计算机毕业设计:基于Python网易云音乐数据采集分析可视化系统 实时爬虫(附源码)✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。
1、项目介绍
设计语言:Python语言+ SQL语言 +HTML语言
数据爬取:selenium模块+request库
数据存储:SQLite数据库 (通过Navicat软件查看)
后端搭建:Flask框架
前端搭建:Bootstrap框架
图表展现:ECharts可视化
词云制作:pyplot库+jieba库+wordcloud库+Image+numpy数据分析库
(1)项目功能模块:
1.歌单预览页
2.歌单详情页(歌单标题、歌单作者、作者url、歌单创建日期、
歌单收藏量、歌单分享量、歌单评论数、歌单标签、歌单介绍、歌单歌曲数量)
3.歌单内音乐(歌曲id、标题、时长、歌手、专辑、歌曲url)
4.歌曲详情(歌曲id、歌曲标题、歌手、专辑、歌词、评论数、评论内容)
5.歌曲歌单评论内容(歌单歌曲辨识id、评论者id、评论者名、评论内容、
评论时间、评论点赞量、评论者url-地区累计听歌量)
1.数据库可视化:用户搜索关键词,完成相应内容可视化的展现。
1.数据呈现的多样化:多种图表形式。(用户活跃时间分布、用户地域分布、
歌单标签排名、歌曲情绪、评论区词云、歌单歌曲词云、)
2.数据维度的设计:能够从不同维度的数据分析,为用户提供更多的价值
3.界面表现的美化(可点击保存词云图片,根据歌曲id生成评论区词云、根据歌单id生成歌单词云)
2、项目界面
(1)数据可视化展示–情感分类统计图

(2)系统首页–数据概况

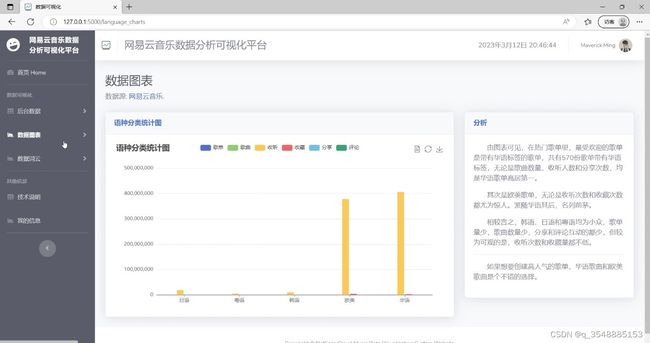
(3)语种分类统计分析
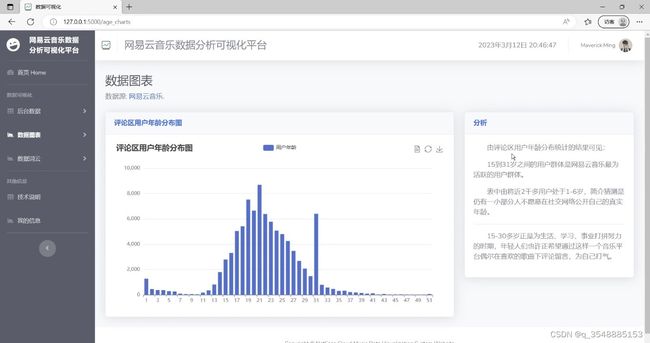
(4)评论区用户年龄分布图
(5)评论区用户进村天数分布图

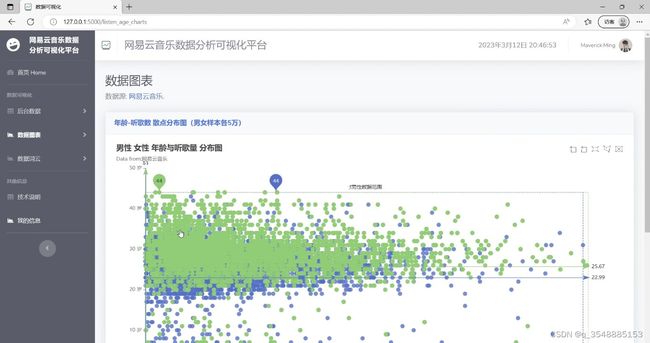
(6)性别年龄与听歌数量分布图
(7)歌词词云图

(8)数据管理

3、项目说明
(1)项目功能模块:
1.歌单预览页
2.歌单详情页(歌单标题、歌单作者、作者url、歌单创建日期、
歌单收藏量、歌单分享量、歌单评论数、歌单标签、歌单介绍、歌单歌曲数量)
3.歌单内音乐(歌曲id、标题、时长、歌手、专辑、歌曲url)
4.歌曲详情(歌曲id、歌曲标题、歌手、专辑、歌词、评论数、评论内容)
5.歌曲歌单评论内容(歌单歌曲辨识id、评论者id、评论者名、评论内容、
评论时间、评论点赞量、评论者url-地区累计听歌量)
1.数据库可视化:用户搜索关键词,完成相应内容可视化的展现。
1.数据呈现的多样化:多种图表形式。(用户活跃时间分布、用户地域分布、
歌单标签排名、歌曲情绪、评论区词云、歌单歌曲词云、)
2.数据维度的设计:能够从不同维度的数据分析,为用户提供更多的价值
3.界面表现的美化(可点击保存词云图片,根据歌曲id生成评论区词云、根据歌单id生成歌单词云)
(2)本系统主要研究从如何采集数据到如何搭建Web可视化图表的过程展开研究,包括但不限于所需技术和原理说明,采集数据的需求、手段和实现思路,对采集数据文本进行预处理即数据清洗与永久性数据库存储,对可视化web平台的构建与可视化图表的实现。本系统希望所作分析能为网易云音乐平台提供相应的歌单、歌曲的播放、收藏、分享、评论量一定的预测参考信息,也希望能为平台用户群体提供关于如何创建以及如何选择优质的歌单的参考;对网易云音乐平台如何提高用户使用率、活跃率、增强用户粘性以及给用户推送音乐信息具有一定的参考价值。
4、核心代码
from datetime import timedelta # 本来是用做时间转换的
import sqlite3 # 连接数据库
from matplotlib import pyplot as plt # 负责绘图的模块
import jieba # 提供分词、识词过滤模块
from wordcloud import WordCloud # 词云,形成有遮罩效果的图形
from PIL import Image # 图像处理,如图形虚化、验证码、图片后期处理等
import numpy as np # 矩阵运算,中文显示需要运算空间
from flask import Flask, render_template, request # Flask框架需要渲染页面用的库
# from flask_caching import Cache # Flask视图函数缓存,重复的数据,只需要缓存1次,10分钟自动清除缓存
app = Flask(__name__)
# cache = Cache(app, config={'CACHE_TYPE': 'simple'})
@app.route('/') # 首页
def index():
# 链接数据库
conn = sqlite3.connect('data/NEC_Music.db')
cur = conn.cursor()
# 读取歌单、歌曲、评论总数、精彩评论总数
sql = '''select * from count_all'''
result_list = []
table = cur.execute(sql)
for row in table:
result_list.append(row[0])
result_list.append(row[1])
result_list.append(row[2])
result_list.append(row[3])
# 随机读取两条精彩评论
sql3 = '''select song_id,userAvatar,user_id,user_name,content,likeCount from comments_info where comment_type = 'hot_comments' and likeCount > 500 order by random() limit 4;'''
table = cur.execute(sql3)
datalist = [] # 存放每一行数据
for row in table:
data = {'song_id': row[0], 'userAvatar': row[1], 'user_id': row[2], 'user_name': row[3], 'content': row[4],
'likeCount': row[5]} # 利用字典存取数据比较方便
datalist.append(data)
cur.close()
conn.close()
print('打开index')
return render_template('index.html', count=result_list, datalist=datalist)
@app.route('/songs') # 歌曲
# @cache.cached(timeout=600)
def songs():
# 链接数据库
data = {} # 利用字典输入列名取数据,之后,再利用字典列名存数据
datalist = [] # 每一条记录(字典)存到列表里,方面页面存取
conn = sqlite3.connect('data/NEC_Music.db')
cur = conn.cursor()
key_list = ['list_img', 'list_url', 'songs.song_id' ,'song_url', 'song_name', 'song_duration', 'artists_name',
'album_name', 'artists_id', 'album_size', 'album_id', 'album_img', 'publishTime', 'publishCompany',
'publishSubType', 'lyric']
for key in key_list: # 给空字典添加key:value
data[key] = ' '
keys = ', '.join(key_list) # select列名
sql = '''select {keys} from playlist inner join songs inner join songs_info
where songs.song_id = songs_info.song_id and songs.list_id = playlist.list_id
group by songs.song_id order by random() limit 50'''.format(keys=keys)
result_list = cur.execute(sql)
for row in result_list:
# print(type(row), row) # 可以见到每一行内容放在一个元组里
data = {} # 清空已存在的key:value
for i in range(len(row)):
data[key_list[i]] = row[i]
datalist.append(data)
cur.close()
conn.close()
for d in datalist:
# 为了增加详情页,将song_id转换为字符串,用来做target标识,打开相应的详情页面
d['target_id'] = str(d['songs.song_id']).replace('1', 'a').replace('2', 'b').replace('3', 'c').replace('4', 'd').replace('5', 'e').replace('6', 'f').replace('7', 'g').replace('8', 'h').replace('9', 'i').replace('10', 'j')
d['lyric'] = d['lyric'].replace(u'\n', r'
')
return render_template('songs_tables.html', datalist=datalist)
if __name__ == '__main__':
app.run()
5、源码获取
由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看获取联系方式