【hive】hive的调优经验
一、hive自己进行优化
对union这样的命令进行了优化
二、数据本地化率
hdfs数据本地化率对hive性能产生影响
在数据大小一定的情况下,500个128M的文件和2个30G的文件 跑hive任务,性能是有差异的,两者最大的区别在于,后者在读取文件时,需要跨网络传输,而前者为本地读写。数据本地化率问题。
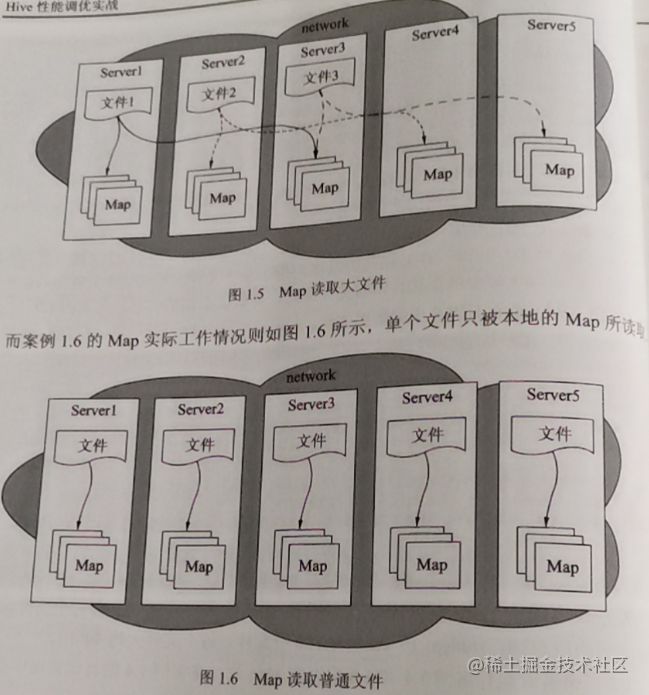
三、数据格式
hive提供text,sequenceFile,RCFile,ORC,Parquest等格式。
- sequenceFile是一个二进制key/value对结构的平面文件,广泛应用于MapReduce中。
- Parquet时一种列式存储格式,兼容多种数据引擎,MapReduce和Spark。
- ORC时对RCFile的一种优化,主流选择之一。
四、分区和分桶
1. 分区表:
总结:分区表的意思,其实想明白了就很简单。就是在系统上建立文件夹,把分类数据放在不同文件夹下面,加快查询速度。
理解分区就是文件夹分而治之,查询的时候可以当作列名来显示查询的范围。
- 关键点1:partitioned by (dt String,country string); 创建表格时,指明了这是一个分区表。将建立双层目录,第一次目录的名字和第二层目录名字规则
PARTITIONED BY子句中定义列,是表中正式的列,成为分区列。但是数据文件中并没有这些值,仅代表目录。
- 关键点2: partition (dt=‘2001-01-01’,country=‘GB’); 上传数据时,把数据分别上传到不同分区中。也就是分别放在不同的子目录下。
2. 动态分区表:
关闭严格分区模式
动态分区模式时是严格模式,也就是至少有一个静态分区。
set hive.exec.dynamic.partition.mode=nonstrict //分区模式,默认nostrict
set hive.exec.dynamic.partition=true //开启动态分区,默认true
set hive.exec.max.dynamic.partitions=1000 //最大动态分区数,默认1000
为什么要使用动态分区呢,我们举个例子,假如中国有50个省,每个省有50个市,每个市都有100个区,那我们都要使用静态分区要使用多久才能搞完。所有我们要使用动态分区。
动态分区默认是没有开启。开启后默认是以严格模式执行的,在这种模式下需要至少一个分区字段是静态的。
这有助于阻止因设计错误导致导致查询差生大量的分区。列如:用户可能错误使用时间戳作为分区表字段。然后导致每秒都对应一个分区!这样我们也可以采用相应的措施:
3. 分桶表:
每一个表或者分区,Hive可以进一步组织成桶。也就是说,桶为细粒度的数据范围划分。
分桶规则:对分桶字段值进行哈希,哈希值除以桶的个数求余,余数决定了该条记录在哪个桶中,也就是余数相同的在一个桶中。分桶不会改变原有表和原有分区目录的组织方式。只是更改了数据在文件中的分布。
优点:1、提高join查询效率 2、提高抽样效率
可以用 desc formatted [表名] 来查看目录组织方式
五、 干预sql的运行方式
- 改写sql,实现对计算引擎执行过程的调优
- 通过sql-hint语法,实现对计算引擎执行过程的干预
- 通过数据库开放的一些配置,实现对计算引擎的干预
具体如下:
1. 使用grouping sets grouping__id rollup cube等代替group by +union all
hive对group by+ union all的写法进行了优化
2.使用 group by 来代替 distinct
在数据没有发生数据倾斜的情况下,采用distinct要比group by要好
默认情况下,distinct会被hive翻译成一个全局唯一reduce任务来做去重操作,因而并行度为1,而且有导致数据倾斜的可能。
而group by则会被hive翻译成分组聚合运算,会有多个reduce任务并行处理,每个reduce对收到的一部分数据组,进行每组聚合(去重)
注意:最新的hive版本中:新增了对count(distinct)的优化,通过配置hive.optimize.countdistinct
即使真的出现数据倾斜也可以自动优化。
3 .使用Hinit
使用mapjoin(b) 括号中指定的是数据量较小的表,表示在map阶段完成a,b两表的连接。
将原来在Reduce中进行的连接操作,前推到了Map阶段。
SELECT /* + MAPJOIN(b) */ a.key,a.value
FROM a
JOIN b ON a.key = b.key;
大表在右边使用streamtable的sql
--STRSEAMTABLE(),括号中指定数据量大的表
--默认情况下,在reduce阶段进行连接,hive把坐标中的数据放在缓存中,右表的数据作为流数据表
SELECT /*+ STREAMTABLE(a) */ a.val,b.val,c.val
FROM a
JOIN b ON (a.key = b.key)
JOIN c ON (c.key = b.key)
普通表的join又被称为 Replartition Join,通常shuflle操作发生在此阶段
也可以通过设置hive.smalltable.filesize or hive.mapjoin.smalltable.filesize
如果大小表在进行连接时,小表连接小于这个默认值,则自动开启Mapjoin优化,
六、配置的一些优化
1. 开启向量化
默认是关闭的,将一个普通的查询转化为向量化查询。大大减少了扫描,过滤等查询,标准查询时系统一次处理一行,矢量化查询可以一次性查询1024行数据,减少了系统上下文切换的开销。
set hive.vectorized.execution.enabled=true;
目前mapreduce只支持map端的向量化,tez和spark可以支持map和reduce端的向量化操作
2. 开启并行化
--开启并行执行
set hive.exec.parallel=true;
3. 开启map端聚合
hive.map.aggr 默认值为true
4.调整mapTask数量
set mapred.map.tasks= task数量
但是这个并不能完全控制mapTask数量,调节task数量需要一套完整的算法。于mapreduce的切片大小有关。
顾名思义就是将数据进行切分,切分为数据片,其实这个切片关乎于map阶段的map个数,以及每个map处理的数据量的大小。
mapreduce中,一个job的map个数, 每个map处理的数据量是如何决定的呢? 另外每个map又是如何读取输入文件的内容呢?
用户是否可以自己决定输入方式, 决定map个数呢?
mapreduce作业会根据输入目录产生多个map任务, 通过多个map任务并行执行来提高作业运行速度,
但如果map数量过少, 并行量低, 作业执行慢, 如果map数过多, 资源有限,也会增加调度开销.
因此, 根据输入产生合理的map数, 为每个map分配合适的数据量, 能有效的提升资源利用率, 并使作业运行速度加快。
1.默认情况下,Map的个数defaultNum =目标文件或数据的总大小 totalSize/hdfs 集群文件块的大小blockSize.
2.当用户指定mapred.map.tasks,即为用户期望的Map大小,用expNum表示,但是这个值并不
会被立即采纳。他会获取mapred.map.tasks与defaultNum的较大值,作为待定选项。
3.获取文件分片的大小和分片个数,分片大小参数为 mapred.min.split.size 和blockSize间的较大值,
用splitMaxSize表示,将目标文件或数据总大小除以splitMaxSize 即为真是分片个数,用realSplitNum表示。
4.获取realSplitNum于expMaxNum 较小值为实际的Map个数。
通过上面的逻辑:
减少Map个数,需要增大mapred.min.split.size的值,减少mapred.map.tasks的值
增大Map个数,需要减少mapred.min.split.size的值,增大mapred.map.tasks的值
在之前的学习的union all案例中,单纯的减少,增大map.tasks的数量,并不能改变map个数,读者可以自行尝试。
5.调整reduce相关配置
mapred.reduce.tasks 默认值为-1,代表有系统根据需要自行决定reducer的数量
6. 设置每个reducer能处理的数据量
hive.exec.reducers.bytes.per.reducer 设置每个reducer处理的处理量,默认256M
7. 表示数据量需要按相同的键再次聚合,可减少重复的聚合操作
hive.optimize.reducededuplication=true;
七、使用explain dependency查看数据输入依赖
explain dependency用于描述一段sql需要的数据来源
explain dependency 有两个使用场景
注意在使用join时,不同的join,如inner join left join中有非等值过滤条件,过滤效果不同。
场景一:快速排除 快速排除因为读取不到相应分区的数据而岛主任务数据输出异常,上游任务因为生产过程中不可控因素出现异常或者空跑,导致下游任务引发异常。
场景二:帮助清理表的输入,特别是有助于理解有多重自查询,多表连接的依赖输入。
案例:
下面有两个sql:
select a.s_no
from student_orc_partition a
inner join student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and b.part<=2;
select a.s_no
from student_orc_partition a
inner join student_orc_partition_only b
on a.s_no=b.s_no and a.part = b.part
where a.part>=1 and b.part<=2;
通过explain dependency,其实上述的两个sql并不等价,在内连接中连接条件中假如非等值的过滤条件后,并没有将内连接的左右两个表按照过滤条件进行过滤,内连接在执行过程中会多读取part=0的分区数据
案例二:
select a.s_no
from student_orc_partition a
leftjoin student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and b.part<=2;
select a.s_no
from student_orc_partition a
leftjoin student_orc_partition_only b
on a.s_no=b.s_no and a.part=b.part and a.part>=1 and a.part<=2;
通过expalin dependency,对于左外连接在连接条件中加入非等值过滤的条件,如果过滤条件是作用于右表(b表)有起到过滤效果,右表只扫描了2个分区,但是左表(a表)会进行全表扫描,
如果过滤条件是针对的是左表,则完全没有起到过滤的作用,那么两个表将会进行全表扫描。
所以通常的优化的是尽早过滤掉不需要的数据。
select a.s_no
from (
select s_no,part from student_orc_partiton
where part>=1 and part<=2
) a
left outer join student_orc_partition_only b
on a.s_no=b.s_no and a.part = b.part;
八、Map join的原理
一般的join 都是Repartition Join,发生在shuffle 和Reduce 阶段,如果不特殊声明,就是Repartition Join。
Map join是先启动一个作业,读取小表的数据,在内存中构建哈希表,将哈希表写入本地磁盘,然后将哈希表上传到HDFS上并添加到分布式缓存中,再启动一个任务读取表B的数据,在进行连接时Map对获取缓存中的数据并存入到哈希表中,B表会与哈希表的数据进行匹配,时间复杂度是O(1),匹配完后将结果进行输出。
一般不建议使用 hinit /*+mapjoin(b) */ 这样的用法,最坏的情况下容易发生内存溢出问题。
可以使用配置来尝试将repartition连接转化为Map连接,hive.smalltable.filesize
桶的Map 连接将普通的Map连接转化为桶连接,分桶的Hive表会将桶列的值计算Hash值取桶数的模,余数相同会发往相同的桶,每个桶对应一个文件。在两表进行连接的时候,可以快速过滤掉不要的数据,
注意使用 桶的map连接要保证连接的两张表的分桶数之前是倍数关系。
九、Skew Join倾斜连接
当有数据倾斜时的表连接。出现数据倾斜时,会引起个别任务花费大量时间和资源在处理倾斜键的数据,从而变为整个作业的瓶颈。Skew Join在工作是会将数据分为两部分,一部分为倾斜键数据,一部分是余下的所有的数据,由两个作业分别处理。
set hive.optimize.skewjoin = true;
十、ORC与hive相关配置
orc.compress 表示orc的文件压缩类型,可选类型有NONE,ZLIB,SNAPPY
orc.bloom.filter.columns 需要创建布隆过滤的组
orc.bloom.filter.fpp 使用布隆过滤器的假正概率 默认0.05
hive中使用bloom过滤器,可以用较少的文件空间快速判定数据是否存在于表中
十一、数据倾斜
现象就是任务需要处理大量相同键的数据,这种情况有以下4中表现:
- 数据含有大量无意义的数据,如空值(NULL)、空字符串
- 含有倾斜数据在进行聚合计算时,无法聚合中间结果,大量数据都需要经过Shuffle阶段的处理,引起数据倾斜
- 数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜
- 两表进行join,都含有大量相同的倾斜数据键
1. 不可拆分大文件引发的数据倾斜
当对文件使用Gzip压缩等不支持分拣分割操作的压缩方式,当以后有作业读取压缩文件时,改文件只会被一个任务所读取,如果该压缩文件很大,则该map会成为性能瓶颈。
假如一个文件为200M,预先设置每个Map处理数据量为128M,但是计算引擎无法切分这个文件,锁这个文件不会交给两个Map任务去读取,有且只有一个Map任务在操作。
可以采用bzip2和zip等支持文件切分的压缩算法
2. 业务无关的数据引发的数据倾斜
对于空值,NULL这样的,需要在计算过程中排除这些即可。
解决方案 1:user_id 为空的不参与关联
select * from log a join user b on a.user_id is not null and a.user_id = b.user_id
union all
select * from log c where c.user_id is null;
解决方案 2:赋予空值新的 key 值
select * from log a left outer join user b on
case when a.user_id is null then concat('hive',rand()) else a.user_id end = b.user_id
总结
方法 2 比方法 1 效率更好,不但 IO 少了,而且作业数也少了,方案 1 中,log 表 读了两次,jobs 肯定是 2,而方案 2 是 1。这个优化适合无效 id(比如-99,’’,null)产 生的数据倾斜,把空值的 key 变
成一个字符串加上一个随机数,就能把造成数据倾斜的 数据分到不同的 reduce 上解决数据倾斜的问题。
改变之处:使本身为 null 的所有记录不会拥挤在同一个 reduceTask 了,会由于有替代的 随机字符串值,而分散到了多个 reduceTask 中了,由于 null 值关联不上,处理后并不影响最终结果。
1. 多维度聚合计算数据膨胀引起的数据倾斜
对于如下场景 select a,b,c count(1) from T group by a,b,c with rollup;
对于上面这个sql 可以拆分为 (a,b,c),(a,b,null),(a,null,null),(null,null,null)
方法一:手动拆分这个sql
方法二:可以通过参数来自动控制作业的拆解,hive.new.job.grouping.cardinality 针对grouping sets ,rollup,cubes 这类多维度聚合操作,如果最后拆解的组合大于默认配置,会启动信的任务去处理大于该值之外的组合
2. 两个hive数据表连接时引发的数据倾斜
两个普通表进行Repartition join时,如果表连接键存在倾斜,那么shuffle阶段必然会引起数据倾斜
通常这种情况还是启用两个作业,第一个作业处理没有倾斜的数据,第二个作业将倾斜的数据存到分布式缓存中,分到各个Map任务所在节点,在Map阶段完成join操作,避免shuffle,从而避免数据倾斜。