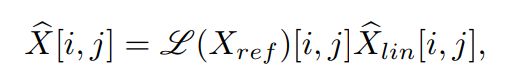RealSR真实场景超分
一、Camera Lens Super-Resolution
本文主要解决RealSR的数据问题,通过控制镜头到物体的距离产生成对的真实数据(Real paired SR data)。
(1)出发点
现有的超分方法通常采用合成退化模型,如双三次(Bicubic)或高斯降采样。
(2)主要工作
本文主要从真实成对数据获取方面解决RealSR问题。
- 为缓解现实成像系统中分辨率R和视场V之间的内在权衡,利用相机镜头的R-V退化,用于现实成像系统中的SR建模。
- 创建City100数据集,包含两种新的获取LR-HR图像对的策略,分别用来描述在单反相机和智能手机相机下的R-V退化。
- 利用实际数据对常用的综合退化模型进行定量分析。
- 一种有效的解决方案,即CameraSR,在现实成像系统中推广现有的基于学习的SR方法。

二、Zoom to Learn, Learn to Zoom
本文主要解决RealSR的数据问题,通过控制相机变焦,产生成对的真实数据(Real paired SR data)。
(1)主要工作
- 使用真实的高比特传感器数据进行计算缩放,相比于处理过的8位RGB图像或合成传感器模型更有效。
- 创建新的数据集,SR-RAW,他是第一个从原始数据超分辨率的数据集,具有光学地面真理。SR-RAW使用变焦镜头拍摄。用长焦距拍摄的图像作为较短焦距拍摄的图像的光学真实。
- 提出了一种新的上下文双边损失(CoBi)处理轻微失调的图像对。
CoBi通过加权空间意识来考虑局部上下文相似性。
(2)不同焦距产生的图像
(3)数据对齐问题(Misalignment Analysis)
(B1)角度偏差;(B2)景深偏差;(B3)对齐偏差

为解决以上问题,本文提出上下文双边损失(Contextual Bilateral Loss)。
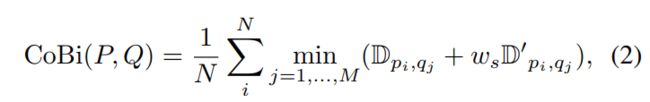
三、Toward Real-World Single Image Super-Resolution: A New Benchmark and A New Model (ICCV2019) 详细介绍
(1)主要工作
- 本文通过镜头变焦+图像配准建立数据集RealSR。
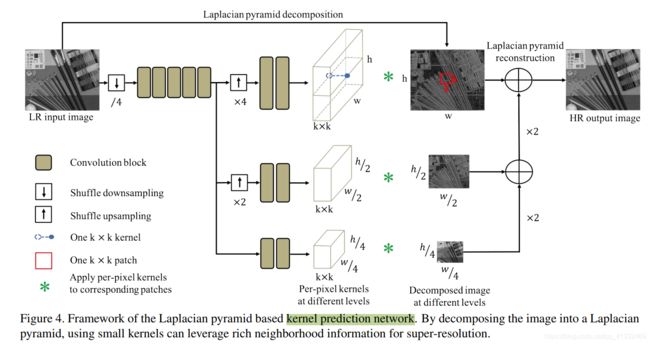
- 提出拉普拉斯金字塔核预测网络(Laplacian pyramid based kernel prediction network (LP-KPN))解决RealSR问题。
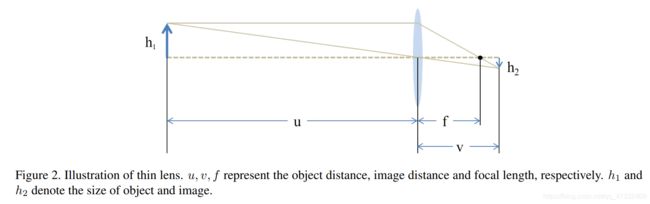
(2)数据收集
- 物距、像距、焦距示意图:
- 图像配准

为了获得精确的图像对配准,本文设计了一种同时考虑亮度调整的像素级配准算法(pixel-wise registration algorithm )。
(3)KPN结构
分三层进行核(kernel)预测,目的是减少计算量、增大感受野。
四、Frequency Separation for Real-World Super-Resolution(ICCV2019)
本文利用GAN合成跟接近于真实场景下的LR-HR图像对,然后利用该数据训练SR模型,在Real-World数据上获得了较好的重建结果。
(1)出发点
真实场景数据更为复杂,现有模型在真实数据上的泛化能力较差。
(2)主要工作
- 利用GAN生成更接近于真实场景的LR-HR图像对,以用于SR模型的训练。
-在ESRGAN基础上加入频域分离(Frequency Separation)技术,构建RealSR模型。
(3)频域分离
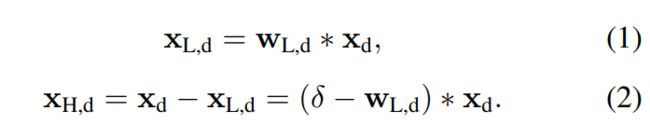
(4)利用GAN生成真实LR数据
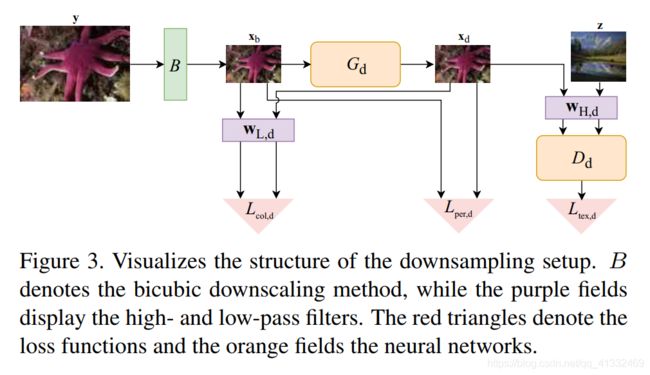
- 生成器:低频颜色损失+高频对抗损失+纹理损失
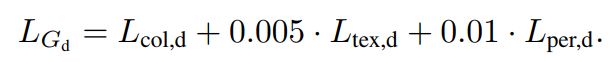
- 判别器:高频判别损失
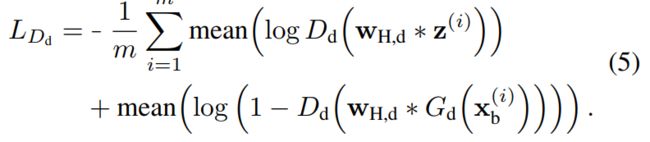
(5)ESRGAN-FS(Frequency Separation)
在ESRGAN中加入频域分离。

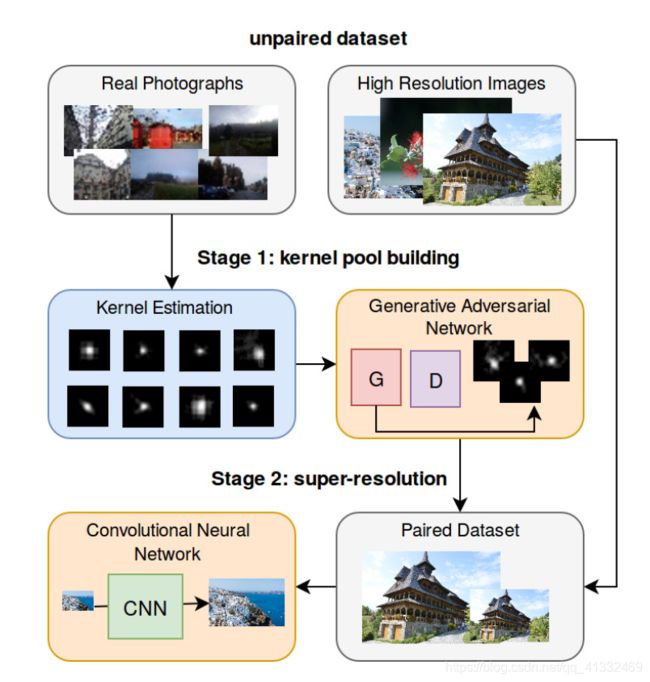
五、Kernel Modeling Super-Resolution on Real Low-Resolution Images (ICCV2019)
(1)主要工作
- 利用Blur-Kernel Estimation算法从真实图像中估计出真实图像的模糊核(realistic blur-kernels),建立模糊核集合K。
- 借助K中的模糊核,利用WGAN-GP学习模糊核的分布,并生成更多的模糊核,然后建立模糊核池(blur kernel pool)K+。
- 利用K+中的模糊核将高分辨率图像转换为接近于真实场景的低分辨率图像,从而构建训练数据。
(2) Blur-Kernel Estimation
该模糊核估计方法出自论文:Blind Image Deblurring Using Dark Channel Prior
- 真实LR利用Bicubic上采样
- 提取图像块p,由于缺乏高频细节的块(如从天空、墙壁等提取的块)的模糊核估计算法可能会失败,所以p需要满足以下条件:
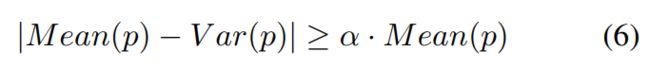
- 利用模糊核估计算法估计p的模糊核,模糊核k通过以下公式求解(详细过程见上述参考文献):

(3)Kernel Modeling with GAN
利用WGAN-GP生成更多的模糊核,创建模糊核池K+。WGAN-GP见WGAN-GP详细过程。

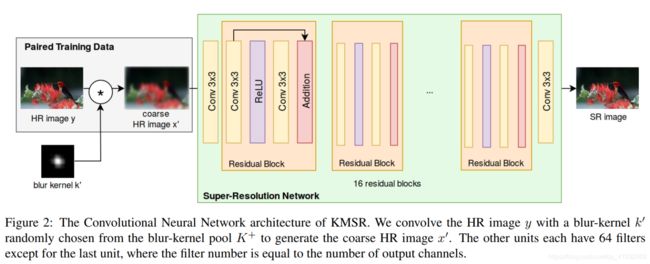
(4)Super-Resolution with CNN
- 由高分辨率图像创建训练数据集:

- 训练模型:
六、Learning to Zoom-in via Learning to Zoom-out: Real-world Super-resolution by Generating and Adapting Degradation (CVPR2020)
本文主要思想为利用CycleGAN生成更接近于真实场景的LR-HR图像对。
(1)出发点
- 现有方法利用各种手段努力获取跟接近于真实的成对的LR-HR图像对(如相机调焦等),但是这些方法采集到的图像对存在各种各样的不对齐情形。
(2)主要工作
- 首先利用CycleGAN训练一个退化生成网络来生成真实的LR图像,尽量减小生成数据与真实数据之间的差异。
- 设计自适应退化超分网络用于真实图像的超分。
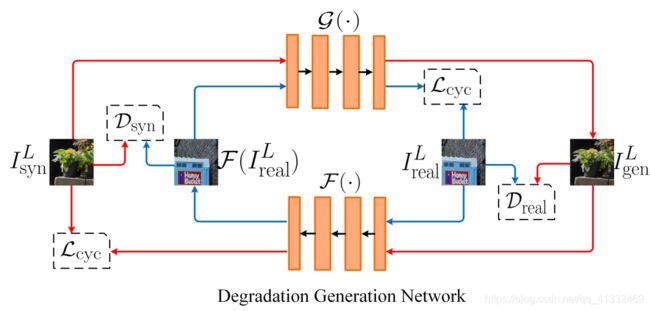
(3) Degradation generation network
- 外圈红色为合成数据;内圈蓝色为真实数据
- G(.)用于将图像由合成域( synthetic domain)向真实域(realistic domain)转换;F(.)用于将图像由真实域(realistic domain)向合成域( synthetic domain)转换。
- 左侧判别器Dsyn用于判别是否为合成数据;左侧判别器Dreal用于判别是否为真实数据;
- 循环一致损失用于保证图像内容不变。
- 损失函数:
生成器:两个循环一致损失+两个对抗损失
判别器:两个判别损失
(4)Degradation Adaptive SR Network
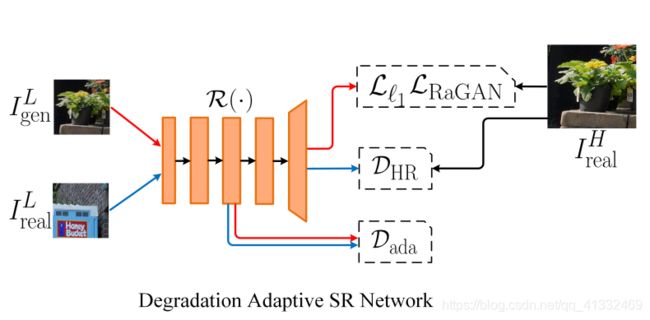
损失函数主要包括两部分:
- 常规GAN损失:L1损失+相对对抗损失
这两个损失用来保证内容的准确性
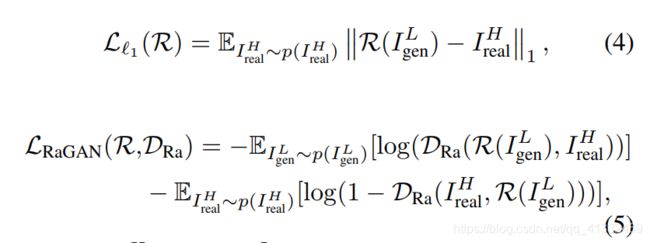
- 自适应退化损失
作者认为,尽管Degradation generation network已经解决了LR的domain gap问题,但还是很难达到理想的情况。所以作者在此
又加入了两个域判别器(domain discriminator):
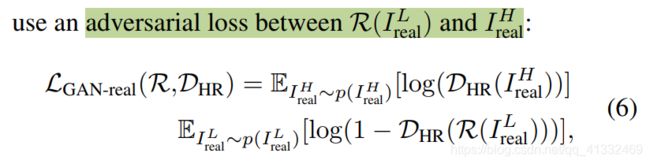
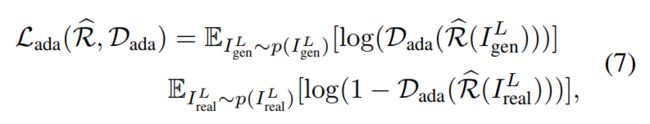
总体的损失函数为:
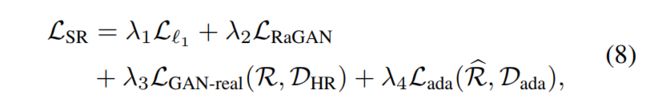
七、Guided Frequency Separation Network for Real-World Super-Resolution(CVPRW2020)
本片文章与前边介绍的文章有很多相似之处,分两部分:domain transformation 和super-resolution.

(1)Domain transformation
生成器损失函数(上图最下方的三个损失):低频内容损失+感知损失+高频域转换对抗损失
(2)SR
生成器损失(上图右上角两个损失):高频内容对抗损失+内容损失+边缘损失(canny)
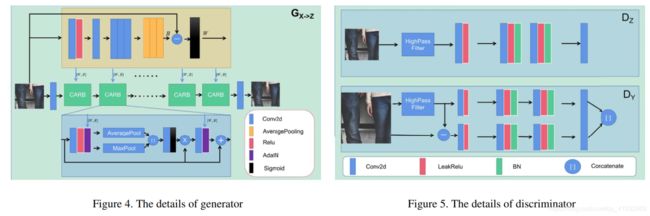
八、Blind Super-Resolution Kernel Estimation using an Internal-GAN (KernelGAN,NIPS2019)
本篇文章提出来一种无监督盲超分方法。
该方法可以理解为是对ZSSR(Zero-Shot SR)的改进。ZSSR利用bicubic进行下采样降质,然后完成无监督超分,但是该方法是非盲的;而本文主要的工作是利用GAN学习自身分布,从而得到更真实的降质图像。所以本文的关注点为:如何更好地完成图像降质过程。
本文方法包含两个过程:
- 利用kernelGAN估计输入图像的降质kernel并得到其所对应的降质图像;
- 得到成对图像,利用ZSSR完成无监督超分。
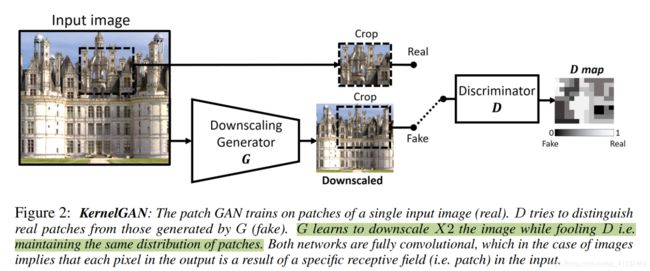
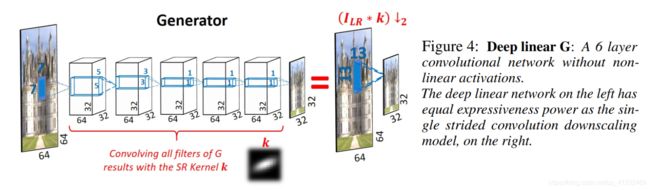
(1)KernelGAN:
kernelGAN详细介绍
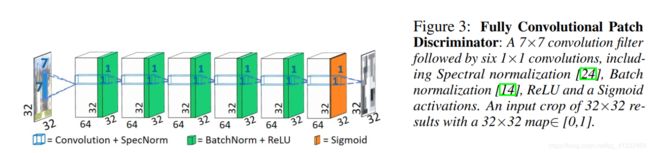
九、Real-World Super-Resolution via Kernel Estimation and Noise Injection(CVPRW2020-RealSR冠军)
本片文章思想类似于Kernel Modeling Super-Resolution on Real Low-Resolution Images (ICCV2019),不同之处为:
1、本文利用kernelGAN预测模糊核
(1)主要工作
本文作者认为真实世界超分辨率的关键问题是引入精确的退化方法,以保证生成的低分辨率图像与原始图像具有相同的域属性,所有本文的主要工作为:
- 提出了一种新的在真实环境下的退化框架RealSR,为超分辨率学习提供了逼真的图像。
- 通过估计核和噪声,我们探索了模糊和噪声图像的具体退化。
(2)Kernel Estimation and Downsampling
利用KernelGAN来估计真实图像的模糊核,估计的模糊核满足以下约束:

(3)Noise Injection
通过注入噪声到降采样图像中,以生成真实的LR图像。噪声ni满足以下约束:

(4)图像退化总体流程
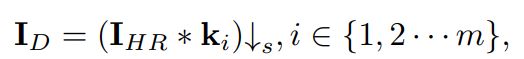
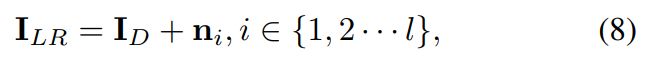

十、Towards Real Scene Super-Resolution with Raw Images (CVPR2019)
本文首先通过模拟数码相机的成像过程来生成真实的训练数据,然后直接利用原始RAW数据进行重建。
(1)出发点
- 缺乏真实的训练数据
- 输入信息的丢失
(2)主要工作
- 合成更接近于真实场景的训练数据。
- 提出双向网络架构(dual network)来利用原始数据(Raw数据)和彩色图像(RGB)来实现真实场景的超分辨率。此外,还提出学习空间变化的颜色变换(spatial-variant color transformations)以及特征融合(feature fusion)以获得更好的性能。
(3)Raw数据
- Raw与彩色图像的关系:
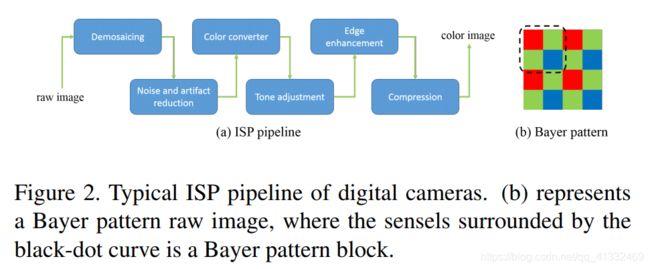
Raw数据的优势: - Raw数据拥有更多的信息可以利用,因为它们通常是12或14位,而颜色像素由ISP产生通常是8位。
- 原始数据与场景亮度成正比,而ISP包含非线性操作,如色调映射。因此,成像过程中的线性退化,包括模糊和噪声,在处理后的RGB空间是非线性的,这给图像恢复带来了更多的困难。
- ISP中的镶嵌步骤与超分辨率高度相关,因为这两个问题都与相机的分辨率限制有关。
因此,用预处理图像(RGB图像)来解决超分辨率问题是次优的,可能不如用一个统一的模型同时解决这两个问题(IPS问题与超分问题)。
(4)合成训练数据
为了获得更接近于真实场景的图像,采用以下方式合成训练数据:

(5)网络结构
上路分支利用输入raw数据重建RGB图像的纹理结构信息(raw数据缺乏颜色亮度信息);
下路分支利用彩色图像对上路图像进行颜色校正。
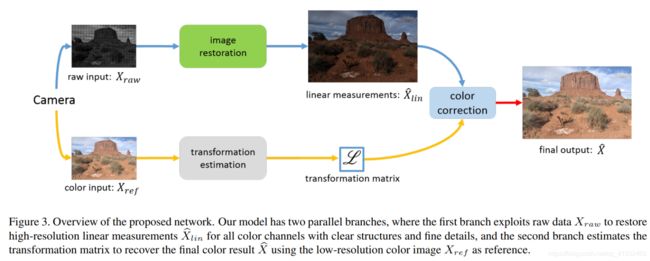
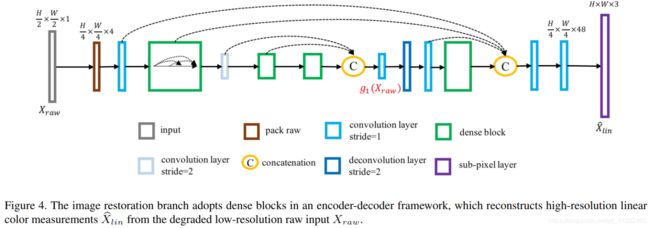
1、重建分支:
首先将原始数据Xraw划分成四个通道,分别对应于R、G、B、G,然后利用U-Net结构提取特征并上采样,最后重建为RGB三通道。
2、颜色校正分支
利用CNN去估计pixel-wise transformation:
![]()
然后对逐个像素进行颜色校正: