark these variables as volatile or not requiring gradients"
class _Loss(nn.Module):
def __init__(self, size_average=True):
super(_Loss, self).__init__()
self.size_average = size_average
class _WeightedLoss(_Loss):
def __init__(self, weight=None, size_average=True):
super(_WeightedLoss, self).__init__(size_average)
self.register_buffer('weight', weight)
class DClassifierForSource(_WeightedLoss):
def __init__(self, weight=None, size_average=True, ignore_index=-100, reduce=True, nClass=10):
super(DClassifierForSource, self).__init__(weight, size_average)
self.nClass = nClass
'''对输入数据进行softmax运算,对到每个类别的概率;如果概率中某些值为0,则对这些值进行加权操作,避免log(0)的情况'''
def forward(self, input):
# _assert_no_grad(target)
batch_size = input.size(0)
prob = F.softmax(input, dim=1)
if (prob.data[:, :self.nClass].sum(1) == 0).sum() != 0: ########### in case of log(0)
soft_weight = torch.FloatTensor(batch_size).fill_(0)
soft_weight[prob[:, :self.nClass].sum(1).data.cpu() == 0] = 1e-6
soft_weight_var = Variable(soft_weight).cuda()
loss = -((prob[:, :self.nClass].sum(1) + soft_weight_var).log().mean())
else:
loss = -(prob[:, :self.nClass].sum(1).log().mean())
return loss