机器学习——KNN算法
【说明】文章内容来自《机器学习——基于sklearn》,用于学习记录。若有争议联系删除。
1、简介
KNN(K-Nearest Neighbor, K 近邻)算法是最简单的分类算法之一,它也是最常用的分类算法之一。KNN算法是在1968年由Cover和Hart提出的,是一个有监督机器学习算法。KNN算法的原理是:确定某一个数据的分类时,计算相邻的K个数据的类别,根据这K个数据中多数样本的类别来判断某一个数据的类别。
1.1 算法实现
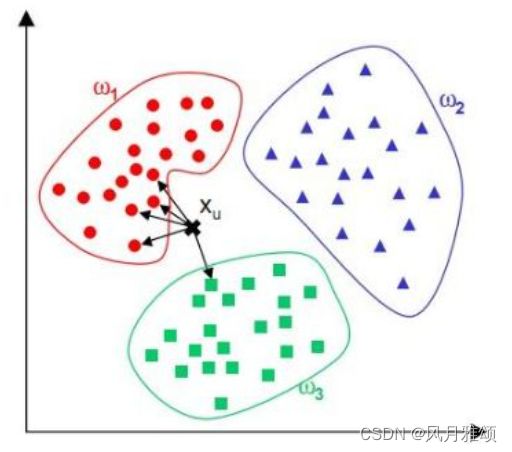
已知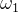 、
、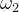 、
、![]() 分别代表训练集中的3个类别,K值为5,预测
分别代表训练集中的3个类别,K值为5,预测![]() 属于那个类别:
属于那个类别:
步骤:
步骤1:算距离。
计算待分类样本 ![]() 与已分类样本的距离。
与已分类样本的距离。
步骤2:找邻居
圈定与待分类样本距离最近的5个已分类样本,作为待分类样本的近邻。
步骤3:做分类。
根据5个近邻中的多数样本所属的类别来决定待分类样本的类别,将![]() 的类别预测为。
的类别预测为。
1.2 算法优缺点
KNN 算法具有如下主要优点:
- 理论成熟,思想简单,可解决分类与回归问题.
- 准确性高,对异常值和噪声有较高的容忍度。
KNN 算法具有如下缺点:
- 由于该算法只计算最近的邻居样本,当样本数据分布不平衡时,会导致结果差距较大,因此,该算法往往引入权值方法(和该样本距离小的邻居样本权值大)来改进。
- 计算量较大,针对每一个待分类的文本,都要计算它到已知样本的距离,才能确定k个最近邻。常用的解决方法是事先去除对分类作用不大的样本点。
1.3 示例
import matplotlib.pyplot as plt
plt.plot([9,9.2,9.6,9.2,6.7,7,7.6],[9.0,9.2,9.2,9.2,7.1,7.4,7.5], 'yx')
plt.plot([7.2,7.3,7.2,7.3,7.2,7.3,7.3],[10.3,10.5,9.2,10.2,9.7,10.1,10.1], 'b.')
plt.plot([7],[9],'r^')
circle1 = plt.Circle((7,9),1.2,color = 'g')
plt.gcf().gca().add_artist(circle1)
plt.axis([6,11,6,11])
plt.ylabel('H/cm')
plt.xlabel('W/cm')
plt.legend(('Orange','lemon'), loc = 'upper right')
plt.show()【运行结果及分析】

【结果分析】
已知两类物体分别为lemon(点)和orange(×),现对未知物体进行分类。取k值为3,计算
与未知物体最近的3个点,查找范围为椭圆形。由于椭圆形内有3个lemon,所以未知物体归为lemon。
2、三要素
KNN 算法的三要素是k值选择、距离度量和分类决策规则。
2.1 k 值选择
k值选择分为如下两种情况:
- k值选择较小,就相当于用较小的训练领域进行预测,学习的近似误差较小,预测结果与近邻的实例点关系非常敏感,容易发生过拟合。
- k值选择较大,近似误差就会增大,对于距离比较远的点就起不到预测作用,容易受样本不平衡的影响,可能造成欠拟合。
2.2 距离度量
特征对于距离度量的影响很大。样本特征要进行归一化处理。计算距离可以使用欧几里得距离或曼哈顿距离等。欧几里得距离的数学表达式如下:![]()
曼哈顿距离的数学表达式如下:
![]()
2.3 分类决策规则
KNN 算法的决策规则是多数表决法,即少数服从多数,由输人实例的k个近邻的训练实例中的多数类决定输入实例的类。这样的决策规则存在一个问题,假设已知A、B属于一类,C、D、E属于另一类,现将A作为实例输入KNN模型进行测试,值设为4,A、B的距离很小,而A与C.、、E距离很大,但是由于分类决策规则是多数表决法,所以最终将A判断为与C、D、E一类,与假设不符。由此可以看出,多数表决法不合理。解决这一问题的方法是对距离进行加权,在k个实例中,B对最终的决策会产生较大影响,应赋于较大权值;距离越远,影响力越小,权值也越小。
3、分类问题
3.1 分类问题简介
分类预测一般采用选择多数表决法,即训练集和预测的样本特征最近的K个样本。
Sklearn提供了KneighborsClassifier解决分类问题,如下所示:
KNeighborsClassifier( n_neighbors, weights, algorithm, leaf_size, p)【参数说明】
- n_neighbors:k值。
- weights:指定权重类型。默认值weights = 'uniform'表示为每个近邻分配统一的权重;weights='distance'表示分配的权重与查询点的距离成反比。
- algorithm:指定计算最近邻的算法,'auto':自动决定最合适的算法;'ball_tree':BallTree算法;'kd_tree':KDTree算法;'brute':暴力搜索。
- leaf_size:指定BallTree/KDTree叶节点规模,会影响树的构建和查询速度
- P:p= 1为曼哈顿距离;p=2为欧几里德距离。
3.2 示例1
from sklearn.datasets import make_blobs
centers = [[-2,2],[2,2],[0,4]]
x,y = make_blobs(n_samples = 60,centers = centers, random_state = 0, cluster_std = 0.60)
#画出数据
import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize = (6,4), dpi = 144)
c = np.array(centers)
#画出样本x[:,0]二维数组的第一维数据
plt.scatter(x[:,0],x[:,1], c = y, s = 100, cmap = 'cool')
#画出中心点
plt.scatter(c[:,0],c[:,1], s = 100, marker = '^', c = 'orange')
plt.savefig('knn_centers.png')
plt.show()
#训练模型
from sklearn.neighbors import KNeighborsClassifier
k = 5
clf = KNeighborsClassifier(n_neighbors = k)
clf.fit(x,y)
#进行预测
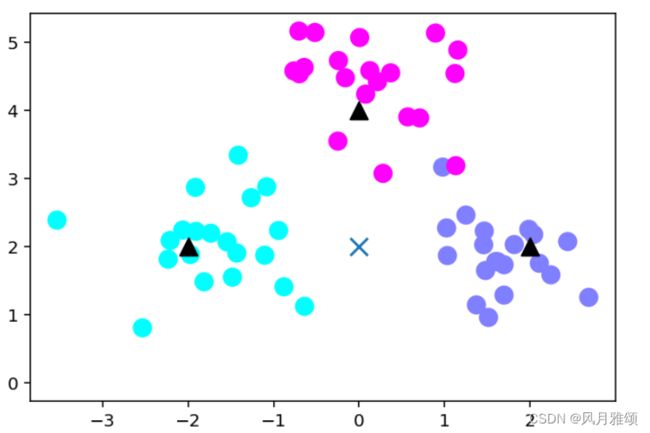
x_sample = np.array([[0,2]])
y_sample = clf.predict(x_sample)
neighbors = clf.kneighbors(x_sample, return_distance = False)
#画出示意图
plt.figure(figsize = (6,4), dpi = 144)
c = np.array(centers)
plt.scatter(x[:,0],x[:,1], c = y, s = 100, cmap = 'cool')
plt.scatter(c[:,0],c[:,1], s = 100, marker = '^', c = 'k')
plt.scatter(x_sample[0][0], x_sample[0][1], marker = 'x', s = 100, cmap = 'cool')
for i in neighbors[0]:
#预测点与距离最近的5个样本连线
plt.plot(x[i][0], x_sample[0][0], [x[i][1]], x_sample[0][1], 'k--', linewidth = 0.6)
plt.savefig('knn_predict.png')
plt.show()【运行结果】

3.3 示例2
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
#生成样本数200,分类数为2的数据集
data = make_blobs(n_samples = 200, n_features = 2, centers = 2, cluster_std = 1.0,
random_state = 8)
x, y = data
#s数据集可视化
clf = KNeighborsClassifier()
clf.fit(x,y)
#绘制图形
x_min, x_max = x[:,0].min() - 1, x[:,0].max() + 1
y_min, y_max = x[:,1].min() - 1, x[:,1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
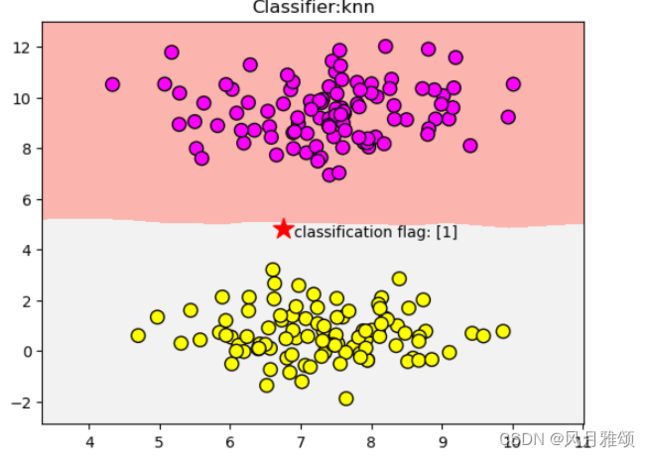
plt.pcolormesh(xx, yy, z, cmap = plt.cm.Pastel1)
plt.scatter(x[:,0],x[:,1], s= 80, c = y, cmap = plt.cm.spring, edgecolors = 'k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('Classifier:knn')
plt.scatter(6.75, 4.82, marker = '*', c = 'red', s = 200)
res = clf.predict([[6.75, 4.82]])
plt.text(6.9, 4.5, 'classification flag: '+ str(res))
plt.show()【运行结果】
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
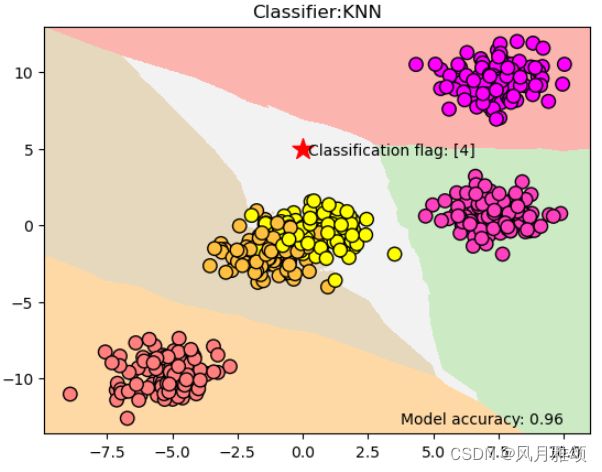
data = make_blobs(n_samples = 500, n_features = 2, centers = 5, cluster_std = 1.0, random_state = 8)
x,y = data
clf = KNeighborsClassifier()
clf.fit(x,y)
#绘制图形
x_min, x_max = x[:,0].min() -1, x[:,0].max() + 1
y_min, y_max = x[:,1].min() -1, x[:,1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
z = clf.predict(np.c_[xx.ravel(), yy.ravel()])#将xx变成一维数组
z = z.reshape(xx.shape)
plt.pcolormesh(xx, yy, z, cmap = plt.cm.Pastel1)
plt.scatter(x[:,0],x[:,1], s= 80, c = y, cmap = plt.cm.spring, edgecolors = 'k')
plt.xlim(xx.min(), xx.max())#x轴y轴的数值显示范围,参数分别为最大值和最小值
plt.ylim(yy.min(), yy.max())
plt.title('Classifier:KNN')
plt.scatter(0, 5, marker = '*', c = 'red', s = 200)
res = clf.predict([[0,5]])
plt.text(0.2, 4.6, 'Classification flag: '+ str(res))
plt.text(3.75, -13, 'Model accuracy: {:.2f}'.format(clf.score(x,y)))
plt.show()【运行结果】