DolphinScheduler 2.0.5详解
文章目录
-
-
- 第一章 DolphinScheduler介绍
-
- 1.1 关于DolphinScheduler
- 1.2 DolphinScheduler特性
- 1.3 配置建议
-
- 1.3.1 Linux 操作系统版本要求
- 1.3.2 服务器建议配置
- 1.3.3 生产环境
- 1.3.4 网络要求
- 1.3.5 客户端 Web 浏览器要求
- 第二章 DolphinScheduler安装部署
-
- 2.1 安装部署介绍
- 2.2 单机版部署
- 2.3 集群部署
-
- 2.3.1 集群规划
- 2.3.2 集群准备工作
- 2.3.3 修改相关配置
- 2.3.4 初始化数据库
- 2.3.5 安装并启动DolphinScheduler
- 2.3.6 启停命令
- 2.3.7 登录DolphinScheduler
- 2.3.8 Master和Worker查看
- 2.3.9 集群安装部署流程总结
- 第三章 DolphinScheduler功能应用
-
- 3.1 租户创建
- 3.2 创建用户
- 3.3 创建项目
- 3.4 进入项目
- 3.5 创建工作流
- 3.6 创建依赖或者并行任务工作流
- 3.7 上线执行-补数-重跑执行
- 3.8 工作流中单个任务运行
- 3.9 定时管理
- 3.10 工作流的导出导入
- 3.11 数据中心操作
-
- 3.11.1 MySQL数据源
- 3.11.2 MySQL数据源创建问题解决
- 3.11.3 Hive数据源准备
- 3.11.4 Hiveserver2连接错误
- 3.11.5 Hive数据源连接
- 3.11.6 Spark的数据源
- 3.12 任务类型
-
- 3.12.1 Shell类型
- 3.12.2 SQL类型
- 3.12.3 Hive任务类型
- 3.12.4 Python类型
- 3.13 参数
-
- 3.13.1 内置参数
- 3.13.2 衍生内置参数
- 3.13.3 本地和全局参数
- 3.13.4 参数优先级
- 3.14 告警
-
- 3.14.1 钉钉告警准备
- 3.14.2 钉钉告警
-
第一章 DolphinScheduler介绍
1.1 关于DolphinScheduler
**定义:**Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度平台。
**作用:**致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
- 解决错综复杂的依赖关系不能直观监控任务健康状态等问题。
- DolphinScheduler以DAG流式的方式将Task组装起来,可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及Kill任务等操作。
架构:

1.2 DolphinScheduler特性
-
简单易用
DAG监控界面,所有流程定义都是可视化,通过拖拽任务定制DAG,通过API方式与第三方系统对接, 一键部署
-
高可靠性
去中心化的多Master和多Worker, 自身支持HA功能, 采用任务队列来避免过载,不会造成机器卡死
-
丰富的使用场景
支持暂停恢复操作.支持多租户,更好的应对大数据的使用场景. 支持更多的任务类型,如 spark, hive, mr, python, sub_process, shell
-
高扩展性
支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master和Worker支持动态上下线
1.3 配置建议
DolphinScheduler 作为一款开源分布式工作流任务调度系统,可以很好地部署和运行在 Intel 架构服务器及主流虚拟化环境下,并支持主流的Linux操作系统环境
1.3.1 Linux 操作系统版本要求
| 操作系统 | 版本 |
|---|---|
| Red Hat Enterprise Linux | 7.0 及以上 |
| CentOS | 7.0 及以上,测试Centos 6.8也可以 |
| Oracle Enterprise Linux | 7.0 及以上 |
| Ubuntu LTS | 16.04 及以上 |
注意: 以上 Linux 操作系统可运行在物理服务器以及 VMware、KVM、XEN 主流虚拟化环境上
1.3.2 服务器建议配置
DolphinScheduler 支持运行在 Intel x86-64 架构的 64 位通用硬件服务器平台。对生产环境的服务器硬件配置有以下建议:
1.3.3 生产环境
| CPU | 内存 | 硬盘类型 | 网络 | 实例数量 |
|---|---|---|---|---|
| 4核+ | 8 GB+ | SAS | 千兆网卡 | 1+ |
注意:
- 以上建议配置为部署 DolphinScheduler 的最低配置,生产环境强烈推荐使用更高的配置
- 硬盘大小配置建议 50GB+ ,系统盘和数据盘分开
1.3.4 网络要求
DolphinScheduler正常运行提供如下的网络端口配置:
| 组件 | 默认端口 | 说明 |
|---|---|---|
| MasterServer | 5678 | 非通信端口,只需本机端口不冲突即可 |
| WorkerServer | 1234 | 非通信端口,只需本机端口不冲突即可 |
| ApiApplicationServer | 12345 | 提供后端通信端口 |
注意:
- MasterServer 和 WorkerServer 不需要开启网络间通信,只需本机端口不冲突即可
- 管理员可根据实际环境中 DolphinScheduler 组件部署方案,在网络侧和主机侧开放相关端口
1.3.5 客户端 Web 浏览器要求
DolphinScheduler 推荐 Chrome 以及使用 Chromium 内核的较新版本浏览器访问前端可视化操作界面
第二章 DolphinScheduler安装部署
2.1 安装部署介绍
DolphinScheduler提供了4种安装部署方式:
- 单机部署(Standalone):Standalone 仅适用于 DolphinScheduler 的快速体验。如果你是新手,想要体验 DolphinScheduler 的功能,推荐使用[Standalone]方式体检。
- 伪集群部署(Pseudo-Cluster):伪集群部署目的是在单台机器部署 DolphinScheduler 服务,该模式下master、worker、api server 都在同一台机器上。如果你想体验更完整的功能,或者更大的任务量,推荐使用伪集群部署。
- 集群部署(Cluster):集群部署目的是在多台机器部署 DolphinScheduler 服务,用于运行大量任务情况。如果你是在生产中使用,推荐使用集群部署或者kubernetes。
- Kubernetes 部署:Kubernetes部署目的是在Kubernetes集群中部署 DolphinScheduler 服务,能调度大量任务,可用于在生产中部署。
注意:
1、Standalone仅建议20个以下工作流使用,因为其采用内存式的H2 Database, Zookeeper Testing Server,任务过多可能导致不稳定,并且如果重启或者停止standalone-server会导致内存中数据库里的数据清空。 如果您要连接外部数据库,比如mysql或者postgresql。
2、Kubernetes部署先决条件:Helm3.1.0+ ;Kubernetes1.12+;PV 供应(需要基础设施支持)
2.2 单机版部署
Standalone 仅适用于 DolphinScheduler 的快速体验.
如果你是新手,想要体验 DolphinScheduler 的功能,推荐使用Standalone方式体检。如果你想体验更完整的功能,或者更大的任务量,推荐使用伪集群部署。如果你是在生产中使用,推荐使用集群部署或者kubernetes
*注意:* Standalone仅建议20个以下工作流使用,因为其采用内存式的H2 Database, Zookeeper Testing Server,任务过多可能导致不稳定,并且如果重启或者停止standalone-server会导致内存中数据库里的数据清空。 如果您要连接外部数据库,比如mysql或者postgresql,请看配置数据库
-
前置准备工作
- JDK:下载JDK (1.8+),安装并配置
JAVA_HOME环境变量,并将其下的bin目录追加到PATH环境变量中。如果你的环境中已存在,可以跳过这步。 - 二进制包:在下载页面下载 DolphinScheduler 二进制包
- JDK:下载JDK (1.8+),安装并配置
-
启动 DolphinScheduler Standalone Server
-
解压并启动 DolphinScheduler
二进制压缩包中有 standalone 启动的脚本,解压后即可快速启动。切换到有sudo权限的用户,运行脚本
# 解压并运行 Standalone Server [root@qianfeng01 soft]# cd /opt/soft [root@qianfeng01 soft]# tar -zxvf apache-dolphinscheduler-2.0.5-bin.tar.gz [root@qianfeng01 soft]# cd ./apache-dolphinscheduler-2.0.5-bin [root@qianfeng01 apache-dolphinscheduler-2.0.5-bin]# ./bin/dolphinscheduler-daemon.sh start standalone-server #查询dolphinscheduler的单机服务 [root@qianfeng01 apache-dolphinscheduler-2.0.5-bin]# jps 18688 Jps 18665 StandaloneServer -
登录 DolphinScheduler
浏览器访问地址 http://qianfeng01:12345/dolphinscheduler 即可登录系统UI。默认的用户名和密码是 admin/dolphinscheduler123

-
启停服务
脚本
./bin/dolphinscheduler-daemon.sh除了可以快捷启动 standalone 外,还能停止服务运行,全部命令如下# 启动 Standalone Server 服务 [root@qianfeng01 apache-dolphinscheduler-2.0.5-bin]# ./bin/dolphinscheduler-daemon.sh start standalone-server # 停止 Standalone Server 服务 [root@qianfeng01 apache-dolphinscheduler-2.0.5-bin]# ./bin/dolphinscheduler-daemon.sh stop standalone-server -
配置数据库
Standalone server 使用 H2 数据库作为其元数据存储数据,这是为了上手简单,用户在启动服务器之前不需要启动数据库。但是如果用户想将元数据库存储在 MySQL 或 PostgreSQL 等其他数据库中,他们必须更改一些配置。请参考 数据源配置
Standalone 切换元数据库创建并初始化数据库。
单机版到此为止即可。
2.3 集群部署
2.3.1 集群规划
集群模式下,可配置多个Master及多个Worker。通常可配置2~3个Master,若干个Worker。由于集群资源有限,此处配置一个Master,三个Worker,集群规划如下。
| 主机名 | ip | 服务 | 备注 |
|---|---|---|---|
| qianfeng01 | 192.168.10.101 | master,worker | |
| qianfeng02 | 192.168.10.102 | master,worker | 该服务器也可以安装master |
| qianfeng02 | 192.168.10.103 | worker |
2.3.2 集群准备工作
-
操作系统:linux centos 7.7
-
部署版本:apache-dolphinscheduler-2.0.5-bin
-
JDK:配置Java环境,将JAVA_HOME配置于PATH中,推荐版本使用jdk8+
-
数据库:本文使用的是MySQL 8.0.26版本,也可以使用5.7版本及以上,或者是使用PostgreSQL数据库(8.2.15+)
-
注册中心:zookeeper(3.4.6+)
-
依赖大数据相关组件及版本为:Zookeeper 3.6.3、Hadoop 3.3.1 、Hive 3.1.2 、Spark 3.1.2
-
创建部署用户,并为该用户配置免登录,以创建dolphinscheduler用户为例(
每一台需要部署DolphinScheduler都需要执行)# 创建用户需使用root登录 useradd dolphinscheduler # 添加密码 echo "dolphinscheduler" | passwd --stdin dolphinscheduler # 配置sudo(系统管理命令)免密 sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers注意:
- 因为任务执行服务是以
sudo -u {linux-user}切换不同 linux 用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。初学习者不理解的话,完全可以暂时忽略这一点 - 如果发现
/etc/sudoers文件中有 “Defaults requirett” 这行,也请注释掉
- 因为任务执行服务是以
-
配置机器SSH免密登陆
由于安装的时候需要向不同机器发送资源,所以要求各台机器间能实现SSH免密登陆。配置免密登陆的步骤如下
#分别在每台安装dolphinscheduler的服务器上执行如下命令 su dolphinscheduler ssh-keygen -t rsa ssh-copy-id qianfeng01 ssh-copy-id qianfeng02 ssh-copy-id qianfeng03注意:
配置完成后,可以通过运行命令
ssh localhost判断是否成功,如果不需要输入密码就能ssh登陆则证明成功 -
启动zookeeper集群(
外置Zookeeper集群启动即可)# 启动 zookeeper zkServer.sh start
2.3.3 修改相关配置
完成了基础环境的准备后,在运行部署命令前,还需要根据环境修改配置文件。配置文件在路径在conf/config/install_config.conf下,一般部署只需要修改INSTALL MACHINE、DolphinScheduler ENV、Database、Registry Server部分即可完成部署,下面对必须修改参数进行说明
-
在安装之前需要修改install_config.conf文件,基础安装只需要修改INSTALL MACHINE、DolphinScheduler ENV、Database、Registry Server几个部分即可,下面对这些参数进行说明:
[root@qianfeng01 soft]# vim /opt/soft/apache-dolphinscheduler-2.0.5-bin/conf/config/install_config.conf # --------------------------------------------------------- # INSTALL MACHINE # --------------------------------------------------------- # 集群服务器(hostname/ip) ips="qianfeng01,qianfeng02,qianfeng03" # 默认ssh端口 sshPort="22" # 集群主节点,多个使用逗号分隔 masters="qianfeng01" # 集群从节点列表 workers="qianfeng01:default,qianfeng02:default,qianfeng03:default" # 告警服务节点 alertServer="qianfeng02" # API服务阶段 apiServers="qianfeng01" # Python网关服务节点 pythonGatewayServers="qianfeng01" # 集群安装目录,如果不存在由`install.sh`来创建 installPath="/usr/local/dolphinscheduler" # 部署用户,该用户需要在`install.sh`脚本运行前在所有节点创建,还需要sudo权限,hdfs的根目录也需要该用户有权限 deployUser="dolphinscheduler" # 数据目录,确保上述用户拥有操作权限 dataBasedirPath="/home/dolphinscheduler/data" # --------------------------------------------------------- # DolphinScheduler ENV # --------------------------------------------------------- # 指定Java安装目录 javaHome="/usr/local/jdk1.8.0_321/" # 指定api服务端口,默认12345 apiServerPort="12345" # --------------------------------------------------------- # Database # NOTICE: If database value has special characters, such as `.*[]^${}\+?|()@#&`, Please add prefix `\` for escaping. # --------------------------------------------------------- # 指定元数据库类型,目前支持:``postgresql``, ``mysql`, `h2``.默认h2 DATABASE_TYPE=${DATABASE_TYPE:-"mysql"} # 指定Spring datasource url SPRING_DATASOURCE_URL=${SPRING_DATASOURCE_URL:-"jdbc:mysql://qianfeng01:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8"} # Spring datasource username SPRING_DATASOURCE_USERNAME=${SPRING_DATASOURCE_USERNAME:-"root"} # Spring datasource password SPRING_DATASOURCE_PASSWORD=${SPRING_DATASOURCE_PASSWORD:-"123456"} # --------------------------------------------------------- # Registry Server # --------------------------------------------------------- # 注册服务插件名称 registryPluginName="zookeeper" # 注册zk集群地址 registryServers="qianfeng01:2181,qianfeng02:2181,qianfeng03:2181" # 注册在zk中的命名空间 registryNamespace="dolphinscheduler" # --------------------------------------------------------- # Worker Task Server # --------------------------------------------------------- # worker服务插件目录 taskPluginDir="lib/plugin/task" # 资源存储类型 resourceStorageType="HDFS" # 资源存储路径,建议使用/dolphinscheduler resourceUploadPath="/dolphinscheduler" # 指定hdfs入口 defaultFS="hdfs://qianfeng01:9000" # yarn的端口 resourceManagerHttpAddressPort="8088" # 如果yarn开启HA,指定HA的虚拟服务名 yarnHaIps="ns-yarn" # 单RM服务节点 singleYarnIp="yarnIp1" # 拥有创建HDFS/S3根目录的权限用户 # Note: if kerberos is enabled, please config hdfsRootUser= hdfsRootUser="hdfs" # kerberos config # kerberos启用,默认关闭 kerberosStartUp="false" # kdc krb5 config file path krb5ConfPath="$installPath/conf/krb5.conf" # keytab username,watch out the @ sign should followd by \\ keytabUserName="hdfs-mycluster\\@ESZ.COM" # username keytab path keytabPath="$installPath/conf/hdfs.headless.keytab" # kerberos expire time, the unit is hour kerberosExpireTime="2" # 是否用sudo权限 sudoEnable="true" # worker tenant auto create workerTenantAutoCreate="false"如果HDFS是HA,执行如下的操作
cp /usr/local/hadoop-3.3.1/etc/hadoop/core-site.xml /usr/local/hadoop-3.3.1/etc/hadoop/hdfs-site.xml /opt/soft/apache-dolphinscheduler-2.0.5-bin/conf/
2.3.4 初始化数据库
DolphinScheduler 任然需要元数据,目前元数据支持存储在 PostgreSQL 和 MySQL中(默认是h2数据库),所以需要创建专用的元数据库、用户和密码。
-
创建数据库、用户和授权
-- 进入MySQL命令行 [root@qianfeng01 soft]# mysql -uroot -p123456 -- 创建dolphinscheduler的元数据库,并指定编码 mysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci; -- 为dolphinscheduler数据库授权 mysql> grant all privileges on dolphinscheduler.* to 'root'@'%'; -- 刷新权限 mysql> flush privileges; -
添加MySQL的lib依赖
MySQL 需要手动下载 对应的mysql-connector-java 驱动并添加到 DolphinScheduler 的 lib目录下。
[root@qianfeng01 apache-dolphinscheduler-2.0.5-bin]# cp /opt/soft/mysql-connector-java-5.1.28-bin.jar /opt/soft/apache-dolphinscheduler-2.0.5-bin/lib/ -
初始化元数据
[root@qianfeng01 soft]# sh ./apache-dolphinscheduler-2.0.5-bin/script/create-dolphinscheduler.sh ...... 2022-05-22 00:01:44.979 INFO 31419 --- [ main] .u.s.CreateDolphinScheduler$CreateRunner : init DolphinScheduler finished 2022-05-22 00:01:44.979 INFO 31419 --- [ main] .u.s.CreateDolphinScheduler$CreateRunner : create DolphinScheduler success 2022-05-22 00:01:44.985 INFO 31419 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : DolphinScheduler - Shutdown initiated... 2022-05-22 00:01:44.986 INFO 31419 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : DolphinScheduler - Shutdown completed.
2.3.5 安装并启动DolphinScheduler
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 安装目录下的logs 文件夹内
[root@qianfeng01 soft]# sh ./apache-dolphinscheduler-2.0.5-bin/install.sh
注意: 第一次部署的话,可能出现 5 次sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,为非重要信息直接忽略即可。
2.3.6 启停命令
第一次安装后会自动启动所有服务的,如有服务问题或者后续需要启停,命令如下。下面的操作脚本都在dolphinScheduler安装目录bin下。
# 一键停止集群所有服务
sh /usr/local/dolphinscheduler/bin/stop-all.sh
# 一键开启集群所有服务
sh /usr/local/dolphinscheduler/bin/start-all.sh
########单个服务的启动和停止使用如下命令
# 启停 Master
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop master-server
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh start master-server
# 启停 Worker
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh start worker-server
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop worker-server
# 启停 Api
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh start api-server
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop api-server
# 启停 Logger
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh start logger-server
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop logger-server
# 启停 Alert
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh start alert-server
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop alert-server
# 启停 Python Gateway
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh start python-gateway-server
sh /usr/local/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop python-gateway-server
2.3.7 登录DolphinScheduler
访问http://192.168.10.101:12345/dolphinscheduler或者http://qianfeng01:12345/dolphinscheduler即可登录系统UI,默认的用户名和密码是 admin/dolphinscheduler123
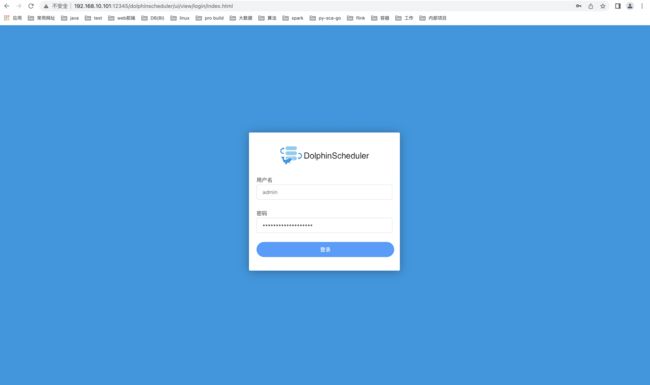
登陆成功如下:

2.3.8 Master和Worker查看
查看Master和workers情况如下:

到此为止,dolphinscheduler集群安装成功。
2.3.9 集群安装部署流程总结
-
准备工作:创建dolphinscheduler用户并且做免登录
-
将apache-dolphinscheduler-2.0.5-bin.tar.gz上传到服务器某个目录
-
将服务器的apache-dolphinscheduler-2.0.5-bin.tar.gz解压到某一个目录即可
-
配置解压目录下的install_config.conf文件,命令为:
vim /opt/soft/apache-dolphinscheduler-2.0.5-bin/conf/config/install_config.conf -
提前自己创建mysql中的dolphinscheduler的元数据库(dolphinscheduler),并要将该元数据库授予对应用户(root)所有权限。
-
将对应的mysql的数据库的连接驱动拷贝到apache-dolphinscheduler-2.0.5-bin.tar.gz解压目录下的lib目录下,命令如下:
cp /opt/soft/mysql-connector-java-5.1.28-bin.jar /opt/soft/apache-dolphinscheduler-2.0.5-bin/lib/ -
dolphinscheduler的元数据库(dolphinscheduler)的初始化。命令:
sh /opt/soft/apache-dolphinscheduler-2.0.5-bin/script/create-dolphinscheduler.sh初始化后,一定要检查mysql中的dolphinscheduler是否有44张表。
-
先启动zookeeper集群,以确保后续的安装成功。启动命令:
/opt/soft/zookeeper/bin/zkServer.sh start -
dolphinscheduler的安装,这一步仅需成功执行一次,命令如下:
sh /opt/soft/apache-dolphinscheduler-2.0.5-bin/install.sh -
在master所在的服务器监听12345端口是否启动,命令如下:
netstat -nltcp | grep 12345 -
如果监听12345成功,则几乎可以访问web ui页面,访问路径为:http://qianfeng01:12345/dolphinscheduler/
安装常见的问题及重新安装注意事项:
所有服务都启动成功,12345监听也成功,但是web ui使用默认的用户名和密码始终登录不上或者没有反应。
检查MySQL中的dolphinscheduler元数据库是否有对应的数据。如果没有,必须要重新生成,并且重新安装。重新安装流程:
1.删除每台服务器的安装目录:rm -rf /usr/local/dolphinscheduler 2.删除zk集群中的dolphinscheduler中的znode节点,命令如下: [root@qianfeng01 soft]# /usr/local/zookeeper-3.6.3/bin/zkCli.sh [zk: localhost:2181(CONNECTED) 1]rmr /dolphinscheduler 3.删除MySQL中的元数据库 (如果有44张表可以不删除) ,如果删除元数据库就必须要重新去初始化一遍 4.然后重新执行安装命令即可。命令如:sh /opt/soft/apache-dolphinscheduler-2.0.5-bin/install.sh
第三章 DolphinScheduler功能应用
3.1 租户创建
租户是操作系统中的实际的用户。

删除、修改等等都可以,但是需要管理员。
3.2 创建用户
用户是dolphinscheudler系统中的用户,可以登录、可以提交作业、可以进行数据开发。

该用户是可以用于登录该系统。同时,在企业中,用户的授权很重要。
3.3 创建项目

项目也可以进行删除、修改等操作。
3.4 进入项目

3.5 创建工作流
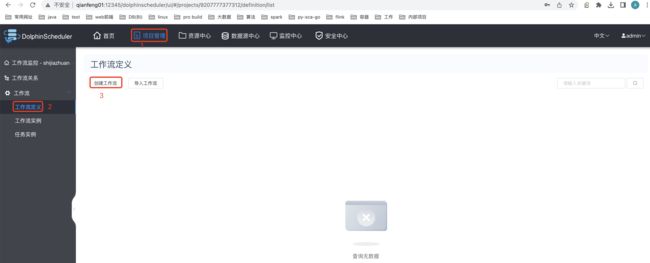
创建shell 类型的task:

保存Shell类型任务的工作流:
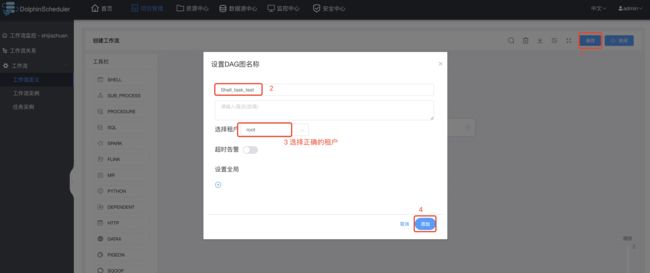
工作流列表查看,并上线工作流:

工作流还可以进行编辑,但是必须先下线,才能编辑。还能进行复制、删除、查看版本等操作。
工作流运行状态:
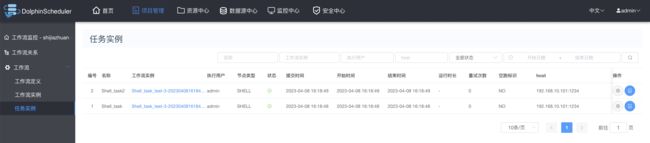
3.6 创建依赖或者并行任务工作流
Shell类型的start任务开始:

Shell类型的TaskA任务的配置如下:

Shell类型的TaskB任务配置如下:

Shell类型的end任务配置如下:
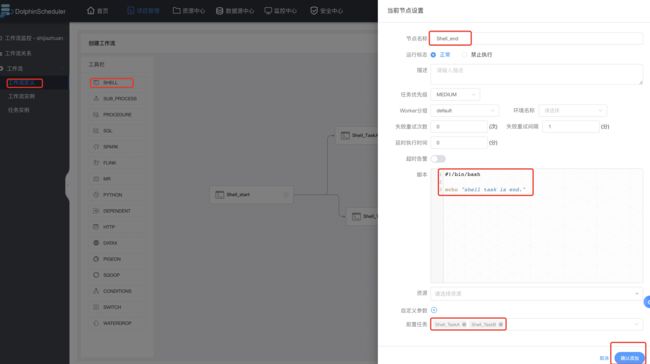
Shell类型工作流保存:

3.7 上线执行-补数-重跑执行
-
对Shell_task_test工作流先上线,然后非补数运行如下:
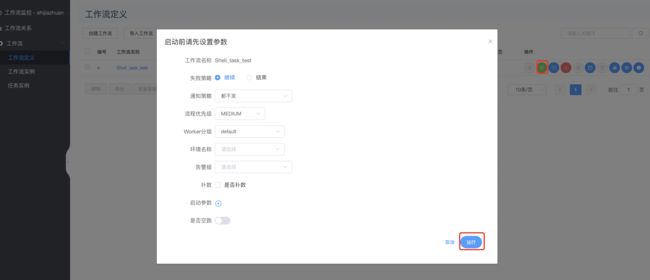
查看普通运行结果:
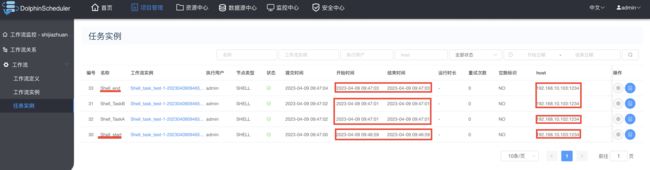
查看task运行日志:
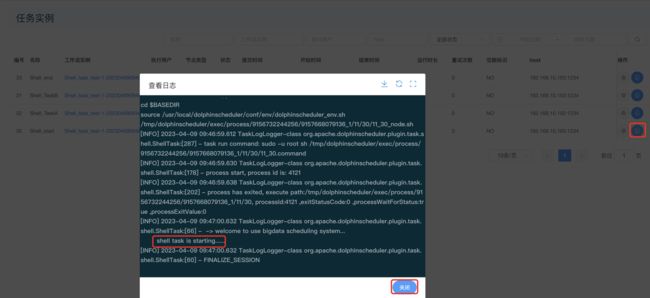
-
对Shell_task_test工作流先上线,然后非补数运行如下:

补数据成功截图:
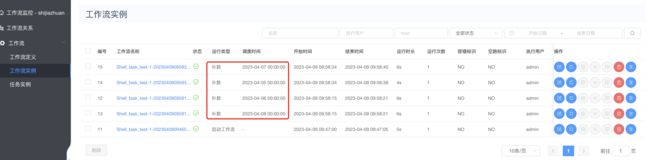
-
重跑执行
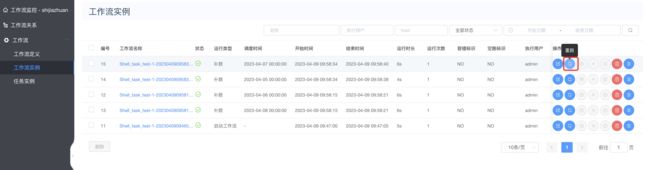
重跑成功如下:
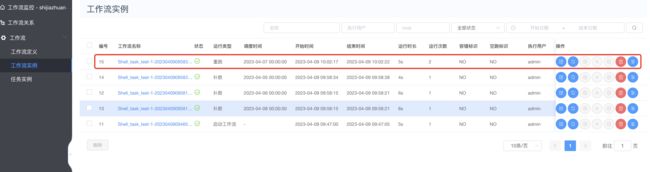
3.8 工作流中单个任务运行
点击某个工作流—>进入DAG面板—>如下图所示:

运行配置如下图所示:
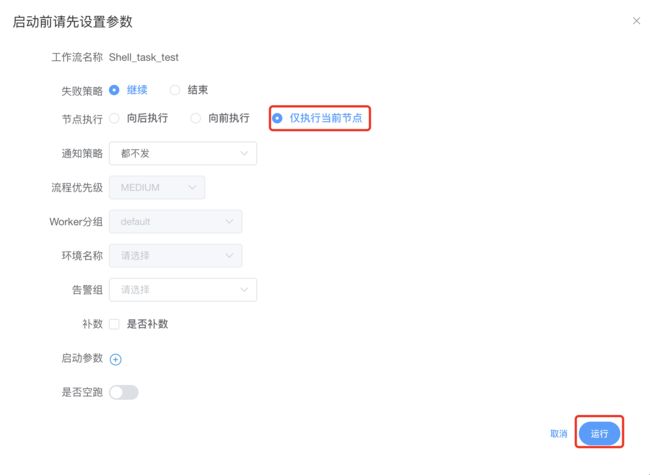
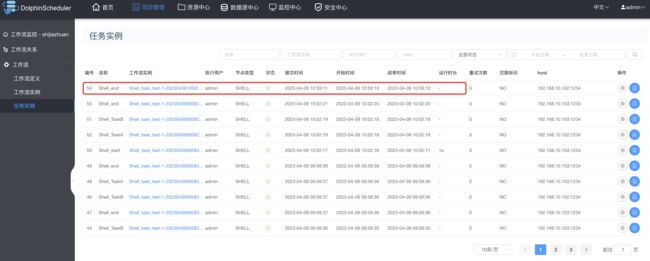
执行结果如下:
3.9 定时管理
工作流—>定时—>如下图:
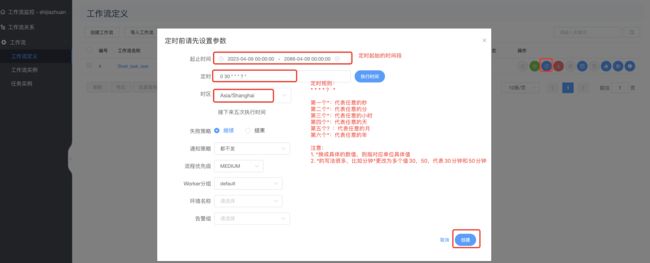
创建后如下图所示:

上线定时任务:
工作流—>点击定时管理—>如下图:

定时工作流上线如下图:

定时任务执行结果:
3.10 工作流的导出导入
导出工作流如下图:

导入工作流:
导入之前,需要将导出的json文件或者已经存在json文件中的工作流名称修改成和ds中已有的工作流名称不一致即可。

导入之后的结果如下:

3.11 数据中心操作
3.11.1 MySQL数据源
数据源中心->创建数据源:

配置MySQL数据源如下图:

创建好MySQL的数据源后如下图:

到此为止,MySQL的数据源配置好。
3.11.2 MySQL数据源创建问题解决
-
去服务器上,查看dolphinscheduler安装目录下lib和各个模块下的libs下的mysql-connector-java-版本情况,命令如下:
[root@qianfeng01 dolphinscheduler]# ll ./lib/mysql-connector-java-8.0.26.jar -rw-r--r--. 1 root root 2462364 4月 8 19:05 ./lib/mysql-connector-java-8.0.26.jar [root@qianfeng01 dolphinscheduler]# ll ./api-server/libs/mysql-connector-java-8.0.16.jar -rw-r--r--. 1 root root 2293144 4月 8 13:41 ./api-server/libs/mysql-connector-java-8.0.16.jar [root@qianfeng01 dolphinscheduler]# ll ./master-server/libs/mysql-connector-java-8.0.16.jar -rw-r--r--. 1 root root 2293144 4月 8 13:41 ./master-server/libs/mysql-connector-java-8.0.16.jar [root@qianfeng01 dolphinscheduler]# ll ./worker-server/libs/mysql-connector-java-8.0.16.jar -rw-r--r--. 1 root root 2293144 4月 8 13:41 ./worker-server/libs/mysql-connector-java-8.0.16.jar [root@qianfeng01 dolphinscheduler]# ll ./alert-server/libs/mysql-connector-java-8.0.16.jar -rw-r--r--. 1 root root 2293144 4月 8 13:41 ./alert-server/libs/mysql-connector-java-8.0.16.jar -rw-r--r--. 1 root root 2293144 4月 8 13:41 ./tools/libs/mysql-connector-java-8.0.16.jar -
将dolphinscheduler安装目录下lib目录下mysql进行备份(三台服务器都执行)
[root@qianfeng01 dolphinscheduler]# cd /usr/local/dolphinscheduler [root@qianfeng01 dolphinscheduler]# mv ./lib/mysql-connector-java-8.0.26.jar ./lib/mysql-connector-java-8.0.26.jar.bak -
将mysql-connector-java-8.0.16.jar包复制到dolphinscheduler安装目录下lib目录下(要求每台服务器都执行)
cp /home/software/mysql-connector-java-8.0.16.jar /usr/local/dolphinscheduler/lib/ #其它两台服务器建议用scp远程拷贝 scp /home/software/mysql-connector-java-8.0.16.jar qianfeng02:/usr/local/dolphinscheduler/lib/ scp /home/software/mysql-connector-java-8.0.16.jar qianfeng03:/usr/local/dolphinscheduler/lib/ -
如果dolphinscheduler安装目录下的其它模块mysql的驱动正常是8.0.16,那就不用去处理,否则需要像2,3步骤一样执行
-
最后,重启dolphinscheduler,然后再创建MySQL数据中心
3.11.3 Hive数据源准备
-
需要启动Hive中的MetaStore和Hiveserver2服务(hive的安装服务器执行),命令如下:
#启动元数据服务 hive --service metastore & #启动Hiveserver2服务 hive --service hiveserver2 & -
查看启动后的metastore和hiveserver2服务(在hive安装的服务器执行如下命令)
#查看2个服务 [root@qianfeng01 dolphinscheduler]# jps 8736 RunJar 8869 RunJar #过滤出某个指定的服务 [root@qianfeng01 dolphinscheduler]# ps -ef | grep hiveserver2 [root@qianfeng01 dolphinscheduler]# ps -ef | grep metastore -
检测metastore服务(在hive安装的服务器执行如下命令)
[root@qianfeng01 dolphinscheduler]# netstat -nltcp | grep 9083 -
检车Hiveserver2的服务(在hive安装的服务器执行如下命令)
[root@qianfeng01 dolphinscheduler]# /usr/local/hive-3.1.2/bin/beeline beeline> !connect jdbc:hive2://qianfeng01:10000 Connecting to jdbc:hive2://qianfeng01:10000 Enter username for jdbc:hive2://qianfeng01:10000: root #操作系统中登录用户名和密码 Enter password for jdbc:hive2://qianfeng01:10000: ****** Connected to: Apache Hive (version 3.1.2) Driver: Hive JDBC (version 3.1.2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://qianfeng01:10000> show databases;
3.11.4 Hiveserver2连接错误
通常是在使用hiveserver2或者dolphinscheduler连接hive(hiveserver2服务)的时候会报错如下:
2023-04-09 00:05:47,328 WARN [main] jdbc.HiveConnection (HiveConnection.java:(237)) - Failed to connect to qianfeng01:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://qianfeng01:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate root (state=08S01,code=0)
解决办法:
- 配置hadoop安装目录下的etc/hadoop/core-site.xml文件(每台安装hadoop的服务器都需要配置),追加如下内容:
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
注意:这里登陆的是root用户。若登录的是hadoop用户,则配置文件中的root需要修改为hadoop
当上述文件配置不正确时会可能会引起beeline连接Hive时报如下异常
User: hadoop is not allowed to impersonate root), serverProtocolVersion:null) (state=08S01,code=0)
先部署安装使用的是hadoop用户,故而需要修改core-site.xml配置文件
- 将Hadoop停止,并重启集群
- 停止hive的metastore和hiveserver2服务,并重启
- 再次使用hive的beeline工具连接即可
3.11.5 Hive数据源连接

上图连接方式和MySQL大致一样即可,提交之后的效果如下:

3.11.6 Spark的数据源
…暂时不做,大家自己集成即可。
3.12 任务类型
3.12.1 Shell类型
…上面说过,参考3.5即可。
3.12.2 SQL类型

保存工作流:
运行工作流:
上线运行:
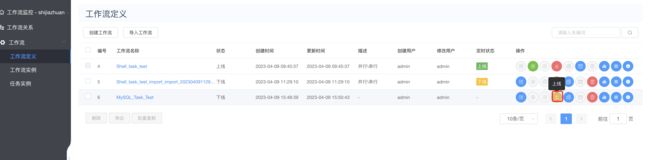
运行:
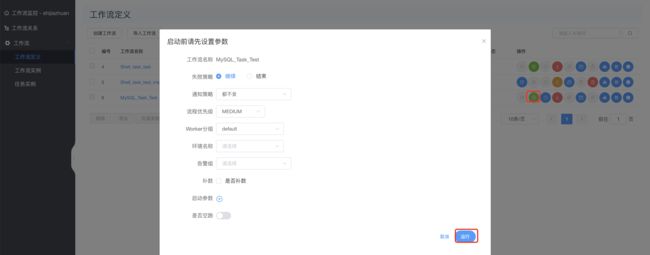
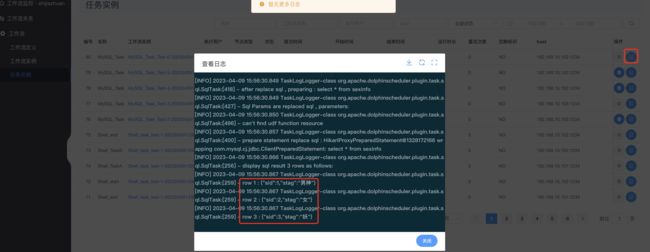
查看结果:
3.12.3 Hive任务类型
该版本Hive仍然使用SQL类型的任务去创建工作流,具体工作流创建如下:

保存工作流:

上线并执行:
去Hive验证结果:

到此为止Hive任务类型完成。
3.12.4 Python类型
创建python类型的工作流:
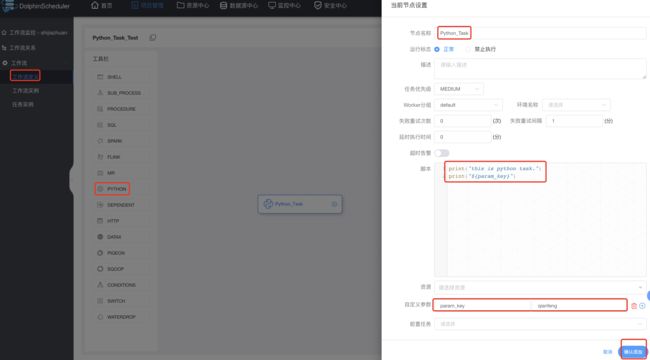
保存工作流:
上线运行:
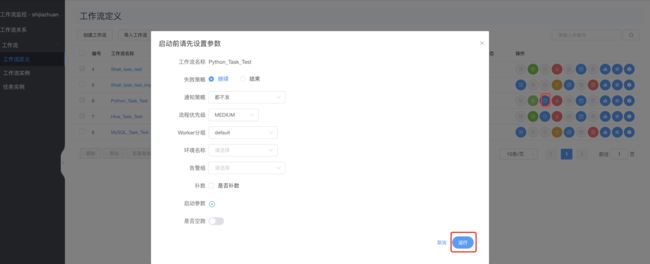
查看运行结果:
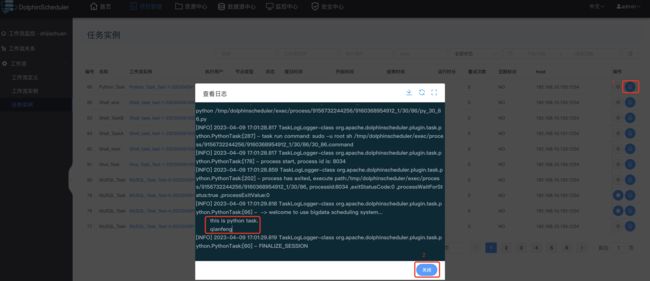
3.13 参数
-
内置参数:系统自带的参数的属性
-
全局参数:工作流中的每一个task都可以用
-
本地参数:当前Task可以使用
-
参数传递:某一个任务接收参数往下一个task传递
3.13.1 内置参数
| 变量名 | 声明方式 | 含义 |
|---|---|---|
| system.biz.date | ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd |
| system.biz.curdate | ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd |
| system.datetime | ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss |
3.13.2 衍生内置参数
-
支持代码中自定义变量名,声明方式:${变量名}。可以是引用 “系统参数”
-
我们定义这种基准变量为 [ . . . ] 格式的, [...] 格式的, [...]格式的,[yyyyMMddHHmmss] 是可以任意分解组合的,比如:$[yyyyMMdd], $[HHmmss], $[yyyy-MM-dd] 等
-
也可以通过以下两种方式:
1.使用add_months()函数,该函数用于加减月份, 第一个入口参数为[yyyyMMdd],表示返回时间的格式 第二个入口参数为月份偏移量,表示加减多少个月
-
后 N 年:$[add_months(yyyyMMdd,12*N)]
-
前 N 年:$[add_months(yyyyMMdd,-12*N)]
-
后 N 月:$[add_months(yyyyMMdd,N)]
-
前 N 月:$[add_months(yyyyMMdd,-N)]
2.直接加减数字 在自定义格式后直接“+/-”数字
- 后 N 周:$[yyyyMMdd+7*N]
- 前 N 周:$[yyyyMMdd-7*N]
- 后 N 天:$[yyyyMMdd+N]
- 前 N 天:$[yyyyMMdd-N]
- 后 N 小时:$[HHmmss+N/24]
- 前 N 小时:$[HHmmss-N/24]
- 后 N 分钟:$[HHmmss+N/24/60]
- 前 N 分钟:$[HHmmss-N/24/60]
-
3.13.3 本地和全局参数
创建带有全局和本地参数的工作流。
创建有本地和全局参数的task:
创建只有全局参数的task:
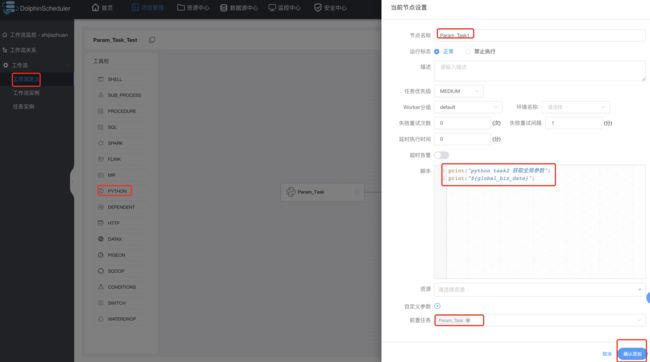
保存工作流:
上线工作流并运行:

查看结果:
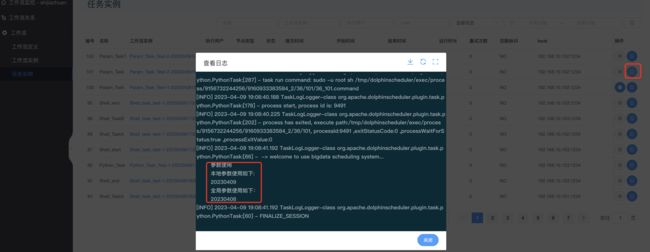
另外一个的全局参数自己查看即可。
3.13.4 参数优先级
DolphinScheduler 中所涉及的参数值的定义可能来自三种类型:
- 全局参数:在工作流保存页面定义时定义的变量
- 上游任务传递的参数:上游任务传递过来的参数
- 本地参数:节点的自有变量,用户在“自定义参数”定义的变量,并且用户可以在工作流定义时定义该部分变量的值
因为参数的值存在多个来源,当参数名相同时,就需要会存在参数优先级的问题。
DolphinScheduler 参数的优先级从高到低为:全局参数 > 上游任务传递的参数 > 本地参数
3.14 告警
- 企业微信
- 钉钉
3.14.1 钉钉告警准备
-
建立钉钉群聊
-自己建立
-
对群聊进行设置
-
选择机器人->添加机器人—>自定义—>如下图:
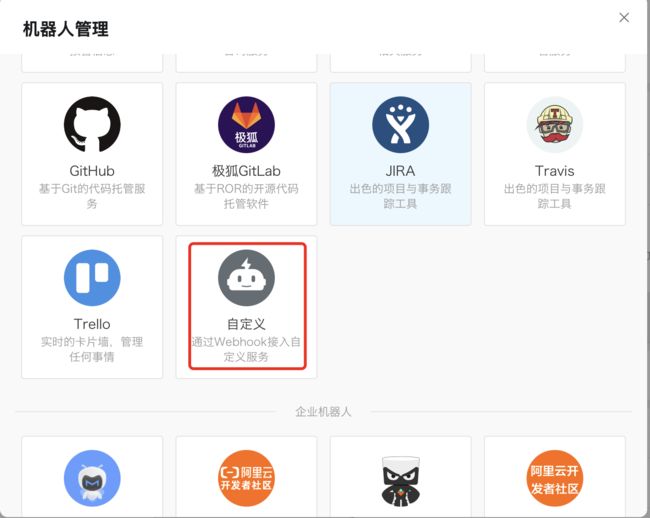
配置机器人:

复制webhook即可:

3.14.2 钉钉告警
创建dingTalk实例:
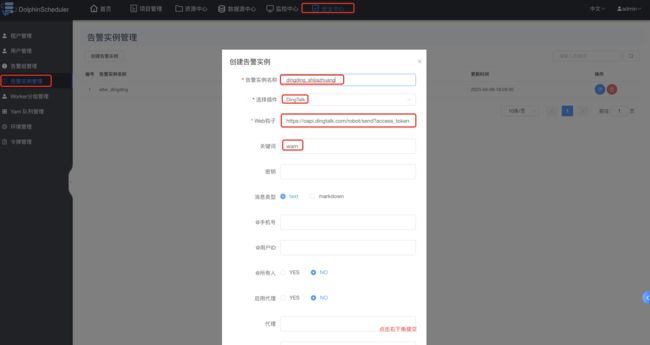
创建告警组:

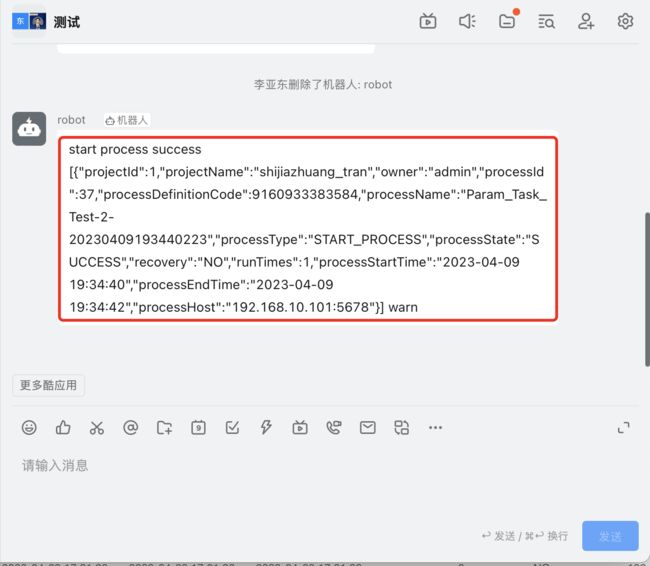
工作流上线运行并配置告警组:

查看钉钉群聊中,是否有任务执行信息: