【机器学习】Boosting算法-AdaBoost算法


一、AdaBoost理论
随机森林与AdaBoost算法的比较

AdaBoost算法


AdaBoost模型训练误差分析


从广义加法模型推导出AdaBoost训练算法,从而给出AdaBoost算法在理论上的解释

各种AdaBoost算法对比






标准AdaBoost算法只能用于二分类问题,它的改进型可以用于多分类问题,典型的实现由AdaBoost.MHsuanfa ,多类Logit型AdaBoost

二、示例代码
2.1 自定义AdaBoost算法
# 导入numpy库,用于进行矩阵运算import numpy as np
# 定义一个决策树桩类,作为弱分类器,用于实现AdaBoost算法
class DecisionStump:
""" Use decision stump as weak classifier to
implement adaboost algorithm. """
# 定义初始化方法,设置决策树桩的属性
def __init__(self):
self.polarity = 1 # 设置极性,表示划分的方向,1表示正向,-1表示反向
self.feature_idx = None # 分类特征,用于构造决策树桩的判定属性
self.threshold = None # 分类阈值,小于阈值的样本判定为-1
self.alpha = None # 弱分类器的权值
# 定义一个AdaBoost类,用于实现AdaBoost算法
class AdaBoost:
"""
Attributes:
n_clfs: The number of weak classifiers will be used.
"""
# 定义初始化方法,设置AdaBoost的属性
def __init__(self, n_clfs=5):
self.n_clfs = n_clfs # 设置弱分类器的个数,默认为5
self.clfs = [] # 设置弱分类器的列表,用于存储训练得到的决策树桩
# 定义拟合方法,用于训练每个弱分类器
def fit(self, X_train, y_train):
""" Fit each weak classifier. """
n_samples, n_features = np.shape(X_train) # 获取训练数据的样本数和特征数
# (1) 初始化数据的权值分布
w = np.full(n_samples, (1 / n_samples)) # 将每个样本的权值初始化为1/n
# (2) 选择“桩节点”的属性和阈值、计算弱分类器的权值、更新数据的权值
for _ in range(self.n_clfs): # 循环n_clfs次,每次训练一个弱分类器
clf = DecisionStump() # 生成一棵“空白的”决策树桩
min_error = np.inf # 设置最小误差为无穷大,用于记录最优的分割属性和阈值
# 1) 为决策树桩的“桩节点”选择属性
for i in range(n_features): # 遍历每个特征
feature_values = np.unique(X_train[:, i]) # 获取该特征的所有取值
# 2) 为决策树桩的“桩节点”选择阈值
for threshold in feature_values: # 遍历每个取值作为阈值
p = 1 # 设置极性为1,表示正向划分
prediction = np.ones(np.shape(y_train)) # 初始化预测标签为全1
prediction[X_train[:, i] < threshold] = -1 # 将小于阈值的样本预测为-1
error = np.sum(w[y_train != prediction]) # 计算加权误差
if error > 0.5: # 如果加权误差大于0.5,说明反向划分更好
error = 1 - error # 更新加权误差
p = -1 # 更新极性为-1,表示反向划分
if error < min_error: # 如果加权误差小于当前的最小误差,说明找到了更优的分割属性和阈值
clf.polarity = p # 更新决策树桩的极性
clf.feature_idx = i # 更新决策树桩的分割属性
clf.threshold = threshold # 更新决策树桩的分割阈值
min_error = error # 更新最小误差
# 3) 计算弱分类器的权值
clf.alpha = 0.5 * np.log((1 - min_error) / (min_error + 1e-10)) # 根据加权误差计算弱分类器的权值,加上一个很小的数避免除零错误
self.clfs.append(clf) # 将训练好的决策树桩添加到弱分类器列表中
# 4) 更新数据的权值
predictions = np.ones(np.shape(y_train)) # 初始化预测标签为全1
predictions[clf.polarity * X_train[:, clf.feature_idx] <
clf.polarity * clf.threshold] = -1 # 根据决策树桩的极性、分割属性和分割阈值,将部分样本预测为-1
w *= np.exp(- clf.alpha * y_train * predictions) # 根据弱分类器的权值和预测结果,更新数据的权值,被正确分类的样本权值降低,被错误分类的样本权值升高
w /= np.sum(w) # 归一化权值,使其和为1
# 定义预测方法,用于对测试数据进行分类
def predict(self, X_test):
""" Linear combination of all weak classifiers. """
y_pred = np.zeros(np.shape(X_test)[0]) # 初始化预测标签为全0
# (3) 构建基本分类器的线性组合
for clf in self.clfs: # 遍历每个弱分类器
predictions = np.ones(np.shape(y_pred)) # 初始化预测标签为全1
predictions[clf.polarity * X_test[:, clf.feature_idx] <
clf.polarity * clf.threshold] = -1 # 根据弱分类器的极性、分割属性和分割阈值,将部分样本预测为-1
y_pred += clf.alpha * predictions # 根据弱分类器的权值和预测结果,更新预测标签,进行线性组合
return np.sign(y_pred) # 返回预测标签的符号,+1表示正类,-1表示负类
# 主函数
if __name__ == '__main__':
pass # 省略主函数的内容2.2 实现Adaboost算法: Adaboost是一种集成学习方法,它可以通过组合多个弱分类器来提高分类性能。代码中使用了sklearn库提供的数据集和决策树分类器,以及pandas和matplotlib库来处理数据和绘制图形.
代码的主要步骤如下:
定义了一些辅助函数,如get_error_rate,print_error_rate和generic_clf,用来计算和打印错误率,以及使用通用的分类器进行训练和预测。
定义了adaboost_clf函数,用来实现Adaboost算法的核心逻辑。该函数接受训练集和测试集的数据和标签,以及迭代次数M和基分类器clf作为参数。函数的主要流程是:
初始化训练集的权重w为均匀分布,初始化训练集和测试集的预测结果为零向量。
对于每次迭代,使用当前的权重w来训练基分类器clf,并得到训练集和测试集的预测结果pred_train_i和pred_test_i。
计算预测结果和真实标签的不一致情况,用miss表示,用miss2表示将其转换为1/-1的形式。
计算当前的错误率err_m,以及对应的权重更新系数alpha_m。
更新权重w,使得预测错误的样本权重增加,预测正确的样本权重减少。
将当前的预测结果乘以alpha_m,并累加到之前的预测结果上,形成新的预测结果。
最后将预测结果转换为正负号,表示类别,并返回训练集和测试集的错误率。
定义了plot_error_rate函数,用来绘制训练集和测试集的错误率随迭代次数的变化曲线。该函数接受训练集和测试集的错误率列表作为参数。函数的主要流程是:
创建一个数据框df_error,将训练集和测试集的错误率作为列,将迭代次数作为索引。
使用pandas的plot方法,绘制折线图,设置线宽,图形大小,颜色,网格等属性。
设置x轴和y轴的标签,以及图形的标题。
使用matplotlib的axhline方法,绘制一条水平虚线,表示初始的错误率。
使用matplotlib的show方法,显示图形。
在主程序中,执行以下操作:
使用sklearn的make_hastie_10_2函数,生成一个二分类问题的数据集,包含10000个样本,每个样本有10个特征,标签为+1或-1。
使用pandas创建一个数据框df,将数据集的特征和标签作为列。
使用sklearn的train_test_split函数,将数据集划分为训练集和测试集,测试集占20%,并设置随机种子为42。
使用sklearn的DecisionTreeClassifier函数,创建一个最大深度为1的决策树分类器,作为基分类器,并设置随机种子为1。
使用generic_clf函数,计算决策树分类器在训练集和测试集上的错误率,作为基准。
使用range函数,创建一个从10到410,步长为10的序列,作为不同的迭代次数。
对于每个迭代次数,使用adaboost_clf函数,计算Adaboost算法在训练集和测试集上的错误率,并将其添加到列表中。
使用plot_error_rate函数,绘制训练集和测试集的错误率随迭代次数的变化曲线,观察Adaboost算法的性能。
# 导入需要的模块
import pandas as pd # 用于数据处理和分析
import numpy as np # 用于科学计算
from sklearn.tree import DecisionTreeClassifier # 用于创建决策树分类器
from sklearn.model_selection import train_test_split # 用于将数据集分割为训练集和测试集
from sklearn.datasets import make_hastie_10_2 # 用于生成一个二分类数据集
import matplotlib.pyplot as plt # 用于绘图
""" 辅助函数:获取误差率 ========================================="""
def get_error_rate(pred, Y):
# 用于计算预测结果和真实标签之间的误差率
# 输入:pred是预测结果的数组,Y是真实标签的数组
# 输出:误差率,是一个浮点数
return sum(pred != Y) / float(len(Y)) # 误差率等于预测错误的个数除以总个数
""" 辅助函数:打印误差率 ======================================="""
def print_error_rate(err):
# 用于打印训练集和测试集的误差率
# 输入:err是一个包含训练集和测试集误差率的元组
# 输出:无,只是打印误差率
print ('Error rate: Training: %.4f - Test: %.4f' % err) # 使用格式化字符串打印误差率,保留四位小数
""" 辅助函数:通用分类器 ====================================="""
def generic_clf(Y_train, X_train, Y_test, X_test, clf):
# 用于使用给定的分类器来训练和预测数据,并返回误差率
# 输入:Y_train是训练集的标签数组,X_train是训练集的特征数组,Y_test是测试集的标签数组,X_test是测试集的特征数组,clf是一个分类器对象
# 输出:一个包含训练集和测试集误差率的元组
clf.fit(X_train,Y_train) # 使用训练集的数据和标签来训练分类器
pred_train = clf.predict(X_train) # 使用训练集的数据来预测标签
pred_test = clf.predict(X_test) # 使用测试集的数据来预测标签
return get_error_rate(pred_train, Y_train), \
get_error_rate(pred_test, Y_test) # 返回训练集和测试集的误差率
""" ADABOOST实现 ================================================="""
def adaboost_clf(Y_train, X_train, Y_test, X_test, M, clf):
# 用于使用给定的基分类器来实现AdaBoost算法,并返回误差率
# 输入:Y_train是训练集的标签数组,X_train是训练集的特征数组,Y_test是测试集的标签数组,X_test是测试集的特征数组,M是迭代次数,clf是一个基分类器对象
# 输出:一个包含训练集和测试集误差率的元组
n_train, n_test = len(X_train), len(X_test) # 获取训练集和测试集的长度
# 初始化权重
w = np.ones(n_train) / n_train # 将每个训练样本的权重初始化为相等的值,即1/n_train
pred_train, pred_test = [np.zeros(n_train), np.zeros(n_test)] # 初始化训练集和测试集的预测结果为全零的数组
for i in range(M): # 对于每一次迭代
# 使用特定的权重来训练一个分类器
clf.fit(X_train, Y_train, sample_weight = w) # 使用训练集的数据和标签以及权重来训练分类器
pred_train_i = clf.predict(X_train) # 使用训练集的数据来预测标签
pred_test_i = clf.predict(X_test) # 使用测试集的数据来预测标签
# 指示函数
miss = [int(x) for x in (pred_train_i != Y_train)] # 将预测错误的样本标记为1,预测正确的样本标记为0
# 等价于1/-1来更新权重
miss2 = [x if x==1 else -1 for x in miss] # 将预测错误的样本标记为1,预测正确的样本标记为-1
# 误差
err_m = np.dot(w,miss) / sum(w) # 计算加权的误差率,即权重和预测错误的样本的点积除以权重的和
# Alpha
alpha_m = 0.5 * np.log( (1 - err_m) / float(err_m)) # 计算每个分类器的权重,即0.5乘以误差率的对数几率
# 新的权重
w = np.multiply(w, np.exp([float(x) * alpha_m for x in miss2])) # 更新每个训练样本的权重,即原来的权重乘以指数函数的值
# 添加到预测结果
pred_train = [sum(x) for x in zip(pred_train,
[x * alpha_m for x in pred_train_i])] # 将每个分类器的预测结果乘以其权重,然后累加到训练集的预测结果上
pred_test = [sum(x) for x in zip(pred_test,
[x * alpha_m for x in pred_test_i])] # 将每个分类器的预测结果乘以其权重,然后累加到测试集的预测结果上
pred_train, pred_test = np.sign(pred_train), np.sign(pred_test) # 将训练集和测试集的预测结果转换为正负号,即+1或-1
# 返回训练集和测试集的误差率
return get_error_rate(pred_train, Y_train), \
get_error_rate(pred_test, Y_test)
""" 绘图函数 ==========================================================="""
# 定义绘图函数
def plot_error_rate(er_train, er_test):
# 用于绘制训练集和测试集的误差率随迭代次数变化的曲线图
# 输入:er_train是训练集的误差率的列表,er_test是测试集的误差率的列表
# 输出:无,只是绘制并显示曲线图
df_error = pd.DataFrame([er_train, er_test]).T # 将训练集和测试集的误差率转换为一个数据框
df_error.columns = ['Training', 'Test'] # 设置数据框的列名
plot1 = df_error.plot(linewidth = 3, figsize = (8,6),
color = ['lightblue', 'darkblue'], grid = True) # 使用数据框的plot方法来绘制曲线图,设置线宽,图形大小,颜色,网格等参数
plot1.set_xlabel('Number of classifier', fontsize = 12) # 设置x轴的标签和字体大小
# 设置刻度位置
plot1.set_xticks(range(0,45,5)) # 设置x轴的刻度位置为0到45之间,每隔5一个刻度
# 设置刻度标签
plot1.set_xticklabels(range(0,450,50)) # 设置x轴的刻度标签为0到450之间,每隔50一个标签
plot1.set_ylabel('Error rate', fontsize = 12) # 设置y轴的标签和字体大小
plot1.set_title('Error rate vs number of classifier', fontsize = 16) # 设置图形的标题和字体大小
plt.axhline(y=er_test[0], linewidth=1, color = 'red', ls = 'dashed') # 在图形上绘制一条水平的虚线,表示测试集的初始误差率
plt.show() # 显示图形
""" 主程序 ============================================================="""
if __name__ == '__main__':
# 读取数据
x, y = make_hastie_10_2() # 使用sklearn的make_hastie_10_2()函数来生成一个二分类数据集
df = pd.DataFrame(x) # 将数据集的特征转换为一个数据框
df['Y'] = y # 将数据集的标签添加到数据框中
# 分割数据集
X_train, X_test, Y_train, Y_test = train_test_split(x, y, test_size=0.2, random_state=42) # 使用sklearn的train_test_split()函数来将数据集分割为训练集和测试集,其中测试集占总数据的20%,并设置随机状态为42
# 训练一个简单的决策树
clf_tree = DecisionTreeClassifier(max_depth = 1, random_state = 1) # 创建一个决策树分类器,设置最大深度为1,随机状态为1
er_tree = generic_clf(Y_train, X_train, Y_test, X_test, clf_tree) # 使用通用分类器函数来训练和预测数据,并返回误差率
# 训练一个使用决策树作为基分类器的AdaBoost分类器
# 使用不同的迭代次数进行测试
er_train, er_test = [er_tree[0]], [er_tree[1]] # 初始化训练集和测试集的误差率为决策树的误差率
x_range = range(10, 410, 10) # 设置迭代次数的范围为10到410之间,每隔10一个值
for i in x_range: # 对于每一个迭代次数,i 为弱分类器数量
er_i = adaboost_clf(Y_train, X_train, Y_test, X_test, i, clf_tree) # 使用AdaBoost实现函数来训练和预测数据,并返回误差率
er_train.append(er_i[0]) # 将训练集的误差率添加到列表中
er_test.append(er_i[1]) # 将测试集的误差率添加到列表中
# 比较误差率和迭代次数的关系
plot_error_rate(er_train, er_test) # 使用绘图函数来绘制训练集和测试集的误差率随迭代次数变化的曲线图
2.3 Multi-class AdaBoosted Decision Trees 展示了AdaBoost算法如何在一个由十维正态分布和三个嵌套的十维球面构成的数据集上进行分类。
AdaBoost算法:一种基于加法模型和前向分步算法的提升方法,通过调整样本权重和基分类器权重来提高分类准确率。
多标签分类问题:一个示例,展示了AdaBoost算法如何在一个由十维正态分布和三个嵌套的十维球面构成的数据集上进行分类。
误分类误差:用于评估AdaBoost算法的性能,显示了每次迭代后的测试集误差,以及与单个决策树和随机分类器的对比。
基分类器的权重和误差:用于分析AdaBoost算法的内部机制,显示了每个基分类器在重新加权的训练集上的加权误差,以及它们在最终加法模型中的权重。
使用了sklearn的make_gaussian_quantiles函数来生成一个多分类数据集,然后使用了DecisionTreeClassifier作为基分类器,通过不同的迭代次数来训练AdaBoost分类器,绘制误差率随迭代次数变化的折线图,并在图上绘制决策树分类器和随机分类器的误差率水平线,用于对比。并绘制了每个基分类器的误差率和权重图形。代码的主要步骤如下:
导入需要的模块,包括sklearn,matplotlib和pandas。
使用make_gaussian_quantiles函数,生成一个包含2000个样本,10个特征,3个类别的数据集,设置随机种子为1。
使用train_test_split函数,将数据集划分为训练集和测试集,训练集占70%,设置随机种子为42。
创建一个最大叶子节点数为8的决策树分类器,作为基分类器。
创建一个AdaBoost分类器,使用决策树作为基分类器,设置迭代次数为300,算法为SAMME,随机种子为42,使用训练集来拟合数据。
创建一个随机的分类器,用于对比。
定义一个函数,用于计算误差率,误差率等于1减去准确率。
计算决策树分类器和随机分类器在测试集上的误差率,并打印出来。
创建一个数据框,用于存储AdaBoost分类器在不同迭代次数下的误差率。
绘制误差率随迭代次数变化的折线图,并在图上绘制决策树分类器和随机分类器的误差率水平线,用于对比。
创建一个数据框,用于存储AdaBoost分类器中每个基分类器的误差和权重。
绘制误差和权重随迭代次数变化的折线图,分为两个子图。
使用fig.tight_layout()函数,自动调整子图的参数,使得子图之间和图形边界之间有一定的填充空间,避免标签,标题等被遮挡或重叠。
#此示例展示了提升如何提高多标签分类问题的预测准确性。它重现了 Zhu 等人 [1] 中图 1 所示的类似实验
# https://www.intlpress.com/site/pub/pages/journals/items/sii/content/vols/0002/0003/a008/
# 导入需要的模块
from sklearn.datasets import make_gaussian_quantiles # 用于生成高斯分布的数据集
from sklearn.model_selection import train_test_split # 用于划分训练集和测试集
from sklearn.ensemble import AdaBoostClassifier # 用于实现AdaBoost算法
from sklearn.tree import DecisionTreeClassifier # 用于创建决策树分类器
from sklearn.dummy import DummyClassifier # 用于创建一个随机的分类器,用于对比
from sklearn.metrics import accuracy_score # 用于计算准确率
import matplotlib.pyplot as plt # 用于绘制图形
import pandas as pd # 用于处理数据
# 生成数据集
X, y = make_gaussian_quantiles(
n_samples=2_000, # 设置样本数为2000
n_features=10, # 设置特征数为10
n_classes=3, # 设置类别数为3
random_state=1 # 设置随机种子为1
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, # 输入数据和标签
train_size=0.7, # 设置训练集占总数据的70%
random_state=42 # 设置随机种子为42
)
# 创建一个决策树分类器,作为基分类器
weak_learner = DecisionTreeClassifier(max_leaf_nodes=8) # 设置最大叶子节点数为8
n_estimators = 300 # 设置迭代次数为300
# 创建一个AdaBoost分类器,使用决策树作为基分类器
adaboost_clf = AdaBoostClassifier(
estimator=weak_learner, # 输入基分类器
n_estimators=n_estimators, # 输入迭代次数
algorithm="SAMME", # 设置算法为SAMME,这是一种多分类的AdaBoost算法
random_state=42, # 设置随机种子为42
).fit(X_train, y_train) # 使用训练集来拟合数据
# 创建一个随机的分类器,用于对比
dummy_clf = DummyClassifier()
# 定义一个函数,用于计算误差率
def misclassification_error(y_true, y_pred):
return 1 - accuracy_score(y_true, y_pred) # 误差率等于1减去准确率
# 计算决策树分类器在测试集上的误差率
weak_learners_misclassification_error = misclassification_error(
y_test, # 真实标签
weak_learner.fit(X_train, y_train).predict(X_test) # 预测标签
)
# 计算随机分类器在测试集上的误差率
dummy_classifiers_misclassification_error = misclassification_error(
y_test, # 真实标签
dummy_clf.fit(X_train, y_train).predict(X_test) # 预测标签
)
# 打印决策树分类器和随机分类器的误差率
print(
"DecisionTreeClassifier's misclassification_error: "
f"{weak_learners_misclassification_error:.3f}" # 使用f-string格式化输出,保留三位小数
)
print(
"DummyClassifier's misclassification_error: "
f"{dummy_classifiers_misclassification_error:.3f}" # 使用f-string格式化输出,保留三位小数
)
# 创建一个数据框,用于存储AdaBoost分类器在不同迭代次数下的误差率
boosting_errors = pd.DataFrame(
{
"Number of trees": range(1, n_estimators + 1), # 设置列名为Number of trees,值为从1到300的序列
"AdaBoost": [ # 设置列名为AdaBoost,值为AdaBoost分类器在不同迭代次数下的误差率
misclassification_error(y_test, y_pred) # 调用误差率函数,计算误差率
for y_pred in adaboost_clf.staged_predict(X_test) # 使用staged_predict方法,得到每次迭代的预测结果
],
}
).set_index("Number of trees") # 将Number of trees列作为索引
# 绘制误差率随迭代次数变化的折线图
ax = boosting_errors.plot() # 使用数据框的plot方法,绘制折线图,返回一个轴对象
ax.set_ylabel("Misclassification error on test set") # 设置y轴的标签
ax.set_title("Convergence of AdaBoost algorithm") # 设置图形的标题
# 在图形上绘制决策树分类器和随机分类器的误差率水平线,用于对比
plt.plot(
[boosting_errors.index.min(), boosting_errors.index.max()], # 设置x轴的范围,从最小的迭代次数到最大的迭代次数
[weak_learners_misclassification_error, weak_learners_misclassification_error], # 设置y轴的值,为决策树分类器的误差率
color="tab:orange", # 设置线的颜色
linestyle="dashed", # 设置线的样式
)
plt.plot(
[boosting_errors.index.min(), boosting_errors.index.max()], # 设置x轴的范围,从最小的迭代次数到最大的迭代次数
[
dummy_classifiers_misclassification_error,
dummy_classifiers_misclassification_error,
], # 设置y轴的值,为随机分类器的误差率
color="c", # 设置线的颜色
linestyle="dotted", # 设置线的样式
)
plt.legend(["AdaBoost", "DecisionTreeClassifier", "DummyClassifier"], loc=1) # 设置图例,位置为右上角
# 创建一个数据框,用于存储AdaBoost分类器中每个基分类器的误差和权重
weak_learners_info = pd.DataFrame(
{
"Number of trees": range(1, n_estimators + 1), # 设置列名为Number of trees,值为从1到300的序列
"Errors": adaboost_clf.estimator_errors_, # 设置列名为Errors,值为AdaBoost分类器中每个基分类器的误差
"Weights": adaboost_clf.estimator_weights_, # 设置列名为Weights,值为AdaBoost分类器中每个基分类器的权重
}
).set_index("Number of trees") # 将Number of trees列作为索引
# 绘制误差和权重随迭代次数变化的折线图,分为两个子图
axs = weak_learners_info.plot(
subplots=True, # 设置为True,表示绘制多个子图
layout=(1, 2), # 设置子图的布局,为一行两列
figsize=(10, 4), # 设置图形的大小,为10英寸宽,4英寸高
legend=False, # 设置为False,表示不显示图例
color="tab:blue" # 设置线的颜色
)
axs[0, 0].set_ylabel("Train error") # 设置第一个子图的y轴标签
axs[0, 0].set_title("Weak learner's training error") # 设置第一个子图的标题
axs[0, 1].set_ylabel("Weight") # 设置第二个子图的y轴标签
axs[0, 1].set_title("Weak learner's weight") # 设置第二个子图的标题
fig = axs[0, 0].get_figure() # 获取图形对象
fig.suptitle("Weak learner's errors and weights for the AdaBoostClassifier") # 设置图形的总标题
fig.tight_layout() #自动调整子图的参数,使得子图之间和图形边界之间有一定的填充空间,避免标签,标题等被遮挡或重叠
plt.show() # 显示图形
# AdaBoostClassifier的收敛性主要受学习率、弱学习器的数量和表达能力的影响。弱学习器的误差和权重呈反比关系,即误差越小的弱学习器在最终的集成预测中影响越大。输出结果:
DecisionTreeClassifier's misclassification_error: 0.475
DummyClassifier's misclassification_error: 0.692

不同阶段的错误分类误差
该图显示了每次提升迭代后测试集上的误分类错误。我们看到,经过 50 次迭代后,提升树的误差收敛到 0.3 左右,这表明与单棵树相比,其精度明显更高,如图中的虚线所示。
由于 SAMME 算法使用弱学习器的离散输出来训练增强模型,因此错误分类误差会出现抖动。
AdaBoostClassifier 的收敛性主要受学习率(即 learning_rate )、使用的弱学习器数量( n_estimators )以及弱学习器的表达能力影响学习者(例如 max_leaf_nodes )。

弱学习器的错误率和权重
在左图中,我们显示了每次提升迭代时每个弱学习器在重新加权训练集上的加权误差。在右图中,我们显示了与每个弱学习器相关的权重,稍后用于对最终加性模型进行预测。
我们看到弱学习器的误差是权重的倒数。这意味着我们的加性模型将更加信任弱学习者,通过增加其对最终决策的影响来减少错误(在训练集上)。事实上,这正是 AdaBoost 中每次迭代后更新基本估计器权重的公式。

2.4 使用AdaBoost回归模型进行北京PM2.5数据预测的例子,通过交叉验证选择最优参数组合,并展示了模型的性能和预测结果
对气象数据进行处理和预处理,包括缺失值的处理、字段的删除、字符串属性值的数字编码,最终将数据集分为训练和预测数据集,用于后续的机器学习模型训练
导入
pandas和numpy两个常用的数据处理库。通过
pd.read_csv读取名为'Boosting\PRSA_data_2010.1.1-2014.12.31.csv'的 CSV 格式的数据文件。第一部分处理缺失值的代码:
定义了一个函数
DeleteTargetNan,用于删除目标值为空值的行,其他列为缺失值则自动填充,同时将目标变量放置在数据集最后一列。定义了一个函数
Shanchu,用于删除原始数据中不需要的字段名。定义了一个函数
Digit,用于将数据中的属性值为字符串的进行数字编码。
数据处理后最终的数据集,依次调用上述三个函数,即 first = DeleteTargetNan(data, 'pm2.5'),two = Shanchu(first),third = Digit(two)。
定义了一个函数 fenge,用于将数据集按照 8:2 的比例分为训练和预测数据集。其中训练数据集再分为 K 份,进行 K 折交叉验证。
调用 fenge 函数,将处理后的数据集分为训练和预测数据集,得到 deeer。
从返回的 deeer 中取出 K 折交叉的训练数据和预测数据,分别存储在 dt_data 和 predict_data 中。
# 导入pandas和numpy两个常用的数据处理库
import pandas as pd
import numpy as np
# 读取数据文件,文件名为'Boosting\PRSA_data_2010.1.1-2014.12.31.csv',文件格式为csv,用逗号分隔
data = pd.read_csv('Boosting\PRSA_data_2010.1.1-2014.12.31.csv')
'''第一部分:缺失值的处理'''
# 因为Pm2.5是目标数据,如有缺失值直接删除这一条记录
# 定义一个函数,用于删除目标值为空值的行,其他列为缺失值则自动填充,同时将目标变量放置在数据集最后一列
def DeleteTargetNan(exdata, targetstr):
# 首先判断目标字段是否有缺失值
if exdata[targetstr].isnull().any():
# 首先确定缺失值的行数,用index.tolist()方法获取缺失值行的索引列表
loc = exdata[targetstr][data[targetstr].isnull().values == True].index.tolist()
# 然后删除这些行,用drop方法删除指定索引的行
exdata = exdata.drop(loc)
# 凡是有缺失值的再一起利用此行的均值填充,用fillna方法填充缺失值,用mean方法计算均值
exdata = exdata.fillna(exdata.mean())
# 将目标字段至放在最后的一列,先用copy方法复制目标字段的值,然后用del方法删除原来的目标字段,再用赋值语句将目标字段添加到最后
targetnum = exdata[targetstr].copy()
del exdata[targetstr]
exdata[targetstr] = targetnum
# 返回处理后的数据集
return exdata
# 定义一个函数,用于删除原始数据中不需要的字段名
def Shanchu(exdata, aiduan=['No']):
# 遍历不需要的字段名列表
for ai in aiduan:
# 如果该字段名在数据集的列名中
if ai in exdata.keys():
# 用del方法删除该字段
del exdata[ai]
# 返回处理后的数据集
return exdata
# 定义一个函数,用于将数据中的属性值为字符串的进行数字编码,因为独热编码对决策树而言不那么重要
def Digit(eadata):
# 遍历数据集的每一列
for jj in eadata:
# 用try-except语句判断该列的值是否为字符串,如果是字符串,会抛出TypeError异常
try:
# 尝试将该列的第一个值加1,如果是字符串,会抛出异常
eadata[jj].values[0] + 1
except TypeError:
# 需要转为数字编码
# 用set和list方法获取该列的值的去重后的列表
numlist = list(set(list(eadata[jj].values)))
# 用列表推导式和index方法将该列的值转为对应的索引值
zhuan = [numlist.index(jj) for jj in eadata[jj].values]
# 用赋值语句将该列的值替换为索引值
eadata[jj] = zhuan
# 返回处理后的数据集
return eadata
# 数据处理后最终的数据集,依次调用上述三个函数
first = DeleteTargetNan(data, 'pm2.5')
two = Shanchu(first)
third = Digit(two)
# 定义一个函数,用于将数据集按照8:2的比例分为训练、预测数据集。其中训练数据集再分为K份,进行K折交叉验证
def fenge(exdata, k=10, per=[0.8, 0.2]):
# 总长度,用len方法获取数据集的行数
lent = len(exdata)
# 用np.arange方法生成一个从0到总长度的整数序列
alist = np.arange(lent)
# 用np.random.shuffle方法打乱该序列的顺序
np.random.shuffle(alist)
# 训练
# 计算训练数据集的长度,用int方法取整
xunlian_sign = int(lent * per[0])
# 用np.random.choice方法从打乱的序列中随机选取训练数据集的长度个元素,作为训练数据集的索引,replace参数为False表示不放回抽样
xunlian = np.random.choice(alist, xunlian_sign, replace=False)
# 预测
# 用列表推导式从打乱的序列中选取不在训练数据集索引中的元素,作为预测数据集的索引,用np.array方法转为数组
yuce = np.array([i for i in alist if i not in xunlian])
# 再将训练数据集分为K折
# 存储字典,用于存储每一折的训练数据和测试数据
save_dict = {}
# 遍历从0到K-1的整数
for jj in range(k):
# 初始化每一折的字典
save_dict[jj] = {}
# 计算训练数据集的长度
length = len(xunlian)
# 计算每一折的测试数据的长度,用int方法取整
yuzhi = int(length / k)
# 用np.random.choice方法从训练数据集的索引中随机选取测试数据的长度个元素,作为测试数据的索引,replace参数为False表示不放回抽样
yan = np.random.choice(xunlian, yuzhi, replace=False)
# 用列表推导式从训练数据集的索引中选取不在测试数据集索引中的元素,作为训练数据的索引,用np.array方法转为数组
tt = np.array([i for i in xunlian if i not in yan])
# 用训练数据和测试数据的索引从原始数据集中选取对应的数据,用train和test作为键名存储到每一折的字典中
save_dict[jj]['train'] = exdata[tt]
save_dict[jj]['test'] = exdata[yan]
# 返回存储字典和预测数据集,用逗号分隔
return save_dict, exdata[yuce]
# 调用上述函数,将处理后的数据集分为训练和预测数据集
deeer = fenge(third.values)
# K折交叉的训练数据,从返回的存储字典中取出第一个元素
dt_data = deeer[0]
# 预测数据,从返回的预测数据集中取出第二个元素
predict_data = deeer[1]导入必要的库和模块,包括处理后的数据集模块(pm25_AdaBoost_Data)、AdaBoost回归模型、决策树回归模型、评估模型性能的指标、绘图相关的库等。
定义了一个训练函数
Train,用于训练AdaBoost回归模型,并返回训练数据和验证数据的均方误差(MSE)。定义了一个函数
Zuhe,用于确定最优的参数组合,包括弱模型的个数和决策树的层数,以及对应的最佳折数。该函数使用了 K 折交叉验证的方法。定义了一个函数
duibi,用于根据序列字典绘制不同参数组合下MSE的对比曲线,并保存图片。定义了一个函数
recspre,用于根据最优的参数组合绘制预测数据的真实值和预测值的对比曲线,并保存图片。在主函数中,调用了
Zuhe函数得到最优的参数组合、最佳的折数和MSE序列,然后调用duibi函数绘制不同参数组合的MSE对比曲线,最后调用recspre函数绘制预测数据的真实值和预测值的对比曲线。
# 引入数据,使用pm25_AdaBoost_Data模块,该模块包含了处理后的数据集
import pm25_AdaBoost_Data as data
# 引入AdaBoost回归模型,使用sklearn库中的AdaBoostRegressor类
from sklearn.ensemble import AdaBoostRegressor
# 引入决策树回归模型,使用sklearn库中的DecisionTreeRegressor类,作为AdaBoost的基学习器
from sklearn.tree import DecisionTreeRegressor
# 引入均方误差函数,使用sklearn库中的mean_squared_error函数,作为评估模型性能的指标
from sklearn.metrics import mean_squared_error as mse
# 引入numpy库,用于进行数值计算
import numpy as np
# 引入绘图相关的库,使用pylab和matplotlib库,用于绘制不同参数下MSE的对比曲线
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 设置字体为仿宋,以显示中文
mpl.rcParams['axes.unicode_minus'] = False # 设置正常显示负号
import matplotlib.pyplot as plt
# 根据K折交叉的结果确定比较好的参数组合,然后给出预测数据真实值和预测值的对比
# 更改的参数一是框架的参数,即弱模型的个数
# 更改的参数二是弱模型的参数,即决策树的层数
# 弱模型中树的层数,设置为20,30,50三种可能的值
cengs = [20, 30, 50]
# 弱模型的个数,设置为500,1000,3000三种可能的值
models = [500, 1000, 3000]
# 定义一个训练函数,用于训练AdaBoost回归模型,并返回训练数据和验证数据的MSE
def Train(data, modelcount, censhu, yanzhgdata):
# 创建AdaBoost回归模型的实例,指定基学习器为决策树回归模型,设置决策树的最大深度为censhu,设置弱模型的个数为modelcount,设置学习率为0.8
model = AdaBoostRegressor(DecisionTreeRegressor(max_depth=censhu),
n_estimators=modelcount, learning_rate=0.8)
# 使用训练数据的特征和标签,拟合AdaBoost回归模型
model.fit(data[:, :-1], data[:, -1])
# 使用训练数据的特征,预测训练数据的标签
train_out = model.predict(data[:, :-1])
# 计算训练数据的真实标签和预测标签的MSE
train_mse = mse(data[:, -1], train_out)
# 使用验证数据的特征,预测验证数据的标签
add_yan = model.predict(yanzhgdata[:, :-1])
# 计算验证数据的真实标签和预测标签的MSE
add_mse = mse(yanzhgdata[:, -1], add_yan)
# 打印训练数据和验证数据的MSE
print(train_mse, add_mse)
# 返回训练数据和验证数据的MSE
return train_mse, add_mse
# 定义一个函数,用于确定最优的参数组合,即弱模型的个数和决策树的层数,以及对应的最佳折数
def Zuhe(datadict, tre=models, tezhen=cengs):
# 存储结果的字典,键为参数组合,值为对应的MSE均值
savedict = {}
# 存储序列的字典,键为参数组合,值为对应的MSE序列
sacelist = {}
# 遍历弱模型的个数的可能值
for t in tre:
# 遍历决策树的层数的可能值
for te in tezhen:
# 打印当前的参数组合
print(t, te)
# 创建一个空列表,用于存储每一折的验证数据的MSE
sumlist = []
# 因为要展示折数,因此要按序开始,对datadict的键进行排序
ordelist = sorted(list(datadict.keys()))
# 遍历每一折的数据
for jj in ordelist:
# 调用训练函数,传入训练数据,弱模型的个数,决策树的层数,验证数据,得到训练数据和验证数据的MSE
xun, ya = Train(datadict[jj]['train'], t, te, datadict[jj]['test'])
# 根据验证数据的MSE确定最佳的参数组合,将验证数据的MSE添加到列表中
sumlist.append(ya)
# 用参数组合作为键,MSE列表作为值,存储到序列字典中
sacelist['%s-%s' % (t, te)] = sumlist
# 用参数组合作为键,MSE列表的均值作为值,存储到结果字典中
savedict['%s-%s' % (t, te)] = np.mean(np.array(sumlist))
# 在结果字典中选择MSE均值最小的参数组合,作为最优的参数组合
zuixao = sorted(savedict.items(), key=lambda fu: fu[1])[0][0]
# 然后再选出此方法中MSE最小的折数,作为最佳的折数
xiao = sacelist[zuixao].index(min(sacelist[zuixao]))
# 返回最优的参数组合,最佳的折数,和序列字典
return zuixao, xiao, sacelist
# 定义一个函数,用于根据序列字典绘制不同参数组合下MSE的对比曲线,并保存图片
def duibi(exdict, you):
# 创建一个图形对象,设置大小为11*7
plt.figure(figsize=(11, 7))
# 遍历序列字典的每一个键值对
for ii in exdict:
# 绘制折数和MSE的折线图,设置标签为参数组合和MSE均值,设置线宽为2
plt.plot(list(range(len(exdict[ii]))), exdict[ii], \
label='%s,%d折MSE均值:%.3f' % (ii, len(exdict[ii]), np.mean(np.array(exdict[ii]))), lw=2)
# 显示图例
plt.legend()
# 设置标题为不同参数组合的MSE对比曲线,标注最优的参数组合
plt.title('不同参数的组合MSE对比曲线[最优:%s]' % you)
# 保存图片到指定路径
plt.savefig(r'C:\Users\cxy\Desktop\adaboost_pm25.jpg')
# 返回提示信息
return '不同方法对比完毕'
# 定义一个函数,用于根据最优的参数组合绘制预测数据的真实值和预测值的对比曲线,并保存图片
def recspre(exstr, predata, datadict, zhe, count=100):
# 将参数组合字符串按照"-"分割,得到弱模型的个数和决策树的层数
tree, te = exstr.split('-')
# 创建AdaBoost回归模型的实例,指定基学习器为决策树回归模型,设置决策树的最大深度为te,设置弱模型的个数为tree,设置学习率为0.8
model = AdaBoostRegressor(DecisionTreeRegressor(max_depth=int(te)),
n_estimators=int(tree), learning_rate=0.8)
# 使用最佳折数的训练数据的特征和标签,拟合AdaBoost回归模型
model.fit(datadict[zhe]['train'][:, :-1], datadict[zhe]['train'][:, -1])
# 使用预测数据的特征,预测预测数据的标签
yucede = model.predict(predata[:, :-1])
# 为了便于展示,随机选取100条数据进行展示
zongleng = np.arange(len(yucede))
randomnum = np.random.choice(zongleng, count, replace=False)
yucede_se = list(np.array(yucede)[randomnum])
yuce_re = list(np.array(predata[:, -1])[randomnum])
# 对比真实值和预测值
plt.figure(figsize=(17, 9))
plt.subplot(2, 1, 1)
# 绘制预测值的折线图,设置红色虚线,标签为'预测',线宽为2
plt.plot(list(range(len(yucede_se))), yucede_se, 'r--', label='预测', lw=2)
# 绘制真实值的散点图,设置蓝色点,标签为'真实',线宽为2
plt.scatter(list(range(len(yuce_re))), yuce_re, c='b', marker='.', label='真实', lw=2)
# 设置x轴的范围为-1到count+1
plt.xlim(-1, count + 1)
# 显示图例
plt.legend()
# 设置标题为预测和真实值对比,显示最大树数
plt.title('预测和真实值对比[最大树数%d]' % int(tree))
plt.subplot(2, 1, 2)
# 绘制真实值和预测值的差值的折线图,设置黑色虚线,标记为方形,标签为'真实-预测',线宽为2
plt.plot(list(range(len(yucede_se))), np.array(yuce_re) - np.array(yucede_se), 'k--', marker='s', label='真实-预测', lw=2)
# 显示图例
plt.legend()
# 设置标题为预测和真实值相对误差
plt.title('预测和真实值相对误差')
# 保存图片到指定路径
plt.savefig(r'C:\Users\cxy\Desktop\duibi.jpg')
# 返回提示信息
return '预测真实对比完毕'
# 主函数
if __name__ == "__main__":
# 调用Zuhe函数,得到最优的参数组合,最佳的折数,和MSE序列
zijian, zhehsu, xulie = Zuhe(data.dt_data)
# 调用duibi函数,根据MSE序列绘制不同参数组合的MSE对比曲线
duibi(xulie, zijian)
# 调用recspre函数,根据最优的参数组合绘制预测数据的真实值和预测值的对比曲线
recspre(zijian, data.predict_data, data.dt_data, zhehsu)输出结果:

不同参数组合的MSE对比曲线
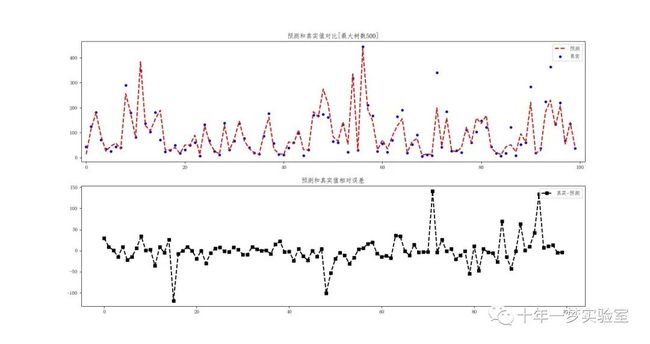
预测数据的真实值和预测值的对比曲线
三、各种AdaBoost适用场景



参考网址
https://zhuanlan.zhihu.com/p/41536315
https://blog.csdn.net/v_july_v/article/details/40718799
https://wiki.mbalib.com/wiki/%E6%9F%94%E6%80%A7%E5%88%B6%E9%80%A0%E6%8A%80%E6%9C%AF
https://softwareconnect.com/manufacturing/what-is-fms/
https://www.investopedia.com/terms/f/flexible-manufacturing-system.asp
https://scikit-learn.org/stable/auto_examples/ensemble/plot_adaboost_hastie_10_2.html Discrete versus Real AdaBoost
https://zhuanlan.zhihu.com/p/150663408 从离散型adaboost 到概率型 adaboost
https://zhuanlan.zhihu.com/p/475830334 一文教会你pandas plot各种绘图
https://scikit-learn.org.cn/view/90.html# 1.11 集成算法-scikit-learn中文社区
https://scikit-learn.org/stable/auto_examples/ensemble/plot_adaboost_multiclass.html#sphx-glr-auto-examples-ensemble-plot-adaboost-multiclass-py Multi-class AdaBoosted Decision Trees — scikit-learn 1.3.2 documentation