架构设计内容分享(十):1000亿数据、30W级qps如何架构?来一个天花板案例
目录
点赞场景的业务分析
数据规模、流量规模分析
大流量、大数据场景下点赞中台化诉求
B赞点赞中台的整体架构
B赞点赞中台的接入层架构
B赞点赞中台的服务层架构
B赞点赞中台的数据层架构
二级DB架构编辑
数据一致性架构
容灾架构
架构的演进方向
点赞场景的业务分析
做系统架构,首先要需求分析。
点赞的业务,已经足够的简单,极致的简要
需求1:视频的点赞数
需求2:UP主维度的总获赞数 
需求3:个人的点赞记录

数据规模、流量规模分析
做系统架构,其次,要确定 数据规模、流量规模, 为啥呢?
不同的体量,架构的方式、方法、方案,都完全不一样。
接下来,对这个案例的数据规模、流量规模进行 梳理和分析。
数据规模:千亿级别
流量规模:
读流量:30W QPS , 全站点赞状态查询、点赞数查询等【读流量】超过300k,
写流量:1.5W QPS ,点赞、点踩等【写流量】超过15K
大流量、大数据场景下点赞中台化诉求
点赞功能,在中台化之前,是分散的。各大业务模块,都有点赞功能的存在,如以下模块:
稿件、视频、动态、专栏、评论、弹幕、等等
以 “稿件” 为例,点赞服务需要提供
-
对某个稿件点赞(取消点赞)、点踩(取消点踩)
-
查询是否对 单个 或者 一批稿件 点过赞(踩) - 即点赞状态查询
-
查询某个稿件的点赞数
-
查询某个用户的点赞列表
-
查询某个稿件的点赞人列表
-
查询用户收到的总点赞数
大流量、大数据场景下,需要进行中台化、平台化
-
进行业务聚合,提供多种实体维度数据查询、数据分析的能力
-
点赞作为一个与社区实体共存的服务,需要提供很强的容灾能力
-
提供业务快速接入的能力(配置级别)
-
数据存储上(缓存、DB),具备数据隔离存储的能力(多租户)
中台化 之后的架构图如下
从此,各大业务模块,业务子系统,再也不用担心点赞的 海量数据问题, 巨量的流量问题, 点赞服务的不可用的问题。
这些问题,都交给中台解决了。各大业务模块,业务子系统,直接使用接口就行。
B赞点赞中台的整体架构
B站架构师给出的架构图
下面是哔哩哔哩资深开发工程师 芦文超, 给出的系统架构图
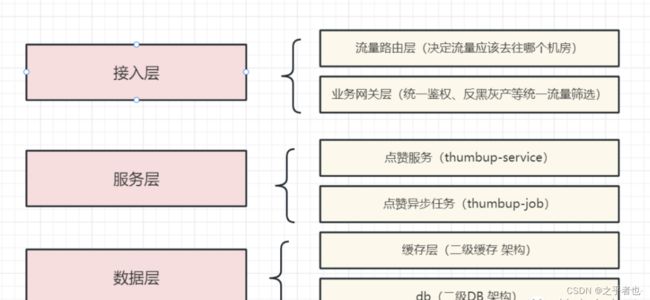
整个点赞服务的中台可以分为五个部分
-
流量路由层(决定流量应该去往哪个机房)
-
业务网关层(统一鉴权、反黑灰产等统一流量筛选)
-
点赞服务(thumbup-service),提供统一的RPC接口
-
点赞异步任务(thumbup-job)
-
数据层(db、kv、redis)
上的B站小伙伴的分层方案,从架构的维度不是太好理解,接下来给大家做进一步的梳理。
分层架构的二次梳理
接下来,对这个案例的分层架构:
接下来,一 层一层来,进行庖丁解牛。
对这个B站千亿级点赞系统服务架构设计,使之成为大家的超级学习案例。
B赞点赞中台的接入层架构
客户端的请求进来会先到SLB(负载均衡),然后到内部的网关,通过网关再分发到具体的业务服务。
业务服务会依赖Redis、Mysql、 MQ、Nacos等中间件。
B站点赞中心做异地多活,在不同地区有不同的机房,他们的架构中,有两个机房。
所以,他们的接入层的效果如下图所示:
流量路由层
用户的请求,从客户端发出,这个用户的请求该到哪个机房,这是 流量路由层 决定的。
首先,用户需要尽量路由到同一个 机房。
为什么呢?虽然服务之间的数据,是没有依赖的,但是服务内部依赖的存储是有状态的。不同的机房之间,虽然有数据同步,但是,毕竟会有延迟。如果用户修改了数据之后,再一查,查不到,感觉非常困惑。
如何 路由到同一个 机房?
首先,使用普通dns是不行的,普通的dns,域名会随机解析到不同的机房中。
一个综合方案:智能DNS+ DLB流量网关
第一个维度是智能DNS,这个具体这里不做展开。
但是智能DNS也不是万能的,需要接入层进行流量矫正。
所以针对同一个用户,尽可能在一个机房内完成业务闭环。
流量路由层 为了解决流量调度的问题,可以基于OpenResty二次开发出了DLB流量网关,DLB会对接多活控制中心,能够知道当前访问的用户是属于哪个机房,如果用户不属于当前机房,DLB会直接将请求路由到该用户所属机房内的DLB。
如果每次都随机到固定的机房,再通过DLB去校正,必然会存在跨机房请求,耗时加长。
所以在这块也是结合客户端做了一些优化,在DLB校正请求后,可以将用户对应的机房IP直接通过Header响应给客户端。
这样下次请求的时候,客户端就可以直接通过这个IP访问。
如果用户当前访问的机房挂了,客户端需要降级成之前的域名访问方式,通过DNS解析到存活的机房。
接入层的业务网关
架构和语言无关。
下面从 Java的角度进行架构分析。
业务网关包括的功能:统一鉴权、反黑灰产等统一流量筛选
接入层功能之一:统一鉴权
这一层,从架构的维度来说,可以在SpringCloud gateway 中, 使用 过滤器进行 统一鉴权
接入层功能2:流量筛选
黑灰产,又称非法产业、非法企业或非法经济
所谓网络黑灰产,指的是电信诈骗、钓鱼网站、木马病毒、黑客勒索等利用网络开展违法犯罪活动的行为。稍有不同的是,“黑产”指的是直接触犯国家法律的网络犯罪,“灰产”则是游走在法律边缘,往往为“黑产”提供辅助的争议行为。
流量筛选这一层,从架构的维度来说, 可以在SpringCloud gateway 中, 使用 过滤器进行 风险ip、风险用户id的 动态探测,拦截。
动态探测可以使用成熟的动态探讨框架,如jd的hotkey, 也可以使用滑动窗口算法,实现类似的动态探测组件。
B赞点赞中台的服务层架构
架构和语言无关。
点赞的业务比较简单,性能也可以很高。但是,之后的入库的操作,性能低。
所以,采用消息队列进行异步消峰解耦。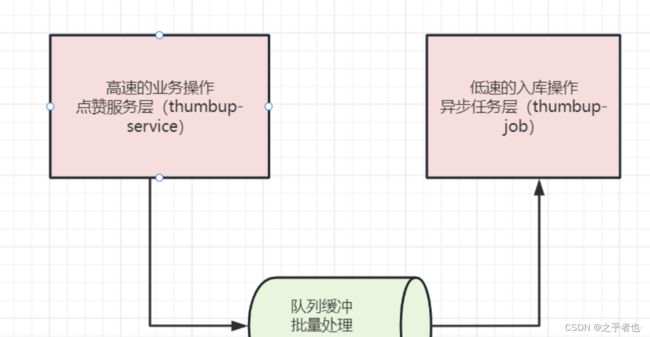
实际上,这里整体用的是异步+批量的架构,异步是一种即为重要的架构模式,关于20种异步的方式,请参见20种异步,你知道几种?
B赞点赞中台的服务层架构,细分为两层:
1 点赞服务层
2 异步任务层
点赞服务层(thumbup-service)
点赞服务层接收到用户的点赞请求,完成点赞的业务计算:
-
点赞数
-
点赞状态
-
点赞列表
-
等等
具体的功能,参考下图
异步任务层(thumbup-job)
异步任务主要作为点赞数据写入、刷新缓存、为下游其他服务发送点赞、点赞数消息等功能
-
点赞数据写入:含用户行为数据(点赞、点踩、取消等)的写入
-
缓存刷新:点赞状态缓存、点赞列表缓存、点赞计数缓存
-
同步点赞消息
-
点赞事件异步消息、点赞计数异步消息
首先是最重要的用户行为数据(点赞、点踩、取消等)的写入。
搭配对数据库的限流组件以及消费速度监控,保证数据的写入不超过数据库的负荷的同时,也不会出现数据堆积造成的C数据端查询延迟问题。
超高流量压力的异步批量处理
超高的全局流量压力:
超高并发读:全站点赞状态查询、点赞数查询等【读流量】超过300k,
超高并发写:点赞、点踩等【写流量】超过15K
采用的策略是:异步写入+批量写入
异步写入
同时数据库的写入我们也做了全面的异步化处理,保证了数据库能以合理的速率处理写入请求。
批量写入(聚合写入)
针对写流量,为了保证数据写入性能,B站在写入【点赞数】数据的时候,在内存中做了部分聚合写入,比如聚合10s内的点赞数,一次性写入。
如此可大量减少数据库的IO次数。
B赞点赞中台的数据层架构
二级缓存架构

二级缓存:分布式Cache 缓存架构
缓存层Cache:点赞作为一个高流量的服务,缓存的设立肯定是必不可少的。
点赞系统主要使用的是CacheAside模式。
这一层缓存主要基于Redis缓存:以点赞数和用户点赞列表为例,进行介绍
实体的点赞数的缓存设计
用业务ID和该业务下的实体ID作为缓存的Key,并将点赞数与点踩数拼接起来存储以及更新

key-value = count:patten:{business_id}:{message_id} - {likes},{disLikes}
business_id 代表 业务id
message_id 代表 实体 id
用户的点赞列表缓存设计
一个用户,在一个业务下的 所有点赞 的列表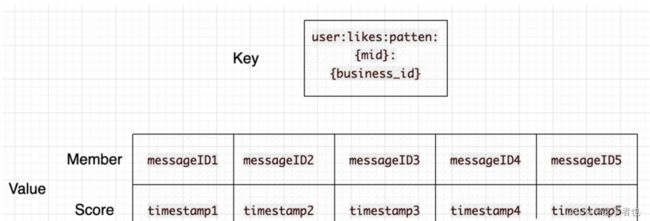
key = user:likes:patten:{mid}:{business_id}
value = zset , member(messageID)-score(likeTimestamp)
key为 mid 与业务ID , mid 代表用户 , business_id 代表业务id
value则是一个ZSet,member为被点赞的实体ID,score为点赞的时间。
当改业务下某用户有新的点赞操作的时候,被点赞的实体则会通过 zadd的方式,把最新的点赞记录加入到该ZSet里面来
为了维持用户点赞列表的长度(不至于无限扩张),需要在每一次加入新的点赞记录的时候,按照固定长度裁剪用户的点赞记录缓存。
该设计也就代表用户的点赞记录在缓存中是有限制长度的,超过该长度的数据请求需要回源DB查询
一级本地存储架构
LocalCache - 本地缓存
本地缓存的建立,目的是为了应对缓存热点问题。 本地缓存主要解决缓存击穿的问题。
在Java应用中,本地缓存建议选用命中率最高的caffeine组件, 其内存淘汰算法 wtiny-lfu,集合了 lrf与lfu的精华,非常牛掰。
热点探测:
热门事件、稿件等带来的系统热点问题,包括DB热点、缓存热点
当一个稿件成为超级热门的时候,大量的流量就会涌入到存储的单个分片上,造成读写热点问题。
此时需要有热点探测机制来识别该热点,并将数据缓存至本地,并设置合理的TTL。
例如,UP主 【杰威尔音乐】发布第一个稿件的时候就是一次典型热点事件。
所以,本地缓存一般要结合热点探讨框架使用,
二级DB架构
在架构体系中, 一般是 结构化DB+NOSql结合的二级架构模式:
-
结构化DB , 为业务计算提供数据支撑, 如mysql、tidb 等等
-
NOSql DB, 提供历史数据支撑,全量数据支撑, 大数据计算支撑, 如hbase,mongdb 等
B站的二级DB架构,也是这种经典的二级架构。
结构化数据存储
基本数据模型:
-
点赞记录表:记录用户在什么时间对什么实体进行了什么类型的操作(是赞还是踩,是取消点赞还是取消点踩)等
-
点赞计数表:记录被点赞实体的累计点赞(踩)数量
①、第一层存储:DB层 - (TiDB)
点赞系统中最为重要的就是点赞记录表(likes)和点赞计数表(counts),负责整体数据的持久化保存,以及提供缓存失效时的回源查询能力。
表1:点赞记录表 - likes :
字段:
用户Mid、被点赞的实体ID(messageID)、点赞来源、时间 等等,
索引:
联合索引(Mid、messageID ) ,用于满足业务请求。
表2:点赞数表 - counts :
字段:
业务ID(BusinessID) 、实体ID(messageID) 、实体的点赞数、点踩数等。
索引:
以业务ID(BusinessID)+实体ID(messageID)为主键,
并且按照messageID维度建立满足业务查询的索引。
结构化DB的分库分表方案
由于DB采用的是分布式数据库TiDB,所以对业务上无需考虑分库分表的操作
如果选用mysql,可以使用shardingjdbc 进行客户端分片的计算,这种方案,非常普遍。
NOSql解决全量数据的数据存储压力
点赞数据的规模:超过千亿级别
如何高效的利用存储介质存放这些数据才能既满足业务需求,也能最大程度节省成本,也是一个点赞服务正在努力改造的工程 - KV化存储
针对TIDB海量历史数据的迁移归档
迁移归档的原因(初衷),是为了减少TIDB的存储容量,节约成本的同时也多了一层存储,可以作为灾备数据。
作为一个典型的大流量基础服务,点赞的存储架构需要最大程度上满足两个点
①、最大的可靠性:满足业务读写需求的同时具备最大的可靠性
②、最小化存储成本: 选择合适的存储介质与数据存储形态,最小化存储成本
从以上两点出发,考虑到KV数据在业务查询以及性能上都更契合点赞的业务形态,选用 TaiShan(B站自研的KV数据库) 作为NoSql的存储方案。
数据一致性架构
采用的是非常经典的 cannal+binlog的架构,具体如下: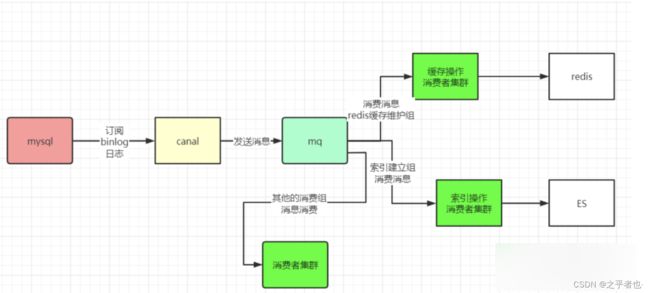
建议大家做一下实操。尤其是高可用cannal实操。
容灾架构:
作为被用户强感知的站内功能,需要考虑到各种情况下的系统容灾。例如当:
1、存储不可用
-
例如当DB不可用时,需要依托缓存尽可能提供服务。
-
同理当缓存不可用时,DB也需要保证自己不宕机的情况下尽可能提供服务。
2、消息队列不可用
-
当消息队列不可用时,依托B站自研的railgun,通过RPC调用的方式自动降级
3、机房灾难
-
切换机房, 通过 流量路由层实现
4、数据同步容灾
比如点赞就遇到过因为cannal+binlog的数据同步问题(断流、延迟)导致的点赞计数同步延迟问题。
5、服务层的容灾和降级
1、存储(db、redis等)的容灾设计(同城多活)
作为面对C端流量的直接接口,在提供服务的同时,需要思考在面对各种未知或者可预知的灾难时,如何尽可能提供服务
在DB的设计上,点赞服务有两地机房互为灾备,设计专用的proxy代理层,db-proxy(sidecar), 业务通过db-proxy(sidecar)访问 redis和db。
正常情况下,机房1承载所有写流量与部分读流量,机房2承载部分读流量。
当DB发生故障时,通过db-proxy(sidecar)的切换可以将读写流量切换至备份机房继续提供服务。


在缓存(Redis)上,点赞服务也拥有两套处于不同机房的集群,并且通过异步任务消费TiDB的binLog维护两地缓存的一致性。
可以在需要时切换机房来保证服务的提供,而不会导致大量的冷数据回源数据库。
2、数据同步容灾
点赞job对binLog的容灾设计
由于点赞的存储为TiDB,且数据量较大。
在实际生产情况中,binLog会偶遇数据延迟甚至是断流的问题。
为了减少binLog数据延迟对服务数据的影响。
服务做了以下改造。
-
监控:
首先在运维层面、代码层面都对binLog的实时性、是否断流做了监控
-
应对
脱离binlog,由业务层(thumb-service)发送重要的数据信息(点赞数变更、点赞状态事件)等。
当发生数据延迟时,程序会自动同时消费由thumbup-service发送的容灾消息,继续向下游发送。
3、服务层的容灾与降级
(以点赞数、点赞状态、点赞列表为例),点赞作为一个用户强交互的社区功能服务,对于灾难发生时用户体验的保证是放在第一位的。
所以针对重点接口,B站都会有兜底的数据作为返回。
多层数据存储互为灾备
-
点赞的热数据在redis缓存中存有一份。
-
kv数据库中存有全量的用户数据,当缓存不可用时,KV数据库会扛起用户的所有流量来提供服务。
-
TIDB目前也存储有全量的用户数据,当缓存、KV均不可用时,tidb会依托于限流,最大程度提供用户数据的读写服务。
-
因为存在多重存储,所以一致性也是业务需要衡量的点。
-
首先写入到每一个存储都是有错误重试机制的,且重要的环节,比如点赞记录等是无限重试的。
-
另外,在拥有重试机制的场景下,极少数的不同存储的数据不一致在点赞的业务场景下是可以被接受的
多地方机房互为灾备
-
点赞机房、缓存、数据库等都在不同机房有备份数据,可以在某一机房或者某地中间件发生故障时快速切换。
点赞重点接口的降级
-
点赞数、点赞、列表查询、点赞状态查询等接口,在所有兜底、降级能力都已失效的前提下也不会直接返回错误给用户,而是会以空值或者假特效的方式与用户交互。
-
后续等服务恢复时,再将故障期间的数据写回存储。
架构的演进方向
架构方案,没有最优,只有更优。
B站的点赞中台后续的演进方向大致为:
1、点赞服务单元化:要陆续往服务单元化的方向迭代、演进。
2、点赞服务平台化:在目前的业务接入基础上增加迭代数据分库存储能力,做到服务、数据自定义隔离。