【机器学习】深度学习概论(一)
经典的机器学习算法与深度学习对比

一、机器学习面临的挑战

1.1 机器学习算法用于各种应用问题时所利用的典型特征

1.2 采用人工特征的机器学习算法处理流程

1.3 人工设计特征面临的问题

二、 深度学习技术
2.1 采用受限玻尔兹曼机和逐层训练的方法训练深层网络

2.2 自动编码器

2.3 训练有多个隐含层的自动编码器存在困难

2.4 AlexNet 网络

2.5 循环神经网络(Recurrent Neural Network,RNN)

2.6 解决深层神经网络梯度消失和退化以及局部最优解等问题

三、进展和典型应用
深度学习技术在机器视觉领域、语音识别、自然语言处理、数据挖掘、推荐系统、计算机图形学等方向的应用

3.1 计算机视觉



3.2 语音识别

3.3 自然语言处理

3.4 计算机图形学

3.5 推荐系统

3.6 深度强化学习


四、自动编码器(Autoencoder)

4.1 自动编码器简介


示例代码:用TensorFlow实现的一个简单的自动编码器模型,用于对MNIST数据集进行降维和可视化。
# 导入所需的库
import numpy as np # 用于科学计算
import matplotlib.pyplot as plt # 用于绘图
from tensorflow.keras.datasets import mnist # 用于加载MNIST数据集
from tensorflow.keras.models import Model # 用于构建模型
from tensorflow.keras.layers import Input, Dense # 用于定义层
# 加载MNIST数据集,它包含了6万张训练图像和1万张测试图像,每张图像是28*28的灰度图
#x_train是一个形状为(60000, 28, 28)的数组,表示有6万张训练图像,每张图像有28*28个像素值。y_train是一个形状为(60000,)的数组,表示有6万个训练标签,每个标签是一个0到9的整数。x_test和y_test的含义类似,只是它们的数量是1万而已。
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 将图像数据归一化到[0,1]区间,这样可以加快模型的收敛速度
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 将图像数据展平成一维向量,方便输入到全连接层
#-1表示自动计算该维度的大小,2828表示将每张图像展平成一个784维的向量
x_train = x_train.reshape(-1, 28*28)
x_test = x_test.reshape(-1, 28*28)
# 定义编码器的输入层和输出层,输入层的形状是(28*28,),输出层的形状是(2,),表示将784维的数据降维到2维,输出层使用了ReLU激活函数
input_img = Input(shape=(28*28,))
encoded = Dense(2, activation='relu')(input_img)
# 定义解码器的输入层和输出层,输入层的形状是(2,),输出层的形状是(28*28,),表示将2维的数据还原到784维,输出层使用了Sigmoid激活函数,使得输出值在[0,1]区间
decoded = Dense(28*28, activation='sigmoid')(encoded)
# 构建自动编码器模型,它由编码器和解码器组成,输入是图像数据,输出是重构后的图像数据
autoencoder = Model(input_img, decoded)
# 构建编码器模型,它只包含编码器部分,输入是图像数据,输出是编码后的数据
encoder = Model(input_img, encoded)
# 构建解码器模型,它只包含解码器部分,输入是编码后的数据,输出是重构后的图像数据
decoder_input = Input(shape=(2,))#解码器的输入层,它的形状是(2,),表示输入的数据是2维的向量,这是编码器的输出层的形状
decoder_layer = autoencoder.layers[-1] #获取了自动编码器模型的最后一层,它是一个全连接层,它的形状是(28*28,),表示输出的数据是784维的向量,这是原始图像数据的形状
decoder = Model(decoder_input, decoder_layer(decoder_input)) #构建了解码器模型,它的输入是解码器的输入层,它的输出是自动编码器的最后一层对输入层的计算结果。
# 编译自动编码器模型,使用Adam优化器和二元交叉熵损失函数
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 训练自动编码器模型,使用训练数据作为输入和输出,设置10个周期,每个批次256个样本,打乱数据顺序,使用测试数据作为验证数据
autoencoder.fit(x_train, x_train, epochs=10, batch_size=256, shuffle=True, validation_data=(x_test, x_test))
# 用编码器模型对测试数据进行编码,得到编码后的数据,它的形状是(10000, 2),表示有1万个样本,每个样本有2个特征
encoded_imgs = encoder.predict(x_test)
# 用解码器模型对编码后的数据进行解码,得到重构后的图像数据,它的形状是(10000, 28*28),表示有1万个样本,每个样本有784个像素值
decoded_imgs = decoder.predict(encoded_imgs)
# 绘制原始图像和重构图像,比较它们的相似度
n = 10 # 显示的图像数量
plt.figure(figsize=(20, 4))# 大小为20英寸宽,4英寸高
for i in range(n):
# 显示原始图像,它是28*28的灰度图
ax = plt.subplot(2, n, i + 1)#第一行第i+1列
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()#设置图像的颜色为灰度
ax.get_xaxis().set_visible(False)#隐藏子图的x轴
ax.get_yaxis().set_visible(False)
# 显示重构图像,它是28*28的灰度图
ax = plt.subplot(2, n, i + 1 + n)# 第二行第i+1列
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
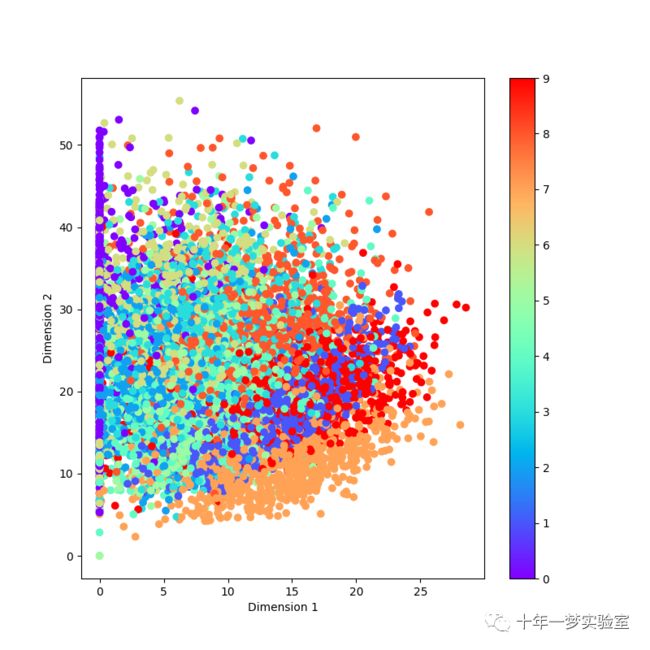
# 绘制编码后的数据的散点图,用不同的颜色表示不同的类别,观察它们的分布情况
plt.figure(figsize=(8, 8))
#绘制散点图,横坐标是编码后的数据的第一维,纵坐标是编码后的数据的第二维,颜色是测试数据的标签,颜色映射是彩虹色
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test, cmap='rainbow')
plt.colorbar()#添加一个颜色条,显示不同的颜色对应的数字类别
plt.xlabel('Dimension 1')#设置横坐标的标签
plt.ylabel('Dimension 2')
plt.show()输出结果:
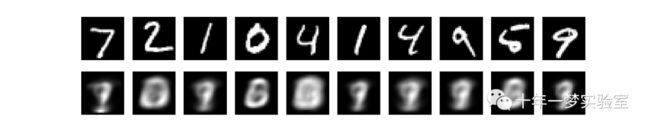
测试集中前10个原始图像和重建图像
4.2 去噪编码器(Denoising Autoencoder)

示例代码:
#去噪自编码器是一种神经网络,它可以从带有噪声的图像中恢复出原始的清晰图像。
# 用带噪声的图像作为输入,用原始的图像作为输出,让网络学习如何去除噪声
# 导入keras的相关模块
import os
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.callbacks import TensorBoard
from keras.datasets import mnist
# 导入numpy和matplotlib的相关模块
import numpy as np
import matplotlib.pyplot as plt
# 加载mnist数据集,只使用图像数据,不使用标签数据
(x_train, _), (x_test, _) = mnist.load_data()
# 将图像数据转换为浮点型,并归一化到[0,1]区间
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# 将图像数据调整为四维张量,第一维是样本数,后三维是图像的高、宽、通道数
# 一个四维的numpy数组,存储了训练集的图像数据,每个图像的形状为(28, 28, 1)
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
# 定义噪声因子,用于在图像数据中添加随机噪声
noise_factor = 0.5
# 在训练集和测试集中添加正态分布的随机噪声
# np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)是一个numpy函数,用于生成一个与x_train形状相同的随机数组,每个元素都服从均值为0,标准差为1的正态分布
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
# 将噪声数据裁剪到[0,1]区间 添加噪声后,图像的像素值可能会超出 0 到 1 的范围,这会影响网络的性能。
# 所以,我们需要用 np.clip 函数来将像素值限制在 0 到 1 之间,保证输入的合法性。
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# 定义要显示的图像数量
n = 10
# 创建一个大小为(20, 2)的图形窗口
plt.figure(figsize=(20, 2))
# 循环显示测试集中的噪声图像
for i in range(n):
# 创建一个子图,位置为第一行第i+1列
ax = plt.subplot(1, n, i + 1)
# 显示第i个噪声图像,将其调整为28*28的灰度图
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
# 隐藏子图的坐标轴
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示图形窗口
plt.show()
# 定义输入图像的形状,为(28, 28, 1)
input_img = Input(shape=(28, 28, 1))
# 定义编码器部分,使用卷积层和最大池化层实现特征提取和降维
x = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img) # (28, 28, 32)
x = MaxPooling2D((2, 2), padding='same')(x) # (14, 14, 32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) # (14, 14, 32)
encoded = MaxPooling2D((2, 2), padding='same')(x) # (7, 7, 32)
# 定义解码器部分,使用卷积层和上采样层实现特征还原和升维
x = Conv2D(32, (3, 3), activation='relu', padding='same')(encoded) # (7, 7, 32)
x = UpSampling2D((2, 2))(x) # (14, 14, 32)
x = Conv2D(32, (3, 3), activation='relu', padding='same')(x) # (14, 14, 32)
x = UpSampling2D((2, 2))(x) # (28, 28, 32)
# 使用卷积层输出重建的图像,激活函数为sigmoid,保证输出值在[0,1]区间
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
# 定义自动编码器模型,输入为噪声图像,输出为重建图像
autoencoder = Model(input_img, decoded)
# 编译自动编码器模型,优化器为adadelta,损失函数为二元交叉熵
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
logdir = os.path.join(os.getcwd(), 'my_logs')
# 训练自动编码器模型,输入为噪声图像,输出为原始图像
autoencoder.fit(x_train_noisy, x_train,
epochs=100, # 迭代次数为100
batch_size=128, # 批次大小为128
shuffle=True, # 每次迭代前打乱数据
validation_data=(x_test_noisy, x_test), # 使用测试集作为验证集
callbacks=[TensorBoard(log_dir=logdir, histogram_freq=0, write_graph=False)]) # 使用TensorBoard回调函数记录训练过程
# 使用自动编码器模型对测试集中的噪声图像进行预测,得到重建图像
decoded_imgs = autoencoder.predict(x_test_noisy)
# 定义要显示的图像数量
n = 10
# 创建一个大小为(20, 4)的图形窗口
plt.figure(figsize=(20, 4))
# 循环显示测试集中的噪声图像和重建图像
for i in range(n):
# 显示噪声图像,位置为第一行第i+1列
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示重建图像,位置为第二行第i+1列
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示图形窗口
plt.show()
测试集中前10个噪声图像

测试集中前10噪声图像和重建图像
4.3 稀疏自动编码器(Sparse Autoencoder)

示例代码(pytorch):
# 导入 torch 模块,用于构建和训练神经网络
import torch
# 导入 torch.nn 模块,用于定义神经网络的层和损失函数
import torch.nn as nn
# 导入 torch.nn.functional 模块,用于实现一些常用的激活函数和其他函数
import torch.nn.functional
# 导入 torch.optim 模块,用于实现优化算法
import torch.optim as optim
# 导入 torch.utils.data.dataloader 模块,用于加载和处理数据
import torch.utils.data.dataloader as dataloader
# 导入 torchvision 模块,用于处理图像数据
import torchvision
# 导入 torchvision.datasets 模块,用于获取一些常用的数据集
import torchvision.datasets as datasets
# 导入 torchvision.transforms 模块,用于对图像数据进行一些变换
import torchvision.transforms as transforms
# 导入 common.datas 模块,用于获取 MNIST 数据集的加载器
from common.datas import get_mnist_loader
# 导入 os 模块,用于操作系统相关的功能
import os
# 导入 time 模块,用于获取时间相关的信息
import time
# 导入 matplotlib.pyplot 模块,用于绘制图形
import matplotlib.pyplot as plt
# 导入 PIL.Image 模块,用于处理图像
from PIL import Image
# 定义一些超参数
batch_size = 100 # 批次大小,即每次训练的数据量
num_epochs = 50 # 训练的轮数,即所有数据训练的次数
in_dim = 784 # 输入维度,即图像的像素数,28*28=784
hidden_size = 30 # 隐藏层维度,即隐藏层神经元的个数
expect_tho = 0.05 # 期望的平均激活值,用于稀疏性约束
def KL_devergence(p, q):
"""
计算两个分布的 KL 散度
:param p: 期望的分布
:param q: 实际的分布
:return: KL 散度
"""
# 编码器激活函数是relu,输出没有限制在0~1
# 对 q 这个张量进行 softmax 函数的运算,使得 q 的每个元素缩放到 (0, 1) 区间且和为 1
q = torch.nn.functional.softmax(q, dim=0) # 对 q 进行 softmax 归一化,使其和为 1
q = torch.sum(q, dim=0)/batch_size # 对 q 的第一维求和,即将第 j 个神经元在 batch_size 个输入下的所有输出取平均
s1 = torch.sum(p*torch.log(p/q)) # 计算 p 和 q 的交叉熵
s2 = torch.sum((1-p)*torch.log((1-p)/(1-q))) # 计算 1-p 和 1-q 的交叉熵
return s1+s2 # 返回 KL 散度
# 定义一个自编码器类,继承自 nn.Module
class AutoEncoder(nn.Module):
def __init__(self, in_dim=784, hidden_size=30, out_dim=784): # 定义类的初始化方法,接受输入维度、隐藏层维度和输出维度作为参数
super(AutoEncoder, self).__init__() # 调用父类的初始化方法
self.encoder = nn.Sequential( # 定义编码器,即将输入数据压缩为隐藏层表示的部分
nn.Linear(in_features=in_dim, out_features=hidden_size), # 定义一个全连接层,将输入维度映射为隐藏层维度
nn.ReLU() # 定义一个 ReLU 激活函数,增加非线性
)
self.decoder = nn.Sequential( # 定义解码器,即将隐藏层表示恢复为输出数据的部分
nn.Linear(in_features=hidden_size, out_features=out_dim), # 定义一个全连接层,将隐藏层维度映射为输出维度
nn.Sigmoid() # 定义一个 Sigmoid 激活函数,将输出限制在 0 到 1 之间,因为图像的像素值在 0 到 1 之间
)
def forward(self, x): # 定义类的前向传播方法,接受输入数据 x 作为参数
encoder_out = self.encoder(x) # 调用编码器,得到隐藏层表示
decoder_out = self.decoder(encoder_out) # 调用解码器,得到输出数据
return encoder_out, decoder_out # 返回隐藏层表示和输出数据
train_loader, test_loader = get_mnist_loader(batch_size=batch_size, shuffle=True) # 调用 get_mnist_loader 函数,获取 MNIST 数据集的训练集和测试集的加载器
autoEncoder = AutoEncoder(in_dim=in_dim, hidden_size=hidden_size, out_dim=in_dim) # 创建一个自编码器对象,传入输入维度、隐藏层维度和输出维度作为参数
if torch.cuda.is_available(): # 判断是否有 GPU 可用
autoEncoder.cuda() # 将模型放到 GPU 上,因此后续传入的数据必须也在 GPU 上
Loss = nn.BCELoss() # 定义损失函数,使用二元交叉熵损失,用于衡量输出数据和输入数据的差异
Optimizer = optim.Adam(autoEncoder.parameters(), lr=0.001) # 定义优化器,使用 Adam 算法,传入自编码器的参数和学习率作为参数
# 定义期望平均激活值和 KL 散度的权重
#用于计算隐藏层神经元的平均激活值和期望的平均激活值之间的 KL 散度,从而增加稀疏性的约束。
# 期望的平均激活值是一个很小的值,比如 0.05,表示我们希望隐藏层神经元的激活值的平均值接近于这个值,
# 这样可以使得隐藏层神经元只有少数的激活,而大多数的抑制,从而提取输入数据的重要特征
tho_tensor = torch.FloatTensor([expect_tho for _ in range(hidden_size)]) # 创建一个张量,存储期望的平均激活值,大小为隐藏层维度
if torch.cuda.is_available(): # 判断是否有 GPU 可用
tho_tensor = tho_tensor.cuda() # 将张量放到 GPU 上
_beta = 3 # 定义 KL 散度的权重,用于控制稀疏性的程度
# def kl_1(p, q):
# p = torch.nn.functional.softmax(p, dim=-1)
# _kl = torch.sum(p*(torch.log_softmax(p,dim=-1)) - torch.nn.functional.log_softmax(q, dim=-1),1)
# return torch.mean(_kl)
for epoch in range(num_epochs): # 对所有数据进行 num_epochs 轮训练
time_epoch_start = time.time() # 记录每轮训练的开始时间
#enumerate 是一个内置函数,它可以将一个可迭代的对象转换为一个枚举对象,即在每个元素前面加上一个计数值,从 0 开始。这样可以方便地获取每个元素的索引和值。
# MNIST 数据集 train_data 的数据维度应该是 (batch_size, 1, 28, 28),其中 batch_size 是您设置的每次训练的数据量,1 是图像的通道数,28 是图像的高度和宽度
for batch_index, (train_data, train_label) in enumerate(train_loader): # 对训练集的每个批次进行迭代,获取批次索引、数据和标签
if torch.cuda.is_available(): # 判断是否有 GPU 可用
train_data = train_data.cuda() # 将数据放到 GPU 上
train_label = train_label.cuda() # 将标签放到 GPU 上
input_data = train_data.view(train_data.size(0), -1) # 将 train_data 的每个图像数据转换为一个一维的向量,大小为 784
# train_data.size(0) 是一个整数,表示 train_data 的第一维的大小,即批次大小,即每次训练的数据量
# view 是一个 torch 模块提供的函数,用于改变张量的形状,即维度和大小
# input_data 的形状应该是 (batch_size, 784),其中 batch_size 是 train_data 的第一维的大小,784 是 train_data 的其他三维的乘积,即 1×28×28
encoder_out, decoder_out = autoEncoder(input_data) # 调用自编码器的前向传播方法,得到隐藏层表示和输出数据
loss = Loss(decoder_out, input_data) # 计算损失函数,比较输出数据和输入数据的差异
# 计算并增加 KL 散度到损失
_kl = KL_devergence(tho_tensor, encoder_out) # 调用 KL_devergence 函数,计算期望的分布和实际的分布的 KL 散度
loss += _beta * _kl # 将 KL 散度乘以权重后加到损失上,增加稀疏性的约束
Optimizer.zero_grad() # 清空优化器的梯度
loss.backward() # 调用损失的反向传播方法,计算梯度
Optimizer.step() # 调用优化器的更新最后几行输出:
Epoch: 50, Loss: 3.8174, Time: 6.95
Epoch: 50, Loss: 3.8174, Time: 6.97
Epoch: 50, Loss: 3.8171, Time: 6.98
Epoch: 50, Loss: 3.8215, Time: 6.99
Epoch: 50, Loss: 3.8229, Time: 7.004.4 收缩自动编码器(Contractive Autoencoder )

示例代码(pytorch)
# 导入所需的库
import os
import argparse
import torch
import torch.utils.data
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchvision import datasets, transforms
# import pdb
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
# 设置CUDA设备的顺序和可见性
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" # see issue #152
os.environ["CUDA_VISIBLE_DEVICES"]="1"
# 打印导入成功的信息
print("Imported all libraries successfully!")
# 创建一个解析器对象,用于处理命令行参数
parser = argparse.ArgumentParser(description='PyTorch MNIST Example for CAE')
# 添加各种参数,包括批量大小,训练轮数,是否使用CUDA,随机种子,日志间隔等
parser.add_argument('--batch-size', type=int, default=128, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--epochs', type=int, default=19, metavar='N',
help='number of epochs to train (default: 2)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='enables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
# 解析参数并赋值给args对象
args = parser.parse_args()
# 判断是否使用CUDA
args.cuda = not args.no_cuda and torch.cuda.is_available()
# 设置随机种子
torch.manual_seed(args.seed)
# 如果使用CUDA,设置CUDA的随机种子
if args.cuda:
torch.cuda.manual_seed(args.seed)
# 设置数据加载器的参数,如果使用CUDA,设置num_workers和pin_memory
kwargs = {'num_workers': 5, 'pin_memory': True} if args.cuda else {}
# 创建训练数据加载器,使用MNIST数据集,将图片转换为张量
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.ToTensor()),
batch_size=args.batch_size, shuffle=True, **kwargs)
# 创建测试数据加载器,使用MNIST数据集,将图片转换为张量
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.ToTensor()),
batch_size=args.batch_size, shuffle=True, **kwargs)
# 设置收缩损失的系数
lam = 1e-4
# 定义一个收缩自编码器(CAE)的类,继承自nn.Module
class CAE(nn.Module):
def __init__(self):
super(CAE, self).__init__()
self.fc1 = nn.Linear(784, 400, bias = False) # 编码器
self.fc2 = nn.Linear(400, 784, bias = False) # 解码器
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def encoder(self, x):
h1 = self.relu(self.fc1(x.view(-1, 784))) # 将输入图片展平为784维向量,然后通过全连接层和激活函数得到400维的隐层向量
return h1
def decoder(self,z):
h2 = self.sigmoid(self.fc2(z)) # 将隐层向量通过全连接层和激活函数得到784维的重构向量
return h2
def forward(self, x):
h1 = self.encoder(x) # 编码过程
h2 = self.decoder(h1) # 解码过程
return h1, h2 # 返回隐层向量和重构向量
# 将重构的图片按网格排列并保存,用于检查质量和进度
def samples_write(self, x, epoch):
_, samples = self.forward(x) # 得到重构向量
#pdb.set_trace()
samples = samples.data.cpu().numpy()[:16] # 将重构向量转换为numpy数组,并取前16个
fig = plt.figure(figsize=(4, 4)) # 创建一个4x4的画布
gs = gridspec.GridSpec(4, 4) # 创建一个4x4的网格
gs.update(wspace=0.05, hspace=0.05) # 设置网格间距
for i, sample in enumerate(samples): # 遍历每个重构向量
ax = plt.subplot(gs[i]) # 在对应的子图上绘制
plt.axis('off') # 关闭坐标轴
ax.set_xticklabels([]) # 设置x轴刻度为空
ax.set_yticklabels([]) # 设置y轴刻度为空
ax.set_aspect('equal') # 设置等比例缩放
plt.imshow(sample.reshape(28, 28), cmap='Greys_r') # 将重构向量还原为28x28的图片,并以灰度显示
if not os.path.exists('out/'): # 如果输出文件夹不存在,创建一个
os.makedirs('out/')
plt.savefig('out/{}.png'.format(str(epoch).zfill(3)), bbox_inches='tight') # 保存图片,文件名为训练轮数,用0补齐
#self.c += 1
plt.close(fig) # 关闭画布
# 定义均方误差损失函数,不取平均
mse_loss = nn.BCELoss(size_average = False)
# 定义总损失函数,包括均方误差和收缩损失
def loss_function(W, x, recons_x, h, lam):
mse = mse_loss(recons_x, x) # 计算重构向量和输入向量的均方误差
# Since: W is shape of N_hidden x N. So, we do not need to transpose it as
# opposed to #1
dh = h * (1 - h) # 计算隐层向量的导数,得到N_batch x N_hidden的矩阵
# Sum through the input dimension to improve efficiency, as suggested in #1
w_sum = torch.sum(Variable(W)**2, dim=1) # 计算全连接层的权重矩阵的平方和,得到N_hidden维的向量
# unsqueeze to avoid issues with torch.mv
w_sum = w_sum.unsqueeze(1) # 将向量扩展为N_hidden x 1的矩阵
contractive_loss = torch.sum(torch.mm(dh**2, w_sum), 0) # 计算收缩损失,即隐层向量导数的平方与权重平方和的乘积的和
return mse + contractive_loss.mul_(lam) # 返回总损失,即均方误差加上收缩损失乘以系数
# 创建一个CAE模型的实例
model = CAE()
# 创建一个优化器,使用Adam算法,学习率为0.0001
optimizer = optim.Adam(model.parameters(), lr = 0.0001)
# 如果使用CUDA,将模型转移到GPU上
if args.cuda:
model.cuda()
# 定义一个训练函数,接受训练轮数作为参数
def train(epoch):
model.train() # 将模型设置为训练模式
train_loss = 0 # 初始化训练损失为0
# 遍历训练数据加载器,得到每个批次的数据和标签(标签在这里不需要)
for idx, (data, _) in enumerate(train_loader):
data = Variable(data) # 将数据转换为变量
if args.cuda:
data = data.cuda() # 如果使用CUDA,将数据转移到GPU上
optimizer.zero_grad() # 清空优化器的梯度缓存
hidden_representation, recons_x = model(data) # 将数据输入模型,得到隐层向量和重构向量
# 获取权重矩阵
# model.state_dict().keys()
# 根据手动查看的键名修改
# (将来我会尝试自动化这个过程)
W = model.state_dict()['fc1.weight'] # 获取编码器的权重矩阵
loss = loss_function(W, data.view(-1, 784), recons_x,
hidden_representation, lam) # 计算总损失函数
loss.backward() # 反向传播,计算梯度
train_loss += loss.data[0] # 累加训练损失
optimizer.step() # 更新参数
# 如果达到日志间隔,打印训练信息
if idx % args.log_interval == 0:
print('Train epoch: {} [{}/{}({:.0f}%)]\t Loss: {:.6f}'.format(
epoch, idx*len(data), len(train_loader.dataset),
100*idx/len(train_loader),
loss.data[0]/len(data)))
# 打印每轮训练的平均损失
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(train_loader.dataset)))
# 调用模型的方法,将重构的图片保存
model.samples_write(data,epoch)
# 遍历训练轮数,调用训练函数
for epoch in range(args.epochs):
train(epoch)out目录输出:

4.5 卷积自动编码器(Convolutional Autoencoder)
卷积自编码器(Convolutional Autoencoder)是一种利用卷积神经网络(Convolutional Neural Network, CNN)来实现自编码器功能的深度学习模型,它可以对输入的图像数据进行有效的编码和解码,从而实现图像的降维、去噪、重构等任务。卷积自编码器的结构由两部分组成:卷积编码器(Convolutional Encoder)和卷积解码器(Convolutional Decoder)。卷积编码器使用多个卷积层和池化层(Pooling Layer)来逐渐减小图像的尺寸,提取图像的高级特征,并输出一个压缩的隐层表示。卷积解码器使用多个卷积层和上采样层(Upsampling Layer)来逐渐增大图像的尺寸,恢复图像的细节,并输出一个重构的图像。
示例代码(keras):
# 导入所需的模块和库
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D # 导入 Keras 中的层模块
from keras.models import Model # 导入 Keras 中的模型模块
from keras.callbacks import TensorBoard # 导入 Keras 中的回调模块,用于可视化训练过程
from keras.datasets import mnist # 导入 Keras 中的数据集模块,用于加载 MNIST 数据集
from keras import backend as K # 导入 Keras 中的后端模块,用于处理张量运算
import numpy as np # 导入 NumPy 库,用于处理数组运算
import matplotlib.pyplot as plt # 导入 Matplotlib 库,用于绘制图像
# 定义输入图像的形状,即 (28, 28, 1),表示高度为 28,宽度为 28,通道数为 1 的灰度图像
input_img = Input(shape=(28, 28, 1))
# 定义编码器部分,即将输入图像压缩为一个低维的向量
x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_img) # 使用 16 个 3×3 的卷积核对输入图像进行卷积操作,激活函数为 ReLU,填充方式为 same,保持输出图像的大小不变,即 (28, 28, 16)
x = MaxPooling2D((2, 2), padding='same')(x) # 使用 2×2 的池化核对卷积后的图像进行最大池化操作,填充方式为 same,将输出图像的大小减半,即 (14, 14, 16)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) # 使用 8 个 3×3 的卷积核对池化后的图像进行卷积操作,激活函数为 ReLU,填充方式为 same,保持输出图像的大小不变,即 (14, 14, 8)
x = MaxPooling2D((2, 2), padding='same')(x) # 使用 2×2 的池化核对卷积后的图像进行最大池化操作,填充方式为 same,将输出图像的大小减半,即 (7, 7, 8)
x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) # 使用 8 个 3×3 的卷积核对池化后的图像进行卷积操作,激活函数为 ReLU,填充方式为 same,保持输出图像的大小不变,即 (7, 7, 8)
encoded = MaxPooling2D((2, 2), padding='same')(x) # 使用 2×2 的池化核对卷积后的图像进行最大池化操作,填充方式为 same,将输出图像的大小减半,即 (4, 4, 8),这就是编码后的向量,共有 128 个元素
# 在这一点上,表示是 (4, 4, 8),即 128 维
# 定义解码器部分,即将编码后的向量还原为原始的输入图像
x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded) # 使用 8 个 3×3 的卷积核对编码后的向量进行卷积操作,激活函数为 ReLU,填充方式为 same,保持输出图像的大小不变,即 (4, 4, 8)
x = UpSampling2D((2, 2))(x) # 使用 2×2 的上采样核对卷积后的图像进行上采样操作,将输出图像的大小增加一倍,即 (8, 8, 8)
x = Conv2D(16, (3, 3), activation='relu', padding='same')(x) # 使用 16 个 3×3 的卷积核对上采样后的图像进行卷积操作,激活函数为 ReLU,填充方式为 same,保持输出图像的大小不变,即 (8, 8, 8)
x = UpSampling2D((2, 2))(x) # 使用 2×2 的上采样核对卷积后的图像进行上采样操作,将输出图像的大小增加一倍,即 (16, 16, 8)
x = Conv2D(16, (3, 3), activation='relu')(x) # 使用 16 个 3×3 的卷积核对上采样后的图像进行卷积操作,激活函数为 ReLU,填充方式为 valid,将输出图像的大小减少 2,即 (14, 14, 8)
x = UpSampling2D((2, 2))(x) # 使用 2×2 的上采样核对卷积后的图像进行上采样操作,将输出图像的大小增加一倍,即 (28, 28, 8)
decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) # 使用 1 个 3×3 的卷积核对上采样后的图像进行卷积操作,激活函数为 sigmoid,填充方式为 same,保持输出图像的大小不变,即 (28, 28, 1),这就是解码后的图像,与输入图像的形状相同
# 定义自编码器模型,即将输入图像和解码后的图像连接起来
autoencoder = Model(input_img, decoded)
# 编译自编码器模型,使用 adadelta 优化器和loss='binary_crossentropy' 二元交叉熵损失函数
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
# 定义编码器模型,即将输入图像和编码后的向量连接起来
encoder = Model(input_img, encoded)
# 从 MNIST 数据集中加载训练数据和测试数据,只需要图像数据,不需要标签数据
(x_train, _), (x_test, _) = mnist.load_data()
# 将图像数据转换为浮点类型,并归一化到 [0, 1] 区间
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
# 将图像数据调整为 (28, 28, 1) 的形状,以适应输入图像的形状
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
# 训练自编码器模型,使用训练数据作为输入和输出,设置迭代次数为 50,批次大小为 128,打乱数据顺序,使用测试数据作为验证数据,使用 TensorBoard 回调函数来可视化训练过程,将日志文件保存在 conv_autoencoder 目录下
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test),
callbacks=[TensorBoard(log_dir='./conv_autoencoder')])
# 使用编码器模型对测试数据进行编码,得到编码后的向量
encoded_imgs = encoder.predict(x_test)
# 使用自编码器模型对测试数据进行解码,得到解码后的图像
decoded_imgs = autoencoder.predict(x_test)
# 设置要显示的图像的个数,这里为 10 个
n = 10
# 创建一个新的图形窗口,设置大小为 (20, 4)
plt.figure(figsize=(20, 4))
# 循环遍历每个图像
for i in range(n):
# 显示原始图像
# 创建一个子图,位置为第 i + 1 个,共有 2 行 n 列
ax = plt.subplot(2, n, i + 1)
# 将测试数据中的第 i 个图像从 (28, 28, 1) 的形状还原为 (28, 28) 的形状,并显示出来
plt.imshow(x_test[i].reshape(28, 28))
# 设置为灰度模式
plt.gray()
# 隐藏 x 轴和 y 轴的刻度
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示重建图像
# 创建一个子图,位置为第 i + 1 + n 个,共有 2 行 n 列
ax = plt.subplot(2, n, i + 1 + n)
# 将解码数据中的第 i 个图像从 (28, 28, 1) 的形状还原为 (28, 28) 的形状,并显示出来
plt.imshow(decoded_imgs[i].reshape(28, 28))
# 设置为灰度模式
plt.gray()
# 隐藏 x 轴和 y 轴的刻度
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示图形窗口
plt.show()
# 创建一个新的图形窗口,设置大小为 (20, 8)
plt.figure(figsize=(20, 8))
# 循环遍历每个图像
for i in range(n):
# 显示编码向量
# 创建一个子图,位置为第 i + 1 个,共有 1 行 n 列
ax = plt.subplot(1, n, i + 1)
# 将编码数据中的第 i 个向量从 (4, 4, 8) 的形状还原为 (4, 32) 的形状,并转置为 (32, 4) 的形状,然后显示出来
plt.imshow(encoded_imgs[i].reshape(4, 4 * 8).T)
# 设置为灰度模式
plt.gray()
# 隐藏 x 轴和 y 轴的刻度
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 显示图形窗口
plt.show()输出结果:


4.5 多层编码器-层叠自动编码器(Stacked_AutoEncoder-SAE)



示例代码-SAE 层叠自动编码器(pytorch)
models.py
# 导入所需的库,包括torch,torchvision,time和os
import torch
from torch import nn, optim, functional, utils
import torchvision
from torchvision import datasets, utils
import time, os
# 定义一个自编码器层的类,继承自nn.Module
class AutoEncoderLayer(nn.Module):
"""
fully-connected linear layers for stacked autoencoders.
This module can automatically be trained when training each layer is enabled
Yes, this is much like the simplest auto-encoder
"""
# 定义初始化方法,接受输入维度,输出维度和是否进行逐层预训练的参数
def __init__(self, input_dim=None, output_dim=None, SelfTraining=False):
super(AutoEncoderLayer, self).__init__() # 调用父类的初始化方法
# if input_dim is None or output_dim is None:
# raise ValueError
self.in_features = input_dim # 保存输入维度
self.out_features = output_dim # 保存输出维度
self.is_training_self = SelfTraining # 指示是否进行逐层预训练,还是训练整个网络
# 定义编码器,使用全连接层和Sigmoid激活函数
self.encoder = nn.Sequential(
nn.Linear(self.in_features, self.out_features, bias=True),
nn.Sigmoid() # 统一使用Sigmoid激活
)
# 定义解码器,使用全连接层和Sigmoid激活函数
self.decoder = nn.Sequential( # 此处decoder不使用encoder的转置, 并使用Sigmoid进行激活.
nn.Linear(self.out_features, self.in_features, bias=True),
nn.Sigmoid()
)
# 定义前向传播方法,接受输入x
def forward(self, x):
out = self.encoder(x) # 将x通过编码器得到隐层向量
if self.is_training_self: # 如果是逐层预训练,返回解码器的输出
return self.decoder(out)
else: # 否则,返回隐层向量
return out
# 定义一个方法,锁定该层的梯度,即不更新参数
def lock_grad(self):
for param in self.parameters():
param.requires_grad = False
# 定义一个方法,解锁该层的梯度,即更新参数
def acquire_grad(self):
for param in self.parameters():
param.requires_grad = True
# 定义一个属性,返回输入维度
@property
def input_dim(self):
return self.in_features
# 定义一个属性,返回输出维度
@property
def output_dim(self):
return self.out_features
# 定义一个属性,返回是否进行逐层预训练的标志
@property
def is_training_layer(self):
return self.is_training_self
# 定义一个属性的设置方法,接受一个布尔值,设置是否进行逐层预训练的标志
@is_training_layer.setter
def is_training_layer(self, other: bool):
self.is_training_self = other
# 定义一个栈式自编码器的类,继承自nn.Module
class StackedAutoEncoder(nn.Module):
"""
Construct the whole network with layers_list
> 栈式自编码器的架构一般是关于中间隐层对称的
"""
# 定义初始化方法,接受一个自编码器层的列表作为参数
def __init__(self, layers_list=None):
super(StackedAutoEncoder, self).__init__() # 调用父类的初始化方法
self.layers_list = layers_list # 保存自编码器层的列表
self.initialize() # 调用初始化方法,将所有层的逐层预训练标志设为False
# 将列表中的四个自编码器层分别命名为encoder_1, encoder_2, encoder_3, encoder_4
self.encoder_1 = self.layers_list[0]
self.encoder_2 = self.layers_list[1]
self.encoder_3 = self.layers_list[2]
self.encoder_4 = self.layers_list[3]
# 定义一个初始化方法,将所有层的逐层预训练标志设为False
def initialize(self):
for layer in self.layers_list:
# assert isinstance(layer, AutoEncoderLayer)
layer.is_training_layer = False
# for param in layer.parameters():
# param.requires_grad = True
# 定义前向传播方法,接受输入x
def forward(self, x):
out = x # 将x赋值给out
# 遍历自编码器层的列表,将out依次通过每一层
# for layer in self.layers_list:
# out = layer(out)
# 也可以直接使用命名的四个自编码器层
out = self.encoder_1(out)
out = self.encoder_2(out)
out = self.encoder_3(out)
out = self.encoder_4(out)
return out # 返回最终的输出run.py
# 导入系统库
import sys
# 将上一级目录添加到系统路径中,以便导入其他模块
sys.path.append('../')
# 从common.datas模块中导入get_mnist_loader函数,用于获取MNIST数据集的加载器
#from common.datas import get_mnist_loader
# 从models模块中导入AutoEncoderLayer和StackedAutoEncoder类,分别用于定义自编码器层和栈式自编码器模型
from models import AutoEncoderLayer, StackedAutoEncoder
# 导入torch库,用于构建和训练神经网络
import torch
# 从torch.nn模块中导入BCELoss类,用于计算二元交叉熵损失函数
from torch.nn import BCELoss
# 从torch模块中导入optim子模块,用于优化神经网络的参数
from torch import optim
# 导入torchvision库,用于处理图像数据
import torchvision
# 从torchvision.datasets模块中导入MNIST类,用于获取MNIST数据集
from torchvision.datasets import MNIST
# 定义一些超参数,包括逐层预训练的轮数,整体训练的轮数,批量大小,是否打乱数据等
num_tranin_layer_epochs = 20
num_tranin_whole_epochs = 50
batch_size = 100
shuffle = True
# 定义一个函数,用于获取MNIST数据集的加载器,接受批量大小和是否打乱数据的参数
def get_mnist_loader(batch_size=100, shuffle=True):
"""
:return: train_loader, test_loader
"""
# 创建一个训练数据集的对象,指定数据集的根目录,是否为训练集,是否进行图像转换(转换为张量),是否下载数据集
train_dataset = MNIST(root='../data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
# 创建一个测试数据集的对象,指定数据集的根目录,是否为训练集,是否进行图像转换(转换为张量),是否下载数据集
test_dataset = MNIST(root='../data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# 创建一个训练数据加载器的对象,指定数据集,批量大小,是否打乱数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=shuffle)
# 创建一个测试数据加载器的对象,指定数据集,批量大小,是否打乱数据
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=shuffle)
# 返回训练数据加载器和测试数据加载器
return train_loader, test_loader
# 定义一个函数,用于训练自编码器层,接受自编码器层的列表,要训练的层的索引,训练轮数,是否验证等参数
def train_layers(layers_list=None, layer=None, epoch=None, validate=True):
# 如果GPU可用,将所有层转移到GPU上
if torch.cuda.is_available():
for model in layers_list:
model.cuda()
# 调用get_mnist_loader函数,获取训练数据和测试数据的加载器
train_loader, test_loader = get_mnist_loader(batch_size=batch_size, shuffle=True)
# 创建一个优化器,使用SGD算法,学习率为0.001,优化要训练的层的参数
optimizer = optim.SGD(layers_list[layer].parameters(), lr=0.001)
# 创建一个损失函数,使用二元交叉熵损失函数
criterion = BCELoss()
# 训练
# 遍历训练轮数
for epoch_index in range(epoch):
# 初始化总损失为0
sum_loss = 0.
# 如果要训练的层不是第0层,将前面的层的梯度锁定,并将逐层预训练的标志设为False
if layer != 0:
for index in range(layer):
layers_list[index].lock_grad()
layers_list[index].is_training_layer = False
# 遍历训练数据加载器,得到每个批次的数据和标签(标签在这里不需要)
for batch_index, (train_data, _) in enumerate(train_loader):
# 如果GPU可用,将数据转移到GPU上
if torch.cuda.is_available():
train_data = train_data.cuda()
# 将数据展平为一维向量
out = train_data.view(train_data.size(0), -1)
# 如果要训练的层不是第0层,将数据依次通过前面的层,得到该层的输入
if layer != 0:
for l in range(layer):
out = layers_list[l](out)
# 训练第layer层,将输入通过该层,得到输出
pred = layers_list[layer](out)
# 清空优化器的梯度缓存
optimizer.zero_grad()
# 计算输出和输入的二元交叉熵损失
loss = criterion(pred, out)
# 累加总损失
sum_loss += loss
# 反向传播,计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 如果达到日志间隔,打印训练信息
if (batch_index + 1) % 10 == 0:
print("Train Layer: {}, Epoch: {}/{}, Iter: {}/{}, Loss: {:.4f}".format(
layer, (epoch_index + 1), epoch, (batch_index + 1), len(train_loader), loss
))
# 如果需要验证,执行验证过程
if validate:
pass
# 定义一个函数,用于训练整个栈式自编码器模型,接受模型,训练轮数,是否验证等参数
def train_whole(model=None, epoch=50, validate=True):
# 打印开始训练的信息
print(">> start training whole model")
# 如果GPU可用,将模型转移到GPU上
if torch.cuda.is_available():
model.cuda()
# 将模型的所有参数的梯度解锁,即更新参数
for param in model.parameters():
param.require_grad = True
# 调用get_mnist_loader函数,获取训练数据和测试数据的加载器
train_loader, test_loader = get_mnist_loader(batch_size=batch_size, shuffle=shuffle)
# 创建一个优化器,使用SGD算法,学习率为0.001,优化模型的所有参数
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 创建一个损失函数,使用均方误差损失函数
# criterion = BCELoss()
criterion = torch.nn.MSELoss()
# 从测试数据加载器中获取一批测试数据,并保存为图片
test_data, _ = next(iter(test_loader))
torchvision.utils.save_image(test_data, './test_images/real_test_images.png')
# 训练
# 遍历训练轮数
for epoch_index in range(epoch):
# 初始化总损失为0
sum_loss = 0.
# 遍历训练数据加载器,得到每个批次的数据和标签(标签在这里不需要)
for batch_index, (train_data, _) in enumerate(train_loader):
# 如果GPU可用,将数据转移到GPU上
if torch.cuda.is_available():
train_data = train_data.cuda()
# 将数据展平为一维向量
x = train_data.view(train_data.size(0), -1)
# 将数据输入模型,得到输出
out = model(x)
# 清空优化器的梯度缓存
optimizer.zero_grad()
# 计算输出和输入的均方误差损失
loss = criterion(out, x)
# 累加总损失
sum_loss += loss
# 反向传播,计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 如果达到日志间隔,打印训练信息
if (batch_index + 1) % 10 == 0:
print("Train Whole, Epoch: {}/{}, Iter: {}/{}, Loss: {:.4f}".format(
(epoch_index + 1), epoch, (batch_index + 1), len(train_loader), loss
))
# 如果是最后一个批次,将输出重构为图片,并保存
if batch_index == len(train_loader) - 1:
torchvision.utils.save_image(out.view(100, 1, 28, 28), "./test_images/out_{}_{}.png".format(epoch_index, batch_index))
# 每个轮数验证一次
if validate:
# 如果GPU可用,将测试数据转移到GPU上
if torch.cuda.is_available():
test_data = test_data.cuda()
# 将测试数据展平为一维向量
x = test_data.view(test_data.size(0), -1)
# 将测试数据输入模型,得到输出
out = model(x)
# 计算输出和输入的均方误差损失
loss = criterion(out, x)
# 打印验证信息
print("Test Epoch: {}/{}, Iter: {}/{}, test Loss: {}".format(
epoch_index + 1, epoch, (epoch_index + 1), len(test_loader), loss
))
# 判断是否为主模块,如果是,则执行以下代码
if __name__ == '__main__':
# 导入os库,用于操作系统相关的功能
import os
# 如果不存在test_images文件夹,就创建一个
if not os.path.exists('test_images'):
os.mkdir('test_images')
# 如果不存在models文件夹,就创建一个
if not os.path.exists('models'):
os.mkdir('models')
# 定义自编码器层数为5
nun_layers = 5
# 创建四个自编码器层的对象,分别为encoder_1, encoder_2, decoder_3, decoder_4,设置输入维度,输出维度和逐层预训练的标志
encoder_1 = AutoEncoderLayer(784, 256, SelfTraining=True)
encoder_2 = AutoEncoderLayer(256, 64, SelfTraining=True)
decoder_3 = AutoEncoderLayer(64, 256, SelfTraining=True)
decoder_4 = AutoEncoderLayer(256, 784, SelfTraining=True)
# 将四个自编码器层的对象放入一个列表中,命名为layers_list
layers_list = [encoder_1, encoder_2, decoder_3, decoder_4]
# 按照顺序对每一层进行预训练
# 遍历层数,从0到3
for level in range(nun_layers - 1):
# 调用train_layers函数,传入自编码器层的列表,要训练的层的索引,训练轮数,是否验证等参数,进行逐层预训练
train_layers(layers_list=layers_list, layer=level, epoch=num_tranin_layer_epochs, validate=True)
# 统一训练
# 创建一个栈式自编码器的对象,传入自编码器层的列表,命名为SAE_model
SAE_model = StackedAutoEncoder(layers_list=layers_list)
# 调用train_whole函数,传入栈式自编码器的对象,训练轮数,是否验证等参数,进行整体训练
train_whole(model=SAE_model, epoch=num_tranin_whole_epochs, validate=True)
# 保存模型 refer: https://pytorch.org/docs/master/notes/serialization.html
# 调用torch.save函数,传入栈式自编码器的对象和保存路径,将模型保存为sae_model.pt文件
torch.save(SAE_model, './models/sae_model.pt')输出结果:

test_images文件夹

real_test_images.png