【23-24 秋学期】NNDL 作业7 基于CNN的XO识别
一、用自己的语言解释以下概念
1.局部感知、权值共享:局部感知是指网络中的每个神经元只关注输入数据的一个局部区域,而不是整个数据。这种局部感知的方式使得网络可以更加专注于输入数据的局部特征,从而更好地理解和分类数据。权值共享是指在整个网络中,同一个卷积核的权值是相同的,即卷积操作使用的滤波器是共享的。这种权值共享的方式可以减少网络的参数数量,提高网络的泛化能力。
2.池化:池化(子采样、降采样、汇聚)是一种常见的深度学习技术,通常用于减少数据的维度和计算复杂度。通过池化操作,可以将输入数据的尺寸减小,从而减少网络的参数数量和计算量。池化操作通常会带来以下好处:减少过拟合、提高泛化能力、减少计算量和内存占用、提高网络的可扩展性。然而,池化操作也存在一些坏处,例如可能会丢失一些重要的信息,导致网络的性能下降。
3.全卷积网络:它只包含卷积层、激活函数和池化层,没有全连接层。这种网络结构可以有效地处理图像分割、目标检测等任务,因为它可以自动学习到更加高级的特征。全卷积网络的优点包括:可以处理任意尺寸的输入图像、可以端到端训练、可以自动学习特征等。然而,全卷积网络也存在一些缺点,例如可能会产生梯度消失或爆炸的问题,导致网络难以训练。
4.低级特征、中级特征、高级特征:低级特征、中级特征和高级特征是计算机视觉领域中的三个概念,通常用于描述图像处理的不同阶段。低级特征通常包括颜色、边缘、纹理等基本属性,这些特征可以在图像的局部区域中提取出来。中级特征通常包括角点、边缘、纹理等更复杂的属性,这些特征可以在图像的较大区域内提取出来。高级特征通常包括物体、人脸等更高级别的属性,这些特征需要在图像的全局范围内提取出来。
5.多通道。N输入,M输出是如何实现的:在输入端,每个像素点可以包含多个通道的数据,例如RGB图像的每个像素点包含三个通道的颜色信息。在输出端,每个神经元也可以包含多个通道的输出数据,例如在目标检测任务中,每个目标可能会输出多个通道的特征表示。多通道输入和多通道输出的实现方式是通过卷积操作和激活函数来实现的。
6.1×1的卷积核有什么作用:1×1的卷积核可以用来实现跨通道的连接和信息整合,它可以增加网络的深度和表达能力。
二、使用CNN进行XO识别
1.复现参考资料中的代码
# https://blog.csdn.net/qq_53345829/article/details/124308515
import torch
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
path_test = r'test_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_test = datasets.ImageFolder(path_test, transform=transforms)
print("size of train_data:",len(data_train))
print("size of test_data:",len(data_test))
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
data_loader_test = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(data_loader_test):
images, labels = data
print(images.shape)
print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss() # 损失函数 交叉熵损失函数
optimizer = optim.SGD(model.parameters(), lr=0.1) # 优化函数:随机梯度下降
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(data_loader):
images, label = data
out = model(images)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
print('finished train')
# 保存模型 torch.save(model.state_dict(), model_path)
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是模型, 不止是w和b权重值
# 读取模型
model = torch.load('model_name1.pth')
# https://blog.csdn.net/qq_53345829/article/details/124308515
import torch
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.optim as optim
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'train_data'
path_test = r'test_data'
data_train = datasets.ImageFolder(path, transform=transforms)
data_test = datasets.ImageFolder(path_test, transform=transforms)
print("size of train_data:", len(data_train))
print("size of test_data:", len(data_test))
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
data_loader_test = DataLoader(data_test, batch_size=64, shuffle=True)
print(len(data_loader))
print(len(data_loader_test))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
x = self.maxpool(self.relu(self.conv1(x)))
x = self.maxpool(self.relu(self.conv2(x)))
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 读取模型
model = Net()
model.load_state_dict(torch.load('model_name1.pth', map_location='cpu')) # 导入网络的参数
# model_load = torch.load('model_name1.pth')
# https://blog.csdn.net/qq_41360787/article/details/104332706
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in data_loader_test: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
# "_," 的解释 https://blog.csdn.net/weixin_48249563/article/details/111387501import numpy as np
import matplotlib.pyplot as plt
x = np.array([[-1, -1, -1, -1, -1, -1, -1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, -1, -1, 1, -1, -1, -1, -1],
[-1, -1, -1, 1, -1, 1, -1, -1, -1],
[-1, -1, 1, -1, -1, -1, 1, -1, -1],
[-1, 1, -1, -1, -1, -1, -1, 1, -1],
[-1, -1, -1, -1, -1, -1, -1, -1, -1]])
print("x=\n", x)
plt.imshow(x, cmap='gray')
plt.title('Original')
plt.show()
# 初始化 三个 卷积核
Kernel = [[0 for i in range(0, 3)] for j in range(0, 3)]
Kernel[0] = np.array([[1, -1, -1],
[-1, 1, -1],
[-1, -1, 1]])
Kernel[1] = np.array([[1, -1, 1],
[-1, 1, -1],
[1, -1, 1]])
Kernel[2] = np.array([[-1, -1, 1],
[-1, 1, -1],
[1, -1, -1]])
# --------------- 卷积 ---------------
stride = 1 # 步长
feature_map_h = 7 # 特征图的高
feature_map_w = 7 # 特征图的宽
feature_map = [0 for i in range(0, 3)] # 初始化3个特征图
for i in range(0, 3):
feature_map[i] = np.zeros((feature_map_h, feature_map_w)) # 初始化特征图
for h in range(feature_map_h): # 向下滑动,得到卷积后的固定行
for w in range(feature_map_w): # 向右滑动,得到卷积后的固定行的列
v_start = h * stride # 滑动窗口的起始行(高)
v_end = v_start + 3 # 滑动窗口的结束行(高)
h_start = w * stride # 滑动窗口的起始列(宽)
h_end = h_start + 3 # 滑动窗口的结束列(宽)
window = x[v_start:v_end, h_start:h_end] # 从图切出一个滑动窗口
for i in range(0, 3):
feature_map[i][h, w] = np.divide(np.sum(np.multiply(window, Kernel[i][:, :])), 9)
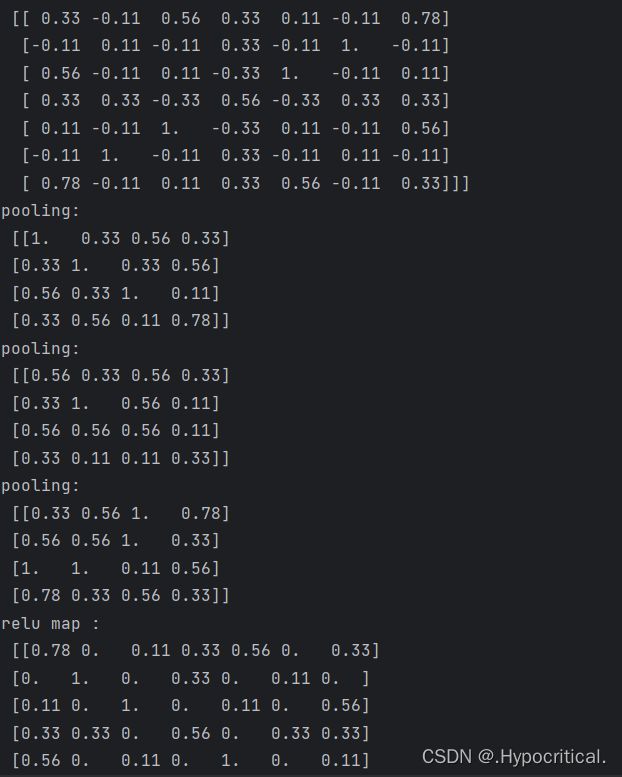
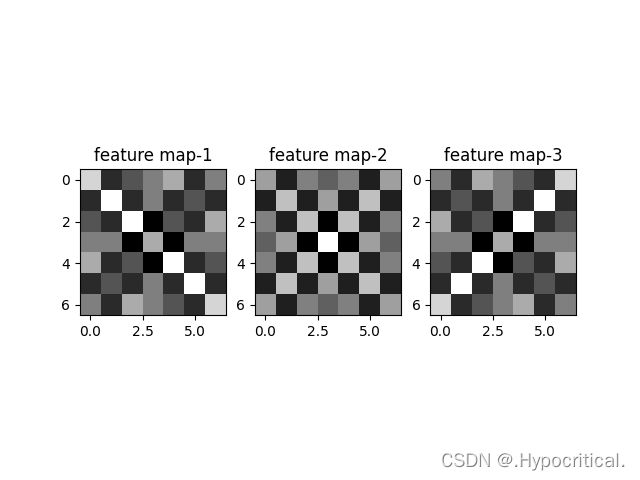
print("feature_map:\n", np.around(feature_map, decimals=2))
plt.subplot(131)
plt.imshow(np.around(feature_map, decimals=2)[0], cmap='gray')
plt.title('feature map-1')
plt.subplot(132)
plt.imshow(np.around(feature_map, decimals=2)[1], cmap='gray')
plt.title('feature map-2')
plt.subplot(133)
plt.imshow(np.around(feature_map, decimals=2)[2], cmap='gray')
plt.title('feature map-3')
plt.show()
# --------------- 池化 ---------------
pooling_stride = 2 # 步长
pooling_h = 4 # 特征图的高
pooling_w = 4 # 特征图的宽
feature_map_pad_0 = [[0 for i in range(0, 8)] for j in range(0, 8)]
for i in range(0, 3): # 特征图 补 0 ,行 列 都要加 1 (因为上一层是奇数,池化窗口用的偶数)
feature_map_pad_0[i] = np.pad(feature_map[i], ((0, 1), (0, 1)), 'constant', constant_values=(0, 0))
# print("feature_map_pad_0 0:\n", np.around(feature_map_pad_0[0], decimals=2))
pooling = [0 for i in range(0, 3)]
for i in range(0, 3):
pooling[i] = np.zeros((pooling_h, pooling_w)) # 初始化特征图
for h in range(pooling_h): # 向下滑动,得到卷积后的固定行
for w in range(pooling_w): # 向右滑动,得到卷积后的固定行的列
v_start = h * pooling_stride # 滑动窗口的起始行(高)
v_end = v_start + 2 # 滑动窗口的结束行(高)
h_start = w * pooling_stride # 滑动窗口的起始列(宽)
h_end = h_start + 2 # 滑动窗口的结束列(宽)
for i in range(0, 3):
pooling[i][h, w] = np.max(feature_map_pad_0[i][v_start:v_end, h_start:h_end])
print("pooling:\n", np.around(pooling[0], decimals=2))
plt.subplot(131)
plt.imshow(np.around(pooling[0], decimals=2), cmap='gray')
plt.title('pooling-1')
print("pooling:\n", np.around(pooling[1], decimals=2))
plt.subplot(132)
plt.imshow(np.around(pooling[1], decimals=2), cmap='gray')
plt.title('pooling-2')
print("pooling:\n", np.around(pooling[2], decimals=2))
plt.subplot(133)
plt.imshow(np.around(pooling[2], decimals=2), cmap='gray')
plt.title('pooling-3')
plt.show()
# --------------- 激活 ---------------
def relu(x):
return (abs(x) + x) / 2
relu_map_h = 7 # 特征图的高
relu_map_w = 7 # 特征图的宽
relu_map = [0 for i in range(0, 3)] # 初始化3个特征图
for i in range(0, 3):
relu_map[i] = np.zeros((relu_map_h, relu_map_w)) # 初始化特征图
for i in range(0, 3):
relu_map[i] = relu(feature_map[i])
plt.figure()
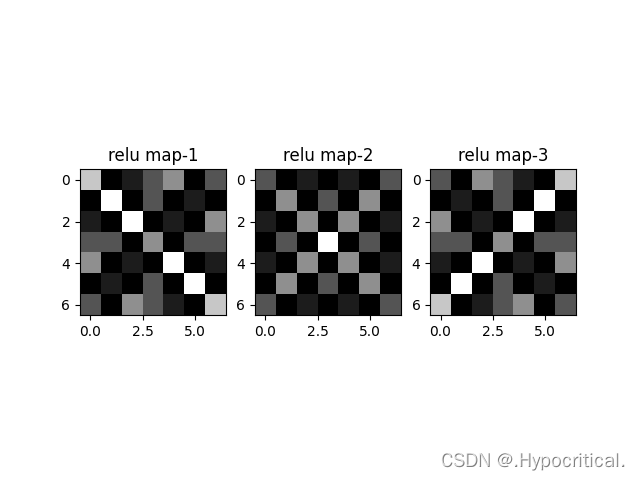
print("relu map :\n", np.around(relu_map[0], decimals=2))
plt.subplot(131)
plt.imshow(np.around(relu_map[0], decimals=2), cmap='gray')
plt.title('relu map-1')
print("relu map :\n", np.around(relu_map[1], decimals=2))
plt.subplot(132)
plt.imshow(np.around(relu_map[1], decimals=2), cmap='gray')
plt.title('relu map-2')
print("relu map :\n", np.around(relu_map[2], decimals=2))
plt.subplot(133)
plt.imshow(np.around(relu_map[2], decimals=2), cmap='gray')
plt.title('relu map-3')
plt.show()复现结果:




2.重新设计网络结构
2.1至少增加一个卷积层,卷积层达到三层以上:
self.conv1 = nn.Conv2d(in_channels=1, out_channels=9, kernel_size=3)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=9, out_channels=9, kernel_size=3)
self.conv3 = nn.Conv2d(in_channels=9, out_channels=5, kernel_size=3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(in_features=12 * 12 * 5, out_features=300)
self.fc2 = nn.Linear(in_features=300, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=2)
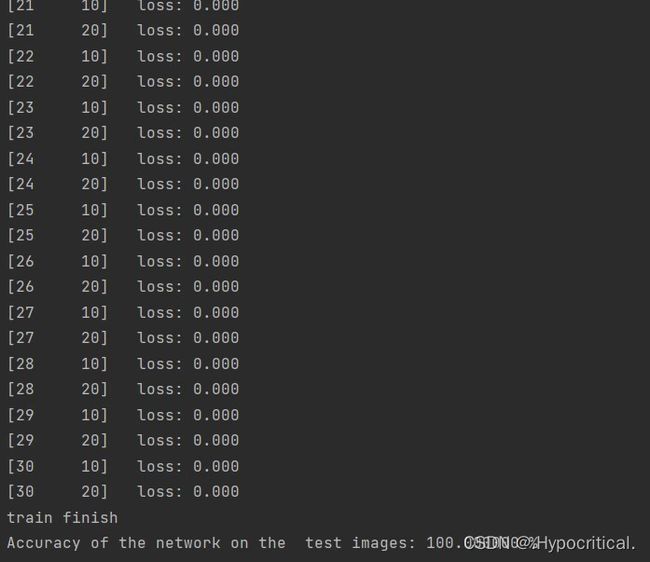
一开始训练完可以看到模型的性能还是非常好的,但是当我在训练多次后发现性能下降了,可能卷积层并不是越多越好。
2.2去掉池化层,对比“有无池化”的效果:
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
# 将输入的图片先转换为灰度图,然后将其转换为 Tensor,并进行归一化处理。这样处理后的数据可以直接作为模型的输入。
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
data_train = datasets.ImageFolder('train_data', transforms)
data_test = datasets.ImageFolder('test_data', transforms)
train_loader = DataLoader(data_train, batch_size=64, shuffle=True)
test_loader = DataLoader(data_test, batch_size=64, shuffle=True)
for i, data in enumerate(train_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
for i, data in enumerate(test_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=9, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=9, out_channels=5, kernel_size=3)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(in_features=112 * 112 * 5, out_features=1200)
self.fc2 = nn.Linear(in_features=1200, out_features=64)
self.fc3 = nn.Linear(in_features=64, out_features=2)
def forward(self, input):
output = self.relu(self.conv1(input))
output = self.relu(self.conv2(output))
output = output.view(-1, 112 * 112 * 5)
output = self.relu(self.fc1(output))
output = self.relu(self.fc2(output))
output = self.fc3(output)
return output
model = CNN()
loss = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
epochs = 10
for epoch in range(epochs):
total_loss = 0.0
for i, data in enumerate(train_loader):
images, labels = data
out = model(images)
one_loss = loss(out, labels)
optimizer.zero_grad()
one_loss.backward()
optimizer.step()
total_loss += one_loss
if (i + 1) % 10 == 0:
print('[%d %5d] loss: %.3f' % (epoch + 1, i + 1, total_loss / 100))
total_loss = 0.0
print('train finish')
torch.save(model, 'model.pth') # 保存的是模型, 不止是w和b权重值
torch.save(model.state_dict(), 'model_name1.pth') # 保存的是w和b权重值
correct = 0
total = 0
with torch.no_grad(): # 进行评测的时候网络不更新梯度
for data in test_loader: # 读取测试集
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取出 最大值的索引 作为 分类结果
total += labels.size(0) # labels 的长度
correct += (predicted == labels).sum().item() # 预测正确的数目
print('Accuracy of the network on the test images: %f %%' % (100. * correct / total))
去掉池化层后模型的性能明显下降了,所以池化层还是很必要的
2.3修改“通道数”等超参数,观察变化:
修改了通道数后,模型的性能没有太大的提升,可能是之前的模型训练就已经够好了,所以这次的改动并没有让模型有一个很大的提升。
3.可视化
import torch
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 #有中文出现的情况,需要u'内容
# 定义图像预处理过程(要与网络模型训练过程中的预处理过程一致)
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'D:\project\DL\training_data_sm'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.maxpool(self.relu(self.conv1(x)))
# outputs.append(x)
x = self.maxpool(self.relu(self.conv2(x)))
outputs.append(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
# create model
model1 = Net()
# load model weights加载预训练权重
model_weight_path = "model_name1.pth"
model1.load_state_dict(torch.load(model_weight_path))
x = images[0]
x = x.reshape([1, x.shape[0], x.shape[1], x.shape[2]])
# forward正向传播过程
out_put = model1(x)
weights_keys = model1.state_dict().keys()
for key in weights_keys:
print("key :", key)
# 卷积核通道排列顺序 [kernel_number, kernel_channel, kernel_height, kernel_width]
if key == "conv1.weight":
weight_t = model1.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, 0, :, :] # 获取第一个卷积核的信息参数
# show 9 kernel ,1 channel
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(k[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel1'
plt.title(title_name)
plt.show()
if key == "conv2.weight":
weight_t = model1.state_dict()[key].numpy()
print("weight_t.shape", weight_t.shape)
k = weight_t[:, :, :, :] # 获取第一个卷积核的信息参数
print(k.shape)
print(k)
plt.figure()
for c in range(9):
channel = k[:, c, :, :]
for i in range(5):
ax = plt.subplot(2, 3, i + 1) # 参数意义:3:图片绘制行数,5:绘制图片列数,i+1:图的索引
plt.imshow(channel[i, :, :], cmap='gray')
title_name = 'kernel' + str(i) + ',channel' + str(c)
plt.title(title_name)
plt.show()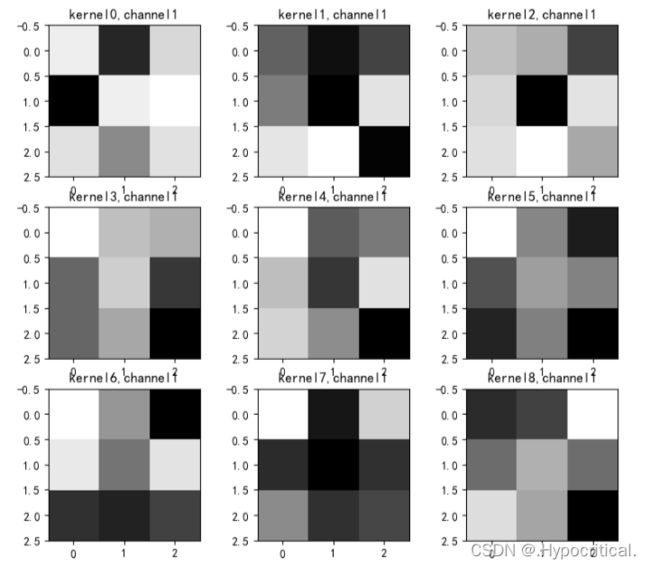
import torch
import matplotlib.pyplot as plt
import numpy as np
from torchvision import transforms, datasets
import torch.nn as nn
from torch.utils.data import DataLoader
# 定义图像预处理过程
transforms = transforms.Compose([
transforms.ToTensor(), # 把图片进行归一化,并把数据转换成Tensor类型
transforms.Grayscale(1) # 把图片 转为灰度图
])
path = r'D:\project\DL\training_data_sm'
data_train = datasets.ImageFolder(path, transform=transforms)
data_loader = DataLoader(data_train, batch_size=64, shuffle=True)
for i, data in enumerate(data_loader):
images, labels = data
print(images.shape)
print(labels.shape)
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 9, 3) # in_channel , out_channel , kennel_size , stride
self.maxpool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(9, 5, 3) # in_channel , out_channel , kennel_size , stride
self.relu = nn.ReLU()
self.fc1 = nn.Linear(27 * 27 * 5, 1200) # full connect 1
self.fc2 = nn.Linear(1200, 64) # full connect 2
self.fc3 = nn.Linear(64, 2) # full connect 3
def forward(self, x):
outputs = []
x = self.conv1(x)
outputs.append(x)
x = self.relu(x)
outputs.append(x)
x = self.maxpool(x)
outputs.append(x)
x = self.conv2(x)
x = self.relu(x)
x = self.maxpool(x)
x = x.view(-1, 27 * 27 * 5)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return outputs
# create model
model1 = Net()
# load model weights加载预训练权重
model_weight_path = "model_name1.pth"
model1.load_state_dict(torch.load(model_weight_path))
# 打印出模型的结构
print(model1)
x = images[0]
x = x.reshape([1, x.shape[0], x.shape[1], x.shape[2]])
# forward正向传播过程
out_put = model1(x)
for feature_map in out_put:
im = np.squeeze(feature_map.detach().numpy())
im = np.transpose(im, [1, 2, 0])
print(im.shape)
plt.figure()
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(im[:, :, i], cmap='gray')
plt.show()
- 低级特征:低级特征通常指的是图像的基本属性,例如边缘、角点、纹理等。这些特征通常是最基本的图像属性,通常被用于图像分割、边缘检测等任务。低级特征通常由图像处理算法提取,例如Sobel、Canny等算法。
- 中级特征:中级特征通常指的是在低级特征的基础上,通过一些更复杂的操作和算法提取出来的特征,例如梯度方向直方图(HOG)、局部二值模式直方图(LBP)等。这些特征通常用于更复杂的任务,例如目标检测和人脸识别等。
- 高级特征:高级特征通常指的是通过深度学习算法,例如卷积神经网络(CNN),从大量的数据中学习到的特征。这些特征通常具有更高的抽象程度,能够表达更复杂的图像属性,例如物体的颜色、形状、纹理等。高级特征通常用于更高级的任务,例如图像分类、目标跟踪等。
总的来说,低级特征、中级特征和高级特征是按照抽象程度逐渐递增的。低级特征通常是最基本的图像属性,中级特征是在低级特征的基础上通过一些更复杂的操作和算法提取出来的,而高级特征则是通过深度学习算法从大量数据中学习到的更抽象的特征。
感悟:
这次自己使用Numpy手写底层代码和使用框架进行卷积池化操作,发现还是框架简单一些,体会到了卷积主要是提取特征,而池化主要偏向于降维,理解卷积过程中的卷积核由来、特征图由来以及卷积核参数的设置。发现不同的卷积核提取的主要特征不同。然后对卷积的理解更加深入了。在写的过程中也遇到一些问题,比如修改参数时一直找不到合适的。在一些概念方面也去看来别人的一些理解。
参考文献:【精选】NNDL 作业6:基于CNN的XO识别-CSDN博客
【2021-2022 春学期】人工智能-作业6:CNN实现XO识别_x = self.conv2(x)#请问经过conv2(x)之后,x的维度是多少-CSDN博客