时序数据库入门 | 时序数据库的特点及与传统数据库的区别详解
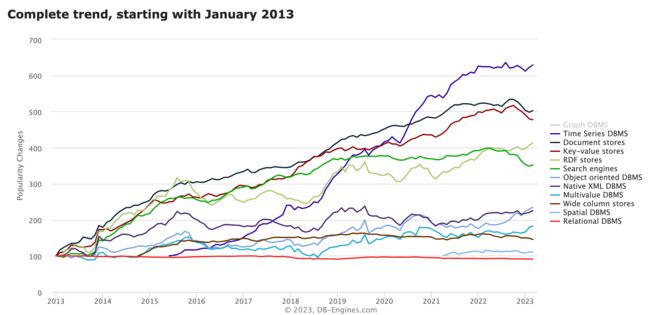
在过去的几年里,物联网(IoT)的日益普及和对实时数据的需求导致时序数据库(TSDB)的采用量大幅增长。根据 DB-Engines 的排名,TSDB 的普及率超过了其他任何类型的数据库,仅次于 Graph DBMS。
作为存储、管理和分析时序数据的重要工具,对时序数据库 (TSDB) 的需求在未来也很可能会持续上升。如果你对此还不太了解,本文将全面地介绍什么是时序数据库,以及为什么需要有针对时序数据的数据库。
什么是时序数据
谈到近年来时序数据库的普及,我们不得不先聊聊时序数据,为什么它需要一种专门优化的数据库来处理?通用的关系数据库不能满足吗?
所谓时序数据,非常通俗的角度来讲,就是一些随着时间变化而变化的值 (Value),同时这些值上面附带有一些 Key=Value 组成的标签。
一般包括下列三个属性(来自 Wikipedia):
时间线(Time series)
一个名称(通常称为指标,metric)和一系列 Key=Value 标签( Label,或者一般称之为 Tag)组成的唯一标识。
键值对(Timestamp, Value)
时间戳和值组成的键值对,并且按照时间戳自然排序,这些键值对一般称为采样(Sample)。
数值(Value)
第 2 点中的 Value 一般是数值,比如气温、湿度、CPU、内存占用等,但是也可能是任意的数据结构(结构化,非结构化都有可能)。
时序数据案例
举例来说,比如某天气网站截图的余杭 15 天的天气预报:

以最高气温和最低气温两条线来分析,这里的三个属性分别是:
时间线分别是:
a. 每日最高气温 + <地区=余杭>
b. 每日最低气温 + <地区=余杭>
最高气温的时间戳和 Value 组成的序列就是从 8/29 日开始到 09/06 日 15 个键值对,值是每日最高气温。最低气温类似。
这里 Value 就是气温,也就是数值,比如 8/29 最高气温是 36 摄氏度,最低气温是 25 摄氏度。
除了天气预报信息外,时序数据还广泛存在于以下领域:
股票价格:让股票分析师和交易者了解某一股票价格的趋势和走向。
健康监测:用于医学领域,以监测可能正在服用某些药物的病人的心率或其他健康数值。
工业及物联网的物理传感器:包括各类智能手机、智能汽车和智能家居等包含的各类温度、湿度、速度、加速度、方向和心率、血氧等传感器,制造业、医疗等业已大量使用的各类传感器,都在无时无刻地、按照固定或者不固定间隔产生海量的感知数据,主要用于设备和人体的日常和异常监测、基于这些海量数据挖掘的智能化应用(比如智能制造的产线优化、自动驾驶)等。
软件传感器:比如传统 DevOps 里的监控侵入式探针,云原生环境下的无侵入式探针(比如现在热火朝天的基于 eBPF 的无侵入探针方案和 Service Mesh 数据面探针),各类软件的各种指标埋点数据等,主要用途还是软件应用的日常和异常监控,保障业务服务的持续稳定运行,加上目前 AIOps 领域的发展,对于时序数据的使用规模和粒度也提出了更高要求。
时序数据的特点
数据是相对高频、稳定地产生,并且频率一般较为稳定,不随人们的昼夜活动周期而变化。传感器的种类众多,叠加上行业、地理位置的大量标签,数据和时间线的规模膨胀都极其庞大。并且这样的数据规模随着智能设备(可穿戴设备、智能汽车、智能制造)的普及以及人们对这些数据应用提出的更精细的需求而迅速增长。
数据的变更特征上是更类似 Append-Only 的方式,数据源源不断地添加上去, 更新的场景较少(但是仍然有,特别是弱网环境下的数据延迟),数据的删除通常是以过期时间为周期批量地删除。
数据应用上,最常见的还是日常和异常监控,基于这些数据搭建可视化监控报表和告警系统,其次是未来趋势的预测,也就是时序预测,特别是在金融领域
为什么时序数据如此重要
尽管时序数据并不是一种新的数据类型,但在过去的几年里,它的流行程度和使用量显著增加,正如 DB-Engines 所分析的那样。有几个因素不容忽视,包括:
互联网的发展和许多行业的数字化。直接导致了海量时序数据的产生,如网站流量、社交媒体活动和传感器读数等。
机器学习算法的发展。如递归神经网络(RNN)和长短期记忆(LSTM)网络,这些算法适用于时序数据分析,便于人们从这类数据中提取有价值的信息,使得时序数据有机会进一步产生价值。
预测性分析的兴起。这使得时序数据成为预测趋势和未来结果的重要工具。
金融、医疗和交通等领域的需求。这些领域对实时决策的需求越来越大,时序数据分析能够应对这些快速变化的情况。
什么是时序数据库
时序数据库(Time Series Database)如果按照 Wikipedia 的定义就是专门面向时序数据处理优化的数据库,它是领域数据库的一种,都是为了特定业务领域的数据处理服务,比如图数据库处理图的存储和检索,文档数据库用于半结构化的文档的存储和检索,搜索引擎专门用于非结构化文本的检索等。
时序数据库的特点
为了应对上述时序数据的特点和所涉及的挑战,TSDB 采用了一些技术。其中一些典型特征包括:
Log-Structured Merge-tree(LSM-tree)
LSM-tree 是一种基于磁盘的数据结构,为写入量较大的工作负载进行了优化,通过在一系列层次中合并和压缩数据,实现了高效的数据摄取和存储。与传统的 B-tree 相比,这减少了写入放大率,提供了更好的写入性能。
基于时间的分区
时序数据库通常基于时间间隔对数据进行分区,使查询更快速、更高效,也更容易保留和管理数据。这种方法有助于将最近的、经常访问的数据与较早的、不常访问的数据区隔开来,优化了存储和查询性能。
数据压缩
时序数据库采用各种压缩技术,如 delta 编码、Gorilla 压缩或字典编码,以减少存储空间需求。这些技术利用了时序数据中的时间和基于价值的模式,实现高效存储,同时又不丢失数据的保真度。
内置基于时间的函数和聚合
时序数据库对基于时间的函数的提供了本地支持,如移动平均数、百分比和基于时间的聚合。与传统数据库相比,这些内置功能使用户能够更有效地执行复杂的时间序列分析,并减少计算开销。
为什么要选择时序数据库
从以上这些介绍来看,我们对为什么需要时序数据库这一特定领域数据库也有了初步的答案。
针对时序数据的特征、规模和应用,时序数据库可以做出针对性的专门优化:存储采用定制型的压缩算法、存储格式采用面向时序海量写入和查询场景优化的行列混存格式;查询算子上针对时序引入更多时间窗口相关的函数、查询协议上面向时序模型优化;数据删除采用更灵活的过期策略等。
这些领域特定的专门优化,可以让时序数据库在领域能力、性能、成本、稳定性等维度上对比通用型数据库会有极大的优势。
总结
时序数据库已被广泛用于物联网(Internet of Things)、金融数据分析、监控和警报系统、能源管理、医疗保健应用以及其他对“时间”敏感的行业。通过使用时序数据库来对时序数据进行分析预测,企业可以从数据中获得有价值的信息,从而做出更明智的决策,获得独特的竞争优势。
然而,时序数据库跟关系数据库并非水火不容的关系,由于业务系统通常还在大量使用关系数据库,如何使得时序的数据和业务的数据能更方便、更好地结合,从而产生更大的业务价值,是时序数据库需要解决的问题之一。
关于 Greptime
Greptime 格睿科技于 2022 年创立,目前正在完善和打造时序数据库 GreptimeDB 和格睿云 GreptimeCloud 这两款产品。
GreptimeDB 是款用 Rust 语言编写的时序数据库。具有分布式,开源,云原生,兼容性强等特点,帮助企业实时读写、处理和分析时序数据的同时,降低长期存储的成本。
GreptimeCloud 基于开源的 GreptimeDB,为用户提供全托管的 DBaaS,以及与可观测性、物联网等领域结合的应用产品。利用云提供软件和服务,可以达到快速的自助开通和交付,标准化的运维支持,和更好的资源弹性。GreptimeCloud 已正式开放内测,欢迎关注公众号或官网了解最新动态!
官网:https://greptime.com/
公众号:GreptimeDB
GitHub: https://github.com/GreptimeTeam/greptimedb
文档:https://docs.greptime.com/
Twitter: https://twitter.com/Greptime
Slack: https://greptime.com/slack
LinkedIn: https://www.linkedin.com/company/gr