金融大数据应用-企业信贷风险防控模型竞赛开始-中国建设银行数据集-作者开箱测评
各位朋友,最新金融风控模型竞赛开始了!竞赛名称为金融大数据应用:企业信贷风险防控;组织单位:数字中国建设峰会组委会;中国建设银行提供模型竞赛数据集。
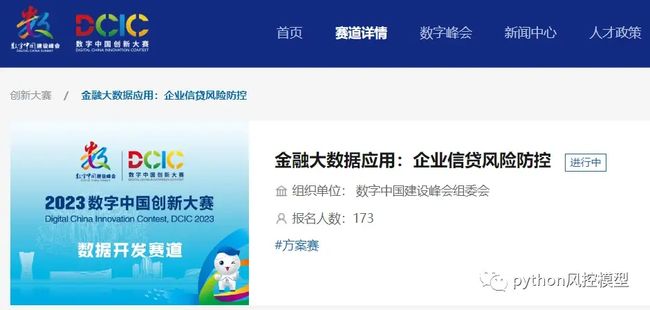

这次模型竞赛奖金很高,总奖金160万元,一等奖八万元。
赛题背景:
金融机构的数字化转型正在如火如荼地进行,人工智能作为数字化转型的重要手段之一,全方位融合赋能金融行业的业务领域和场景应用。目前人工智能技术在金融产品设计、市场营销、风险控制、客户服务和其他支持性活动等金融行业五大业务链环节均有渗透,特别是以生物特征识别、机器学习、计算机视觉、知识图谱等技术赋能下的金融行业,已经衍生出智能营销、智能身份识别、智能客服等多个金融人工智能典型场景。

赛题任务
1.将金融数据与政务数据相结合,可自备行业数据丰富模型维度。从需求分析、场景设计、解决方案、落地验证、产品价值多个方面开展创意设计,提交创意解决方案。
2.企业信贷风险防控方案。结合企业数据与公共数据,建立企业信贷风险分析模型。场景方向可从准入管理、预警监控、信贷调整、贷后管理等方面,对企业各方面的风险进行评估,结合模型及业务场景设计完整的风险防控方案,提升银行信贷风险防控能力。
参赛规则
▶▶ 参赛人群:大赛面向社会各界开放,不限年龄国籍、高校、科研院所、企业从业人员均可登录官网报名参赛。参与大赛组织工作有关单位员工可参赛但不可获奖;
▶▶ 报名要求:每道赛题每人仅能参加一支团队(1-5人),可同时选择多道赛题进行参赛,不同赛题可以拥有不同的团队,报名时所有成员需提供个人基本信息,并通过实名认证;需在组队截止日期前完成组队,一旦组队不可退出队伍。组队条件:各成员提交总次数≤开赛天数*3,且一个团队至少有一名中国籍选手;更多参赛规则可访问官网主页。
数据说明
这次Toby老师也下载了模型竞赛数据,观察这次数据集的变量是公开透明的。这意味着此次模型竞赛非常有意义,我们能通过数据挖掘和建模方法找出有价值变量和业务意义。
下图是中国建设银行提供数据集,共47个变量,12万客户数据,数据量还算比较大。
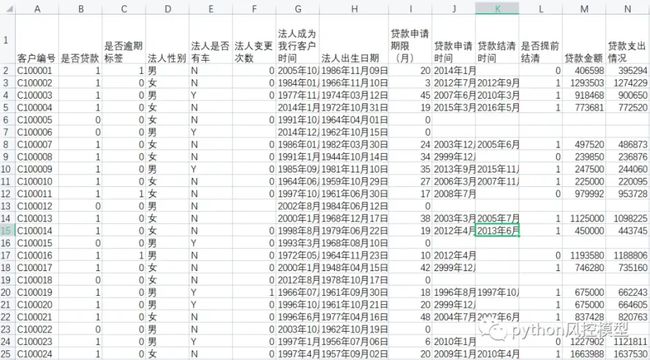
企业信贷风险防控数据主要包括企业工商信息、法人基本信息、公积金缴交等金融数据与政务数据(均为模拟数据),数据字典已包含。其中训练集与测试集可由选手根据方案实际情况自行划分,选手也可自备数据丰富方案维度。
提交要求
参赛者须在初赛阶段提供解决方案设计说明书(PPT、WORD或PDF格式)和成果模型。内容需包括但不限于:
背景分析 —— 具有现实意义、面向金融业实际面对的问题,结合具体情况,分析业务现状、当前痛点、难点;
实施方案 —— 基于背景分析,设计数字化场景,提出可解决问题、降低金融风险、提升客户体验的创新思路实施方案;
数据分析 —— 对数据的选取、使用过程进行分析,包括数据清洗过程、字段筛选、重要性分析等;
算法分析 —— 对建模使用的具体算法进行分析介绍,包括算法选择原因、调参过程等进行分析说明;
作品价值 —— 体现作品的实际落地价值,通过可度量的指标进行体现。
提交示例
解决方案设计说明书可以是PPT、WORD或PDF格式,文件名以“赛题名称+团队名称+方案名称”为准。
如有影音、数据、模型等文件,请打包在同一个文件夹压缩后进行提交。
评测标准
大赛主办方组建大赛专家评审团负责比赛评审工作。
大赛专家评审团根据各指标比例及对应参考描述,以百分制方式,对参赛者作品进行打分。评审标准暂拟如下,仅供参考,根据大赛实际组织情况调整,以实际评审标准为准。
评分维度作品成熟度技术水准应用潜力答辩表现占比40%30%20%10%
● 作品成熟度(40%)
(1)需求分析(10%):具有较强社会意义、金融行业实际需求的问题,基于对数据的处理分析,结合真实情况,有效把握需求痛点、难点、堵点;
(2)场景设计(10%):基于需求分析,设计数字化场景,提出可解决问题、减少社会成本、提高效益的创新思路;
(3)解决方案(10%):基于赛题场景设计,提出符合金融需求的可落地解决方案,形成较完善的分析报告或综合方案;
(4)数据使用(10%):对于系统构建所需数据有较清晰的数据清单,其中或包括数据类别、数据格式、数据功能、数据来源等信息,并对数据使用流程做出较清晰规划。
● 技术水准(30%)
(1)先进性(5%):有效使用云计算、大数据、人工智能等技术,且技术能力领先市场已有应用,具备技术先进性;
(2)创新性(20%):解决问题的思路、方案具有较强的创新性,与传统方法有明显的区别与升级;
(3)成熟度(5%):方案深入行业需求,能够有效解决行业痛点问题,并针对未来实施过程中可能遇到的风险问题做出预测,并提出相应预案。
● 应用潜力(20%)
(1)实用性(5%):作品方案符合实际使用场景需求,可落地应用,解决真实业务难题;
(2)普适性(5%):作品方案具有较强的普适性,可适用于多种场景,解决多类问题;
(3)社会效益(5%):作品方案实际应用后,可产生较大社会效益,切实助力惠民、兴业、优政;
(4)商业价值(5%):作品方案可高效率、低费用应用,具有较强的商业价值、推广潜力。
● 答辩表现(10%)
答辩时仪态得体,语言表达逻辑清晰,合理解答专家疑问,展现了较为丰富的经验和专业的能力。
Toby老师指出这次模型竞赛非常open,不是之前以单个指标(accuracy/AUC/F1 score)来排名,而是对参赛者多个方面考察。之前我写的文章《四川省大学生金融科技建模大赛-模型复现和点评》提出过主办方改进建议,如下图。

貌似主办方看过这篇文章,这次项目的确弥补了之前缺点,堪称经典。这次比赛非常经典,建议大家都去参与,提高自己建模能力。
开箱测试
Toby老师下载数据后开箱测试,先绘制变量直方图和相关性热图,投石问路。
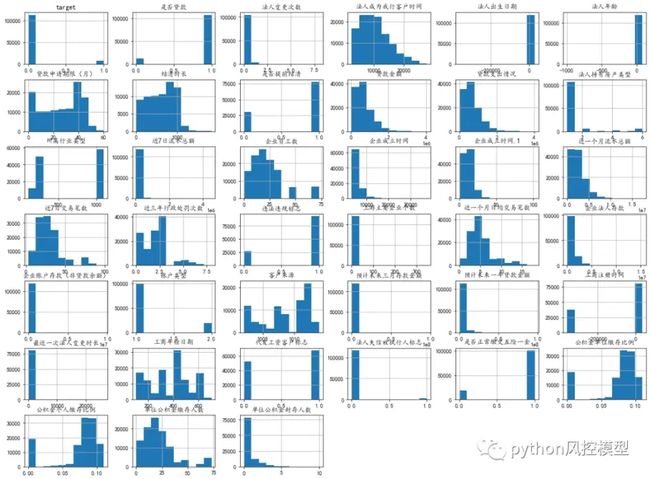
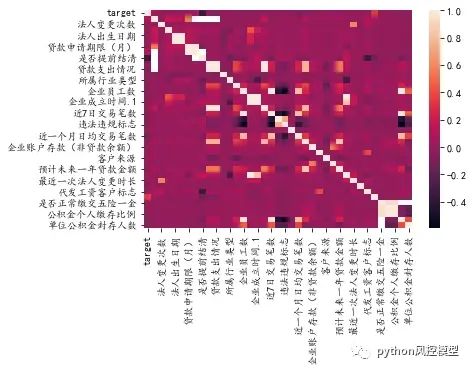
Toby老师建议大家不要急着建模,先观察数据分布特征,这类似进攻前的情报收集工作。
Toby老师通过描述性统计,发现这数据集需要大量预处理工作,对初学者有一定难度。例如时间变量比较多,可以做衍生变量。

此数据集夹杂着错误数据,如果参赛者没有自动化检测工具,很难发现里面埋的坑。例如贷款申请时间里有2999年数据,法人出生日期有3019年数据,这是什么东东?

脏数据意味着中国建设银行复杂数据库员工工作不仔细,或者故意输入几个错误数据。脏数据很正常,因为数据量太大了,我们经常遇到。
Toby老师初次建模观察,模型性能解决完美。如果是经验不足选手,估计已经高兴地晕过去。对于我们来说,模型质量好的可疑,我们要去仔细检查变量业务意义。

果不其然,变量存在数据泄露风险。至于什么是数据泄露,请大家阅读之前我写的文章《数据泄露-揭秘机器学习模型如何作弊》。
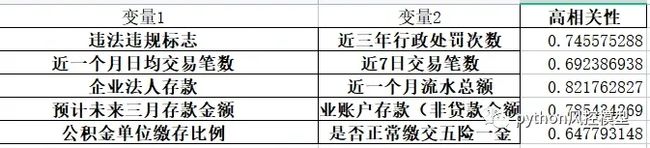
Toby老师通过多轮变量筛选,删除疑似数据泄露变量后,最后用34个变量建模,模型性能非常棒。通过建模,我发现数据集存在多个强变量。中国建设银行拥有这些强变量,风控能力会非常不错。

Toby老师入模的34个变量中,高相关性变量已经非常少。如果更严格一些,这34个变量还可以继续筛选。此模型用10-20个变量,足以发挥优秀性能。
如下图,模型AUC为0.98,当然我可以做的更高,这属于前几轮测试数据,模型调参等提高模型性能方法还没用。

有的变量重要性比较低,但业务意义比较重要,我还是建议保留,继续收集更多数据后观察实验。我们建模不能只看统计结果,还要尊重业务意义。数据建模和业务意义类似于太极的阴和阳,两者缺一不可,互相平衡方能发挥最好效果。

总结
金融大数据应用-企业信贷风险防控模型竞赛是一次非常棒的比赛!鼓励大家多去参与。如果大家想学习风控建模方法和代码,可关注Toby老师自研课程《python金融风控评分卡模型和数据分析》。教程包含逻辑回归,集成树,神经网络等常见算法介绍和代码,有大量实战案例,模型性能优越,适用于论文,作业,专利,模型竞赛,企业模型。欢迎大家收藏,以备工作和学习使用。
如果有模型竞赛定制需求朋友,可给博主留言。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。