OCR预处理之:通过随机森林机器学习进行去噪
OCR预处理之:通过随机森林机器学习对图像进行预处理去噪
此博文详细描述如何通过机器学习的算法(随机森林)对一张图片进行去噪处理。并且,这里也会附上及其详细的代码以及注解。如果感兴趣的同学可以自行下载。注:代码运行于Ubuntu AMD 环境。
代码下载地址:https://download.csdn.net/download/zyctimes/74472005
喜欢的朋友点个赞哦:)
文章目录
- OCR预处理之:通过随机森林机器学习对图像进行预处理去噪
-
- 0. 效果图
- 1. 准备
-
- 1.1 代码的安装与使用
- 1.2 代码结构
- 1.3 数据集
- 2. 用随机森林去噪
- 2.1. 特征提取:Random Forest Regression
- 2.2 特征提取:代码
- 2.3 模型训练
- 2.4 测试训练
0. 效果图

在真实的环境中,难以避免的,一些纸张上会有一些污渍或者褶皱。这个时候,如果我们想要去对其做一些OCR文字识别,其精度可能会大打折扣。我们希望通过一些简单的机器学习算法,对输入的图片做一些预处理,部分地消除其背景噪声。
1. 准备
1.1 代码的安装与使用
首先,我们将代码下载后,新建一个虚拟环境:virtualenv [venv],[venv]指的是我们自己命名的虚拟环境的名称。接下来进入虚拟环境:source [venv]/bin/activate。如是自己创建的新虚拟环境,还需要安装依赖:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple。如想直接看到结果,可以直接运行python main.py(在项目的根目录下)。
1.2 代码结构
一如既往地,我们先附上代码结构,并做一些相关的解释。
--document denoise
|---img-ml-denoise (包含我们训练模型用的数据集)
|---img2test (测试数据集,我们实际不用)
|---img2trn (训练数据集,带有噪声的照片,如上图左)
|---imggroundtruth (训练数据集,没有噪声的照片,如上图右)
|---imgRaw (测试用的照片,用于测试我们训练出来的模型的效果)
|---imgSave (保存照片的路径)
|---buildfeature4trn.py (训练模型的第一步是从照片中提取特征并将其存于一个.csv文件中)
|---imgmlfeatures.csv (运行buildfeature4trn.py后,会生成这个csv文件,用于保存特征)
|---main.py (主程序)
|---mathe.py (一些与计算有关的函数)
|---modeltrain,py (模型的训练)
|---modeltest.py (模型的测试)
|---configInputsParse.py (读取config.txt文件中的参数)
|---config.txt (所有可调参数)
|---requirements.txt (所有安装包以及版本)
|---imgdenoiser,pickle (ML 模型)
|---readme.md (说明文档)
文件有一些多,但并不难理解。
接下来,我们可以直接进入main.py,看到如下代码:
def main(args):
config = configparser.ConfigParser() # Set properties of parameters inside config file.
config.read(cfgFile)
config.sections()
cfgParameters.cfgInputParameters(config) # Parameters to load.
# For the first step of training, we need to build features based on train images and ground truth images
buildFeature = buildFeature4TrnCls(cfgParameters)
buildFeature.buildFeaturesMain()
# After getting the feature and saving into file, we load them and use data inside for training.
model2Trn = trainModelCls(cfgParameters)
model2Trn.trainModelMain()
# Test and display results
testModel = testModelCls(cfgParameters)
testModel.testModelMain()
从上述代码中,我们其实已经能够一眼看出这整个项目实际上只有四个部分:
- 读取参数(就是
config文件,cfgParameters.cfgInputParameters(config)) - 提取特征(
buildFeature.buildFeaturesMain()) - 训练(
model2Trn.trainModelMain()) - 测试结果(
testModel.testModelMain())
1.3 数据集
数据集源于Kaggle的Denoising Dirty Documents。
上图列举了一些例子。整个数据集的数量也不是很大,一共216张训练集。我这里也已经全部下载并放入项目中了。
数据集中的照片尺寸多为540248以及540420。我们的目标是输入上图中的带有噪声的照片,输出背景干净的照片,就如第0章所示。
接下来,让我们详细解释其中的每一个环节,以及对这个随机森林是如何使用的做一些详细说明。
2. 用随机森林去噪
在这之前,多说一句。实际上,我并不认为这个算法可以解决很大类的问题,但这个博文依旧有一些很值得借鉴的地方,比如去噪的逻辑,相对于传统的图像处理已经是更进了一步,以及代码的书写(我自认为还可以:))。
2.1. 特征提取:Random Forest Regression
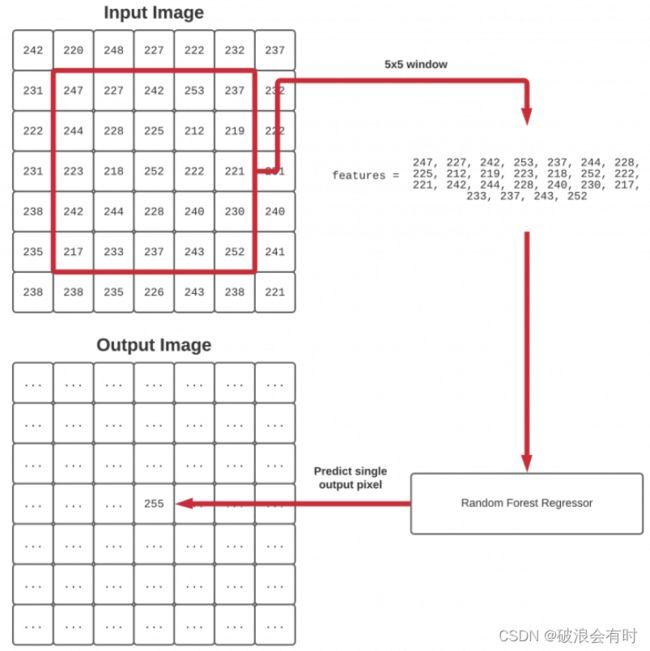
我们这个Random Forest Regression (RFR) 算法的工作原理是应用一个从左到右、从上到下滑动的5 x 5窗口。这个滑动窗口在带有噪声的图像(即我们要自动预处理和清理的图像)中滚动。痛过RFR算法,去预测/拟合在没有噪声的图像中对应位置的中心点的值。(这里的5x5的尺寸是可以根据输入图片的分辨率进行调整的)
让我们再次回顾一下代码结构:
--document denoise
|---img-ml-denoise (包含我们训练模型用的数据集)
|---img2test (测试数据集,我们实际不用)
|---img2trn (训练数据集,带有噪声的照片,如上图左)
|---imggroundtruth (训练数据集,没有噪声的照片,如上图右)
img2trn即那些带有噪声的照片。imggroundtruth即没有噪声的照片。这两个文件夹中的照片是一一对应的。所以说,两个文件夹中的照片共同组成了我们这个项目的训练集。
在每个滑动窗口停止处,我们提取:
- 带有噪声图像的5 x 5区域。然后,我们将5x5区域展平为一个25维列表(25x1),并将其视为一个特征向量。
- 不带噪声图像的相同5x5区域,但这次我们只取中心点(x,y)坐标。
- 给定来自噪声输入图像的25维特征向量,这个不带噪声图像的单像素值就是我们希望RFR预测的值。
2.2 特征提取:代码
def buildFeaturesMain(self):
# grab the paths to our training images
allTrainImgPaths = sorted(list(paths.list_images(self.imgMlTrainPath)))
allGtImgPaths = sorted(list(paths.list_images(self.imgMlGtPath)))
# initialize the progress bar
widgets = ["Creating Features: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(self.allTrnFilesPath), widgets=widgets).start()
# zip training image paths and ground truth image paths, then open the output featureFile2Save file for writing
allImgPaths = zip(allTrainImgPaths, allGtImgPaths)
featureFile2Save = open(self.featureFileName, "w")
# loop over the training images together
for (i, (trainPath, gtPath)) in enumerate(allImgPaths):
trainImage = cv2.imread(trainPath) # Load train image (noisy image)
gtImage = cv2.imread(gtPath) # Load ground truth image
trainImage = cv2.cvtColor(trainImage, cv2.COLOR_BGR2GRAY) # Convert train image from BGR to grey
gtImage = cv2.cvtColor(gtImage, cv2.COLOR_BGR2GRAY) # Convert ground truth image from BGR to grey
# apply paddingStepxpaddingStep padding to both images, replicating the pixels along
# the border/boundary. This denoising document algorithm works by sliding a 5 x 5 window
# from left-to-right and top-to-bottom across the noisy input. This padding is similar
# as which in CNN in deep learning.
trainImage = cv2.copyMakeBorder(trainImage, self.paddingStep, self.paddingStep, \
self.paddingStep, self.paddingStep, cv2.BORDER_REPLICATE)
gtImage = cv2.copyMakeBorder(gtImage, self.paddingStep, self.paddingStep, \
self.paddingStep, self.paddingStep, cv2.BORDER_REPLICATE)
# blur and threshold the noisy image
trainImage = ImgBlurThresholding(trainImage)
# scale the pixel intensities in the ground truth image from the range [0, 255] to [0, 1]
# (the train/noisy image is already in the range [0, 1])
gtImage = gtImage.astype("float") / 255.0
for ii in range(self.featureNumPerImage):
# We randomly select the position on the image
x = random. randint(1,trainImage.shape[1])
y = random. randint(1,trainImage.shape[0])
# extract the window ROIs for both the train image and ground truth image,
# then grab the spatial dimensions of the ROI
trainROI = trainImage[y:y + self.filterScale, x:x + self.filterScale]
gtROI = gtImage[y:y + self.filterScale, x:x + self.filterScale]
(rH, rW) = trainROI.shape[:2]
# if the ROI is not filterScale x filterScale, throw it out
if rW != self.filterScale or rH != self.filterScale:
continue
# our features will be the flattened filterScale x filterScale raw pixels from the noisy ROI while
# the target prediction will be the center pixel in the filterScale x filterScale window
features = trainROI.flatten()
target = gtROI[self.paddingStep, self.paddingStep]
# write the target and features to our CSV file
features = [str(x) for x in features]
row = [str(target)] + features
row = ",".join(row)
featureFile2Save.write("{}\n".format(row))
# update the progress bar
pbar.update(i)
# close the featureFile2Save file
pbar.finish()
featureFile2Save.close()
print("All features were generated and saved in {} file.".format(self.featureFileName))
首先我们把所有训练图片的路径提取出来,zip到一起:
allTrainImgPaths = sorted(list(paths.list_images(self.imgMlTrainPath)))
allGtImgPaths = sorted(list(paths.list_images(self.imgMlGtPath)))
allImgPaths = zip(allTrainImgPaths, allGtImgPaths)
然后,我们通过一个for循环对每一套训练照片进行遍历。我们需要注意的是,这里的每一套训练照片包含了两张照片,分别对应有噪声trainImage与没有噪声gtImage的照片。
在每一次的循环迭代中,我们首先通过cv2.cvtColor将照片灰度化,然后再照片的外面做一圈padding。回顾一下上一章节中我们提到,这个RFR算法的核心在于滑动的5 x 5窗口,这里我们希望原图的每一个像素点都能取到,所以在图像的外面padding了一圈。padding的尺寸为paddingStep这个变量,而滑动框的尺寸为filterScale,也是一个变量。两者之间的关系是:self.paddingStep = int(np.floor(self.filterScale/2)),比如filterScale=5的话,paddingStep=2。
trainImage = cv2.copyMakeBorder(trainImage, self.paddingStep, self.paddingStep, \
self.paddingStep, self.paddingStep, cv2.BORDER_REPLICATE)
gtImage = cv2.copyMakeBorder(gtImage, self.paddingStep, self.paddingStep, \
self.paddingStep, self.paddingStep, cv2.BORDER_REPLICATE)
经过一些简单的预处理,比如模糊取差(类似经典图像处理里面的hat),详细参见ImgBlurThresholding函数,以及归一(像素点从0-255归一到0-1),详细参见gtImage.astype("float") / 255.0,我们在每一组图像中的随机位置抽取featureNumPerImage个点。之所以这么做,是因为普通的滑动滚窗计算量太大,而且没有必要(就类似于stochastic gradient decent)。所以我们这里就做了一些随机取点的处理。
对于每一个随机取到的像素点位置,在有噪声的图片中,我们抽取以这个点为中心,长宽为filterScale的矩阵,然后把它转换为一个filterScale x filterScale纬的向量;在没有噪声的图片中,我们则直接选取这个像素点即可。
x = random. randint(1,trainImage.shape[1])
y = random. randint(1,trainImage.shape[0])
trainROI = trainImage[y:y + self.filterScale, x:x + self.filterScale]
gtROI = gtImage[y:y + self.filterScale, x:x + self.filterScale]
features = trainROI.flatten()
target = gtROI[self.paddingStep, self.paddingStep]
target和feature组成了我们这组图片的特征。
最后我们将这组特征保存进csv文件中,然后进行下一组图片的循环。
features = [str(x) for x in features]
row = [str(target)] + features
row = ",".join(row)
featureFile2Save.write("{}\n".format(row))
2.3 模型训练
这块其实就很简单了,我们直接来看代码吧。
def trainModelMain(self):
# initialize lists to hold our features and target predicted values
print("Start training the model.\nLoading dataset...")
featureList = []
predictList = []
# loop over the rows in our features CSV file
for row in open(self.featureFileName):
# parse the row and extract (1) the target pixel value to predict
# along with (2) the 5x5=25 pixels which will serve as our feature vector
row = row.strip().split(",")
row = [float(x) for x in row]
predict_ = row[0]
feature_ = row[1:]
# update our featureList and predictList
featureList.append(feature_)
predictList.append(predict_)
# convert the features and targets to NumPy arrays
featureArray = np.array(featureList, dtype="float")
predictArray = np.array(predictList, dtype="float")
# construct our training and testing split, using 75% of the data for
# training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(featureArray, predictArray,
test_size=self.mltrnValidDataPercentage, random_state=42)
# train a random forest regressor on our data
print("training model...")
model = RandomForestRegressor(n_estimators=10)
model.fit(trainX, trainY)
# compute the root mean squared error on the testing set
print("Evaluating model...")
preds = model.predict(testX)
rmse = np.sqrt(mean_squared_error(testY, preds))
print("rmse: {}".format(rmse))
# serialize our random forest regressor to local.
f = open(self.imgDenoiseModel, "wb")
f.write(pickle.dumps(model))
f.close()
首先我们打开上一个步骤中保存好的特征csv文件,然后分别把带有噪声的特征(featureList)以及不带噪声的特征(其实就是ground truth)(predictList)放入对应的列表中。
for row in open(self.featureFileName):
row = row.strip().split(",")
row = [float(x) for x in row]
predict_ = row[0]
feature_ = row[1:]
featureList.append(feature_)
predictList.append(predict_)
然后我们直接调用sklearn做随机森林
# construct our training and testing split, using 75% of the data for
# training and the remaining 25% for testing
(trainX, testX, trainY, testY) = train_test_split(featureArray, predictArray,
test_size=self.mltrnValidDataPercentage, random_state=42)
# train a random forest regressor on our data
print("training model...")
model = RandomForestRegressor(n_estimators=10)
model.fit(trainX, trainY)
2.4 测试训练
代码如下,这里就不一句句解释了,确实不难理解,感兴趣的同学可以下载我的代码,或直接阅读下面的代码,几乎每一行都有注释。
def testModelMain(self):
# load our document denoiser from disk
model = pickle.loads(open(self.imgDenoiseModel, "rb").read())
# load the test image
print("Load test image from {}".format(self.imgTestPath))
imgTest = cv2.imread(self.imgTestPath)
imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2GRAY) # Convert from BGR to gray
imgOrig = imgTest.copy()
# pad the image followed by blurring/thresholding it
imgTest = cv2.copyMakeBorder(imgTest, self.paddingStep, self.paddingStep, \
self.paddingStep, self.paddingStep, cv2.BORDER_REPLICATE)
imgTest = ImgBlurThresholding(imgTest)
# initialize a list to store our ROI features (i.e., filterScale x filterScale pixel neighborhoods)
features2Predict = []
# slide a filterScale x filterScale window across the image
for y in range(0, imgTest.shape[0]):
for x in range(0, imgTest.shape[1]):
# extract the window ROI and grab the spatial dimensions
roi = imgTest[y:y + self.filterScale, x:x + self.filterScale]
(rH, rW) = roi.shape[:2]
# if the ROI is not filterScale x filterScale, throw it out
if rW != self.filterScale or rH != self.filterScale:
continue
# our features will be the flattened filterScale x filterScale pixels from the training ROI
features = roi.flatten()
features2Predict.append(features)
print("self.filterScale: ",self.filterScale)
print("self.paddingStep: ",self.paddingStep)
# use the ROI features to predict the pixels of our new denoised image
imgPredict = model.predict(features2Predict)
# the pixels list is currently a 1D array so we need to reshape
# it to a 2D array (based on the original input image dimensions)
# and then scale the pixels from the range [0, 1] to [0, 255]
imgPredict = imgPredict.reshape(imgOrig.shape)
imgPredict = (imgPredict * 255).astype("uint8")
imgOrig = cv2.cvtColor(imgOrig, cv2.COLOR_GRAY2BGR) # Convert from gray to BGR
imgPredict = cv2.cvtColor(imgPredict, cv2.COLOR_GRAY2BGR) # Convert from gray to BGR
# show the original and output images
imgs2Display = {"Original image":imgOrig, "Image after denoising":imgPredict}
self.imgSaveFullPath = os.path.join(self.imgSaveFullPath,"imgSave.png")
displaySaveMultipleImgs(imgs2Display,rows=1,cols=2, imgDisplay=self.imgDisplay, \
imgSave=self.imgSave, imgSaveFullPath=self.imgSaveFullPath)