ACL 2021|CHASE: 首个跨领域多轮Text2SQL中文数据集

©PaperWeekly 原创 · 作者 | 徐叶琛
单位 | 字节跳动
研究方向 | NLP语义理解、问答系统
自然语言处理语义解析子任务 Text2SQL 旨在将用户的自然语言转换为 SQL 序列,继而完成数据库查询工作,打破了人与结构化数据库之间的壁垒,具有广泛的研究&应用价值。
近日,微软亚洲研究院联合北航和西安交大,发布了全新跨领域多轮交互 Text2SQL 中文数据集 CHASE,相关论文已被 ACL 2021 接收。
本文从现有 Text2SQL 数据集、CHASE 主要特点、解决方案测评等角度来讲解这篇顶会论文。随同数据集发布的还有同名公开榜单。

论文标题:
CHASE: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL
论文链接:
https://xjtu-intsoft.github.io/chase/

Text2SQL任务和数据集
典型的 Text2SQL 任务是给定一张表格 ,用户输入自然语言问句 ,模型自动生成相应SQL序列 ,相当于对文本和结构化表格同时建模: 。

▲ 任务示例
自从上世纪 90 年代提出该任务以来,Text2SQL 在 NLP 和数据库社区吸引了众多科研人员的关注,学术界和工业界相继发布了一些大规模数据集。从单领域、单轮到跨领域、多轮,任务难度逐渐提升。

▲ 现有的Text2SQL数据集
在实际场景,用户往往会围绕一个感兴趣的问题持续发问,直到从数据库中获得想要的信息。而以往的 Text2SQL 多轮数据集没有中文,仅有的英文数据集 Sparc [1] 和 CoSQL [2] 又包含了很多上下文独立的样本,且部分数据存在标注混乱。

CHASE简介
鉴于以上不足,微软亚洲研究院联合北航和西安交大,发布了最新的 Text2SQL 数据集 CHASE,它有以下特点:
1)跨领域,包含 280 个不同领域的数据库,且 train/dev/test 不重复;
2)大规模,包含 5459 个多轮问题组成的列表,一共 17940 个
3)多轮交互,同一个列表的问题之间会有实体省略等交互现象,类似于 SParc 和 CoSQL;
4)中文数据集,问题和数据库表名、列名、其中的元素都是中文,相比之下,CSpider 只是将表名、列名字段翻译为中文。
5)标注信息丰富,除了 query 和 SQL,CHASE 额外标注了(1)上下文依赖关系,包括 Coreference 共指、Ellipsis 省略;(2)模式链接关系,对于 query 中提到的表名和列名信息进行了标记。
下图是 CHASE 中问题列表的实际例子。
用户的第一个输入“哪所大学培养了最多 MVP 球员”属于独立问题,没有可参考的上下文;紧接着第二个问题“状元呢”直接省略了主语“大学”,完整的问题应该是“哪所大学培养了最多状元”,模型需要结合历史信息才能生成正确 SQL。第三个问题同样类似。

完整的 CHASE 数据集由 CHASE-C 和 CHASE-T 两部分组成。
CHASE-C
CHASE-C 收集了百度去年发布的 DuSQL [3] 单轮中文数据集中的 120 个高质量数据库,包含了运动、教育、娱乐等 60 个子领域;并修复了其中的一些错误(例如重复列、缺少的外键约束等等)。
随后,作者安排了 12 位中国大学生从头开始标注具有上下文依赖的问题列表,以及上文介绍的两种依赖关系,
CHASE-T
CHASE-T 翻译自 Sparc 数据集公开的 train/dev 部分。作者让参与翻译的学生修改那些与上下或主题无关的 query 和 SQL,使问题序列更加连贯和自然。
在构建过程中,CHASE-T 发现并修复了 SParC 中 150 个不正确的 SQL 查询,并调整了 1470 个 SQL 查询,使最终的问题序列更加连贯。
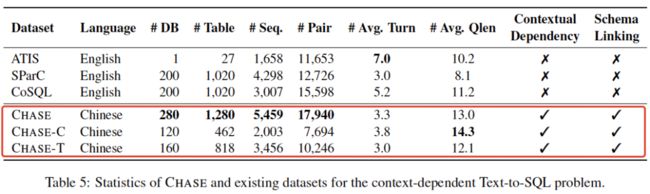
下表统计了 CHASE 和其他多轮 Text2SQL 数据集的对比信息,可以发现 CHASE 规模最大,且标注信息最丰富。

现有 SOTA 模型效果评测
在实验部分,作者选取了 IGSQL [4]、RAT-SQL [5]、EditSQL [6] 3种当前 Text2SQL 领域的 SOTA 方法进行对比,采用问题匹配度 Question Match(QM) 和交互匹配度 Interaction Match(IM)两种评测指标。
最终得到了 4 个观察结论:
1)当前 CHASE 上最优模型 IGSQL 的 QM 仅为40.4%,相比之下 Sparc 和 CoSQL 上的最高 QM 分别是 60.1% 和 50.8%,表明 CHASE 对未来的研究提出了重大挑战;
2)SOTA 方法在 CHASE-C 上的 QM 和 IM 结果均低于 CHASE-T,证明从头创建的问题序列更具挑战性;
3)SOTA 方法在 CHASE-T 的表现要比 Sparc 差,原因来自两方面:(1)CHASE 修复了 Sparc 中的一些 badcase,使得前者更具挑战性;(2)现有方法只针对英文,在处理中文输入时可能表现的不那么稳定;
4)尽管 RAT-SQL 在 Sparc 和 CoSQL 上达到了 SOTA 性能,却在 CHASE 上远落后于 EditSQL 和 IGSQL,原因在于 RAT-SQL 采用了一种基于字符串匹配的方法来寻找数据库模式和 query 提及之间的联系;然而,当许多模式在问题中没有被准确提及时(例如涉及语义推理),这种方法就会陷入困境;CHASE 中的模式链接标注信息为未来解决这一问题提供了帮助。

▲ 实验对比

总结
CHASE 是最新的 Text2SQL 高质量多轮交互数据集,通过人工标注和 review 丰富了问题的多样性和凝聚力,贴近实际应用场景的同时增大了 Text2SQL 任务的难度。
现有的 SOTA 方法在 CHASE 公开榜单上最高 QM 准确率只有 43.7%,还有巨大的提升空间,对语义理解感兴趣的同学不妨来试试刷榜!

最后,我在 Github 上整理了一个 Text2SQL 资源仓库,包含数据集、解决方案、paper、落定应用等信息,可以帮助你快速了解 Text2SQL 领域的研究现状,链接:
https://github.com/yechens/NL2SQL

参考文献
[1] Tao Yu, Rui Zhang, et al. 2019b. SParC: Cross-domain semantic parsing in context. In Proceedings of the 57th Annual Meeting of the ACL, pages 4511–4523.
[2] Tao Yu, Rui Zhang, et al. 2019a. CoSQL: A conversational text-to-SQL challenge towards crossdomain natural language interfaces to databases. In Proceedings of the 2019 Conference on EMNLP and the 9th IJCNLP, pages 1962–1979.
[3] Lijie Wang, Ao Zhang, et al. 2020c. DuSQL: A large-scale and pragmatic Chinese text-to-SQL dataset. In Proceedings of the 2020 Conference on EMNLP, pages 6923–6935. Association for Computational Linguistics.
[4] Yitao Cai and Xiaojun Wan. 2020. IGSQL: Database schema interaction graph based neural model for context-dependent text-to-SQL generation. In Proceedings of the 2020 Conference on EMNLP) pages 6903–6912.
[5] Bailin Wang, Richard Shin, et al. 2020a. RATSQL: Relation-aware schema encoding and linking for text-to-SQL parsers. In Proceedings of the 58th Annual Meeting of the ACL, pages 7567–7578.
[6] Rui Zhang, Tao Yu, et al. 2019. Editing-based SQL query generation for cross-domain context-dependent questions. In Proceedings of the 2019 Conference on EMNLP and the 9th IJCNLP, pages 5338–5349.
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
???? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
???? 投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
