DDIM详解
DDIM详解
参考:https://www.bilibili.com/video/BV1VP411u71p/
虽然 DDIM 现在主要用于加速采样,但他的实际意义远不止于此。本文将首先回顾 DDPM 的训练和采样过程,再讨论 DDPM 与 DDIM 的关系,然后推导 DDIM 的采样公式,最后给出几个不同的理解 DDIM 的角度。
DDPM回顾
DDPM 实际是建模两个分布:diffusion 过程的分布 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) 、 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 和 reverse 过程的分布 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)。
diffusion 过程:
q ( x t ∣ x 0 ) = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) x t = α ˉ t x 0 + 1 − α ˉ t ϵ , ϵ ∼ N ( 0 , I ) q(x_t|x_0)=\mathcal{N}(x_t;\sqrt{\bar\alpha_t}x_0,(1-\bar{\alpha}_t)I)\\ x_t=\sqrt{\bar\alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon,\ \ \ \epsilon\sim\mathcal{N}(0,I) q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)xt=αˉtx0+1−αˉtϵ, ϵ∼N(0,I)
reverse 过程:
q ( x t − 1 ∣ x t ) = q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) = N ( x t − 1 ; μ ( x t , x 0 ) , σ t 2 I ) q(x_{t-1}|x_t)=q(x_{t-1}|x_t,x_0)=\frac{q(x_t|x_{t-1})q(x_{t-1}|x_0)}{q(x_t|x_0)}=\mathcal{N}(x_{t-1};\mu(x_t,x_0),\sigma_t^2I)\\ q(xt−1∣xt)=q(xt−1∣xt,x0)=q(xt∣x0)q(xt∣xt−1)q(xt−1∣x0)=N(xt−1;μ(xt,x0),σt2I)
其中:
μ ( x t , x 0 ) = α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 σ t 2 = 1 − α ˉ t − 1 1 − α ˉ t β t \mu(x_t,x_0)=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\bar\alpha_{t}}x_t+\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar\alpha_t}x_0 \\ \sigma_t^2=\frac{1-\bar\alpha_{t-1}}{1-\bar\alpha_t}\beta_t μ(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0σt2=1−αˉt1−αˉt−1βt
之前的文章已经详细介绍过推导过程,这里仅列出结论。
强调一个点:注意 reverse 过程中的 x 0 x_0 x0 是未知的,因此这里每一步的 x 0 x_0 x0 实际都是该步对 x 0 x_0 x0 的估计值,最终的 x 0 x_0 x0 相当于是每一步估计 x 0 x_0 x0 的加权和。DDPM 的 reverse 过程的每一步可以理解为做了两件事情:
- 根据 x t x_t xt 和 UNet 预测出的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t) 估计当前步的 x ^ 0 ∣ t \hat{x}_{0|t} x^0∣t: x ^ 0 ∣ t = 1 α ˉ t ( x t − 1 − α ˉ t ϵ θ ( x t , t ) ) \hat{x}_{0|t}=\frac{1}{\sqrt{\bar{\alpha}_t}}(x_t-\sqrt{1-\bar\alpha_t}\epsilon_\theta(x_t,t)) x^0∣t=αˉt1(xt−1−αˉtϵθ(xt,t))
- 计算出 x t − 1 x_{t-1} xt−1: x t − 1 = μ ( x t , x ^ 0 ∣ t ) + σ t ϵ , ϵ ∼ N ( 0 , I ) x_{t-1}=\mu(x_t,\hat{x}_{{0|t}})+\sigma_t\epsilon,\ \ \ \ \epsilon\sim\mathcal{N}(0,I) xt−1=μ(xt,x^0∣t)+σtϵ, ϵ∼N(0,I)
DDIM理解
在 DDPM 的采样公式 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0) 中 ,当我们已知 x 0 x_0 x0 时,当然可以通过扩散公式来计算 x t − 1 x_{t-1} xt−1 。但在采样时,我们显然并不知道真实的 x 0 x_0 x0,因此,我们使用 x t x_t xt 来计算 x 0 x_0 x0 的估计值 x 0 ∣ t x_{0|t} x0∣t ,然后计算 x t − 1 x_{t-1} xt−1 :
q ( x t − 1 ∣ x t , x 0 ) = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 ϵ , ϵ ∼ N ( 0 , I ) = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 ϵ = α ˉ t − 1 1 α ˉ t ( x t − 1 − α ˉ t ϵ θ ( x t , t ) ) + 1 − α ˉ t − 1 ϵ \begin{aligned} q(x_{t-1}|x_t,x_0)&=\sqrt{\bar{\alpha}_{t-1}}x_{0}+\sqrt{1-\bar{\alpha}_{t-1}}\ \epsilon,\ \ \ \epsilon\sim\mathcal{N}(0,I) \\ &=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar{\alpha}_{t-1}}\ \epsilon \\ &=\sqrt{\bar\alpha_{t-1}}\frac{1}{\sqrt{\bar{\alpha}_t}}(x_t-\sqrt{1-\bar\alpha_t}\epsilon_\theta(x_t,t))+\sqrt{1-\bar{\alpha}_{t-1}}\ \epsilon \end{aligned} q(xt−1∣xt,x0)=αˉt−1x0+1−αˉt−1 ϵ, ϵ∼N(0,I)=αˉt−1x^0∣t+1−αˉt−1 ϵ=αˉt−1αˉt1(xt−1−αˉtϵθ(xt,t))+1−αˉt−1 ϵ
这与我们上面复习 DDPM 时的思路相同。
对于这个式子:
q ( x t − 1 ∣ x t , x 0 ) = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 ϵ q(x_{t-1}|x_t,x_0)=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar{\alpha}_{t-1}}\ \epsilon q(xt−1∣xt,x0)=αˉt−1x^0∣t+1−αˉt−1 ϵ
我们知道 ϵ \epsilon ϵ 是采样自标准高斯分布,我们可以将其替换为模型估计的噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t):
q ( x t − 1 ∣ x t , x 0 ) = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 ϵ θ ( x t , t ) q(x_{t-1}|x_t,x_0)=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar{\alpha}_{t-1}}\ \epsilon_\theta(x_t,t) q(xt−1∣xt,x0)=αˉt−1x^0∣t+1−αˉt−1 ϵθ(xt,t)
同时考虑式 (5,6),我们可以将这两种噪声都考虑进来,则有:
q ( x t − 1 ∣ x t , x 0 ) = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 − σ t 2 ϵ θ + σ t ϵ q(x_{t-1}|x_t,x_0)=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2_t}\epsilon_\theta+\sigma_t\epsilon q(xt−1∣xt,x0)=αˉt−1x^0∣t+1−αˉt−1−σt2ϵθ+σtϵ
注意这里要保证加的两个噪声的方差和之前一样,即 1 − α ˉ t − 1 − σ t 2 2 + σ t 2 = 1 − α ˉ t − 1 2 \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2_t}^2+\sigma^2_t=\sqrt{1-\bar{\alpha}_{t-1}}^2 1−αˉt−1−σt22+σt2=1−αˉt−12 ,明显上式中是满足的。
**观察上述推导过程,其实有一个 DDPM 中的条件我们是一直没有用到的。即: q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 。 这件事情其实是 DDIM 的核心,即丢弃掉 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 这个条件。这样一来,我们的采样公式就不依赖于两步是相邻的,从而可以实现跳步的采样,即 q ( x s ∣ x k , x 0 ) q(x_s|x_k,x_0) q(xs∣xk,x0) (因此 DDIM 可以用来加速采样)。**我们有更通用的 DDIM 的采样公式:
x s = q ( x s ∣ x k , x 0 ) = α ˉ s x ^ 0 ∣ s + 1 − α ˉ s − σ k 2 ϵ θ + σ k ϵ x_s=q(x_s|x_k,x_0)=\sqrt{\bar\alpha_{s}}\hat{x}_{0|s}+\sqrt{1-\bar{\alpha}_s-\sigma^2_k}\epsilon_\theta+\sigma_k\epsilon xs=q(xs∣xk,x0)=αˉsx^0∣s+1−αˉs−σk2ϵθ+σkϵ
在这个公式中,我们丢弃了 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) 这个约束条件,实现了从任意步 k k k 到任意步 s s s 的跳步采样。在 DDPM 采样时,必须一步一步进行,而使用 DDIM 采样,则可以自己定义任意的采样步数与步长:
DDPM Samping : T = 1000 , 999 , 998 , . . . , 2 , 1 , 0 DDIM Samping : T = 1000 , 888 , 666 , . . . , 123 , 0 \text{DDPM Samping}:\ \ \ \ T=1000,999,998,...,2,1,0\\ \text{DDIM Samping}:\ \ \ \ T=1000,888,666,...,123,0 DDPM Samping: T=1000,999,998,...,2,1,0DDIM Samping: T=1000,888,666,...,123,0
DDIM 丢掉了 DDPM 中的一个条件 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) ,可以进行跳步采样,实际上是一种更一般的形式。也就是说 DDIM 加一个条件约束 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) ,即可推出 DDPM,DDPM 去掉该条件,即可得到更一般的 DDIM。

DDIM推导
接下来我们来正式地推导一下 DDIM。
首先整理一下我们推到的目标:给定 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) 和 q ( x t − 1 ∣ x 0 ) q(x_{t-1}|x_0) q(xt−1∣x0) ,不能用 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) ,求 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0) 。
这里假设 x t − 1 x_{t-1} xt−1 是 x t x_t xt 和 x 0 x_0 x0 的线性组合,记其系数分别为 m t m_t mt 和 n t n_t nt ,即有:
x t − 1 = m t x t + n t x 0 + σ t ϵ 1 x_{t-1}=m_tx_t+n_tx_0+\sigma_t\epsilon_1 xt−1=mtxt+ntx0+σtϵ1
又知道:
x t = α ˉ t x t + 1 − α ˉ t ϵ 2 x t − 1 = α ˉ t − 1 x t − 1 + 1 − α ˉ t − 1 ϵ 3 x_t=\sqrt{\bar\alpha_t}x_t+\sqrt{1-\bar{\alpha}_t}\epsilon_2 \\ x_{t-1}=\sqrt{\bar{\alpha}_{t-1}}x_{t-1}+\sqrt{1-\bar\alpha_{t-1}}\epsilon_3 xt=αˉtxt+1−αˉtϵ2xt−1=αˉt−1xt−1+1−αˉt−1ϵ3
这里用 ϵ 123 \epsilon_{123} ϵ123 的下标来区分对高斯分布的不同采样。(11) 代入 (10),有:
x t − 1 = m t ( α ˉ t x t + 1 − α ˉ t ϵ 2 ) + n t x 0 + σ t ϵ 1 = ( m t α ˉ t + n t ) x 0 + m t 1 − α ˉ t ϵ 2 + σ t ϵ 1 \begin{aligned} x_{t-1}&=m_t(\sqrt{\bar\alpha_t}x_t+\sqrt{1-\bar{\alpha}_t}\epsilon_2)+n_tx_0+\sigma_t\epsilon_1 \\ &=(m_t\sqrt{\bar{\alpha}_t}+n_t)x_0+m_t\sqrt{1-\bar{\alpha}_t}\epsilon_2+\sigma_t\epsilon_1 \end{aligned} xt−1=mt(αˉtxt+1−αˉtϵ2)+ntx0+σtϵ1=(mtαˉt+nt)x0+mt1−αˉtϵ2+σtϵ1
从而:
{ m t α ˉ t + n t = α ˉ t − 1 m t 2 ( 1 − α t ) + α t 2 = 1 − α ˉ t − 1 \begin{cases} m_t\sqrt{\bar{\alpha}_t}+n_t=\sqrt{\bar{\alpha}_{t-1}} \\ m_t^2(1-\alpha_t)+\alpha_t^2=1-\bar{\alpha}_{t-1} \\ \end{cases} {mtαˉt+nt=αˉt−1mt2(1−αt)+αt2=1−αˉt−1
立即可以计算出 m t m_t mt 和 n t n_t nt:
m t = 1 − α ˉ t − 1 − σ t 2 1 − α ˉ t n t = α ˉ t − 1 − α ˉ t 1 − α ˉ t ( 1 − α ˉ t − 1 − σ t 2 ) m_t=\sqrt{\frac{1-\bar\alpha_{t-1}-\sigma^2_t}{1-\bar\alpha_t}} \\ n_t=\sqrt{\bar\alpha_{t-1}}-\sqrt{\frac{\bar\alpha_t}{1-\bar\alpha_t}(1-\bar\alpha_{t-1}-\sigma^2_t)} mt=1−αˉt1−αˉt−1−σt2nt=αˉt−1−1−αˉtαˉt(1−αˉt−1−σt2)
代回到式 (10),有:
x t − 1 = 1 − α ˉ t − 1 − σ t 2 1 − α ˉ t x t + ( α ˉ t − 1 − α ˉ t 1 − α ˉ t ( 1 − α ˉ t − 1 − σ t 2 ) ) x 0 + σ t ϵ = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 ( 1 1 − α ˉ t x t − α ˉ t 1 − α ˉ t x 0 ) + σ t ϵ = α ˉ t − 1 x 0 + 1 − α ˉ t − 1 − σ t 2 x t − α ˉ t x 0 1 − α ˉ t + σ t ϵ \begin{aligned} x_{t-1}&=\sqrt{\frac{1-\bar\alpha_{t-1}-\sigma^2_t}{1-\bar\alpha_t}}x_t+(\sqrt{\bar\alpha_{t-1}}-\sqrt{\frac{\bar\alpha_t}{1-\bar\alpha_t}(1-\bar\alpha_{t-1}-\sigma^2_t)})x_0+\sigma_t\epsilon \\ &=\sqrt{\bar\alpha_{t-1}}x_0+\sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}(\frac{1}{\sqrt{1-\bar\alpha_t}}x_t-\frac{\sqrt{\bar\alpha_t}}{\sqrt{1-\bar\alpha_t}}x_0)+\sigma_t\epsilon \\ &=\sqrt{\bar\alpha_{t-1}}x_0+\sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}\frac{x_t-\sqrt{\bar\alpha_t}x_0}{\sqrt{1-\bar\alpha_t}}+\sigma_t\epsilon \end{aligned} xt−1=1−αˉt1−αˉt−1−σt2xt+(αˉt−1−1−αˉtαˉt(1−αˉt−1−σt2))x0+σtϵ=αˉt−1x0+1−αˉt−1−σt2(1−αˉt1xt−1−αˉtαˉtx0)+σtϵ=αˉt−1x0+1−αˉt−1−σt21−αˉtxt−αˉtx0+σtϵ
代换成模型的预测值:
x t − 1 = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( x t , t ) + σ t ϵ x_{t-1}=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}\epsilon_{\theta}(x_t,t)+\sigma_t\epsilon xt−1=αˉt−1x^0∣t+1−αˉt−1−σt2ϵθ(xt,t)+σtϵ
至此,推导出的结果式 (16) 就与式 (8) 完全一致了。即:我们使用 q ( x t ∣ x 0 ) q(x_t|x_0) q(xt∣x0) 和 q ( x t − 1 ∣ x 0 ) q(x_{t-1}|x_0) q(xt−1∣x0) 两个条件,没有用 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) ,求出了 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0) 。DDPM 去掉条件 q ( x t ∣ x t − 1 ) q(x_t|x_{t-1}) q(xt∣xt−1) ,得到了更一般的 DDIM 的采样公式。而如果我们再加上该条件,就可以把方差 σ t \sigma_t σt 的值也确定下来,就得到了 DDPM 的采样公式。
理解DDIM的三个视角
训练目标的角度
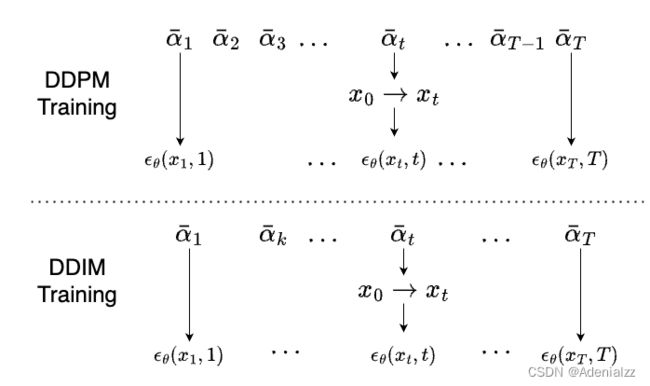
DDPM 推导了那么多公式,但是在网络训练的时候是很简单的。就是先定义一系列超参数 α ˉ 1... T \bar\alpha_{1...T} αˉ1...T ,均匀采样一个时间步 t t t,从训练集中采样真实图片,按照 α ˉ \bar\alpha αˉ 和 t t t 计算出噪声加到图片上,得到 x t x_t xt,训练一个 UNet 网络根据 x t x_t xt 和 t t t 来预测出图中噪声。也就是说,DDPM 训练的就是一个 UNet 网络在不同的噪声步条件 t t t 下对应的去噪能力。
而 DDIM 在采样时可以跳步,也就是说 UNet 只需要具备对某几个时间步的去噪能力就行了。即:DDIM 的训练目标是 DDPM 的子集。
反过来说,如果一个 DDPM 已经完整地训练完成了,UNet 具备 1... T 1...T 1...T 所有时间步的去噪能力,那么就肯定包含了 DDIM 所需要的能力。因此,一个训练好的 DDPM 网络,可以直接使用 DDIM 采样算法进行加速采样。
图示理解的角度
x t − 1 = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( x t , t ) + σ t ϵ x_{t-1}=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}\epsilon_\theta(x_t,t)+\sigma_t\epsilon xt−1=αˉt−1x^0∣t+1−αˉt−1−σt2ϵθ(xt,t)+σtϵ
观察 DDIM 的采样公式,其中一共有三项:
- 第一项 α ˉ t − 1 x ^ 0 ∣ t \sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t} αˉt−1x^0∣t 的意义是当前步对 x 0 x_0 x0 的估计,乘一个系数(图中蓝色部分)
- 第二项 1 − α ˉ t − 1 − σ t 2 ϵ θ ( x t , t ) \sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}\epsilon_\theta(x_t,t) 1−αˉt−1−σt2ϵθ(xt,t) 则相当于按照原来的方向又往回走了一段距离(图中绿色部分)
- 第三项 σ t ϵ \sigma_t\epsilon σtϵ 则表示在当前到达的位置又加了一个小扰动(图中黄色部分)
经过这样一步一步,最终逼近 x 0 x_0 x0。

这又有两种特殊情况:
特殊情况一: σ t = 0 \sigma_t=0 σt=0 。此时相当于第三项没有了,即没有了小扰动。此时采样的过程就没有随机性了,初始点 x T x_T xT 就已经决定了最终结果 x 0 x_0 x0 。这样的好处就是 x T x_T xT 可以被看做是一个隐变量,类似 GAN Inversion 那中编辑、插值的方法就都可以搞起来了。
特殊情况二: 1 − α ˉ t − 1 − σ t 2 = 0 \sqrt{1-\bar\alpha_{t-1}-\sigma_t^2}=0 1−αˉt−1−σt2=0 。此时相当于第二项没有了,这样采样过程会比较震荡。所以说,第二项的存在,能够使得采样的过程更加平滑。
常微分方程的角度
考虑 σ t = 0 \sigma_t=0 σt=0 的情况:
x t − 1 = α ˉ t − 1 x ^ 0 ∣ t + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( x t , t ) = α ˉ t − 1 ⋅ 1 α ˉ t ( x t − 1 − α ˉ t ϵ θ ( x t , t ) ) + 1 − α ˉ t − 1 − σ t 2 ϵ θ ( x t , t ) x t − 1 α ˉ t − 1 = x t α ˉ t − 1 − α ˉ t α ˉ t ϵ θ ( x t , t ) + 1 − α ˉ t − 1 α ˉ t − 1 ϵ θ ( x t , t ) x t − 1 α ˉ t − 1 − x t α ˉ t = ( 1 − α ˉ t − 1 α ˉ t − 1 − 1 − α ˉ t α ˉ t ) ϵ θ ( x t , t ) \begin{aligned} x_{t-1}&=\sqrt{\bar\alpha_{t-1}}\hat{x}_{0|t}+\sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}\epsilon_\theta(x_t,t) \\ &=\sqrt{\bar\alpha_{t-1}}\cdot \frac{1}{\sqrt{\bar\alpha_t}}(x_t-\sqrt{1-\bar\alpha_t}\epsilon_\theta(x_t,t))+\sqrt{1-\bar\alpha_{t-1}-\sigma^2_t}\epsilon_\theta(x_t,t) \\ \frac{x_{t-1}}{\sqrt{\bar\alpha_{t-1}}}&=\frac{x_t}{\sqrt{\bar\alpha_t}}-\sqrt{\frac{1-\bar\alpha_t}{\bar\alpha_t}}\epsilon_\theta(x_t,t)+\sqrt{\frac{1-\bar\alpha_{t-1}}{\bar\alpha_{t-1}}}\epsilon_\theta(x_t,t) \\ \frac{x_{t-1}}{\sqrt{\bar\alpha_{t-1}}}-\frac{x_t}{\sqrt{\bar\alpha_t}}&=(\sqrt{\frac{1-\bar\alpha_{t-1}}{\bar\alpha_{t-1}}}-\sqrt{\frac{1-\bar\alpha_t}{\bar\alpha_t}})\ \epsilon_\theta(x_t,t) \end{aligned} xt−1αˉt−1xt−1αˉt−1xt−1−αˉtxt=αˉt−1x^0∣t+1−αˉt−1−σt2ϵθ(xt,t)=αˉt−1⋅αˉt1(xt−1−αˉtϵθ(xt,t))+1−αˉt−1−σt2ϵθ(xt,t)=αˉtxt−αˉt1−αˉtϵθ(xt,t)+αˉt−11−αˉt−1ϵθ(xt,t)=(αˉt−11−αˉt−1−αˉt1−αˉt) ϵθ(xt,t)
可以看到,这已经是一个差分的形式。
记 自变量为 s ∈ [ 0 , 1 ] s\in[0,1] s∈[0,1], a = α ˉ a=\sqrt{\bar\alpha} a=αˉ , σ = 1 − α ˉ α ˉ \sigma=\sqrt{\frac{1-\bar\alpha}{\bar\alpha}} σ=αˉ1−αˉ ,则有:
d d s ( x ( s ) a ( s ) ) = d d s σ ( s ) ϵ θ ( x ( s ) , t ( s ) ) \frac{d}{ds}(\frac{x(s)}{a(s)})=\frac{d}{ds}\sigma(s)\epsilon_\theta(x(s),t(s)) dsd(a(s)x(s))=dsdσ(s)ϵθ(x(s),t(s))
这就把离散的形式写成连续的形式。
那么,扩散模型采样的过程就相当于:给定 x ( 1 ) ∼ N ( 0 , I ) x(1)\sim\mathcal{N}(0,I) x(1)∼N(0,I),求 x ( 0 ) x(0) x(0) 。这样一来,扩散模型的采样过程就相当于求解这个常微分方程。从而,很多加速求解常微分方程的方法,都可以用来加速扩散模型的采样过程。