04【DQL查询】
上一篇:03【MySQL字符集】
下一篇:05【数据的备份与恢复】
目录:【MySQL零基础系列教程】
文章目录
- 04【DQL查询】
-
- 4.1 排序
-
- 4.1.1 单列排序
- 4.1.2 组合排序
- 4.2 聚合函数
-
- 4.2.1 五个聚合函数
- 4.2.2 语法:
- 4.3 分组
-
- 4.3.1 分组的用法
- 4.3.2 having与where的区别
- 4.4 limit语句
-
- 4.4.1 limit语句简介
- 4.4.2 LIMIT的使用场景:
- 4.5 case when语句
-
- 4.5.1 case when使用示例
- 4.5.2 case when 案例
-
- 1)案例1
- 2)案例2
04【DQL查询】
4.1 排序
- 准备数据:
create database if not exists db02;
use db02;
drop table if exists student ;
CREATE TABLE student (
id int, -- 编号
`name` varchar(20), -- 姓名
age int, -- 年龄
sex char(1), -- 性别
address varchar(100), -- 地址
math int, -- 数学
english int -- 英语
);
-- 插入数据
insert into student values(1,'小明',24,'男','湖北武汉',90,100);
insert into student values(2,'小红',25,'女','湖南长沙',88,69);
insert into student values(3,'小龙',26,'男','江西南昌',78,80);
insert into student values(4,'小丽',24,'女','安徽合肥',95,80);
insert into student values(5,'张三',19,'男','福建福州',80,90);
insert into student values(6,'李四',24,'男','广东广州',100,95);
insert into student values(7,'王五',24,'男','河南郑州',90,95);
排序本身不会影响到表中的记录位置,只是查询结果变成有序的。默认是升序,从小到大。 数字和字符都有大小的。
- 语法:
SELECT * FROM 表名 ORDER BY 字段名 [ASC/DESC]
升序: ASC(默认值)
降序: DESC
4.1.1 单列排序
-- 查询所有数据,使用年龄升序排序
select * from student order by age asc;
-- 排序默认是升序(asc),因此asc也可以不写
select * from student order by age asc;
-- 查询所有数据,使用年龄降序排序
select * from student order by age desc;
4.1.2 组合排序
- 语法:
SELECT * FROM 表名 ORDER BY 字段名1 [ASC/DESC],字段名2 [ASC/DESC] 先按字段名1进行排序,如果按1排序值相同,再按字段名2进行排序
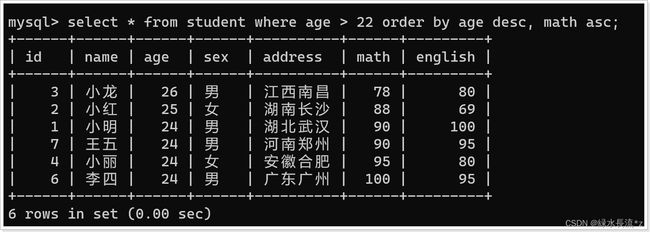
-- 查询所有数据大于20岁的学生,在年龄降序排序的基础上,如果年龄相同再以数学成绩升序排序
select * from student where age > 22 order by age desc, math asc;
4.2 聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个结果值。聚合函数会忽略空值。
4.2.1 五个聚合函数
| SQL中的聚合函数 | 作用 |
|---|---|
| count | 统计个数,如果这一列有NULL,null不会参与统计 |
| max | 找这一列中的最大值,一般是数值类型进行操作。 |
| min | 找这一列中的最小值 |
| sum | 求这一列的总和 |
| avg | 求这一列的平均,返回值小数average |
4.2.2 语法:
SELECT 聚合函数(字段名) FROM 表
- 示例:
-- 查询学生人数总数
select count(id) sum from student;
-- 查询年龄大于24的总数
select count(*) from student where age > 24;
-- 查询数学成绩总分
select sum(math) from student;
-- 查询学生的平均年龄
select avg(age) from student;
-- 查询数学成绩最高的分数
select max(age) from student;
-- 查询数学成绩最低分
select min(math) from student;
4.3 分组
4.3.1 分组的用法
可以将表中的数据按照某个字段分组,分成不同的组之后再使用聚合函数进行计算;
- 语法:
SELECT * FROM 表名 WHERE 条件 GROUP BY 字段名 [HAVING 条件] GROUP BY 分组 HAVING 分组以后得到结果再进行过滤
GROUP BY如何分组的?
将分组字段结果中相同内容作为一组,如按性别将学生分成2组。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-77nEqmql-1661613353807)(media/98.png)]
分组一般搭配聚合函数一起使用
例如:求每个性别的下的数学总成绩,我们通过上述图也能理解,分组之后查询全部数据是毫无意义的
-- 求每个性别的下的数学总成绩
select sex 性别,sum(math) 数学总成绩 from student group by sex;
- 效果如下:
实际上是将每组的math进行求和,返回每组统计的结果

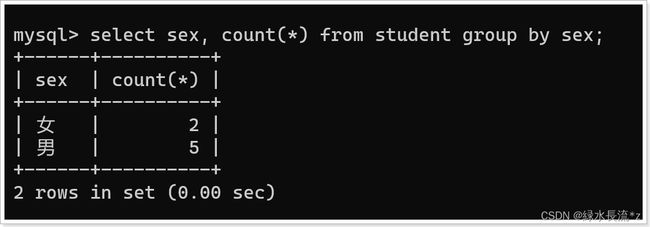
- 查询男女各多少人
-
查询所有数据,按性别分组。
-
统计每组人数
select sex, count(*) from student group by sex;
- 查询年龄大于23岁的人,按性别分组,统计每组的人数
-
先查询年龄出年龄大于23岁的人。
-
再分组。
-
最后统计每组的人数
select sex, count(*) from student where age>23 group by sex;
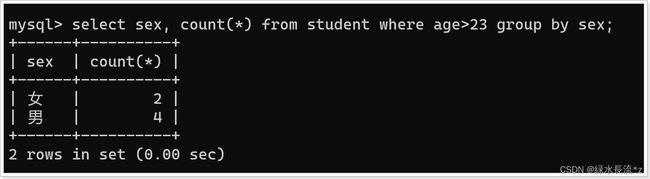
-
查询年龄大于23岁的人,按性别分组,统计每组的人数,并只显示性别人数大于2的数据
-
以下代码是否正确?
SELECT sex, COUNT(*) FROM student WHERE age > 23 GROUP BY sex WHERE COUNT(*) >2;

上面的SQL语句有三处地方有问题:
1)where后面是不能再跟where语句的
2)在where后面是不可以写聚合函数的
3)分组后面不能使用where语句
- 正确写法:
SELECT sex, COUNT(*) FROM student WHERE age > 23 GROUP BY sex having COUNT(*) >2;

4.3.2 having与where的区别
| 子名 | 作用 |
|---|---|
| where 子句 | 先过滤掉行上的一些数据,再进行分组操作。(先过滤再分组) |
| having子句 | 先分组后得到的结果上再进行过滤的操作。(先分组再过滤) |
另外,where子句后不能使用聚合函数,having子句后面可以使用聚合函数;
4.4 limit语句
4.4.1 limit语句简介
-
作用:默认情况下查询所有行,限制查询记录的条数
-
语法:
select * from table LIMIT offset,length
- offset:跳过多少条记录,默认是0
- length:返回多少条记录
案例:查询学生表中数据,从第3条开始显示,显示3条。
select * from student limit 2, 3;
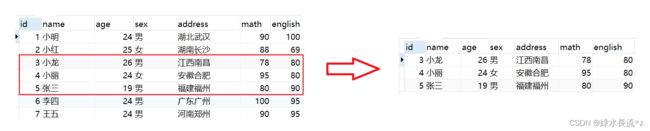
4.4.2 LIMIT的使用场景:
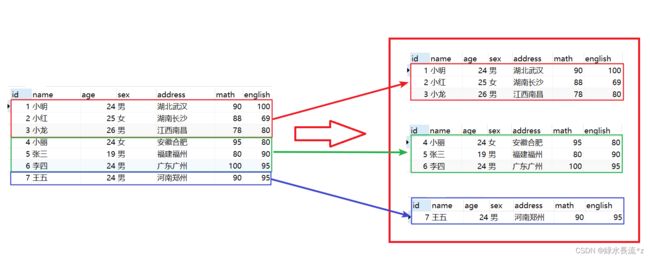
分页:比如我们登录京东,淘宝,返回的商品信息可能有几万条,不是一次全部显示出来。是一页显示固定的条数。
假设我们一每页显示3条记录的方式来分页。
-- 每页显示3条
-- 第一页:跳过0条,显示3条
select * from student3 limit 0,3;
-- 如果第1个参数是0,可以省略
select * from student3 limit 3;
-- 第二页:跳过3条,显示3条
select * from student3 limit 3,3;
-- 第三页:跳过6条,显示3条(如果没有这么多记录,有多少条显示多少条)
select * from student3 limit 6,3;
-- 公式: select * from student limit (当前页-1)*页大小,页大小
4.5 case when语句
4.5.1 case when使用示例
Case When语句用于选择判断,在执行时先对条件进行判断,然后根据判断结果做出相应的操作;
- 语法:
CASE 字段
WHEN 条件1 THEN 操作1
WHEN 条件2 THEN 操作2
...
ELSE 操作n
END;
- 使用示例:
SELECT
*,
CASE
sex
WHEN '男' THEN
'man'
WHEN '女' THEN
'woman'
ELSE '其他'
END AS 'other'
FROM
student;
# 效果:
+------+------+------+------+----------+------+---------+-------+
| id | name | age | sex | address | math | english | 性别 |
+------+------+------+------+----------+------+---------+-------+
| 1 | 小明 | 24 | 男 | 湖北武汉 | 90 | 100 | man |
| 2 | 小红 | 25 | 女 | 湖南长沙 | 88 | 69 | woman |
| 3 | 小龙 | 26 | 男 | 江西南昌 | 78 | 80 | man |
| 4 | 小丽 | 24 | 女 | 安徽合肥 | 95 | 80 | woman |
| 5 | 张三 | 19 | 男 | 福建福州 | 80 | 90 | man |
| 6 | 李四 | 24 | 男 | 广东广州 | 100 | 95 | man |
| 7 | 王五 | 24 | 男 | 河南郑州 | 90 | 95 | man |
+------+------+------+------+----------+------+---------+-------+
7 rows in set (0.00 sec)
mysql>
4.5.2 case when 案例
1)案例1
- 数据准备:
DROP TABLE IF EXISTS `info`;
CREATE TABLE `info` (
`id` int(11) NOT NULL,
`province` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`population` int(255) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of info
-- ----------------------------
INSERT INTO `info` VALUES (1, '江西', 200);
INSERT INTO `info` VALUES (2, '山西', 300);
INSERT INTO `info` VALUES (3, '广西', 300);
INSERT INTO `info` VALUES (4, '湖南', 500);
INSERT INTO `info` VALUES (5, '湖北', 400);
INSERT INTO `info` VALUES (6, '广东', 800);
INSERT INTO `info` VALUES (7, '福建', 300);
INSERT INTO `info` VALUES (8, '山东', 400);
INSERT INTO `info` VALUES (9, '四川', 700);
- 根据省份的人口数据数据,统计华东和华南的人口数量。
先统计每个省份的人数
SELECT
CASE province
WHEN '江西' THEN '华东'
WHEN '广西' THEN '华南'
WHEN '广东' THEN '华南'
WHEN '福建' THEN '华东'
WHEN '山东' THEN '华东'
ELSE '其他' END as '地区',
population as '人口'
FROM info;

在根据地区进行分组:
SELECT
CASE province
WHEN '江西' THEN '华东'
WHEN '广西' THEN '华南'
WHEN '广东' THEN '华南'
WHEN '福建' THEN '华东'
WHEN '山东' THEN '华东'
ELSE '其他' END as '地区',
sum(population) as '总人数'
FROM info
GROUP BY 地区
order by 总人数;

2)案例2
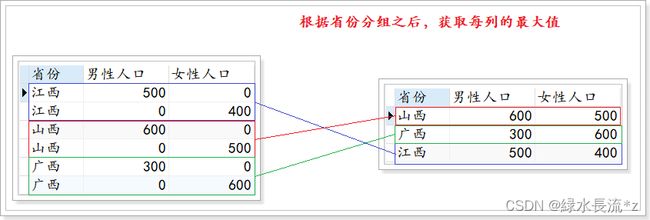
- 案例效果:

- 准备数据:
DROP TABLE IF EXISTS `info`;
CREATE TABLE `info` (
`id` int(11) NOT NULL,
`province` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sex` char(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`population` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of info
-- ----------------------------
INSERT INTO `info` VALUES (1, '江西', '男', 500);
INSERT INTO `info` VALUES (2, '江西', '女', 400);
INSERT INTO `info` VALUES (3, '山西', '男', 600);
INSERT INTO `info` VALUES (4, '山西', '女', 500);
INSERT INTO `info` VALUES (5, '广西', '男', 300);
INSERT INTO `info` VALUES (6, '广西', '女', 600);
- 步骤1):进行行和列的转换
select
province as '省份',
case when sex = '男' then population else 0 end as '男性人口',
case when sex = '女' then population else 0 end as '女性人口'
from info;
效果如下:

- 步骤2):根据省份进行分组,取每组最大值
select
province as '省份',
max(case when sex = '男' then population else 0 end) as '男性人口',
max(case when sex = '女' then population else 0 end) as '女性人口'
from info
group by province;