Python从入门到熟练
文章目录
- Python 环境
- Python 语法与使用
-
- 基础语法
-
- 数据类型
- 注释
- 数据类型介绍
-
- 字符串
- 列表
- 元组
- 集合
- 字典
- 类型转换
- 标识符
- 运算符
-
- 算数运算符
- 赋值运算符
- 复合运算符
- 字符串
-
- 字符串拼接
- 字符串格式化
- 判断语句
-
- bool 类型
- 语法
- if 语句
- if else 语句
- if elif else 语句
- 循环语句
-
- while循环
- for 循环
- range 语句
-
- case 1
- case 2
- case 3
- 作用域
- 循环的中断
-
- break
- continue
- 函数
-
- 定义语法
- 传参
- 返回值
-
- None类型
- 函数说明
- 作用域
- 数据容器
-
- list 列表
-
- 定义
- 使用
- 方法
-
- 查找下标
- 列表修改
- 插入
- 追加
- 删除
- 修改
- 查询
- 循环遍历
- tuple 元组
-
- 定义
- 操作
- str 字符串
-
- 方法
-
- 查找下标
- 替换
- 分割
- 去除前后空格
- 去除前后指定字符
- 统计字符串出现次数
- 统计字符串长度
- 序列的切片
-
- 序列
- 序列的切片
- set 集合
-
- 定义
- 方法
-
- 添加
- 移除
- 随机取出
- 清空
- 差集
- 消除差集
- 并集
- dict 字典
-
- 定义
- 访问
-
- 方法
- 总结
- 推导式
-
- 列表推导式
-
- 数据的过滤
- 字典推导式
- 集合推导式
- 函数进阶
-
- 多返回值
- 函数的传参
-
- 位置参数
- 关键字参数
- 缺省参数
- 不定长参数
-
- 位置传递
- 关键字传参
- 函数式编程的高阶函数
-
- 函数作为参数传递
- lambda匿名函数
- filter()函数
- map()函数
- reduce()函数
- sorted()函数
- 文件操作
-
- 文件编码
- 文件的打开
-
- 文件的读取
-
- read() 方法
- readlines() 方法
- readline() 方法
- 文件关闭
- 文件写入
- 文件追加
- 模块与包
-
- 模块的导入
- 编写自己的模块
- 包
- 面向对象
-
- 类的定义和使用
- 成员方法的定义
- 构造方法
- 其他内置方法
-
- \_\_str\_\_ 字符串方法
- \_\_lt\_\_ 小于符号比较
- \_\_le\_\_ 小于等于比较 \_\_eq\_\_ 等于比较
- 封装
-
- 私有成员
- 继承
-
- 复写
-
- 方法1
- 方法2
- 类型注解
-
- 变量类型注解
- 函数(方发)类型注解
- Union类型
- 多态
-
- 抽象类(接口)
- 生成器与迭代器
-
- 生成器
-
- 利用生成器表达式创建生成器
- 利用yield创建生成器
- 迭代器
-
- 可迭代对象
- json模块
-
- json与Python数据的相互转化
- pyecharts模块
-
- pyecharts基本操作
-
- 基础折线图
- 配置选项
-
- 全局配置选项
- json模块的数据处理
- 折线图示例
-
- 示例代码
- NumPy
-
- NumPy介绍
- 导入NumPy
- NumPy数组
-
- 序列生成数组
- 函数生成数组
-
- range,arange,linspace
- 其他常用函数
- N维数组的属性
- NumPy数组的运算
-
- 向量运算
- 算数运算
- 逐元素运算、点乘运算
- 操作数组元素
-
- 索引访问数组
- 切片访问数组
- 转置与展平
- NumPy的广播
- NumPy的高级索引
-
- 整数索引
- 布尔索引
- 数组的堆叠
-
- 水平方向堆叠
- 竖直方向堆叠
- 深度方向堆叠
- 行堆叠和列堆叠
- 数组的分割
- 随机数
- Pandas 数据分析
-
- Pandas 简介
- Pandas 安装
- Series 类型数据
-
- Series的创建
- Series的访问
- Series 中向量化操作与布尔索引
- Series的切片
- Series的缺失值
- Series的增与删
- Series的name
- DataFrame 数据类型
-
- DataFrame的创建
- DataFrame的访问
- DataFrame的删除
- DataFrame的添加
-
- 添加行
- 添加列
- Pandas的文件读取与分析
-
- 利用Pandas读取文件
- DataFrame的常用属性
- DataFrame的常用方法
- DataFrame的条件过滤
- DataFrame的切片操作
- DataFrame的排序操作
- Pandas的聚合与分组运算
-
- 聚合
- 分组
- DataFrame中数据清洗方法
- Matplotlib与可视化分析
-
- 简单图形的绘制
- pylot的高级功能
-
- 添加图例与注释
Python 环境
在Python官网下载的Python实际上是Python的解释器,而我们所熟知的PyCharm是一种Python的编辑器,Python安装教程已经非常丰富了,这里就不过多介绍
Python 语法与使用
基础语法
数据类型
在Python中有6种自带的数据类型
| 类型 | 描述 |
|---|---|
| 数字(Number) | 整数(int)、浮点数(float)、复数(complex)、布尔值(bool) |
| 字符串(String) | 由一串字符组成的一种描述文本的数据类型 |
| 列表(List) | 有序的序列 |
| 元组(Tuple) | 有序的不可更改的序列 |
| 集合(Set) | 无序不重复集合 |
| 字典(Dictionary) | 键值对的集合 |
在Python中的数据类型我们可以使用type()函数查看,在Python中声明变量是不需要声明数据类型的,但是在使用过程中仍然要注意类型的匹配,在后面的学习中,我们会介绍标注类型的方法
Python是不受数据大小限制的,例如整数int是没有大小限制的
Python中值相同的变量指向的是同一个地址的,可以用id()来查看
注释
注释用法如下,举例
# 单行注释
"""
多行注释1
多行注释2
多行注释3
"""
数据类型介绍
这里只做最最基础的介绍,之后讲到容器时会具体介绍
字符串
Python中有三种字符串定义方式
str1 = '字符串'
str2 = "字符串"
str3 = """字符串""" # 这里与多行注释不同的是有变量接收,同样也支持多行赋值
str4 = """
字符串1
字符串2
字符串3
"""
列表
用方括号括起,内部元素可以是整数,字符串,其他容器
lt = [1,2,3]
元组
用圆括号括起,内部元素不可改变,可以是其他容器
tp = (1,2,3) # 多个元素声明
tp = (1,) # 单个元素声明
集合
用花括号括起,内部元素可以改变但不能重复
st = {1,2,3}
字典
由花括号括起,内部元素可以改变且无序,类似于生活中的字典
dic = {'key1' : 'val1','key2' : 'val2'}
类型转换
在不同的使用场景下需要不同的数据类型,因此就需要类型转换的功能,例如int()转换为整数,float()转换为浮点数,str()转换为字符串
标识符
我们给变量、类、函数起名时的标识符有如下限制
- 标识符中可以出现英文、中文、数字、下划线,注意其中数字不可以作为开头使用
- Python中的关键字不允许作为标识符使用
False True None and as assert break class continue def del elif else except finally for from global if import in is lambda nonlocal not or pass raise return try while with yield
注意其中的False、True、None的首字母需要大写
运算符
算数运算符
| 运算符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| // | 取整除 |
| % | 取模 |
| ** | 指数 |
赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 赋值 |
复合运算符
| 运算符 | 描述 |
|---|---|
| += | 加法赋值 |
| …… | 诸如此类 |
注意Python不支持++,–操作
字符串
字符串拼接
直接用加号即可拼接
例如
print("str1"+"str2")
name = 'your str'
print("str1"+name+"str2")
字符串格式化
一旦变量过多,要输出需要拼接许多次,略显麻烦,可以采用字符串格式化来表示
例如
mas1 = "str1"
mas2 = "mas1 = %s" % mas1
这里就使用%s进行占位,来进行变量的输出
需要注意的是,多个变量的时候需要在之后用圆括号括起,并按照顺序填写
例如
mas1 = "str1"
mas2 = "str2"
mas3 = "mas1 = %s, mas2 = %s" % (mas1,mas2)
关于其他占位符
| 占位符 | 说明 |
|---|---|
| %s | 字符串 |
| %d | 整数 |
| %f | 浮点数 |
关于浮点数的精度控制可以用 m.n 来控制
m控制宽度,要求是数字
.n,控制小数点精度,要求是数字
示例:
- %5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。
- %5.2f:表示将宽度控制为5,将小数点精度设置为2。小数点和小数部分也算入宽度计算。
- 如,对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35
- %.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35
使用占位符进行格式化的效率比较慢,有第二种格式化的方法,会比较常用,例如
mas1 = "str1"
mas2 = "str2"
print(f"mas1 = {mas1}, mas2 = {mas2}")
需要注意的是,这种写法不用做精度控制,也不需要管类型是如何,适用于快速格式化,较为方便和易读,在花括号内填入变量名或者表达式都可以。
判断语句
bool 类型
bool 类型可以用True和False表示真或假,实际上的数值Ture是1,False是0
要注意这里的首字母需要大写
也可也通过比较运算符来获取结果,这个结果也是bool类型
语法
在Python种基本上不使用大括号进行代码块的区分,而是使用冒号加缩进的方式,因此Python对于格式的要求十分严格,例如
if 语句
condition = int(input()) # 这里利用input函数读取用户输入的数字,默认为字符串,利用int函数转换为整数
if condition > 20:
print("condition is true!")
判断语句的结果必须是bool类型,仅当结果为True时会执行代码块内的语句
if else 语句
condition = int(input())
if condition > 20:
print("condiiton is true!")
else:
print("condition is false!")
else即为条件不成立时执行的语句
else之后不需要加条件,但和if一样需要加冒号
if elif else 语句
当判断条件不止一个时需要用elif实现,elif实际上是 else if 的缩写
condition = int(input())
if condition > 20:
print("condiiton is true!")
elif condition > 10:
print("condition is true, too!")
else:
print("condition is false!")
循环语句
顾名思义,只要条件满足,语句会永远执行
while循环
condition = int(input())
i = 0;
while i < condition:
print("condiiton is true!")
例如,利用循环求从1到100的和
i = 1
ans = 0
while 1 <= 100:
ans += i
print(f"ans = {ans}")
for 循环
这里需要补充一些(转义字符)[http://t.csdnimg.cn/cVNjp]的知识,方便大家的学习
基础语法如下
for 临时变量 in 数据集:
代码
这个句子的意思是从待处理数据集中:逐个取出数据赋值给临时变量
这里的数据集可以是一个范围range,等下我们会讲到,字符串、列表等,临时变量会依次取出其中的数据
range 语句
range实际上从英语意义上理解就可以知道他是范围的意思,他有如下几种用法
case 1
range(num)
从0开始依次取到num的前一个数字,这里的num为整数
case 2
range(num1, num2)
从num1开始取到num2的前一个数字,左闭右开区间
case 3
range(num1, num2, step)
从num1开始取到num2,step为步长,默认为1
同样的,我们可以用for循环求从1到100的和
ans = 0
for i in range(1,101)
ans += i
作用域
在学习完分支循环等控制流程的语句之后,我们已经对代码块有了一个初步的理解
实际上变量也是有其生命周期的,也就是他的作用域,语句执行出这个代码块之后,他本身就不允许再被访问了
循环的中断
在循环的过程中我们会遇到很多意外的情况,需要跳出循环或者跳过这一层循环,这时候就需要break和continue关键字了
break
break是用于循环内部,当执行到break语句时,循环会直接结束
continue
当执行到continue时,会跳过这一次的循环
函数
函数:是组织好的,可重复使用的,用来实现特定功能的代码段。
他具有高复用性,方便了程序的编写与使用
定义语法
def 函数名(传入参数):
函数体
return 返回值
定义是这样的,调用就是直接写函数名称和你需要传入的参数即可
参数和返回值如果不需要是可以省略,需要注意的是函数必须要先定义好才能使用
传参
例如:
def add(x,y):
res = x + y
print(f"{x}+{y}={res}")
要注意传参需要用逗号进行分隔
返回值
是为了返回程序执行的结果
例如
def add(x,y):
res = x + y
return res
这里就是返回了结果
None类型
实际上没有调用return进行返回数据时,函数也是有返回值的,就是None,其实就是返回空的意思,当函数遇到了特殊情况需要结束函数时,即可调用return None进行返回
函数说明
当我们进行团队协作完成项目时,最好写上函数说明,用于辅助理解函数的作用,例如变量的含义,返回值的含义等
作用域
变量作用域指的是变量的作用范围,主要分为局部变量和全局变量
局部变量是定义在函数体内部的变量,即只在函数体内部生效,只在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量
全局变量指的是在函数体内、外都能生效的变量
使用 global关键字 可以在函数内部声明变量为全局变量
数据容器
数据容器是一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素,每一个元素,可以是任意类型的数据,如字符串、数字、布尔等
在Python中有不同的数据容器,他们有不同的特性,分为五类:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
list 列表
定义
list_name1 = [name1,name2,name3,...]
list_a = []
list_b = list()
以方括号作为表示,用逗号隔开,元素之间可以是不同的数据类型,支持嵌套,后面两种都是定义空列表的方式
例如
list_name2 = [[1,2,3],[3,4,5]]
使用
数组是利用下标索引进行访问的,有两种标号方式,一种是从左到右,依次标号为0,1,2,…;第二种是从右到左,一次标号为-1,-2,-3,…;
当我们想要进行取出数据时,可以利用方括号+下标的方式取出,例如
list_1 = list_name1[0]
list_2 = list_name2[0][1]
方法
这里的方法其实就类似于函数,但是需要配合数据容器进行使用
查找下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)
list_name3 = ['name1','name2','name3']
print(list_name3.index('name2')) # 结果会输出 1
列表修改
功能:修改列表中元素的值
语法:列表[下标] = 值
list_name3[2] = 'name4'
插入
语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素
list_name3.insert(2,'name3')
print(list_name3) # 结果 ['name1','name2','name3','name4']
追加
语法:列表.append(元素),将指定元素,追加到列表的尾部
list_name3.append('name5')
语法:列表.extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部
list_name4 = ['name6','name7']
list_name3.append(list_name4)
print(list_name3) # 结果 ['name1','name2','name3','name4''name5','name6','name7']
删除
-
del 列表[下标]
del list_name3[6] -
列表.pop(下标)
list_name3.pop(5)
修改
-
删除第一个匹配的元素 列表.remove(元素)
list_name3.remove('name5') -
清空列表 列表.clear()
list_name4.clear() -
统计某元素在列表内的数量 列表.count(元素)
list_name3.count('name2')
查询
统计列表内,有多少元素
语法:len(列表)
可以得到一个int数字,表示列表内的元素数量
print(len(list_name3)) # 结果是 4
需要注意的是,方法其实非常多,也不需要死记硬背,用的多的自然会记下来,我们只需要知道有这样一个方法即可,要用的时候,只需要查一下
循环遍历
-
while
index = 0 while index < len(列表): 元素 = 列表[index] 处理 idnex += 1这是列表一个简单的遍历,如果没有理解可以看一下之前流程控制的章节
-
for
for 临时变量 in 容器 处理这里与上面不同的是,临时变量可以直接使用,类似于while循环中的元素,也相对便利,了解C++的朋友也可以认为这是简化版的范围for,这在我介绍C++的迭代器的部分也有提及,感兴趣的朋友可以选择性阅读
tuple 元组
列表是可修改的,元组是不可修改的,同样的,也可以包含不同类型的元素
定义
定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型
tuple1 = (e1,e2,e3,...)
tuple2 = ()
tuple3 = tuple()
tuple4 = (e1,)
tuple5 = (e1)
tuple2和tuple3都是空元组,tuple4是只含一个元素的元组,需要注意的是当元组只有一个数据时,这个数据之后需要添加逗号,否则就不是元组类型,而是他本身的类型
操作
元组由于不可修改的特性,所以其操作方法非常少
| 方法 | 说明 |
|---|---|
| index() | 查找元组内数据,存在则返回下标,不存在则报错 |
| count() | 统计某个元素在元组内出现的次数 |
| len() | 统计元组内元素的个数 |
其余的特性除了修改元组内容基本上都和列表一样
str 字符串
对于字符串来说,他只是字符的容器,因此同样也支持下标的访问,他的内容也无法进行修改,我们只能对旧字符串操作之后得到新的字符串,原来的字符串是无法修改的
方法
查找下标
语法:字符串.index(字符串)
str1 = "rick and morty"
print(str1.index("and")) # 结果是5
替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串
str2 = str1.replace("and","or")
print(str2) # 结果是 rick or morty
分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
list1 = str1.split(' ')
print(list1) # 结果是 ['rick','and','morty']
去除前后空格
语法:字符串.strip()
str3 = " rick and morty "
str4 = str3.strip()
去除前后指定字符
语法:字符串.strip(字符串)
str5 = "_~rick and morty~_"
str6 = str5.strip("_~")
需要注意的是这里本质上是从传入的两个字符依次比较,删除相同的字符
统计字符串出现次数
语法:字符串.count(字符串)
count1 = str1.count('and')
统计字符串长度
语法:len(字符串)
len1 = len(str1)
序列的切片
序列
序列是指内容连续、有序,可以使用下标引用的一类数据容器,而列表、元组、字符串都是序列
序列的切片
这里切片的含义是从一个序列中取出一个子序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
步长表示,依次取元素的间隔
步长1表示,一个个取元素
步长2表示,每次跳过1个元素取
步长N表示,每次跳过N-1个元素取
步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
注意:此操作不会影响序列本身,而是会得到一个新的序列
例如
list1 = [1,2,3,4,5]
list2 = list1[1:4] # 从下标1开始取到4结束,前闭后开
这个操作对列表、元组、字符串是通用的
同时非常灵活,根据需求,起始位置,结束位置,步长(正反序)都是可以自行控制的
set 集合
集合的概念类似于数学上集合的定义,具有不重复,无序的特点
那我们其实可以利用这个特点做去重的工作
定义
set1 = {e1,e2,...}
set2 = set()
在定义集合时哪怕e1和e2相同,他也会自动帮你去重
方法
因为集合是无序的,所以集合不支持下标索引访问
添加
语法:集合.add(元素)。将指定元素,添加到集合内
set1 = {'e1','e2'}
set1.add('e3')
移除
语法:集合.remove(元素),将指定元素,从集合内移除
set1.remove('e2')
随机取出
语法:集合.pop(),功能,从集合中随机取出一个元素
elemment = set1.pop()
需要注意的是这个操作之后,集合本身也会被修改,元素被移除
清空
语法:集合.clear(),功能,清空集合
set1.clear()
差集
语法:集合1.difference(集合2)
set3 = set2.difference(set1)
结果是得到一个新集合,集合1和集合2不变
消除差集
语法:集合1.difference_update(集合2)
set1.difference_update(set2)
简单说就是在set1中消除set2中也有的元素
并集
语法:集合1.union(集合2)
set3 = set1.union(set2)
结果会得到新集合,集合1和集合2不变
其余的len()和遍历与其他容器相同
dict 字典
字典实际上就是类似于生活中的字典,是由键值对组成,键是指key,关键字的意思,值是值value
定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对
例如
dict1 = {key:val,key:val,...}
dict2 = dict()
dict3 = {}
key和value可以是任意类型的数据(key不可为字典)
key不可重复,重复会对原有数据覆盖
访问
字典同样是无序的,无法用下标访问,但是可以利用key来访问
例如
dict1 = {'Summer':17,'Morty':14,'Rick':60}
print(dict1['Morty']) # 结果是14
除此之外,字典是可以嵌套字典(列表等)的,放在value的地方,我们可以以此来理解之后的JSON数据,以后会讲到
方法
| 方法 | 说明 |
|---|---|
| dict1[‘Jerry’] = 36 | 添加元素,字典被修改 |
| dict1[‘Rick’] = 61 | 更新元素,字典被修改 |
| dict1.pop(‘Jerry’) | 删除元素 |
| dict1.clear() | 清空字典 |
| dict1.keys() | 获取全部的key |
| for key in dict1.keys() | 遍历字典 |
字典不支持下标索引,所以同样不可以用while循环遍历
总结
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | key : value key:除字典外任意类型 Value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以key检索value的数据记录场景 |
推导式
推导式其实可以理解为简易版的for循环,是Python独有的特性,它能够非常简洁的按照某种规则以一个序列推导出另一个新的序列,也可以理解为是切片的升级
列表推导式
列表的推导式非常简单
[生成表达式 for 变量 in 序列或迭代对象]
最外层的方括号表明生成结果为列表,在功能上,列表推导式相当于一个循环,只是形式更加简介
例如
list1 = [x**2 for x in range(4)]
前面我们讲过range的基本使用,这里的代码等效于下面的for循环,这里的**表示乘方
list1 = []
for x in range(4):
list1.append(x**2)
数据的过滤
在列表推导式中,我们可以使用if语句筛选符合条件的元素,例如我们想提取1到10中平方数为偶数的数
list2 = [x**2 for x in range(10) if (x**2)%2 == 0]
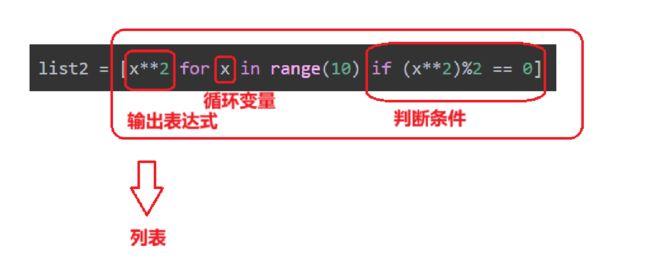
这里只演示了一层循环,实际上也支持两层循环,但是应用场景较少并且易读性不高,这里不过多介绍了
字典推导式
字典和集合不支持切片,推导式则极大的简化了其遍历的过程
字典推导式与列表推导式十分类似,是吧列表的标志从方括号变成了花括号
例如
dict1 = {'Summer':17, 'Morty':14, 'Rick':60}
dict2 = {v:k for k ,v in dict1.items()}
这里我们使用了字典的items()方法,它会返回一个支持遍历操作的列表,列表中是一个个小元组,例如[(‘Summer’,17),(‘Morty’,14),(‘Rick’,60)]
集合推导式
集合推导式与字典推导式及其类似,操作方法类似于列表,而且自带去重效果,例如
set1 = {x**2 for x in [1,2,3,4,1,-1]}
print(set1) # 结果是 1,4,9,16
函数进阶
多返回值
当在函数中想要返回多个返回值时,写多个return是行不通的,因为在执行第一个return的时候就会退出当前函数
def test_return():
return 1,2
x,y = test_return()
print(f"x={x},y={y}")
按照返回值的顺序,写对应顺序的多个变量接收即可
变量之间用逗号隔开
支持不同类型的数据return
函数的传参
位置参数
位置参数就是在调用函数时根据定义函数的参数位置来传递参数
def func(name,age,gender):
print(f"name={name},age={age},gender={gender}")
print(func("n",18,"male"))
需要注意的是传递的参数和定义的参数的顺序和个数必须要一致
关键字参数
在函数调用时通过“关键字=传入值”的形式进行参数的传递,可以不考虑参数传递的顺序
def func(name,age,gender):
print(f"name={name},age={age},gender={gender}")
print(func(age=18,gender="male",name='nn'))
需要注意的是,在关键字参数和位置参数混用的时候,位置参数必须在关键字参数的前面,关键字参数之间不存在先后顺序
缺省参数
也叫默认参数,为参数提供默认值,在调用时可以不传默认参数的值,要注意位置参数必须出现在默认参数之前,包括定义和调用
def func(name,gender,age=20):
print(f"name={name},age={age},gender={gender}")
print(func(gender="male",name='nn'))
函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值
不定长参数
也叫可变参数,用于不确定调用时可能传递多少个参数的场景,有两种类型
位置传递
def func(*args):
print(args)
func('aa')
func('aa',18)
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
关键字传参
def func(**kwargs):
print(kwargs)
fun(name='aa', age=18)
参数应当是以”键=值“的形式传入,并被kwargs接收保存为字典
函数式编程的高阶函数
函数作为参数传递
在之前的学习过程中,我们把各种数据作为参数传递,实际上函数也可以作为参数进行传递
例如
def add(x,y):
return x+y
def func(x,y,compute):
return compute(x,y)
print(func(1,2,add)) # 结果是3
在这个过程中,我们可以定义若干的关于x和y的操作函数,在调用时只需要调用func一个函数即可,只需要传入不同的函数名
lambda匿名函数
也叫lambda表达式,他的本质上是一个没有名称的函数,因此也只能临时使用一次
语法:
lambda 传入参数 : 函数体(一行)
lambda 是关键字,表示定义匿名函数,无法省略
例如
def func(x,y,compute):
return compute(x,y)
print(func(1,2,lambda x, y : x+y)) # 结果是3
这个函数的作用和上面的功能完全一致,只是lambda的函数是匿名的,无法二次使用
filter()函数
filter的意思是过滤器,他的函数的意思也是相同的
这个函数由两个参数,第一个function,意思是用于判断是否符合条件的函数,这个函数是你自己定义的,第二个是iterable意思是迭代对象(对象这个词我们后续会讲到,可以理解为object),实际上就是把序列中的每个元素依次传入function判断是否符合条件
这个函数的返回值是filter对象,因此不能直接使用,需要类型转换才能继续接下来的操作,例如
list1 = [1,2,3,4,5]
res1 = filter(lambda x: x % 2 == 0, list1)
print(type(res1)) # 结果是map()函数
函数是Python中的一个对象(object),而在map()函数中的第一个参数就是filter()函数。
map()函数会根据这个参数制定的规则将一个序列转换成另一个序列,那这样的两个序列中存在一一对应的关系,我们也将这样的关系称为映射(map)
他也可以理解为一个函数的操作,map中第一个参数,可以理解为数学中的函数,是对变量的操作,第二个以及以后的参数可以理解为这个数学中函数的变量,因此也可以传入多个序列
例如
def func(str):
return len(str)
res = map(func,('Summer','Morty','Rick'))
res = list(res)
print(res) # 结果是[6, 5, 4]
map与filter一样,返回值也是一个迭代器对象,我们也会详细介绍迭代器的用法,这里我们直接将其转化为list对象进行输出
对于多参数传递,例如传递两个列表,计算两个列表元素的和,map会按照位置进行相加,如果两个列表的元素个数不同,则会自动取长度小的列表为基准
reduce()函数
reduce的意思是减少或约定,这个函数会对序列中的元素按照规则进行减少,直到只有一个累计的数值
直接说概念理解上比较困难,这里我举出一个例子,大家就能快速理解了
from functools import reduce # 这里的操作我们以后再进行讲解,相当于导入reduce函数
res = reduce(lambda x, y: x+y, [1,2,3,4,5])
print(res) # 结果是15
lambda函数就是传入的函数,就是对这个序列进行的操作,通过结果大家可以猜出来这是用于计算列表元素和的一个过程,实际上细分过程就是,先取出前两个元素传入函数,之后每次取一个元素,带上前一次计算的结果,再次传入函数,直到结束
需要注意的是reduce的传入的函数必须是一个二元函数,他的返回值是最后计算的数值
sorted()函数
这是一个排序函数,实际上对于序列来说,他们本身就有排序的方法sort()
这个函数与之不同的地方就是他会产生一个新的序列,不会对原有序列产生影响
这个函数很好理解,我们主要讲两个参数,key和reverse
key是用于比较的函数,默认是从大到小排序,也可以自己写一个比较大小的函数,然后传入即可
reverse即为逆序输出,传入值是bool类型,True即为逆序,默认为False
例如,我们想按照绝对值进行排序
list1 = [1,2,3,-2,-1,9,-5]
list2 = sorted(list1,key=abs)
print(list2) # 结果是[1, -1, 2, -2, 3, -5, 9]
文件操作
文件编码
编码指的是把文字翻译成二级制的一个过程,有许多不同的对应规则,也就有许多不同的编码规范
例如,UTF-8,GBK,Big5,Unicode等
所谓乱码就是使用了错误的编码方式打开了文件的内容(大概),因此我们也可以选择编码的方式
目前UTF-8是全球通用的编码格式,一般来说文件内容都是UTF-8的
文件的打开
文件可以分为许多类别,在不同操作系统下文件的类型也不同,我们以常见的Windows系统为例,他以后缀名区分文件的类型,例如txt为文本文件,mp4为视频文件,exe为可执行文件等众多类别
对于文件的操作也有,打开,关闭,读写,执行等
我们以最简单的txt文本文件为例,对文件的操作就是,打开,读写,关闭
在Python中,我们使用open函数可以打开一个已经存在的文件,或者创建一个新的文件,语法如下
open(name,mode,encoding)
这里的name是文件名,mode是表示打开文件的方式即访问模式,对应着只读,写入,追加等,encoding表示文件的编码格式
例如
file = open('text1.txt','r',encoding='UTF-8')
这里需要注意的是,encoding的传参位置不是第三位,因此需要使用关键字传参
这里的file实际上是一个文件对象(object),对象是一种特殊的可以自定义的数据类型,在下一部分我们会进行详解
这里我们详细介绍一下mode的内容
mode有三种常用的基础访问模式
‘r’ 表示以只读的方式打开文件,也是默认的模式
‘w’ 表示以写入的方式打开文件,如果文件不存在则会创建新文件,如果文件已经存在,会从头开始写入,原来存在于文件中的内容将会清空
‘a’ 表示以追加方式打开文件,与’w’类似,只是如果文件存在,则会写入到原有内容之后
文件的读取
read() 方法
语法:文件对象.read(num)
num表示从文件中读取的数据的长度,可以不传入,默认读取所有数据
readlines() 方法
语法与read()类似,与之不同的是他将每一行作为列表的每一个元素进行读取,之后进行返回
例如
file = open("text.txt")
print(file.readlines())
# 结果是['Hello World!\n','你好,世界!']
file.close() # 关闭文件
readline() 方法
这里与上面不同的是只读取一行的内容,因此我们可以通过for循环对整个文件进行读取
文件关闭
close() 方法用于关闭文件,如果在文件使用完毕之后不关闭,他将会一直被占用
with open() 语法
with open("text.txt",'r') as f:
f.readlines()
print(f)
在这个代码块结束之后,文件会自动关闭,避免遗忘
文件写入
f = open('text.txt','w')
f.write('hello!')
f.flush()
f.close()
注意,在执行到write语句时,内容并没有真正全部写入到文件中,而是会积攒到程序的内存中,也称之为缓冲区,直到调用flush的时候,才会真正写入文件,因为频繁访问硬盘,会导致运行效率不高
文件追加
与文件写入基本一模一样,只需要对打开方式进行改变即可,同样调用write()方法
模块与包
模块的导入
可以说,Python的灵魂之一就是他丰富多样的库,这些就是他人已经写好的模块化的工具,使用者只需要调用,避免造轮子的工作,例如NumPy,Matplotlib等
模块在本质上来说就是一个Python文件
在使用之前,我们需要使用导入模块的语句
import 模块名 [as 别名] # 这里的方括号表示可选项
当你想使用这个模块中的函数时,只需要
模块名.函数名
即可
我们为了之后对模块的各个函数调用方便,可以取一个简单的别名,例如NumPy->np,Pandas->pd等
还有一种导入的方式是
from 模块 import *
这样是直接导入了模块中的所有函数,当然也可以将*替换成你想要的对象或者函数
这样在你使用他的时候就可以像Python自带的函数一样,不需要写模块名称了
编写自己的模块
对于C和C++抑或是Java等各式各样的语言,都有一个main函数作为所有程序的入口,但是对于Python来说,他对于一个Python文件就是从头到尾依次解释执行,没有统一的入口
但是模块也是一个Python文件,我们在导入之后,并不希望导入的函数依次被执行,因此在Python解释器中有一种内置变量,就是 __name__ 他的意思就是模块名,当你在这个Python文件内执行程序的时候他会自动被命名为__main__,但是当他被导入到别的Python文件中时,他就会变成模块的名称,我们可以以此进行区分
例如
# 模块 计算两个数的和 起名为Compute.py
def add(x,y):
return x+y
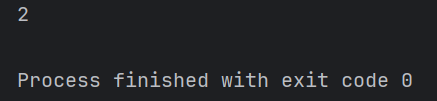
if __name__=='__main__':
print(add(1,1))
import Compute as cp
print(cp.add(1,2))

包
我们知道模块的本质就是一个Python文件,但是在自己创建模块的时候,只有在与执行的Python文件相同时,才能进行导入,但是当大量的模块都存在于一个文件夹时会显得十分臃肿,于是我们引入包的概念
包实际上就是一个文件夹,其中包含着许多的模块
例如我们打开一个包看看里面有什么
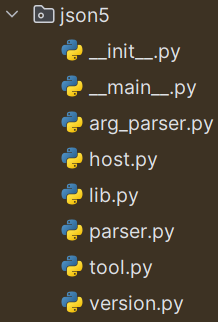
这是一个json5的一个包,之后我们也会讲到他的使用
这里有两个文件的名称与其他文件明显不同__init__.py和__main__.py
我们主要介绍__init__.py,通常他的文件内容为空,他的作用就是要告诉Python解释器,这个文件夹是一个包,相关的模块就在这个文件夹内
因此我们想创建包时,只需要创建一个文件夹和一个__init__.py文件即可,当然还需要将这个文件夹的路径配置到一个系统模块sys.path中,他的本质上就是一个列表,列表中的内容就是要告诉Python这里有一个模块可以用
那我们想要使用包中的模块的语法如下,例如json5的tool.py
import json5.tool
当然我们也可以在自己的Python文件夹中创建一个__init__.py文件,里面可以预先导入一些你想使用的包和模块,类似于C/C++中的头文件,他会自动执行
预告:目前的打算是先介绍Python的一些内建模和他们的基本使用,再讲解Python面向对象的内容,包括封装继承多态等特性,最后详细介绍NumPy,Pandas,Matplotlib,Pyecharts等内容,Python的基础内容就告一段落,之后进阶会打算做一些Python的高阶技巧,MySQL(数据库),PySpark(大数据计算),机器学习入门的相关内容其中MySQL和PySpark只是做简单使用介绍,会在之后出专门的内容进行详尽的讲解,敬请期待
面向对象
在C++面向过程与面向对象的章节里,我们介绍过面向过程关注的是做一件事情的需要的步骤有哪些,通过一系列函数之间的调用配合来实现解决问题,面向对象关注的是解决这一个问题参与的对象,依靠对象之间的交互来完成问题的解决
对于Python或者说很多的编程语言来说,面向对象已经是不可或缺的一部分了
对于Python来说,这个对象实际上指的是类(class),类中可以包含成员变量,成员方法,这都是属于同一个类的内容
类的定义和使用
我们可以用类去封装一系列的变量和函数,基于类去构造出对象来使用
类的定义语法
class 类名称:
成员变量
成员方法
这里的成员方法其实就是函数,但是在类的内部,我们统称为方法
类的创建(实例化)语法
对象名称 = 类名称()
在类定义的时候,实际上是不消耗内存空间的,因为并没有构建类的对象,他就像是一个设计图纸,并未造出实体,一旦我们创建类,或者是实例化一个类,就是产生了一个类的对象,就是消耗了内存的
例如,我们构建一个简单的学生类,定义一个方法让他做自我介绍
class student:
name = None
age = None
gender = None
def greeting(self):
print(f"我是{self.name},我是{self.gender}生,我今年{self.age}了")
这里出现了self关键字,稍后我们会介绍
对于这个类的使用,示例如下
stu = student()
stu.name = '莫蒂'
stu.age = 14
stu.gender = '男'
stu.greeting()
类似于对模块中的变量和方法的使用,我们也可以使用其中的方法
成员方法的定义
def 方法名(self,形参,...):
方法体
这里的self实际上是用来表示对象自身的意思,如果我们想在方法内调用类中的成员,就必须要通过self调用,在调用方法传参的时候,self是可以忽略的
构造方法
在上面我们可以看到,每次初始化成员变量的时候就要调用一个赋值语句,不够优雅,于是我们引入构造方法
例如
class student:
name = None
age = None
gender = None
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def greeting(self):
print(f"我是{self.name},我是{self.gender}生,我今年{self.age}了")
这样创建完构造方法之后,实际上在上面的变量声明就可以省略了,而这个构造方法会在构造对象时自动调用,自动传参
stu = student('莫蒂', 14, '男')
这样对类进行构造就十分方便了
其他内置方法
上文学习的__init__ 构造方法,是Python类内置的方法之一
这些内置的类方法,各自有各自特殊的功能,这些内置方法我们称之为:魔术方法
__str__ 字符串方法
这个方法实际上是一种对类转换成字符串的方法,一种主要的用途就是可以自定义输出的内容,直接调用str就会出现内存地址
例如
class student:
name = None
age = None
gender = None
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
stu = student('莫蒂', 14, '男')
print(stu)
print(str(stu))

class student:
name = None
age = None
gender = None
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
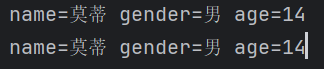
def __str__(self):
return f"name={self.name} gender={self.gender} age={self.age}"
stu = student('莫蒂', 14, '男')
print(stu)
print(str(stu))
__lt__ 小于符号比较
直接对两个类的比较大小是会出错的,我们可以构建这个魔术方法对类的大小进行定义,而且这个方法可以同时实现大于符号和小于符号的两种比较,类似于C++中的运算符重载
例如我们可以按照年龄大小进行比较
class student:
name = None
age = None
gender = None
def __lt__(self,other):
return self.age < other.age
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __str__(self):
return f"name={self.name} gender={self.gender} age={self.age}"
__le__ 小于等于比较 __eq__ 等于比较
这里和小于符合几乎一样,不过多赘述了
封装
面向对象的简单理解就是基于模板(类)去创建实体(对象),再通过对象进行功能的开发
对于面向对象来说,他有三大主要的特性,即为封装,继承,多态
封装的概念我们没有细讲,但是其实已经使用到了
我们将各种属性(成员变量),行为(成员方法)封装到一个类中,形成了一个类似于包裹的东西,可以调用其中的部分变量和方法
在实际中,我们构建出一个类,有些内容是不希望使用者(用户)能够访问到的,这也引申出了一个概念,私有成员
私有成员
我们可以用特定的形式来约定私有成员变量和私有成员方法
例如
class student:
name = None
age = None
gender = None
__id = None # 私有成员变量
def __func():
私有成员变量:变量名以__开头(2个下划线)
私有成员方法:方法名以__开头(2个下划线)
这样我们在类外就无法调用和使用私有成员了,但在成员方法内部依然可以使用
继承
之前的类的定义和使用似乎已经完美了,但是如果我们想要对类进行更新维护,添加新的功能,又不能失去原有的功能,似乎只有两种方法,一是复制粘贴重新写一个类,二是基于原来的类进行修改,但是又难以保证新写出的代码一定是完美的,尤其是当代码量及其庞大的时候,为了解决这个问题我们引入了继承这个概念
继承从字面意思来理解,就是从原有的类中,添加新的功能,那我们也称这个原有的类为父类或者基类
语法:
class 类名(父类名):
类内容
例如我们想构建一个手机类,再对这个手机类进行更新维护
class MyPhone_1:
ID = None
Producer = None
def CallBy4G(self):
print('4G')
class MyPhone_2(MyPhone_1):
FaceID = True
def CallBy5G:
print('5G')
这样我们就从MyPhone_1继承出了MyPhone_2
继承也分为单继承和多继承,也就是说,可以从不止一个父类那里继承来他的成员变量和成员方法,需要注意的是,私有成员不会被继承,在多继承中,如果声明有相同的变量名称,那么按照从左到右的顺序继承,先继承的保留,后继承的则不会保留
复写
我们说子类是对父类的更新,因此如果我们对父类的成员不满意,则可以对其进行复写,例如
class MyPhone_1:
ID = None
Producer = None
def CallBy4G(self):
print('4G')
class MyPhone_2(MyPhone_1):
FaceID = True
ID = 999
def CallBy4G:
print('4G+')
def CallBy5G:
print('5G')
一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员
如果需要使用被复写的父类的成员,需要特殊的调用方式
方法1
父类名.成员
class MyPhone_1:
ID = None
Producer = None
def CallBy4G(self):
print('4G')
class MyPhone_2(MyPhone_1):
FaceID = True
ID = 999
def CallByOld4G:
MyPhone_1.CallBy4G()
def CallBy4G:
print('4G+')
def CallBy5G:
print('5G')
方法2
super().成员
class MyPhone_1:
ID = None
Producer = None
def CallBy4G(self):
print('4G')
class MyPhone_2(MyPhone_1):
FaceID = True
ID = 999
def CallByOld4G:
super().CallBy4G()
def CallBy4G:
print('4G+')
def CallBy5G:
print('5G')
需要注意的是,只能在子类内调用父类的同名成员,如果使用对象调用则会直接调用复写的成员
类型注解
当我们在使用诸如PyCharm的工具中他会自动弹出代码补全,而我们我们自己写的类或函数则不会,这是为什么,实际上是因为我们自己写的变量,PyCharm不确定这个对象是什么类型,因此不会弹出代码补全
在Python3.5之后,都支持类型注解,可以提供类型的显示说明,方面代码提示
他可以作用于变量的类型注解,函数(方法)形参、返回值的类型注解
变量类型注解
语法如下 变量: 类型
age: int = 14
name: str = '莫蒂' # 变量的类型注解
class student:
pass
stu: student = student() # 类对象类型注解
list1: list = [1,2,3] # 容器类型注解
list2: list[int] = [1,2,3] # 容器详细注解
tuple1: tuple[str,int,bool] = ('a',1,True) # 元组需要将每一个元素都标记出来
dict1: dict[str,int] = {'a':1,'b':2} # 字典需要两个类型,一个代表key,一个代表val
在注释中进行类型注解也是符合语法的 # type: 类型
例如
age = 14 # type: int
需要注意的是,类型注解是提示性信息,并不是决定性的,即使错误也并不会进行报错
例如
age: int = 'aa'
函数(方发)类型注解
语法
def func(形参名: 类型, 形参名: 类型) -> 返回值类型:
pass
例如
def add(x: int, y: int) -> int:
return x+y
Union类型
这个实际上是用于定义联合类型注解的,例如
from typing import Union
dict2: dict[str, Union[str,int]] = {'a':1,'b':'b'}
这里表示的就是可能出现的类型,也很简单,在变量,函数注解中都可以使用
多态
多态指的是多种状态,即完成某个行为(调用某个函数),使用不同的对象会得到不同的状态(结果)
可以理解为,一个高级的ifelse语句
例如
class Animal:
def speak(self):
pass
class Dog(Animal): # 继承
def speak(self):
print('wang wang')
class Cat(Animal): # 继承
def speak(self):
print('miao miao')
def MakeNoise(anm: Animal): # 类型注解
anm.speak()
d = Dog()
c = Cat()
MakeNoise(d)
MakeNoise(c)
这个过程中Animal是父类,并没有实际的定义实际的内容,只是声明,他有两个子类Dog和Cat,他们是对功能进行实际的定义,最后通过第三方来调用,以达到传入不同的类能产生不同的结果
抽象类(接口)
在上面的不少代码中,我们都使用到了pass关键字,这里表示空实现,也可以对比理解为变量的None,这种写法就叫做抽象类(接口),与之对应的还有抽象方法
由此我们就可以只定义各类方法的标准,具体实现交给别的类,例如我们规定动物(父类)可以走,跑,跳,叫,吃(方法),但是不规定他们以何种形式,以何种工具实现这种功能,直到具体到某动物(子类)的时候,我们才能知道他的实现方式,例如猫是四条腿走路,鸵鸟是两条腿走路
生成器与迭代器
我们已经学习了Python的对象,其实在Python中的所有东西都可以认为是对象,因此,我们就可以用生成器(generator)和迭代器(iterator)做到
生成器
利用生成器表达式创建生成器
一个最简单的创建生成器的方法与我们之前学的推导式其实差不多,与之不同的是,利用推导式时,他会将所有符合条件的列表元素全部加载到内存中,一旦数据量十分大,例如百万量级,内存就会吃不消了
我们可以利用生成器表达式来创造一个生成器,实际上就是把推导式的方括号变成圆括号,例如
a = [x**2 for x in range(10) if x % 2 == 0]
print(a)
print(type(a))
b = (x**2 for x in range if x % 2 == 0)
print(b)
print(type(b))
print(list(b))
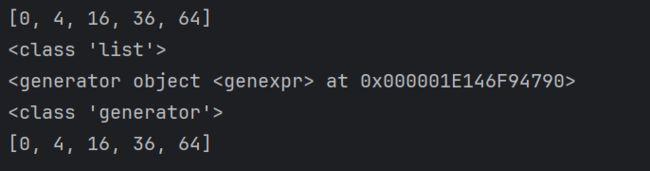
利用类型转换可以将生成器转换为列表进行输出,除此之外,我们还可以利用全局内置函数next(),他会从生成器的第一个元素开始,每次返回当前元素的值,并且自动指向下一个元素,直到输出最后一个元素,会抛出StopIteration的异常
当然,生成器内部也有内置函数__next__(),因此我们可以通过b.__next__()达到和next(b)一个效果
实际上使用的时候并没有这么复杂,直接使用for循环遍历即可,Python内部会自动确保不越界,因此也不会报错
例如
b = (x**2 for x in range(10) if x % 2 == 0)
for num in b:
print(num)

利用yield创建生成器
我们刚刚讲了类似于用列表推导式来构建生成器的方法,但是当构造的规则比较复杂的时候,就难以利用了
这里的yield,实际上是一种声明,他只能用于函数内部,表示这个函数是一个生成器,用法就是在给变量之前加一个标识,表示这是一个生成器对象,之后每次对这个变量时,就相当于给生成器插入值,这个函数的返回值就是生成器本身
这里示例一下,生成一个斐波那契数列
def func(t):
n, a, b = 0, 0, 1
while n < t:
yield b
a, b = b, a + b
n += 1
res = func(10)
for num in res:
print(num)

迭代器
迭代是访问集合元素的一种方式,迭代器就是用于迭代操作的多谢,他可以像列表一样迭代获取其中的每一个元素
可迭代对象
我们之前大略讲过,列表、元组、字典、集合、字符串,这些容器(container)就是可迭代对象,我们逐个访问,获取其中元素的过程就是迭代
例如
x = [1, 2, 3, 4]
it1 = iter(x)
print(next(it1))
print(next(it1))
print(next(it1))
print(next(it1))

这里我们只设置了一个迭代器it1,实际上我们也可以设置多个迭代器分别指向列表x,他们也是相互独立的,互不干扰
在这里我们可以用异常捕获来进行循环输出
例如
x = list[1, 2, 3, 4]
it1 = iter(x)
while True:
try:
print(next(it))
except StopIteration:
break
这里的 try 和 except 是用于捕获异常的结构,使用也比较简单,当没有发生异常的时候会执行try内的语句,except之后也可以不写异常的名称,写了就是发生特定异常才执行,不写就是发生任何异常都会执行之后的语句
Python的基础内容就到这里了,从下一篇开始我们会开始Python进阶的内容
json模块
json实际上是一种数据存储格式,是一种轻量级的数据交互格式,可以把他理解成一个特定格式的字符串以文件的形式存储起来
主要是在各个编程语言中交流的数据格式
从形式上看,json数据格式类似于Python的字典,列表,元组等数据容器
他长得像这样
{"name":"summer","age":18}
[{"name":"summer","age":18},{"name":"morty","age":14}]
我们可以利用一些工具将这些数据的格式层次显示清楚一点
在线JSON格式化工具
例如

当数据量巨大时,或者嵌套层数比较深的时候,这样的工具就比较方便了
json与Python数据的相互转化
import json # 导入json模块
data = [{"name":"summer","age":18},{"name":"morty","age":14}]
data = json.dumps(data)
data = json.loads(data)
dumps方法就是将python数据转化为json数据
loads方法是将json数据转化为python数据
pyecharts模块
我们可以使用pyecharts模块进行数据可视化,这个模块的使用相对比较简单,这里只做基础的介绍
echarts是由百度开源的数据可视化的模块,交互性良好,图表也很精良,pyecharts只是他支持的一个部分
首先我们需要在命令行或者PyCharm中安装pyecharts模块
pip install pyecharts
pyecharts官方文档
pyecharts基本操作
基础折线图
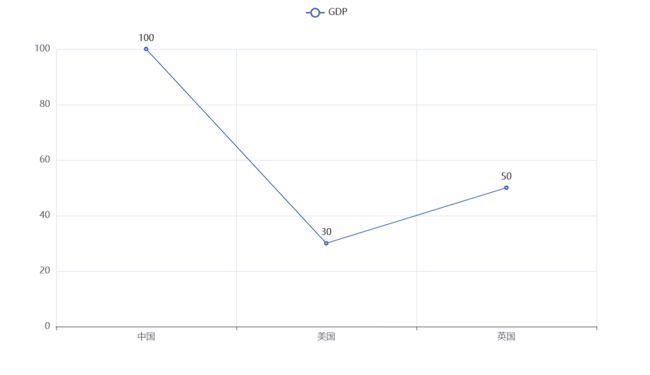
from pyecharts.charts import Line # 导入Line功能构建折现图
line = Line() # 得到折线图对象
line.add_xaxis(['中国','美国','英国']) # 构建x轴行标
line.add_yaxis('GDP',[100,30,50]) # 构建y轴列标与数据
line.render() # 生成图表
运行完成之后回生成一个render.html文件,用浏览器打开之后就是我们的图表
配置选项
在pyecharts模块中由很多的配置选项
全局配置选项
这里可以用set_global_opts可以配置许多的内容,例如标题、图例、颜色、工具箱等内容
之后我们对示例详细讲解
json模块的数据处理
这里我们有一段json数据,格式化之后如下图所示
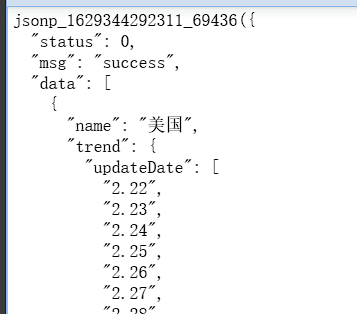
我们发现他除了数据内容,还包含了一串字符,在数据的末尾还有一个分号(未显示)
我们在把他转化成使用的元组、列表、字典时就需要对这个字符串进行处理
示例如下
import json
# 将json数据已经保存到data中
data = data.replace('jsonp_1629344292311_69436(','') #用空字符替换这一串
data = data[:-2] # 去除最后的括号和分号
这个数据量其实非常大,我们只展示了其中的一部分
折线图示例
import json
from pyecharts.charts import Line
import pyecharts.options as opts
这里我们先导入相关的配置项
file_us = open('C:/Users/Downloads/资料/可视化案例数据/折线图数据/美国.txt', encoding='UTF-8')
us_data = file_us.read()
第一行我们获取了一个文件对象,利用UTF-8格式读取了
再将文件对象读取到us_data中
us_data = us_data.replace('jsonp_1629344292311_69436(','')
us_data = us_data[:-2]
这里我们将开头和结尾进行处理,获得了一个标准的json字符串,也就是我们上图所表示的结构
us_dict = json.loads(us_data)
print(type(us_dict))
print(us_dict)
第一行我们将json字符串加载未python数据格式,通过结构我们可以知道这个结构最外层是字典,我们通过type()和print()验证

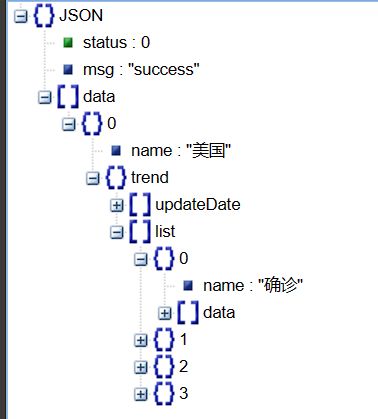
这个json包含了某国的疫情数据,由于数据嵌套比较深,我们先取到某国trend下的数据
trend_data = us_dict['data'][0]['trend']
print(type(trend_data ))
print(trend_data )
第一行是我们一路取数据的过程,再经过输出验证一下
这里我们再看看此时的结构
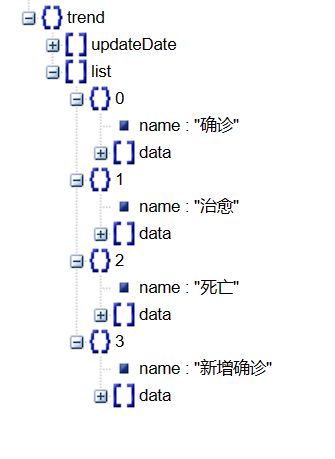
这里我们可以看到有两部分,一部分是更新日期,另一部分分别是数据,因此我们要取更新日期作x轴,为了表示简单,我们只取一列数据作为y轴
x_data = trend_data['updateDate'][:360]
y_data = trend_data['list'][0]['data'][:360]
这里我们就分别取出来了x轴和y轴的数据了,当然为了避免过多的数据挤在同一个表中,使用了切片减少数据
line = Line()
line.add_xaxis(x_data)
line.add_yaxis('确诊人数',y_data)
Line.render()
这里我们就创建了一个折线图对象,添加x轴y轴,将他生成
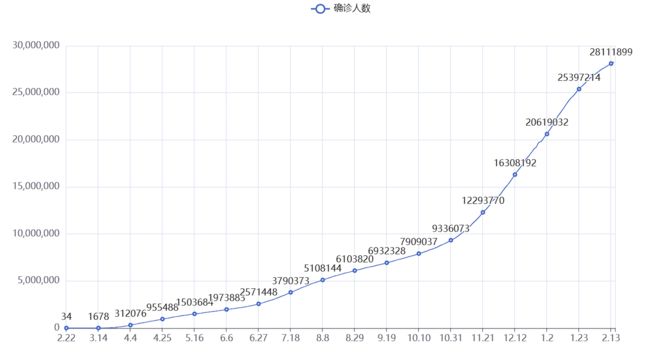
结果就像这样,如果我们有其他的y轴数据,继续添加y轴数据即可
line.set_global_opts(
title_opts=opts.TitleOpts(title='某国确诊人数折线图',pos_left='center',pos_bottom='1%')
)
这里是添加了一个标题的全局选项,只是做一个演示,具体的功能还有非常多,详情还请阅读官方文档
示例代码
import json
from pyecharts.charts import Line
import pyecharts.options as opts
file_us = open('C:/Users/Downloads/资料/可视化案例数据/折线图数据/美国.txt', encoding='UTF-8')
us_data = file_us.read()
us_data = us_data.replace('jsonp_1629344292311_69436(','')
us_data = us_data[:-2]
us_dict = json.loads(us_data)
# print(type(us_dict))
# print(us_dict)
trend_data = us_dict['data'][0]['trend']
# print(type(trend_data))
# print(trend_data)
x_data = trend_data['updateDate'][:360]
y_data = trend_data['list'][0]['data'][:360]
line = Line()
line.add_xaxis(x_data)
line.add_yaxis('确诊人数',y_data)
line.set_global_opts(
title_opts=opts.TitleOpts(title='某国确诊人数折线图',pos_left='center',pos_bottom='1%')
)
line.render()
file_us.close()
NumPy
NumPy介绍
在Python中有列表和数组模块,但是都不好用,列表的缺点是要保存每个对象的指针,如果你的列表有一百万个元素,他就有一百万个指针,而数组又只支持一维数组,并不适合数值运算
NumPy的模块支持数组和矩阵(向量)的运算,对机器学习算法比较友好,支持n维数组,有强大的数学运算对很多第三方库(SciPy,Pandas)都提供的底层支持
导入NumPy
首先要确保你的安装了NumPy库
pip install numpy
一般我们会给NumPy起别名为np
NumPy数组
序列生成数组
生成数组最简单的方法就是用array()方法,他可以接收任意类型的数据(列表、元组等)作为数据源
需要注意的是,如果各种数据的数据类型不统一,但是数据类型可以相互转换,就会进行自动转换,浮点数和整数都存在时,就会将整数自动转化成浮点数
每一个数组都可以利用dtype数据(ArrName.dtype)来输出数组中数据的类型,如果没有显示指定(ArrName.astype()),数组就会自动推断数据类型
例如
import numpy as np
print(np.__version__)
list1 = [1, 2, 2.5, 3, 4, 5]
arr1 = np.array(list1)
print(arr1.dtype)
arr1 = arr1.astype(int)
print(arr1.dtype)
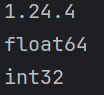
如果数据序列是嵌套的,而且嵌套序列是等长的,就会自动转换为高维数组,例如列表中有两个分别带有4个元素的子列表,数组就会自动变为两行四列的二维数组
函数生成数组
我们可以用arange()方法来生成数组,参数如下
arange(start, stop, step, dtype)
start与stop为起止位置,step为步长,区间为左闭右开,例如
arr3 = np.arange(1, 10, 2, int)
print(arr3)
![]()
对于数组的操作有一个是
arr3 = arr3 + 1
需要注意的是这个操作是给所有元素加1,但是这个1实际上是利用了“广播机制”,将1扩展为等长的数组,才能进行相加
range,arange,linspace
这里是三个函数,第一个是我们之前学习到的range,他的返回值本质上是一个可迭代对象,可以看作是一个迭代器,而且也有一定的局限性,例如步长只能是整数
第二个是用于创建数组的方法,步长可以是浮点数,而且他的底层其实是C语言,因此执行效率也会比较高,对于arange他的返回值就是数组对象本身了
第三个是也是用于创建数组的方法,他的好处是避免了每一次创建数组都要手动算一下步长,他的参数有三个,起始位置,停止位置,数据个数,例如
arr4 = np.linspace(1,10,20)
其他常用函数
| 方法 | 说明 | 示例 |
|---|---|---|
| zeros | 生成全零数组 | ze = zeros((2,3)) 生成两行三列0数组 |
| ones | 生成全一数组 | 与上面一样 |
| shape参数 | 描述轮廓 | one = np.ones(shape = [3, 4], dtype = float) |
| zeros_like | 结构和某数组一样的全零数组 | ze1 = zeros_like(ze) |
| ones_like | 结构和某数组一样的全一数组 | one = zeros_like(one) |
其余函数还有,empty_like、full_like,等等
N维数组的属性
我们首先要知道,内存的本质还是一维的,用狭隘的眼光来看他甚至只能从一个方向存储删除数据,因此我们所说的n维数组实际上是一个逻辑的结构,并非内存的真实结构
一个n维数组的本质就是用n个同类的数据容器来存储数据
我们可以用ndim输出数组的维度
arr1 = np.arange(1,10)
print(arr1.ndim)
同样的,我们也可以用shape查看数组的形状信息
print(arr1.shape)
我们也可以用reshape()方法来改变一维数组的形状信息,也就是重构或者说变形
arr1 = np.arange(1,10)
print(arr1.shape)
print(arr1)
arr2 = arr1.reshape(3,3)
print(arr2.shape)
print(arr2)

需要注意的是,三位数组的形状信息是分别对应着宽、高、长
NumPy数组的运算
向量运算
如果我们想求两个列表元素对应的和,我们可以使用for循环,列表推导式,也可以将他们转换为数组直接求和即可
import numpy as np
arr1 = np.arange(1,11)
arr2 = np.arange(11,21)
arr3 = arr1 + arr2
print(arr1)
print(arr2)
print(arr3)
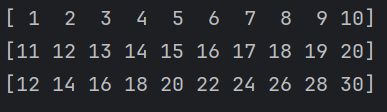
算数运算
NumPy有着强大的算数运算函数,只需要直接调用即可
如果要进行普通的数学运算,直接跟两个数字直接运算的方法一模一样,支持加减乘除取余乘方
注意,要操作数组的形状一致,除数不要为0就行
还有许多统计函数,例如
| 函数 | 说明 |
|---|---|
| sum | 求和 |
| min | 最小值 |
| max | 最大值 |
| median | 中位数 |
| mean | 平均数 |
| average | 加权平均数 |
| std | 标准差 |
| var | 方差 |
逐元素运算、点乘运算
N维数组实际上类似于矩阵,一般来说,加减乘除是元素对元素的运算
这里的乘法与矩阵乘法或是向量乘法不同,而是元素对元素的乘法
对于数学中的点乘操作NumPy也有对应的方法为dot(),也可以使用@符号替换乘法操作,意为点乘
例如
arr1 = np.arange(1, 10)
arr2 = np.arange(11, 20)
arr1 = arr1.reshape(3, 3)
arr2 = arr2.reshape(3, 3)
print(arr1*arr2)
print(arr1@arr2)
print(np.dot(arr1,arr2))
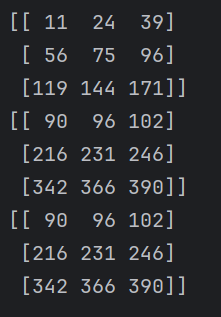
后两种符合的就是矩阵乘法的操作了
其他矩阵运算的函数
| 方法 | 说明 |
|---|---|
| a.I | 返回a的逆矩阵 |
| a.T | 返回a的转置矩阵 |
| a.A | 返回a对应的二维数组 |
操作数组元素
索引访问数组
索引是数组中元素所在的编号,类似于列表和C/C++中的数组,像一个指针一样对数组进行访问
一维数组二维数组的访问也是相同的,同样可以更改数组中的值
切片访问数组
与Python的列表一样,NumPy也可以使用切片访问和修改数据,我们可以批量获取符合要求的元素,提取出一个新的数组
例如
arr1 = np.arange(1,10)
sl = slice(2,9,2)
arr2 = arr1[sl]
print(arr2)
print(arr1)
这里的arr1表示原有数组,sl表示切片对象,是利用slice函数构造出来的,代表从2到9,步长为2,再对arr1切片得到arr2

也可以利用类似列表的切片方法arr2 = arr1[2:9:2]
转置与展平
我们可以通过transpose()方法将二维数组转置,也可以通过我们上面提到过的ArrName.T来进行转置
要将多维数组转化成一维数组,就要使用ravel()方法完成这个功能
例如
arr1 = np.arange(1,10)
arr1 = arr1.reshape(3,3)
print(arr1)
arr1 = arr1.T
print(arr1)
arr1 = arr1.ravel()
print(arr1)
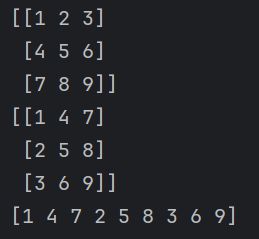
flatten()函数也可以进行展平操作,不同的是,flatten会重新分配内存,进行一次深拷贝,但是原数组并没有改变
NumPy的广播
实际上就是对两个数组进行加减乘除运算时,即便两个数组形状不同,NumPy会自动填充小数组中的元素来匹配大数组,这种机制也叫做广播(broadcasting),这个过程中需要的性能比较小,也无须关注实现细节
NumPy的高级索引
整数索引
这种索引的使用场景是为了补充之前的直接索引和切片索引,一旦我们想要访问的数据没有规律可循,但数据量比较大的时候,我们可以自行指定一个索引表进行访问
例如
import numpy as np
arr1 = np.arange(1,50)
index = [5,23,23,32,37,16]
print(arr1[index])
![]()
如果是二维数组,只需要写一个二维索引表即可
需要注意的是,我们也可以只访问行索引和列索引,行索引直接传入一维列表即可,列索引需要用冒号隔开,在冒号之后传入一维列表即为列索引
布尔索引
这里就类似于筛选的功能,符合条件(True)的数据就会被保留下来,不符合则会被过滤
例如
arr1 = np.arange(1,50)
index = [5,23,23,32,37,16]
arr1 = arr1[index]
print(arr1[arr1<30])
![]()
需要注意的是这里的arr1<30实际上就是利用了之前的广播,将30扩展成一个同样形状的数组,然后分别进行比较
数组的堆叠
这里的堆叠可以将数组理解成书,他分为三中,水平方向堆叠,类比两本书横向堆叠放,垂直方向堆叠,就是两本书纵向堆叠,深度方向堆叠就是一本书摞在另一本书上了
水平方向堆叠
hstack()这里的h表示水平,stack表示堆叠,需要注意的是,这个函数的参数是一个元组,元组内的元素可以是列表,数组等,返回结果是一个数组
例如
list1 = [[1,1,2],[3,4,4]]
list2 = [[2,3,3],[4,4,5]]
arr1 = np.hstack((list1,list2))
print(arr1)
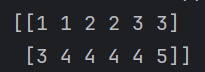
他是把两个元素的前两项叠在一起,后两项叠在一起,之后再组成一个数组
竖直方向堆叠
vstack() 例如
list1 = [[1,1,2],[3,4,4]]
list2 = [[2,3,3],[4,4,5]]
arr1 = np.vstack((list1,list2))
print(arr1)
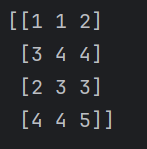
深度方向堆叠
dstack() 例如
list1 = [[1,1,2],[3,4,4]]
list2 = [[2,3,3],[4,4,5]]
arr1 = np.dstack((list1,list2))
print(arr1)
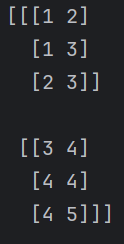
这里输出的就是一个三维数组了,相当于把两片纸堆叠在一起就有了高度
要注意元素之间的对应关系
行堆叠和列堆叠
这里就好理解很多了,因为上面的三个操作是在三维空间里的堆叠,而这里只是针对二维的数据
行堆叠 column_stack()
列堆叠 row_stack()
数组的分割
分割就是与堆叠的你操作,那也就分为水平分割,垂直分割,深度分割
分别用hsplit(),vsplit(),dsplit()实现
随机数
NumPy中含有随机数模块,random
随机数其实是由随机数种子根据一定规则计算出的数值,因此只要计算方法和种子一定,随机数就是不会变了,如果不设置随机种子,就会根据系统时间生成随机种子
例如
import numpy as np
rdm = np.random.RandomState(1)
np.random.seed(20231214) # 定义随机种子
# 生成两行三列的随机数组,服从均匀分布
rand = np.random.rand(2,3)
print(rand)
# 生成两行三列的随机数组,服从标准正态分布
randn = np.random.randn(2,3)
print(randn)
# 生成两行三列的1到10的随机整数
randint = np.random.randint(1,10,(2,3))
print(randint)
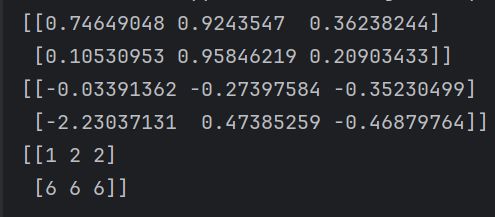
Pandas 数据分析
Pandas 简介
Pandas是Python生态下的一个数据分析包,他对于Python数据分析的意义是十分重大的,他与NumPy的不同之处是支持图标和混杂数据运算的,而NumPy是基于数组构建的内容,他的各种图像生成也十分方便,并且支持各种数据存储文件、数据库、甚至Web中读取数据
Pandas 安装
和NumPy的安装一样使用
pip install pandas
命令安装即可
Series 类型数据
Series是Pandas的核心数据结构之一,也是理解DataFrame的基础
Series的创建
Series的中文翻译是系列,是一种类似于一维数组的结构,是数组和索引构成的
import pandas as pd
pd.Series(data, index = index)
在这两个参数中,data是数据源,可以是整数,字符串等,而默认索引就是数据的标签(label)
例如
a = pd.Series([1, 2, 5, 3, 2])
print(a)

需要注意的是Series的内部是基于NumPy的N维数组构建的,因此内部的数据需要统一
其次Series增加对应的label作为索引,如果没有显示添加索引,Python会自动添加一个0到n-1的索引值,通常都是索引在左,数值在右边
当然,其中的索引也可以被更改为其他的内容,是类似于Python中的字典
Series还提供了一些简单的统计方法,describe()
例如
print(a.describe())

| 参数 | 说明 |
|---|---|
| count | 数据个数 |
| mean | 均值 |
| std | 均方差 |
| min | 最小值 |
| max | 最大值 |
| 25% | 前25%的数据分位数 |
| 50% | 前50%的数据分位数 |
| 75% | 前75%的数据分位数 |
Series的访问
第一种最简单的访问方式就是通过下标存取Series对象内部的元素
当然也可以用label进行访问
需要说明的是,可以按照任意顺序一次访问多个数据
例如
print(a[[1,2,3]])
需要说明的是,同时访问多个数值就需要以列表的形式出现
对于两个Series对象还可以通过append()方法进行叠加操作,用来合并对象
但是当叠加对象时,索引就会混乱,因此当叠加时可以采用ignore_index=True,这样就可以重新添加索引
例如
a1.append(a2,ignore_index=True)
Series 中向量化操作与布尔索引
类似于NumPy,Pandas也支持广播操作,也就是加减乘除一个标量,
同样的Series也支持用布尔表达式提取符合条件的数值,而且Series也可以作为NumPy函数的一个参数进行数据运算
Series的切片
对于Series也可以使用切片操作选取处理其中的值,返回值依然是Series的对象
需要注意的时,与数字的切片不同,用label切片不是左闭右开,而是两边都是闭区间
Series的缺失值
在数据处理中会遇到缺失值,在Pandas会用NaN来表示
我们可以使用Pandas中的isnull()和notnull()来检测是否含有缺失值
对于isull()方法,他的返回值是一个布尔值Series对象,True表示为缺失值,False表示不是缺失值,notnull正好与之相反
这对海量数据的操作是十分友好的
Series的增与删
当我们要删除Series中的数据时,使用drop方法即可,他的参数就是label,也可以是列表,用于删除多项元素
添加数据就可以使用我们之前所说的append方法即可
Series的name
除了index和value,还有两个属性,是name和index.name
name可以立即为数值(value)列的名称,index可以理解为一个特殊的索引列,index.name就是索引列(index)的名称,就相当于是列名的作用
默认情况下都被设置为None,我们也可以通过代码进行直接赋值
DataFrame 数据类型
如果Series是Excel中的一列,那DataFrame就是Excel中的一张表
DataFrame的创建
DataFrame实际上可以理解为数据结构中带标签的二维数组,他由若干个Series构成
构建DataFrame的最常用的方法是先构建一个由列表或NumPy数组组成的字典,再将字典作为DataFrame中的参数
例如
df = pd.DataFrame({'name':['summer','morty','rick','jerry']})
print(df)
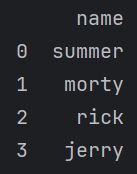
这样我们就可以用若干字典的项来构建一张表了,左边的数字就是行数
例如
df = pd.DataFrame({'name': ['summer', 'morty', 'rick', 'jerry'],
'age': [17 , 14, 60,35],
'gender': ['female', 'male', 'male', 'male']})
print(df)

我们也可以通过NumPy的数组生成DataFrame,我们也可以在创建DataFrame时指定列名和行名
例如
df2 = pd.DataFrame(data,columns=['one','two'],index=['a','b'])
本质上,DataFrame是由若干个Series构成的,那么Series就是DataFrame的天然数据源,同样的DataFrame也支持NumPy转置操作,也可以使用transpose()方法完成转置
DataFrame的访问
访问DataFrame的列很方便,因为DataFrame提供了columns属性,可以通过具体的列名称进行访问
例如
df.columns # 访问列名
df.columns.values[0] # 访问元素
DataFrame的一个神奇的地方在于,他可以把列明当作为对象中的一个元素进行获取
例如
df.列名
想要获取切片就和NumPy的数组操作时一模一样的,这里不多赘述
DataFrame的删除
类似于Series,删除操作也是使用drop方法删除一行或一列
我们也可以使用全局内置函数del,直接在DF中删除某行某列,因为drop方法是生成新的DF
DataFrame的添加
添加行
我们直接创建一个空的DF对象,再利用for循环逐个添加新的行即可
例如
df = pd.DataFrame(columns = ['1','2'])
for index in range(5):
df.loc[index] = ['name '+str(index)] + list(randint(10, size=2))
使用loc方法就可以添加一个新的行,index就是DF对象中原先没有的行索引,再进行赋值
我们还可以使用append方法,可以同时批量添加多行数据,类似于NumPy的vstack,垂直堆叠的效果
添加列
和添加行相比就更加简单,实际上就是添加了一个列的名称,再对其内容进行赋值,我们也可以使用concat方法,类似于hstack,水平堆叠,将两个DF对象进行拼接
对于以上两种添加方法,也可以设置忽略原有的索引,进行重新定义索引的编号
对于Pandas的操作指令还有非常多,我们需要在实践中不断掌握,慢慢摸索,越用越熟,越用越精
Pandas的文件读取与分析
Pandas是数据分析的重要工具,因此从外部读取数据的能力是十分重要的,常用的API如图
| 文件类型 | 文件说明 | 读取函数 | 写入函数 |
|---|---|---|---|
| CSV | 是以纯文本形式存储的,以逗号分隔的表格数据 | read_csv | to_csv |
| HDF | 是一种高效存储和分发科学数据的层级数据格式 | read_hdf | to_hdf |
| SQL | 是一种用格式化查询语言编写的数据库查询脚本文件 | read_sql | to_sql |
| JSON | 一种轻量级文本数据交换格式文件 | read_json | to_json |
| html | 一种由超文本标记语言编写的网页文件 | read_html | read_html |
| PICKLE | Python内部支持的一种序列化文件 | read_pickle | to_pickle |
利用Pandas读取文件
Pandas可以读取到表格类型数据,转换成DF类型的数据,然后通过DF进行数据分析,数据预处理等操作
对于Pandas来说他的核心在于数据分析,而不是进行读写
需要注意的是,读取文件的方法配置了大量的参数,更多内容还需要阅读Pandas的官方文档
DataFrame的常用属性
这里一般就是用于显示DF对象中的数据
| 属性 | 说明 |
|---|---|
| dtypes | 返回各个列的数据类型 |
| columns | 返回各个列的名称 |
| axes | 返回行标签和列标签 |
| ndim | 返回维度 |
| size | 返回元素个数 |
| shape | 返回一个元组,表示几行几列 |
| values | 返回以个存储DF数值的NumPy的数组 |
DataFrame的常用方法
| 方法 | 说明 |
|---|---|
| head([n])/tail([n]) | 前n行或者后n行数据,方括号表示可选参数 |
| describe() | 返回所有列的统计信息 |
| max()/min() | 返回所有列的最大值和最小值 |
| mean()/median() | 返回均值和中位数 |
| std() | 返回标准差 |
| sample([n]) | 从DF对象中随机抽取n个样本 |
| dropna() | 删除所有缺失值的数据 |
| count() | 对符合条件的记录计数 |
| value_counts() | 查看某列有多少不同值 |
| groupby() | 按照给定条件分组 |
DataFrame的条件过滤
和Series一样,我们可以通过布尔索引来提取DF的子集,过滤我们不需要的数据
DataFrame的切片操作
他的切片操作和NumPy二维数组的几乎一模一样,而且由于DF具有行标签和列标签,使他的切片操作更加方便了
DataFrame的排序操作
在DF中,我们可以根据某列或某几列对DF中的数据进行排序,默认升序
在sort_values方法中参数ascending为升序的意思,默认值为True
Pandas的聚合与分组运算
对数据分组并进行运算统计,是数据分析的重要环节
聚合
聚合是将多个数值按照某种规则聚合在一起,变成单个数据的转换过程
聚合的流程如下,先根据一个或多个键,拆分我们的Series或者DataFrame,然后根据每个数据块进行统计意义上的各种操作,例如平均值中位数等操作,还可以包含用户自定义的函数
我们可以通过agg方法来实施聚合操作,实际上其中的各个参数,才是其中的精华,通过设置参数,可以将函数作用在一个列或者多个列上
参数的函数名称是有官方提供的,以字符串形式出现,多个参数放在一个列表中即可
例如
df.列名.agg(['min','max','mean','median'])
我们就可以通过这种方式获取这一列的最小最大值,平均数与中位数了
需要注意的是,如果是自定义函数,就要直接给出函数名,而不应该传入字符串,同时也不需要括号
分组
groupby()是Pandas的一个高效的分组方法,可以通过各种名称,指标等内容对数据进行分组,再对其进行数据统计与分析
实际上如果我们单纯分组是没有什么意义的,分组的精髓就在于再次使用之前的统计方法,例如mean()、count()等
需要注意的是,我们如果想要获取分组之后的列数据,再将其合并,如果用双方括号,返回值就是DF对象,如果是单括号,返回值就是一个Series对象
例如
df.groupby(分组依据)[[列名]].mean()
df.groupby(分组依据)[列名].mean()
第一行就是返回值是一个DF对象,第二行则是Series对象
与之对应的,我们可以在分组之后再进行聚合运算,这样便能很方便的统计出对应数据的大量信息了
例如
df.groupby(分组依据)[列名].agg(['mean','std','skew'])
一般来说分组和聚合结合起来使用可以达到很好的效果
DataFrame还有许多其他的工具和特性,例如透视表,类SQL操作等如果想要系统学习还是需要各位通过官方文档,现用现查的方式
DataFrame中数据清洗方法
对于我们从巨大量级的互联网获取的数据,有很多都包含了不统一,不准确,有缺失的情况,因此我们在进行数据分析之前一定要进行数据清理
| 函数 | 说明 |
|---|---|
| isnull() | 存在缺失值返回True |
| notnull() | 不存在缺失值返回True |
| filna(0) | 给缺失值赋值,默认值为0 |
| dropna() | 存在缺失值,无条件删除 |
| dropna(how=‘nall’) | 一行或一列全是缺失值则删除 |
| dropna(axis=1,how=‘all’) | 当列方向全是缺失值则删除列 |
| dropna(axis=1,how=‘any’) | 列只要存在一个缺失值,删除列 |
| dropna(thresh=5) | 行的有效值低于5个时,删除行 |
Matplotlib与可视化分析
我们之前对数据的处理与分析,其实最终还是要利用可视化工具进行更加直观的输出
我们开业通过
pip install matplotlib
命令来安装对应的模块
简单图形的绘制
我们可以通过matplotlib的子模块pyplot来进行平面图像的绘制,比较便捷,而且输出格式也更加多样化
我们可以给他起个名字叫plt
例如
import math
import matplotlib.pyplot as plt
nbSamples = 256
xRange = (-math.pi, math.pi)
x, y = [], []
for n in range(nbSamples):
ratio = (n + 0.5) / nbSamples
x.append(xRange[0] + (xRange[1] - xRange[0]) * ratio)
y.append(math.sin(x[-1]))
plt.plot(x, y)
plt.show()
结果如下
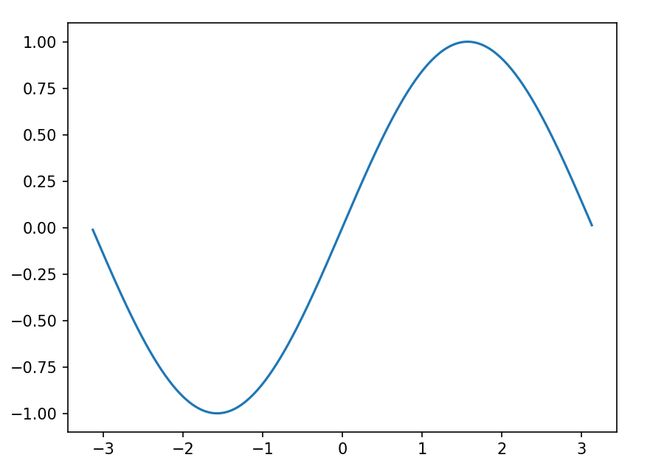
这里最复杂的其实是对x和y函数的构造,实际上关于绘图的代码是由最后两行完成的,plot是构建图像,show则是显示图像
对于各种复杂的数据计算和处理,实际上可以结合numpy的内容辅助处理
我们也可以对图像中线条的属性,例如color选项可以选择图像的颜色,linewidth可以选择线条的宽度,linestyle可以选择线条的样式
这里我们给出常用的颜色
| 字母 | 颜色 |
|---|---|
| r | 红色 |
| b | 蓝色 |
| m | 紫色 |
| k | 黑色 |
| g | 绿色 |
| c | 青色 |
| y | 土黄色 |
| w | 白色 |
pylot的高级功能
添加图例与注释
例如
nbSamples = 128
x = np.linspace(-np.pi, np.pi, nbSamples)
y1 = np.sin(x)
y2 = np.cos(x)
plt.plot(x, y1, color='g', linewidth=4, linestyle='--', label=r'$y=sin(x)')
plt.plot(x, y2, '*', markersize=8, markerfacecolor='r', markeredgecolor='k', label=r'$y=cos(x)')
plt.legend(loc='best')
plt.show()
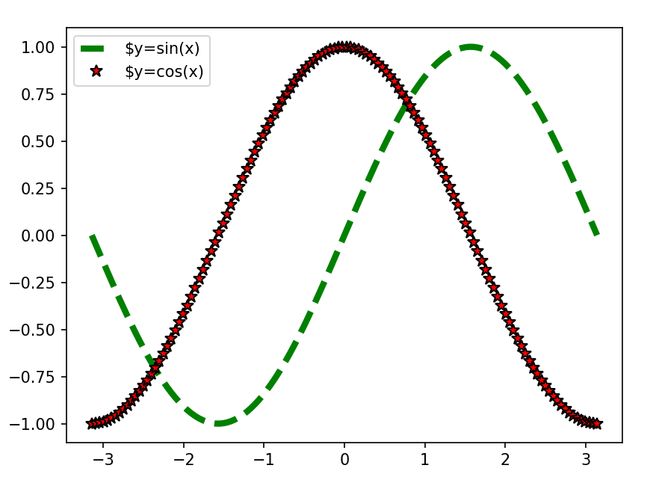
这里我们加入了属性标签,legend是放在了最佳位置,也可以进行设置,例如,upper right,upper left,lower left,center left 等
对于这里的美元符号则是对应着LaTeX公式,可以访问可以更加高效的描述数学公式
除此之外,我们也可以设置显示一些其他的文本提示,例如坐标提示等
例如
plt.text(a, b, (a, b), ha = 'center', va = 'bottom', fontsize = 10)
设置标题以及坐标轴
plt.title()
plt.xlabel()
Matplotlib对于中文支持并不友好,在Windows平台下,我们需要设置如下参数显示中文文本
plt.rcParams['font.sans-serif']=['SimHei'] # 用于正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 设置正常显示政府和
这里的sim指的是simple简体中文,hei表示黑体
关于众多子图的内容,还有更多的matplotlib内容,还请阅读官方文档,我们对于基本的图像绘制了解到此基本就足以日常使用了,如果需要更多的方法,官方文档绝对是一个更好的选择
我们的Python基础部分也告一段落,之后会陆续推出其他内容,还请大家继续支持