Flink面试题与详解
Flink面试题目合集
从牛客网上找到的一些面试题,如果还有其他的,欢迎大家补充。
1、能否详细描述下Apache Flink的架构组件和其工作原理?请介绍一下Flink on YARN部署模式的工作原理。
官网图:

由两个部分组成,JM,TM。
JM中包含三个组件,dispatch、jobmaster、resource manager。
dispatch主要是负责提供了rest接口,接受客户端提供的jar包、dataflow、streamgraph等信息,并且运行Flink UI也是该组件运行。
jobmaster主要是负责将dataflow等数据流图转换成真正的物理执行图,如果资源足够启动任务,那么就会将图分发给对应的TM,并且负责任务启动后的协调运行管理,比如checkpoint的协调。
resource manager主要负责资源的申请、释放、分配。管理着Flink的slot。
TM主要是任务执行的地方,根据slot的个数,决定启动的task线程个数。其中每一个TM共享着NetWorkBufferPool、NetWorkEnvironment。NetWorkBufferPool管理着TM的可用的内存MemorySegment,默认是32k。每一个slot线程任务会存在,输入区域inputgate和输出区域result partition,对应两个local buffer pool,这个是根据NetWorkBufferPool进行动态平均分配的。详细了解:Flink 解析(二):反压机制解析_flink的taskmanager内反压过程-CSDN博客
2、Flink的窗口操作有哪些类型,它们之间有什么不同?请举例说明如何定义不同类型的窗口。
直接盗用官网例子。。。
Keyed Windows
stream
.keyBy(...) <- 仅 keyed 窗口需要
.window(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (省略则使用默认 trigger)
[.evictor(...)] <- 可选项:"evictor" (省略则不使用 evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (省略则为 0)
[.sideOutputLateData(...)] <- 可选项:"output tag" (省略则不对迟到数据使用 side output)
.reduce/aggregate/apply()[apply方法已过时,一般使用process,下同] <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
Non-Keyed Windows
stream
.windowAll(...) <- 必填项:"assigner"
[.trigger(...)] <- 可选项:"trigger" (else default trigger)
[.evictor(...)] <- 可选项:"evictor" (else no evictor)
[.allowedLateness(...)] <- 可选项:"lateness" (else zero)
[.sideOutputLateData(...)] <- 可选项:"output tag" (else no side output for late data)
.reduce/aggregate/apply() <- 必填项:"function"
[.getSideOutput(...)] <- 可选项:"output tag"
滚动窗口
基于时间:
// 滚动 event-time 窗口
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.();
// 滚动 processing-time 窗口
input
.keyBy()
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.();
// 长度为一天的滚动 event-time 窗口, 偏移量为 -8 小时。
input
.keyBy()
.window(TumblingEventTimeWindows.of(Time.days(1), Time.hours(-8)))
.();
滑动窗口
// 滑动 event-time 窗口
input
.keyBy()
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.();
// 滑动 processing-time 窗口
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.();
// 滑动 processing-time 窗口,偏移量为 -8 小时
input
.keyBy()
.window(SlidingProcessingTimeWindows.of(Time.hours(12), Time.hours(1), Time.hours(-8)))
.();
如上例子所示,窗口的 assigners 也可以传入可选的 offset 参数。这个参数可以用来对齐窗口。 比如说,不设置 offset 时,长度为一小时的滚动窗口会与 linux 的 epoch 对齐。 你会得到如 1:00:00.000 - 1:59:59.999、2:00:00.000 - 2:59:59.999 等。 如果你想改变对齐方式,你可以设置一个 offset。如果设置了 15 分钟的 offset, 你会得到 1:15:00.000 - 2:14:59.999、2:15:00.000 - 3:14:59.999 等。 一个重要的 offset 用例是根据 UTC-0 调整窗口的时差。比如说,在中国你可能会设置 offset 为 Time.hours(-8)。
基于计数(也分滚动和滑动):
stream.keyBy(可选).countWindow(size)
会话窗口
// 设置了固定间隔的 event-time 会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.();
// 设置了动态间隔的 event-time 会话窗口
input
.keyBy()
.window(EventTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.();
// 设置了固定间隔的 processing-time session 窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.();
// 设置了动态间隔的 processing-time 会话窗口
input
.keyBy()
.window(ProcessingTimeSessionWindows.withDynamicGap((element) -> {
// 决定并返回会话间隔
}))
.();
全局窗口
DataStream input = ...;
input
.keyBy()
.window(GlobalWindows.create())
.(); 3、请详细介绍Apache Flink中的Watermark(水位线)机制。实现Watermark需要哪个接口?应在哪里定义?其主要作用是什么?
watermark是继承了StreamElement,专门触发EventTime窗口计算,其本质其实就是一个时间戳。Watermark 是和事件一个级别的抽象,其内部包含一个成员变量时间戳timestamp,标识当前数据的时间进度。Watermark实际上作为数据流的一部分随数据流流动。如果存在多个数据源时,Flink内部为了保证watermark保持单调递增,Flink会选择所有流入的EventTime中最小的一个向下游流出。从而保证watermark的单调递增和保证数据的完整性。
目前Flink有两种生成watermark的方式
Punctuated:通过数据流中某些特殊标记事件来触发新水位线的生成。这种方式下窗口的触发与时间无关,而是决定于何时收到标记事件,即数据流中每一个递增的eventTime都会产生一个Watermark。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求很高的场景才会选择Punctuated的方式生成watermark。
Periodic:周期性的(如一定时间间隔或者达到一定的记录条数)产生的一个Watermark。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延迟。
如果需要自定义watermark生成,核心是需要实现WatermarkGenerator接口,需要new WatermarkStrategy,然后重写里面的createWatermarkGenerator方法,return 返回我们自己实现的方法。
/**
* {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。
*
* 注意: WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks}
* 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。
*/
@Public
public interface WatermarkGenerator {
/**
* 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或者也可以基于事件数据本身去生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用,也许会生成新的 watermark,也许不会。
*
* 调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
4、能否描述Flink的窗口实现机制是如何工作的?
答案同上。
5、请解释Flink的Checkpoint机制,它是如何工作的?Flink进行Checkpoint时,整个流程是怎样的?Flink的Checkpoint机制主要用来实现什么功能?请描述Flink的checkpoint barrier机制。请描述Flink的分布式快照算法及其工作原理。Flink是如何保证数据在处理过程中不丢失的?
checkpoint主要是全局性的轻量级快照,保存的是所有算子的状态,存储于状态后端,主要用于故障恢复中。主要流程是同步快照、异步上传。通过JM中的checkpoint协调器从source端将barrier插入到数据流中(前提是需要开启checkpoint,默认不开启),当barrier流经算子时,就会触发该算子的checkpoint,暂停计算,然后保存状态,然后异步上传到状态后端中,算子完成checkpoint后就会将barrier广播到下游,从source端到sink端都完成checkpoint才算是完成一次完整的checkpoint,通知给JM的checkpoint协调器更新状态。如果是多数据源的情况下,在配置为barrier对齐时,算子会等待上游的所有的barrier都到齐了,才会开始进行checkpoint,否则就会将先到的数据流中的数据,进行保存,不会进行计算(极端情况,容易导致OOM,以致于反压);若配置为非对齐时,当上游第一个barrier到达算子时,就会触发checkpoint,并且将barrier提前向下游发送,同时除了保存当前状态还需要保存其余数据源的迟到的barrier之前还未处理的数据以及暂未向下游发送的数据,相当于用空间换取时间。下图是非对齐barrier。
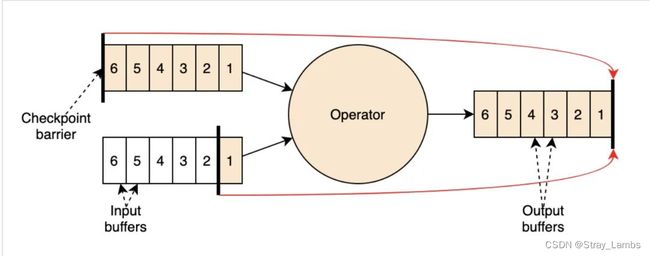
6、Flink的Checkpoint机制是如何在底层实现的?Savepoint和Checkpoint有什么区别?你了解Flink的Savepoint机制吗?它与Checkpoint有何不同?
具体checkpoint实现的源码:Flink-checkPoint机制 | 智能后端和架构
(实在是看不过来。。。)
从概念上讲,Flink 的 savepoints 与 checkpoints 的不同之处类似于传统数据库系统中的备份与恢复日志之间的差异。
Checkpoints 的主要目的是为意外失败的作业提供恢复机制。 Checkpoint 的生命周期 由 Flink 管理, 即 Flink 创建,管理和删除 checkpoint - 无需用户交互。 由于 checkpoint 被经常触发,且被用于作业恢复,所以 Checkpoint 的实现有两个设计目标:i)轻量级创建和 ii)尽可能快地恢复。 可能会利用某些特定的属性来达到这个目标,例如, 作业的代码在执行尝试时不会改变。
- 在用户终止作业后,会自动删除 Checkpoint(除非明确配置为保留的 Checkpoint)。
- Checkpoint 以状态后端特定的(原生的)数据格式存储(有些状态后端可能是增量的)。
尽管 savepoints 在内部使用与 checkpoints 相同的机制创建,但它们在概念上有所不同,并且生成和恢复的成本可能会更高一些。Savepoints的设计更侧重于可移植性和操作灵活性,尤其是在 job 变更方面。Savepoint 的用例是针对计划中的、手动的运维。例如,可能是更新你的 Flink 版本,更改你的作业图等等。
- Savepoint 仅由用户创建、拥有和删除。这意味着 Flink 在作业终止后和恢复后都不会删除 savepoint。
- Savepoint 以状态后端独立的(标准的)数据格式存储(注意:从 Flink 1.15 开始,savepoint 也可以以后端特定的原生格式存储,这种格式创建和恢复速度更快,但有一些限制)。
7、在Flink中,Checkpoint超时可能是由哪些原因造成的?
1、网络原因抖动导致偶发性的失败,一般都会进行失败重启(需要代码里面配置)
2、checkpoint timeout时间不合理,比如timeout的时间给太短了,或者是timeout给太长,导致sink的时候数据一直堆着没有提交。
3、数据倾斜或者是反压。如果是数据倾斜,需要判断监控当中的task的任务状态。如果是反压,那就是有可能计算资源给的不够,或者看看代码中是否存在优化点。
优化方案:Flink优化——数据倾斜(二)-CSDN博客
(如果还有其他原因,欢迎大家补充。。。)
8、Flink如何保证Exactly-Once处理语义?请解释Flink端到端的Exactly-Once处理语义,并描述如何实现。Flink是如何保证数据处理的一致性的?Flink任务如何实现端到端的数据一致性?
通过checkpoint机制和两阶段提交保证的精准一次性。
其中flink内部是通过checkpoint将算子计算的状态定时保存到持久化存储中,如hdfs或者rockdb,在故障恢复时恢复到算子上一次成功保存的状态,重新开始计算,避免数据重复计算以及数据丢失。
两阶段提交流程,当数据来了之后,会开启事务正常写入,但是标记为未提交(预提交),当barrier到达了sink算子并且完成checkpoint后,JM收到了所有任务的通知,开启下一阶段的事务,并且发出确认信息,表示当前阶段的checkpoint已经完成。sink端收到后,开始正式提交预提交的数据。
如果是端到端保持一致性,外部应用数据输入到source要保证Exactly-Once语义。比如kafka可以重置offset,sink到外部应用时,要么保证事务,要么保证幂等性。
9、Flink中的水印(Watermark)有哪几种类型?它们有什么区别?
- 周期性水印(
Periodic WaterMark)如一定时间间隔或者达到一定的记录条数 - 间歇性水印(
Punctuated Watermark)通过数据流中某些特殊标记事件来触发新水位线的生成
真正在底层生成的水印的方法
/**
* {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。
*
* 注意: WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks}
* 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。
*/
@Public
public interface WatermarkGenerator {
/**
* 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或者也可以基于事件数据本身去生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用,也许会生成新的 watermark,也许不会。
*
* 调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
10、请解释Flink中的时间语义,并讨论其在事件时间处理中的重要性。
摄入时间:数据刚到达机器的时间
- 事件进入Flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间
- 不需要指定watermarks的生成方式(自动生成)
- 弱点:不能处理无序时间和延迟数据
处理时间:数据进行计算的机器时间
- 执行操作的机器的当前系统时间(每个算子都不一样)
- 不需要流和机器之间的协调
- 优势:最佳的性能和最低的延迟
- 弱点:不确定性,容易受到各种因素影响(例如event产生的速度、到达flink的速度、在算子之间传输速度等),压根就不管顺序和延迟
事件时间:数据本身的业务时间
- 事件生成的时间,在进入Flink之间就已经存在,可以从event的字段中抽取
- 必须指定watermarks的生成方式
- 优势:确定性,在乱序、延时或者数据重复等情况下,都能给出正确的结果
- 弱点:处理无序事件时性能和延迟受到影响
综上所述:
- 性能:ProcessingTime>IngestTime>EventTime
- 延迟:ProcessingTime
- 确定性:ProcessingTime
- 确定性:ProcessingTime
11、请描述Flink中的背压机制,并说明如何通过监控来识别和解决背压问题。Flink是如何处理反压(Backpressure)问题的?请解释背压(Backpressure)是什么,以及如何在Flink中处理背压问题。
背压机制主要是因为消费速度远远小于生产速度,导致数据积压OOM,最终导致任务失败。主要有两个部分,跨TaskManager的反压过程和TaskManager内的反压过程。在跨TM的反压中,在1.5版本之前如果存在背压情况,采用的是TCP多路复用,所以可能会导致TCP的通道被占用,从而影响其他正常运行的任务。在1.5版本之后,则是基于credit,在向下游传递数据之前,会先发送backlog,告知下游准备发送多少数据,下游则会计算剩余的buffer空间,如果内存不足,则会告知上游最多接受多少数据,防止TCP通道被占用。好处:基于credit的反压过程,效率比之前要高,因为只要下游InputChannel空间耗尽,就能通过credit让上游ResultSubPartition感知到,不需要在通过netty和socket层来一层一层的传递。另外,它还解决了由于一个Task反压导致 TaskManager和TaskManager之间的Socket阻塞的问题。
TM内的反压:每一个TM中都会共享一个network buffer pool,TM中的task的输入区域和输出区域也会分别对应一个local buffer pool,会被分配内存块进行数据传输,如果存在反压那就是从输出区域开始,输出区域可使用的内存块全部被用掉,而输入区域的数据还在源源不断的写入积压,最终导致输入区域的内存块也被用掉了,最终形成反压。
处理反压:
首先根据Flink UI监控指标判断是什么阶段形成的反压。有可能以下情况造成:
系统资源
首先,需要检查机器的资源使用情况,像CPU、网络、磁盘I/O等。如果一些资源负载过高,就可以进行下面的处理:
1、尝试优化代码;
2、针对特定资源对Flink进行调优;
3、增加并发或者增加机器
垃圾回收
性能问题常常源自过长的GC时长。这种情况下可以通过打印GC日志,或者使用一些内存/GC分析工具来定位问题。
CPU/线程瓶颈
有时候,如果一个或者一些线程造成CPU瓶颈,而此时,整个机器的CPU使用率还相对较低,这种CPU瓶颈不容易发现。比如,如果一个48核的CPU,有一个线程成为瓶颈,这时CPU的使用率只有2%。这种情况下可以考虑使用代码分析工具来定位热点线程。
线程争用
跟上面CPU/线程瓶颈问题类似,一个子任务可能由于对共享资源的高线程争用成为瓶颈。同样的,CPU分析工具对于探查这类问题也很有用。
负载不均
如果瓶颈是数据倾斜造成的,可以尝试删除倾斜数据,或者通过改变数据分区策略将造成数据的key值拆分,或者也可以进行本地聚合/预聚合。
上面几项并不是全部场景。通常,解决数据处理过程中的瓶颈问题,进而消除反压,首先需要定位问题节点(瓶颈所在),然后找到原因,寻找原因,一般从检查资源过载开始。
12、Flink如何解决数据处理中的延迟问题?
1、事件时间产生的乱序问题,watermark可以设置延迟时间
2、allowedLateness允许数据的最大延迟时间
3、使用侧输出流 sideOutputLateData
13、如何确定Flink任务的合理并行度?在Flink中,任务的并行度和消费Kafka分区数据之间有什么关系?
最优并行度计算:开发完成之后,先压测,任务并行度给10以下,测试单个并行度的处理上限,然后 总 QPS / 单个并行度的处理上限 = 并行度。 最好根据高峰期的 QPS 压测, 并行度 * 1.2 留有一些富裕资源。
source 端并行度:如果上游数据源是kafka,那么并行度与kafka分区保持一致。如果一致的情况下,还是消费不过来反压,考虑kafka扩大分区,并且flink的并行度与分区数保持一致。flink的一个并行度可以处理多个分区数据,如果并行度多于分区数那么就会造成并行度空闲浪费资源。
transform 端并行度:keyby 之前的算子一般都是跟 source 保持一致。keyby 之后如果并发较大建议设置并行度为 2的整数次幂 。
sink 端并行度: Sink 端是数据流向下游的地方,可以根据 Sink 端的数据量 及 下游的服务抗压能力 进行评估。如果 Sink 端是 Kafka,可以设为 Kafka 对应 Topic 的分区数。Sink 端的数据量小,比较常见的就是监控告警的场景,并行度可以设置的小一些。如果 Sink 端的数据量非常大,那么在 Sink 到下游的存储中间件的时候就需要提高并行度。
另外 Sink 端要与下游的服务进行交互,并行度还得根据下游的服务抗压能力来设置,如果在 Flink Sink 这端的数据量过大的话,且 Sink 处并行度也设置的很大, 但下游的服务完全撑不住这么大的并发写入,可能会造成下游服务直接被写挂,所以最终还是要在 Sink 处的并行度做一定的权衡。
14、请讨论Flink的状态管理机制,包括状态的类型和如何使用。
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。从名称中也能读出两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化;Raw State是开发者自己管理的,需要自己序列化。
| Managed State | Raw State | |
| 状态管理方式 | Flink Runtime托管,自动存储、自动恢复、自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供的常用数据结构,如ListState、MapState等 | 字节数组:byte[] |
| 使用场景 | 绝大多数Flink算子 | 用户自己定义 |
raw state基本不用,所以主要介绍managed state。
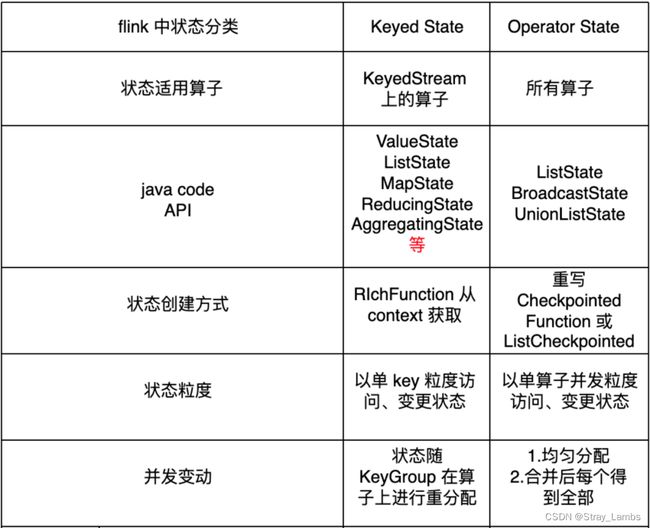
Flink状态只能在rich function中使用,要通过RuntimeContext进行访问,managed state主要具有三种状态
- Keyed State
- Operator State
- Broadcast State(1.5版本之后,特殊的Operator State)
keyed state 主要是在key stream上保存的状态,每一个key都会有对应的一个state,支持的类型有:
valueState 保存一个可以更新和检索的值,通过update进行更新,通过value进行获取。
listState 保存一个元素列表,通过 Iterable
reducingState 保存一个单值,添加到状态的所有值的聚合,接口与 ListState 类似。
AggregatingState
mapState
operator state 需要使用operator State时,我们可以通过实现checkpointedFunction接口。
这个接口主要时提供了访问non-keyed state的方法,主要是需要实现以下两种方法:
void snapshotState(FunctionSnapshotContext context) throws Exception;
void initializeState(FunctionInitializationContext context) throws Exception;operator state 支持的类型:listState、unionListState、BroadcastState
getUnionListState(descriptor)会使用union redistribution算法, 而getListState(descriptor)则简单的是使用even-split redistribution算法。
Even-split redistribution: 每个算子都保存一个列表形式的状态集合,整个状态由所有的列表拼接而成。当作业恢复或重新分配的时候,整个状态会按照算子的并发度进行均匀分配。 比如说,算子 A 的并发读为 1,包含两个元素 element1 和 element2,当并发读增加为 2 时,element1 会被分到并发 0 上,element2 则会被分到并发 1 上。
Union redistribution: 每个算子保存一个列表形式的状态集合。整个状态由所有的列表拼接而成。当作业恢复或重新分配时,每个算子都将获得所有的状态数据。 Do not use this feature if your list may have high cardinality. Checkpoint metadata will store an offset to each list entry, which could lead to RPC framesize or out-of-memory errors.(简单来说就是,如果数据量基数过大,那么不要用这种方法,因为checkpoint的meta数据可能会导致OOM)
并行度变化时:

注意:keyed-state 不能在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的
15、Flink的广播流是什么?它有什么用途?
在Flink中,广播流是一种特殊的数据流类型,用于将一个数据流广播到所有并行任务中,以供每个任务共享和使用。在流上调用DataStream.broadcast()方法并传入MapStateDescriptor作为状态描述符,就可以将它转化为广播流BroadcastStream。该方法的源码如下,注意MapStateDescriptor可以有多个。
public BroadcastStream broadcast(final MapStateDescriptor... broadcastStateDescriptors) {
Preconditions.checkNotNull(broadcastStateDescriptors);
final DataStream broadcastStream = setConnectionType(new BroadcastPartitioner<>());
return new BroadcastStream<>(environment, broadcastStream, broadcastStateDescriptors);
} 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态,比如某些规则或者维表。
在传入的 BroadcastProcessFunction 或 KeyedBroadcastProcessFunction 中,我们需要实现两个方法。processBroadcastElement() 方法负责处理广播流中的元素,processElement() 负责处理非广播流中的元素。 两个子类型定义如下:
public abstract class BroadcastProcessFunction extends BaseBroadcastProcessFunction {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector out) throws Exception;
}
public abstract class KeyedBroadcastProcessFunction {
public abstract void processElement(IN1 value, ReadOnlyContext ctx, Collector out) throws Exception;
public abstract void processBroadcastElement(IN2 value, Context ctx, Collector out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception;
} 这两个方法的区别在于对 broadcast state 的访问权限不同。在处理广播流元素这端,是具有读写权限的,而对于处理非广播流元素这端是只读的。 这样做的原因是,Flink 中是不存在跨 task 通讯的。所以为了保证 broadcast state 在所有的并发实例中是一致的,我们在处理广播流元素的时候给予写权限,在所有的 task 中均可以看到这些元素,并且要求对这些元素处理是一致的, 那么最终所有 task 得到的 broadcast state 是一致的。注:processBroadcastElement() 的实现必须在所有的并发实例中具有确定性的结果。注册一个定时器只能在 KeyedBroadcastProcessFunction 的 processElement() 方法中进行。 在 processBroadcastElement() 方法中不能注册定时器,因为广播的元素中并没有关联的 key。
重要注意事项:
-
没有跨 task 通讯:如上所述,这就是为什么只有在
(Keyed)-BroadcastProcessFunction中处理广播流元素的方法里可以更改 broadcast state 的内容。 同时,用户需要保证所有 task 对于 broadcast state 的处理方式是一致的,否则会造成不同 task 读取 broadcast state 时内容不一致的情况,最终导致结果不一致。 -
broadcast state 在不同的 task 的事件顺序可能是不同的:虽然广播流中元素的过程能够保证所有的下游 task 全部能够收到,但在不同 task 中元素的到达顺序可能不同。 所以 broadcast state 的更新不能依赖于流中元素到达的顺序。
-
所有的 task 均会对 broadcast state 进行 checkpoint:虽然所有 task 中的 broadcast state 是一致的,但当 checkpoint 来临时所有 task 均会对 broadcast state 做 checkpoint。 这个设计是为了防止在作业恢复后读文件造成的文件热点。当然这种方式会造成 checkpoint 一定程度的写放大,放大倍数为 p(=并行度)。Flink 会保证在恢复状态/改变并发的时候数据没有重复且没有缺失。 在作业恢复时,如果与之前具有相同或更小的并发度,所有的 task 读取之前已经 checkpoint 过的 state。在增大并发的情况下,task 会读取本身的 state,多出来的并发(
p_new-p_old)会使用轮询调度算法读取之前 task 的 state。 -
不使用 RocksDB state backend: broadcast state 在运行时保存在内存中,需要保证内存充足。这一特性同样适用于所有其他 Operator State。
16、Flink是否支持JobMaster的高可用性(HA)?其原理是什么?
高可用一般概念是指,在任何时候都有一个领导者 jobManager,如果领导者出现故障,则有多个备用JM来接管领导。保证不存在单点故障。可以通过zookeeper和Kubernetes提供以下高可用服务:
- leader选举: 从n个候选者中选出一个leader
- 服务发现:检索当前leader的地址
- 状态持久化:继承程序恢复作业所需的持久化状态(JobGraph、用户代码jar、已完成的检查点)
17、在不重启Flink的前提下,如何动态修改Flink的配置?
1)通过广播流,去读取最新配置文件,然后将最新的配置广播出去与主流进行connect。
2)通过维表关联,比如lookupjoin,去读取mysql或者redis、tidb等存储的配置信息,然后创建动态表或者其他API(我也不知道还有啥。。。),进行更新最新配置。
如果还有啥方法,欢迎大佬们在评论区补充,我就想到这些了。。
18、在Flink中如何实现实时的Top N处理?
直接看代码。。。
public class WaterMarkWaitingDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream sourceData = env
.addSource(new SensorSource()) // 随机写的一个数据源
.assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofMillis(3000)).withTimestampAssigner((r, ts) -> r.timestamp));//采用事件时间
DataStream> data = sourceData
.keyBy(r -> r.id)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))) // 前一个统计数量,后一个加上end窗口时间
.aggregate(new MyAggregateFunction(), new MyProcessFunction());
data
.keyBy(r -> r.f2)
.process(new TopN(3))
.print();
env.execute();
}
public static class MyAggregateFunction implements AggregateFunction {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(SensorReading sensorReading, Integer integer) {
return integer + 1;
}
@Override
public Integer getResult(Integer integer) {
return integer;
}
@Override
public Integer merge(Integer integer, Integer acc1) {
return null;
}
}
public static class MyProcessFunction extends ProcessWindowFunction, String, TimeWindow> {
@Override
public void process(String s, Context context, java.lang.Iterable iterable, Collector> collector) throws Exception {
Integer cnt = iterable.iterator().next();// 迭代器里面只有一个元素,因为前面聚合函数每个key其实只会有一个聚合后的最终value,可以仔细想想
collector.collect(Tuple3.of(s, cnt, context.window().getEnd()));
}
}
public static class TopN extends KeyedProcessFunction, String> {
private Map>> data;// 个人感觉用mapstate更好点。。。
private int n;
public TopN(int n) {
this.n = n;
data = new HashMap<>();
}
@Override
public void processElement(Tuple3 value, Context context, Collector collector) throws Exception {
Long end = value.f2;
List> tmp = new ArrayList<>();//这里可以考虑剪枝,只保留n个元素就行
if (data.containsKey(end)) {
tmp = data.get(end);
tmp.add(value);
} else {
tmp.add(value);
data.put(end, tmp);
}
context.timerService().registerEventTimeTimer(end + 1); // end窗口+1表示一定触发窗口了
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
super.onTimer(timestamp, ctx, out);
List> tmp = data.get(ctx.getCurrentKey());
tmp.sort(new Comparator>() {
@Override
public int compare(Tuple3 o1, Tuple3 o2) {
return o2.f1 - o1.f1;
}
});
StringBuilder sb = new StringBuilder();
sb.append("==================================\n");
for (int i=0;i t = tmp.get(i);
sb.append("top " + (i+1) + "\n");
sb.append("id = " + t.f0 + "\n");
sb.append("cnt = " + t.f1 + "\n");
sb.append("window end = " + t.f2 + "\n");
sb.append("==================================\n");
}
tmp.clear();
out.collect(sb.toString());
}
}
}
19、Flink SQL是如何进行查询解析和优化的?
等我出个新的博客文章。。太多了。。。
20、请解释一下Flink的流批一体架构。
Flink作为流批一体化的框架,其中流式处理是使用DataStream,而批处理则是使用DataSet。后面的版本已经合并,只需要维护一套DataStream API。其中由以下几个核心组件。
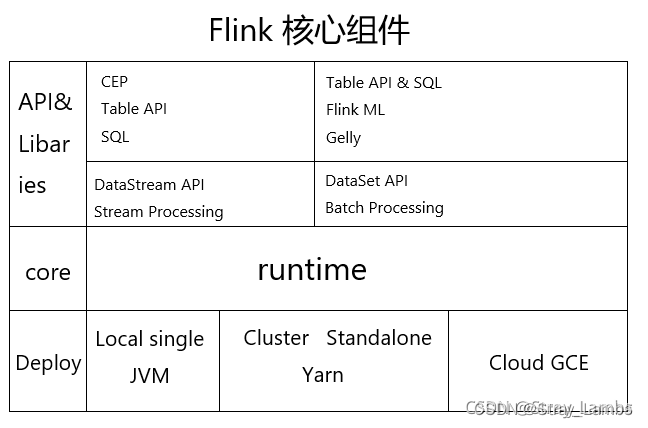
主要执行批任务还是流任务,主要根据数据源是有届还是无界判断。
21、Flink和Spark Streaming在流处理方面有什么不同?在什么情况下应该选择使用Flink?与其他流处理框架相比,Flink有哪些优点?为什么选择使用Flink而不是其他微批处理框架?你考虑过哪些因素?
等我学完spark,一定补上。。。。
22、请介绍一下Flink的复杂事件处理(CEP)库,并给出使用场景的例子。
23、使用Flink Client消费Kafka数据和使用Flink Connector消费有什么不同?