模型微调入门介绍一
备注:模型微调系列的博客部分内容来源于极客时间大模型微调训练营素材,撰写模型微调一系列博客,主要是期望把训练营的内容内化成自己的知识,我自己写的这一系列博客除了采纳部分训练营的内容外,还会扩展细化某些具体细节知识点。
模型微调大致会有下面5大步骤,其中数据下载主要用transformers库中的datasets来完成,数据预处理部分会用到tokenizer对象。本篇博客会重点介绍数据加载和数据预处理部分,剩余的三个步骤会通过一个简单的例子来简要介绍,后面会有专门的博客来介绍超参数如何设置和结果评估等内容。
![]()
数据下载
datasets 是由 Hugging Face 提供的一个 Python 库,用于访问和使用大量自然语言处理(NLP)数据集。该库旨在使研究人员和开发人员能够轻松地获取、处理和使用各种 NLP 数据集,从而促进自然语言处理模型的研究和开发。datasets提供的常用function如下图所示:
load_dataset(name, split=None):用于加载指定名称的数据集。可以通过 split 参数指定加载数据集的特定拆分(如 "train"、"validation"、"test" 等)。
list_datasets():列出所有可用的数据集名称。
load_metric(name):加载指定名称的评估指标,用于评估模型性能,后面会有专门的一篇博客进行介绍。
load_from_disk(path) 和 save_to_disk(path, data):用于从磁盘加载数据集或将数据集保存到磁盘。
shuffle(seed=None):用于对数据集进行随机洗牌。可以通过 seed 参数指定随机数生成器的种子。
train_test_split(test_size=0.2, seed=None):用于将数据集拆分为训练集和测试集。
数据预处理
清洗数据
在进行数据预处理的时候,通常需要分析是否需要进行数据清洗。例如,如果原始数据中存在一些特殊符号需要进行清理,通常会自定义清理方法对原始数据进行清洗。具体demo code如下图所示,具体的clean_text方法需要结合具体的数据进行自定义。
import re
import string
def clean_text(text):
# 将文本转换为小写
text = text.lower()
# 去除标点符号
text = text.translate(str.maketrans("", "", string.punctuation))
# 去除数字
text = re.sub(r'\d+', '', text)
# 去除多余的空格
text = re.sub(r'\s+', ' ', text).strip()
# 处理缩写词,这里只是一个简单的示例
text = re.sub(r"won't", "will not", text)
text = re.sub(r"can't", "can not", text)
# 添加更多的缩写词处理..
return text
# 示例文本
raw_text = "Hello, how are you? This is an example text with some numbers like 123 and punctuations!!!"
# 进行文本清理
cleaned_text = clean_text(raw_text)
# 输出结果
print("Original Text:")
print(raw_text)
print("\nCleaned Text:")
print(cleaned_text)Tokenzier进行数据预处理
除了数据清洗,在做数据预处理的时候,通常会调用tokenizer的方法进行填充、截断等预处理,那么tokenizer具体提供了哪些参数呢?初始化tokenizer对象时,主要有以下参数:
max_length:控制分词后的最大序列长度。文本将被截断或填充以适应这个长度。
truncation:控制是否对文本进行截断,以适应 max_length。可以设置为 True(默认)或 False。
padding:控制是否对文本进行填充,以适应 max_length。
return_tensors:控制返回的结果是否应该是 PyTorch 或 TensorFlow 张量。可以设置为 'pt'、'tf' 或 None(默认)。
add_special_tokens:控制是否添加特殊令牌,如 [CLS]、[SEP] 或 [MASK]。可以设置为 True(默认)或 False。
is_split_into_words:控制输入文本是否已经是分好词的形式。如果设置为 True,分词器将跳过分词步骤。可以设置为 False 或 True(默认)。
return_attention_mask:控制是否返回 attention mask,指示模型在输入序列中哪些标记是有效的。可以设置为 True 或 False(默认)。
return_offsets_mapping:控制是否返回标记的偏移映射,即每个标记在原始文本中的起始和结束位置。可以设置为 True 或 False(默认)。
return_token_type_ids:控制是否返回用于区分文本段的 token type ids。可以设置为 True 或 False(默认)
以下面的demo code为例,当设置padding=“max_length”后,如果内容长度低于10,会对内容进行自动填充。tokenizer对象返回一个字典类型,包含inputs_ids,token_type_ids,attention_mask。其中inputs_ids是真正的对输入文本的编码,attention_mask用于标记哪些是真正的输入文本转换的内容,哪些是填充内容,标记为0的即为填充内容。

除了上面的字段外,还可以设置是否返回tensor,是否添加特殊标记等。以下面的例子为例,在encode中添加了特殊标记,设置了返回张量,则返回的内容是tensor张量。
from transformers import BertTokenizer
# 初始化 BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# 定义文本
text = "Hello, how are you? I hope everything is going well."
# 使用 tokenizer.tokenize 进行分词
tokens = tokenizer.tokenize(text)
print("Tokens after tokenization:", tokens)
# 使用 tokenizer.encode 将文本编码成模型输入的标识符序列
input_ids = tokenizer.encode(text, max_length=15, truncation=True, padding="max_length", add_special_tokens=True)
print("Input IDs after encoding:", input_ids)
# 使用 tokenizer.decode 将模型输出的标识符序列解码为文本
decoded_text = tokenizer.decode(input_ids)
print("Decoded text:", decoded_text)
# 使用 tokenizer.encode_plus 获取详细的编码结果,包括 attention mask 和 token type ids
encoding_result = tokenizer.encode_plus(text, max_length=15, truncation=True, padding="max_length", add_special_tokens=True, return_tensors="pt")
print("Detailed encoding result:", encoding_result) 打印出来的结果如下图所示:
在上面调用tokenizer的方法时,有直接调用encode,有调用encode_plus,还有直接初始化tokenizer对象,那么他们之间有什么区别么?
encode与encode_plus的区别
encode方法:该方法用于将输入文本编码转换为模型输入的整数序列(input IDs)。它只返回输入文本的编码结果。
使用场景: 适用于单一文本序列的编码,例如一个问题或一段文本。
encode_plus方法:该方法除了生成整数序列(input IDs)外,还会生成注意力掩码(attention mask)、段落标记(segment IDs)等其他有用的信息,通常用于训练和评估中。返回一个字典,包含编码后的各种信息。
使用场景: 适用于处理多个文本序列,例如一个问题和一个上下文文本。
encode_plus与直接调用tokenizer对象本质上无区别:在 Hugging Face Transformers 库中,直接调用 tokenizer 对象和调用 tokenizer.encode 方法的本质是相同的,都是为了将文本转换为模型可接受的输入标识符序列。这两种方式实际上等效,都是通过 tokenizer 对象的编码方法完成的。
数据处理的具体例子
在数据预处理过程中,不同的数据类型预处理的步骤不同,以huggingface中的squad数据集和yelp_review_full数据集为例,squad是从上下文context中寻找question的答案。yelp_review_full数据集是对一系列评论以及评论的分数数据。squad用于训练问答系统模型,yelp_review_full用于训练文本分类、情感分类模型。
squad数据集
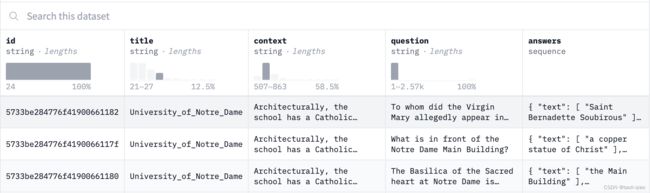 yelp_review_full数据集
yelp_review_full数据集
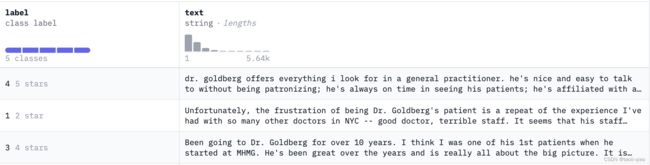
下面以yelp_review_full为例子,看看如何完成数据预处理与模型微调训练。下面的代码是加载yelp_review_full的数据完成模型的微调。在数据预处理部分,调用tokenizer对象,将truncation设置为true,以及设置了padding="max_length".没有复杂的预处理过程。
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
from datasets import load_dataset, load_metric
import evaluate
# 1. 加载YelpReviewFull数据集
dataset = load_dataset("yelp_review_full")
# 2. 选择并加载BERT模型和标记器
model_name = "bert-base-uncased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5) # num_labels=5表示5种分类任务
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 3. 对原始数据进行标记化
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 4. 定义训练参数
training_args = TrainingArguments(
output_dir="./yelp_review_model", # 保存微调模型的目录
per_device_train_batch_size=8, # 每个设备的训练批次大小
evaluation_strategy="steps", # 在每个 steps 后进行评估
eval_steps=500, # 每 500 个 steps 进行一次评估
save_steps=500, # 每 500 个 steps 保存一次模型
num_train_epochs=3, # 微调的轮数
logging_dir="./logs" # 保存训练日志的目录
)
# 5. 定义compute_metrics函数计算准确度
metric = evaluate.load("accuracy")
def compute_metrics(p):
preds = p.predictions.argmax(axis=1)
return metric.compute(predictions=preds, references=p.label_ids)
small_train_data=tokenized_datasets["train"].shuffle(seed=42).select(range(5000))
small_test_data=tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# 6. 定义Trainer对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_data,
eval_dataset=small_test_data,
# train_dataset=tokenized_datasets["train"],
# eval_dataset=tokenized_datasets["test"],
compute_metrics=compute_metrics, # 使用定义的compute_metrics函数
)
# 7. 微调BERT模型
trainer.train()
# 8. 输出评估结果
results = trainer.evaluate()
print("Results:", results)因为只选取了部分数据进行训练,正确率是0.632.训练结果如下图所示:

对于用于训练问答系统模型的squad数据,预处理步骤会多一些,所以会在下一篇博客中做专门的介绍。