数据压缩入门-读书笔记
数据压缩入门-读书笔记
简单的说,数据压缩算法有5类:变长编码(variable-length codes,VLC)、统计压缩(statistical compression)、字典编码(dictionary encodings)、上下文模型(context modeling)和多上下文模型(multicontext modeling)。
对数据进行压缩,通常有两个思路:
•减少数据中不同符号的数量(即让“字母表”尽可能小);
•用更少的位数对更常见的符号进行编码(即最常见的“字母”所用的位数最少)。
60年来的数据压缩研究都可以归结到上面两个重要思路上,数据压缩中的每一个算法都聚焦于解决这两件事情中的一件。
数据压缩所做的无非就是尽可能减少表示特定数据集时所需的二进制位数量。
数位的概念:比如193这个数从左到右包含3个数位,分别是百位、十位和个位
信息论
信息论:即从数学的角度研究如何利用符号序列、脉冲序列或其他形式对信息进行编码,以及信息能以多快的速度在计算机电路或者电信信道中传输。
根据信息论的观点,一个数值所包含的信息内容等于,为了在一个集合中唯一地确定这个数值,需要做出的二选一(是/否)决定的次数。
考虑如下场景:有一个100平方英尺的房间,地上铺了100块瓷砖,上面是拱形的天花板,靠近东面的窗户边有一张四柱大床,北面的墙边有一张古色古香的小写字台,而在床的西边则放着一个沉重的18世纪的衣橱。
你完全可以在一页纸上用JSON 或者其他你喜欢的脚本语言写出上面所有这些内容。
或者,你也可以采用下面这种略有不同的方法,用7个二进制位对地上的100块瓷砖进行编码,再用2个二进制位对4个主要方向进行编码,然后对3件家具进行编码,每件家具各用2个二进制位。
按照瓷砖–家具–方向这样的顺序,你睡的床可以用10010100111来表示。(每个二进制位的“意义”这样的元信息,可以存在你的头脑中,或者编码到组装这个房间的软件中,抑或附在这些数据的后面。)
现在,描述整个房间只需要44个二进制位或者6个字节就够了,比起文字描述或者JSON文件,节省了相当多的空间(不仅我们这样认为,那些下载了你的游戏的移动端用户也会认同)。
简单来说,这就是一个数据压缩的过程。
熵
![]()
给定任意一个十进制整数,通过计算它对应的LOG2函数的值,我们就能知道用二进制来表示这个数最少需要多少二进制位。香农将一个变量对应的LOG2函数的值定义为它的熵(entropy),也就是用二进制来表示这个数所需的最少二进制位数。
数值的LOG2表示形式虽然高效,但对于制造计算机元件的方式来说并不实用。这其中的问题在于,如果用最少的二进制位数来表示一个数,在解码相应的二进制字符串时会产生混乱(因为我们并不知道该数对应的LOG2长度),会与硬件的执行性能相冲突,两者不能兼顾。
现代计算机采用了折中的方案,用固定长度的二进制位数来表示大小不同的整数。最基本的存储单元是一个字节,由8个二进制位组成。
在现代编程语言中,通常可用的整数的存储类型包括:短整型16个二进制位、整型32个二进制位、长整型64个二进制位。
因此,对于十进制数10,虽然其对应的二进制数为1010,但在实际存储中是短整型,在计算机中的实际表示为0000000000001010。显然,这样做浪费了很多的二进制位。
这里需要指出的是,在现代应用程序开发中,我们所用到的绝大多数算法使用预先设定好的固定的二进制位长度,而不是通过LOG2函数计算出的二进制位长度。这就是信息论与实际实现层面的差别。
在计算机内存中,我们遇到的任何二进制位流都会舍入到下一个字节对齐的大小。这可能会让人困惑,比如当我们只存储了7个二进制位的数据时,计算机仍然会报告说我们所存储的数据长度与计算机一次读取的最小字节数相同。
实际中的数据压缩目标,是尽可能接近理论上的压缩极限。
为了使表示某个数据集所需的二进制位数最少,数据集中的每个符号平均所需的最小二进制位数就是熵。
从本质上来说,香农所定义的熵,是以一种倒排序的方式建立在数据流中每个符号出现概率的估算之上的。
总的来说,一个符号出现得越频繁,它对整个数据集包含的信息内容的贡献就会越少,这看起来似乎完全违背直觉。
钓鱼就是这样一个真实的例子。设想你坐在岸边草坪中的躺椅上,戴着漂亮的帽子,手拿卷筒和连杆,望着河面和鱼浮。每隔几分钟,你就会看一眼鱼浮,发现它并没有变化,但每隔一小时左右,就会有鱼咬钩,这才是你真正感兴趣的事情。也就是说,很长的时间里没有什么有用的信息,真正有用的信息偶尔才会出现。如果用0表示没有鱼,用1表示鱼上钩,那么你记录的信息里很容易出现这样的片段:0000000010000000001000000000001。
从统计上来说(从运动角度来说同样如此),我们感兴趣的是鱼在咬钩这样的事件,其他的都是冗余信息。
数据压缩领域的最前沿都是关于如何改变熵的。事实上,整个数据压缩科学界的人士都认为熵是互联网上的一大“谎言”。
真相是,实际上,通过利用真实数据的两个性质,我们完全有可能将数据压缩得比熵定义的还要小。按照香农对熵的定义,他只考虑了符号出现的概率,完全没有考虑符号之间的排序。而对真实数据集来说,排序是一项基本的信息,符号之间的关系同样如此。
例如,排好序的[1,2,3,4] 和没有排序的[4,1,2,3] 这两个集合,按照香农的定义,两者的熵相同,但是凭直觉我们就能发现,其中的一个集合包含了额外的排序信息。我们再来看一个元素为字母的例子,[Q,U,A,R,K] 和[K,R,U,Q,A] 这两个集合有相同的熵,但[Q,U,A,R,K] 这个集合表示的是英语中一个有意义的单词,而且字母的出现也有一定的规则,比如字母Q后面通常会跟着字母U。
突破熵的关键在于,通过利用数据集的结构信息将其转换为一种新的表示形式,而这种新表示形式的熵比源信息的熵小。
增量编码
元素递增的集合[0,1,2,3,4,5,6,7] 称为集合 A1,现在打乱,得到[1,0,2,4,4,5,7,6]集合 A2。
根据香农的定义,每个符号都需要用3个二进制位来编码,而每个集合则需要24个二进制位。然而最终的结果是,我们很容易就能突破熵的限制,用更少的二进制位对集合A1进行编码,具体方法如下:
集合A1实际上是数的一个线性递增序列。因此,无须对其中的每个数都进行编码,而是可以对整个数据流进行转换,将各个数编码为其与前一个数的差。所以,编码后的集合 A3 会是这样:
[0,1,1,1,1,1,1,1]
这样的转换一般称为增量编码(delta coding),也就是将一系列的数转换为其与上一个数的差后再编码。
符号分组
字符串 S = “TOBEORNOTTOBEORTOBEORNOT”,它包含了不同符号的集合[O,T,B,E,R,N]。
如果不是将单个的字母当成符号,而是把单词当成符号,情况又会如何呢?这样一来,我们有单词集合[TO,BE,OR,NOT]。
再观察这个字符串,我们发现“TOBEORNOT”这个词组出现过多次,可以将该词组当做一个符号。
如果数据集中存在连续值组合出现多次的情况,就可以利用这种情况来减小熵。一般来说,通过最佳符号分组预处理数据,会得到一个较小的熵值。
排列
在数学中,排列这一概念是指重新安排或者改变一个集合的所有元素的次序或者顺序。
从经典的定义来看,只有同一组数的不同顺序才算排列,比如可以说[2,1,3,4] 是[1,2,3,4] 的一个排列,但[5,2,7,9] 就不是。
通过消除编码法压缩排列
排列很难压缩是出了名的。排列是可以稍微压缩的,但这个过程没什么意思,也没多少实际价值。
数据压缩算法的艺术,就在于真正试图去突破熵的限定,或者说是将数据转换成一种熵值更小的、新的表现形式。
这可以说是真正的舞蹈:
信息论已经制定了相应的规则,
数据压缩则以斗牛士的热情巧妙地避开了这些规则。
VLC
摩尔斯码
摩尔斯码为英语字母表中的每一个字符都分配了或长或短的脉冲,一个字母用得越频繁,其编码也就越短、越简单。因此,英语中最常用的字母“E”的编码最短,用一个点表示;而字母“X”的编码毫无疑问则很长;所有的数字都用5个脉冲表示。
即使是追溯到19世纪,这也是对符号分配变长编码(variable-length codes,VLC)的最初实现之一,其目的则在于减少传输信息过程中所需要的总工作量。
有理由相信,在早期对信息论的研究中,克劳德•香农(他是摩尔斯码方面的专家)正是利用了这一概念,由此创造了一个新的技术领域“数据压缩”的第一代技术,这些都是在VLC的启发下产生的。
对于给定的输入数据集,可先计算涉及的符号的出现概率,然后就可以通过VLC将字长最短的码字分配给最可能出现的符号,从而实现压缩数据。
运用 VLC
一般来说,对数据进行VLC通常有3个步骤。
(1) 遍历数据集中的所有符号并计算每个符号的出现概率。
(2) 根据概率为每个符号分配码字,一个符号出现的概率越大,所分配的码字就越短。
(3) 再次遍历数据集,对每一个符号进行编码,并将对应的码字输出到压缩后的数据流中。

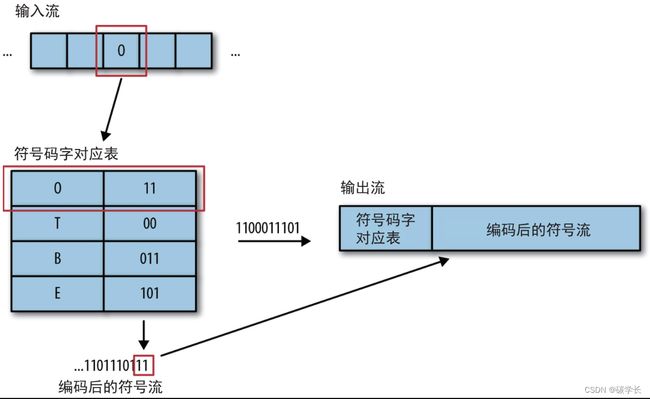
举个例子,要使用刚创建的符号码字对应表对“TOBEORNOT”进行编码,第一个字符是“T”,因此将相应的码字00添加到输出流,接下来是字符“O”,再将11添加到输出流。如此反复,最终得到“TOBEORNOT”所对应的输出流为001101110111010001011100,共24个二进制位。
与72个二进制位的源数据流相比(即使平均每个字符只用3个二进制位),通过压缩节省了大约11% 的空间。
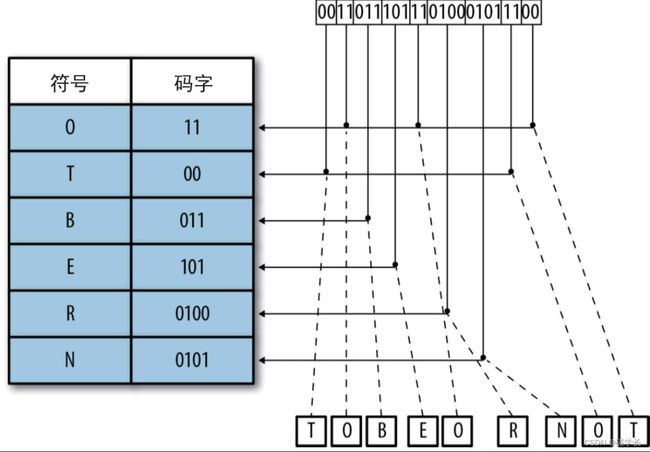
前缀性质
在任意时刻,解码器都需要能确定到目前为止所读取的二进制位,是否与特定字符的码字相匹配,以及是否还需要继续读取下一个二进制位。为了确保正确,在设计VLC集的码字时,必须考虑两个原则:一是越频繁出现的符号,其对应的码字越短;二是码字需满足前缀性质。
先看看一个潜在的VLC是怎样崩溃的。假定我们有数据流0101111,以及如下表所示的VLC对应表。
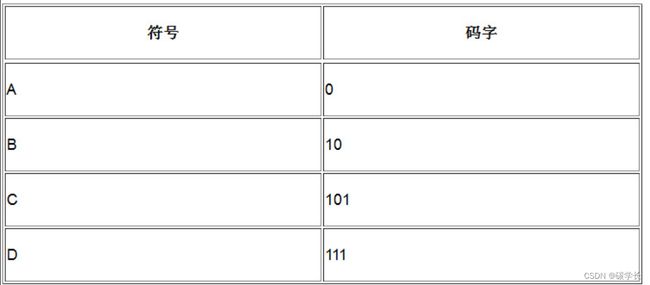
解码过程如下所示:
(1) 解码器读取0,其对应的字符肯定是A,因此将A输出。
(2) 解码器读取1,它可能是字符B、C或D的码字的第一位。
(3) 解码器继续读取0,现在可能字符的范围缩小为B或C。
(4) 解码器继续读取1,这里我们遇到了歧义:读取的二进制位101,应该解释为10 + 1(表示的是B与另一个字符的开始,该字符可以是B、C或者D)还是 101(表示的是字符C)呢?此时,解码的过程已经进行不下去了,因为我们已不能确定读取的二进制位到底表示的是什么符号。如下图所示,我们设计的码字已经让我们无法区分不同的符号。
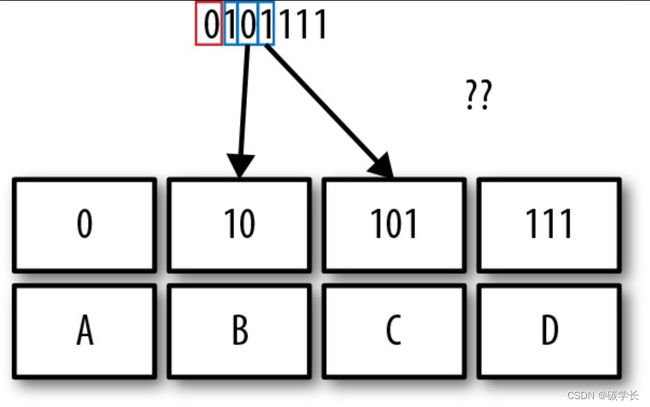
这里,我们提到了VLC的前缀性质,它的意思是:
在某个码字被分配给一个符号之后,其他的码字就不能用该码字作为前缀。
换句话说,每个符号都能通过其码字前缀唯一地确定,只有这样,VLC才能正常工作。
前缀性质是VLC能正常工作所必须具有的性质。这也就意味着,与二进制表示相比,VLC要更长一些。
折中后的结果是,我们得到的数据流会更长(因而也更大),但同时也能在事先不知道符号长度的情况下进行解码。由于那些常见的字符对应的码字很短,因此对那些少数几个字符出现频率特别高的数据流而言,VLC的压缩率还是很高的。
通用编码
一位数学家板凳一坐十年冷,最终找到了一种将整数转换为VLC的独特方法。
这种编码方法一般称为通用编码(universal codes),大致来说,就是为正整数赋上一个长度可变的二进制码字。
通常来说,通用编码遵循以下原则:数值越小,其对应的码字也越短,因为假定小整数比大整数出现得更频繁。
通用编码是一类特殊的前缀编码。还有其他类型的VLC方法,比如唯一可译码(uniquely decodable codes)与非奇异码(nonsingular codes)。
二进制编码
由于二进制编码在计算机中无处不在,因此它总是数据压缩的最终结果。
人们总是习惯用[插图]来表示整数B(n)的标准二进制表示。这种表示通常被称为beta编码或二进制编码,不过它不满足前缀性质。例如,2的二进制表示为10,同时它也是4的二进制表示100的前缀。
给定 0~n 的任意整数,我们都能用 1 + floor(lb(n)) 个二进制位来表示。也就是说,只要提前知道 n 的值,我们就能通过固定长度表示法来避开前缀问题。换句话说,如果知道有多少个数需要表示,我们很容易算出一共需要多少二进制位。然而,如果不能提前知道数据集中有多少个不同的整数,就不能用固定长度表示法。
一元码
任意正整数 n,它的一元码表示都是 n - 1 个1后面跟着1个0,例如,4的一元码表示为1110。所以,很容易得出,整数 n 的一元码长度也是 n 个二进制位。同样,也容易看出一元码满足前缀性质,因此可以将它作为VLC使用。
将一元码应用在那些前一个符号的出现概率是后一个符号2倍的数据集上,效果最佳。(也就是说,A的出现概率是B的两倍,而B的出现概率又是C的两倍。)
Elias gamma 编码
Elias gamma编码主要用于事先无法确定其上界的整数的编码,也就是说,不知道最大的整数会是多大。
该方法最主要的思想是不再对整数直接编码,而是用其数量级作为前缀。这样一来,相应的码字就由两部分组成,即与此整数相当的2的次幂再加上余数,编码方法如下所示:
(1)找出最大的整数 N ,使其满足 2 ^N< n < 2 ^(N+1),并且将 n 表示为 n = 2 ^N + L 这样的形式(这里 L = n - 2 ^N)
(2)用一元码表示 N。
(3)将 L 表示为长为 N 的二进制编码,并加在步骤(2)中得出的一元码之后。(这一步很重要,正是有了这样的对称性,后面才能顺利解码。)
比如,当 n = 12 时,会进行如下编码:
(1)由于 2^3 = 8,而 2 ^4= 16,同时 2 ^3< 12 < 2^4,因此 N 的值等于 3。
(2)根据前面的说明,可以算出 L 的值为 12 - 8 = 4。
(3)N = 3,其对应的一元码为 110.
(4)L = 4,其对应的长度为 3 的 二进制码为 100.
(5) 将前两个步骤得出的编码连接,就得到了最终的输出 110100。
与简单的一元编码类似,Elias gamma编码对那些整数 n 的出现概率 P(n) = 1 / (2 * n²)的情形比较适用。
Elias delta 编码
Elias delta编码则是另外一个变种。在这一方法中,Elias还在前面加上了二进制的长度,使这一编码稍微复杂一些。
原理如下:
(1)将要编码的数 n 用二进制表示。
(2)数一下 n 的二进制位数,并将这个位数转化为二进制,作为C。
(3)去掉 n 的二进制表示的最左边一位,这个值肯定是1,可以推断出来。
(4)将 C 的二进制表示加在去掉最左边一位后的 n 的二进制表示前。
(5) 在上一步骤所得的结果前加上C的二进制位数减1个0作为最终的编码。
以 数字 12 为例:
(1)将 n = 12 表示为二进制1100。
(2)12的二进制表示共有4位,将4表示为二进制,即C = 100。
(3)去掉 n 的二进制表示的最左一位,得到100。
(4) 将C = 100加到上一步骤所得的结果之前,得到100100。
(5) 将C的二进制位数减1,即3-1 = 2,在上一步骤所得的结果前加上2个0,由此得到12的最终编码为00100100。
在过去的40多年中,人们创造了数百种VLC算法.
谷歌的 Varint 算法:避免压缩整数
VLC主要存在以下几个问题,因而只能用于表示压缩数据流,没有其他应用。
•它们不按字节 / 字 / 整型对齐。
•对于大的数值 n,为了方便解码,其码字长度的增长速度一般会超过 lb(n) 个二进制位。
•解码的速度很慢(每次只能读取一个二进制位)。
对那些需要处理很多大整数的系统来说,这些问题使得VLC无法应用。然而,在21世纪初,出现了一个新的可变长度整数模型,在搜索引擎和其他海量数据系统中得到了广泛应用。
虽然它是以谷歌的Varint算法而流行的,但其中最基本的概念早在1972年就提出来了,并在2010年作为“避免压缩整数”(escaping for compressed integers)而被重新引入。
Varint是一种表示整数的方法,它用一个或多个字节来表示一个整数,数值越小用的字节数越少,数值越大用的字节数越多。
该方法将几个字节连接起来表示整数,并用每个字节的MSB作为布尔标志,来判断当前的字节是否为该整数的最后一个字节;而每个字节的低7位则用来存储该数的二进制补码(two’s complement representation)。
比如:
整数1可以用一个字节表示,因此它的MSB不需要设置,可表示为00000001。
再来看整数300,它的表示则要复杂一些:10101100 00000010。那么如何判断它表示的是300呢?
最高有效位( most significant bit,MSB)指的是一个n位二进制数字中的n-1位,具有最高的权值2^(n-1)。
首先,需要删掉每个字节的MSB,因为它的作用只是判断当前字节是否是最后一个字节(正如你看到的那样,第一个字节的MSB已经设置为1,因为用Varint方法来表示,该数需要多个字节)。10101100 00000010 → 0101100 0000010。
接着,将剩下的两个7二进制位的数据顺序颠倒一下,因为用Varint方法表示时,低位的字节在前。最后,将二进制表示转换为十进制数,就得到了最终的数值。
0101100 0000010 → 0000010 0101100 → 2^8 + 2^5 + 2 ^ 3 + 2 ^ 2 = 256 + 32 + 8 + 4 = 300
Varint表示方法结合了VLC的灵活性和现代计算机体系结构的高效率,是一种很好的混合方法。它既允许我们表示可变范围内的整数,同时还对自身的数据进行了对齐以提高解码的效率,达到了双赢。
为数据集找到最适合的编码方法
在为数据集选择一种VLC编码方法时,必须要先考虑数据集的整体大小和数据范围,并计算各个符号的出现概率。如果不这样做,得到的结果可能就是,数据集的大小不但没有压缩,有可能反而比原来的数据集还大。
VLC编码方法是根据某个数值期望的出现频率来为该值分配码字的。因此,每种VLC编码方法,对于数据集中的各个符号如何分布,都有相应的期望。因此,为数据集选择适当的VLC编码方法,关键在于使VLC背后的概率模型与该数据集匹配。如果偏离了这个方向,最终得到的可能会是更大的数据流。
统计编码(statistical encoders)这类算法无须将特定的整数转换为特定的码字,而是通过数据集中符号的出现概率来确定新的、唯一的变长码字。最终的结果就是,给定任何输入数据,我们都能为其构造出一套自定义的码字集,而无须去匹配现有的VLC方法。
如果要更准确地描述这类算法,那么“统计编码算法通过数据集中符号出现的概率来进行编码使结果尽可能与熵接近”这样的表述可能很合适。
统计编码
哈夫曼编码
哈夫曼编码可能是生成自定义VLC最直接、最有名的方法。给定一组符号及其出现频率,该方法能生成一组符号平均长度最短的VLC。它的工作原理是将数据排序后建立决策树(decision tree),然后从“树干”一直往下直到“树叶”为止,并记录下所做的是/否选择。这里所说的“树叶”就是我们要找的各个符号。
1、构造哈夫曼树
哈夫曼发现如果使用二叉树,就能利用符号表中的概率与二叉树的分支来创建优化的二进制代码。

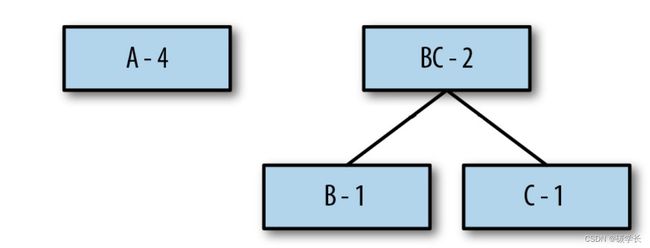
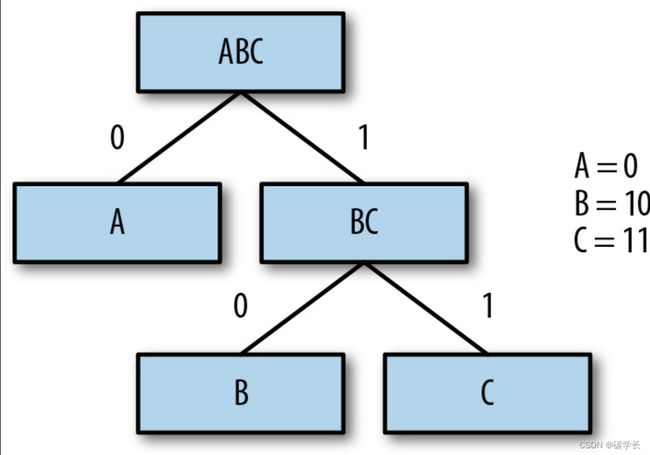
先将符号及其出现的频次写在便签纸上,再根据频次对符号进行排序,然后自下而上建一棵二叉哈夫曼树,并称它们为哈夫曼树的叶子。

接下来,选择出现频次最小的两个符号,并将它们往下移一层,然后拿出新的便签将两者合并作为它们的父节点,上面写上两个符号的组合及频次相加之和:
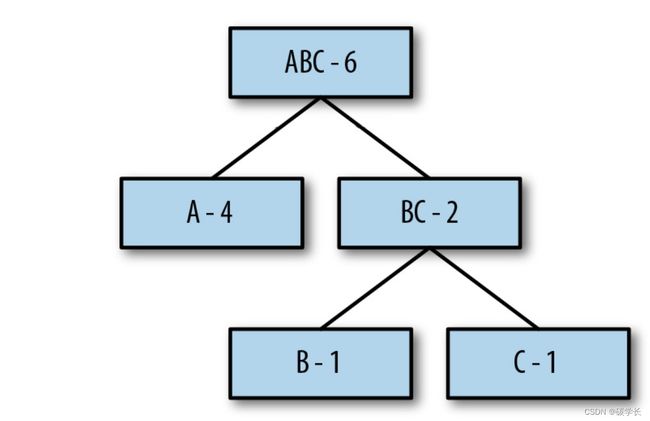
然后重复上述过程,再合并剩下的A结点和BC结点创建一个新的根节点ABC,这样它就表示了完整的符号集:
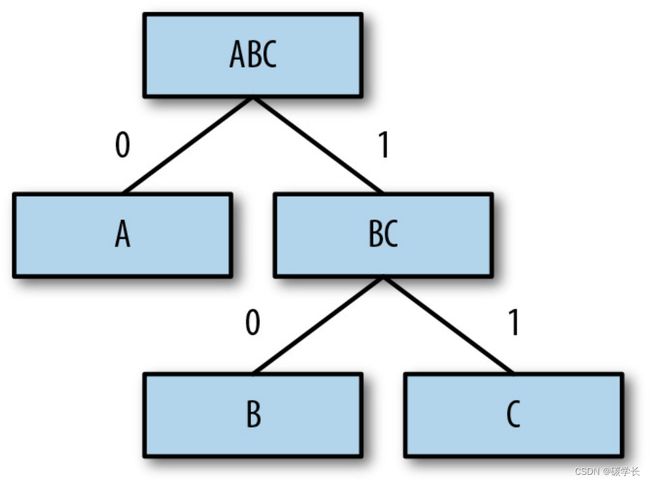
2、生成码字
为了能生成码字,给所有左子树赋值0,为所有右子树赋值1。
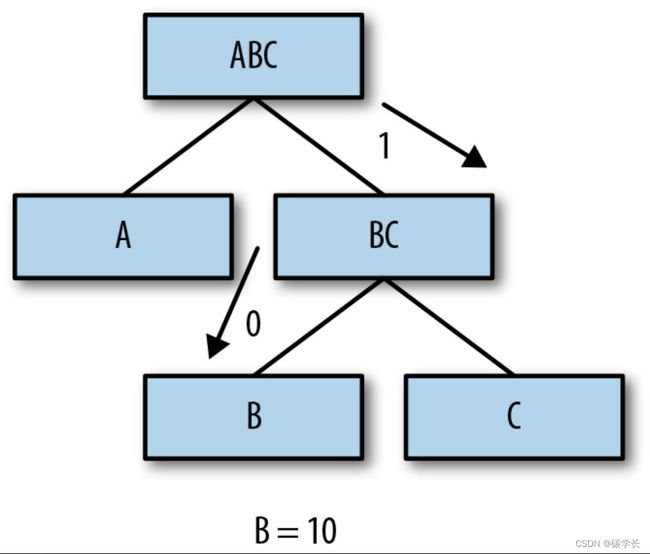
最后,为了获得给定符号(叶子节点)的码字,需要从根节点“沿着树枝”往下走,并将所得的1和0按从MSB到LSB排列起来,也就是从左排到右。
例如,为了确定符号B的码字,从根节点开始,向右遍历(得到1),然后再向左遍历(0),这样得到的10就是B的码字
为了得到其他剩余符号(叶子节点)的码字,只要重复上面的过程就可以了:
3、编码与解码
现在你已成功地为数据集构造了VLC,可以用它们进行编码了。只要遍历输入流,对遇到的每一个符号,写下其对应的码字作为输出就可以了。
为了解码,也需要将符号码字对应表与压缩后的内容放在一起传输,然后再按照标准的VLC的解码过程进行解码。
由于创建哈夫曼树(需使用计算资源)要比传输符号码字对应表(会增加数据流大小)困难得多,因此总是应该将码字对应表加在数据流的前面,而不是在解码时再重新创建一次。
4、实际的实现方法
在过去的50多年里,人们已经对哈夫曼编码进行了大量的分析,不但产生了各种能在特定性能或内存阈值下工作的变体,也有针对特定概率分布的各种变体。
算术编码
哈夫曼编码简单、高效,也能为单个的数据符号生成最佳的码字。然而,对于给定的符号集来说,它并非总是生成最有效的码字。
事实上,哈夫曼编码能生成理想VLC(即码字的平均长度等于符号集的熵)的唯一情形是,各个符号的出现概率等于2的负整数次幂(即是1/2、1/4或1/8这样的值)。这是因为哈夫曼方法会为给定符号集中的每个符号都分配一个整数二进制位长的码字。
信息论告诉我们,如果一个符号的出现概率为0.4,那么它最理想的码字长度应该是1.32个二进制位,因为–lb(0.4) ≈ 1.32。而哈夫曼方法分配给这个符号的码字长度则只能是1个二进制位或2个二进制位。
与按照1∶1的比例为每个符号分配一个码字不同,算术编码算法会将整个输入流转换为一个长度很长的数值,而它的lb表示则与整个输入流真正的熵值很接近。算术压缩的神奇之处在于,它将转换应用到整个源数据上以生成一个输出值,而表示这个输出值所需要的二进制位数比源数据本身少。
1、找出正确的数
算术编码的工作原理是将字符串转换为一个数,与字符串相比,表示这个数需要的二进制位数要少一些。例如,字符串“TOBEORNOT”可以用数236712来表示,而ceil(lb(236 712)) = 18,即只需要18个二进制位就能表示。相比而言,如果用ASCII码来表示“TOBEORNOT”,则需要56个二进制位。
不过,事情并不像前面举的例子那样简单,随机挑选一个数就可以了。相反,算术编码会根据输入流,通过一系列复杂的步骤计算出那个数。
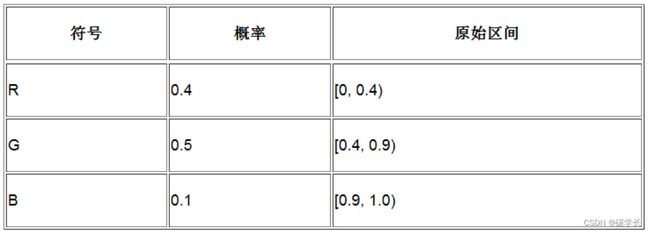
算术编码首先会创建[0,1)这样的数值区间,然后再通过数据流中符号出现的概率对这一区间进行细分。比如说,如果A出现的概率为25%,那么为A分配的区间就是[0,0.25),B出现的概率为10%,那么B对应的区间则为[0.25,0.35),以此类推,如下图所示。

当编码器读取一个符号时,它就会找到这个符号对应的区间。例如,如果读取字符A,那么用到的区间就是[0.0,0.25)。在读取一个符号以后,编码器将继续细分这个取值区间,并按符号的出现比例进行细分。
例如,如果遇到的输入流中有3个A,那么编码器将对A的取值区间细分3次:
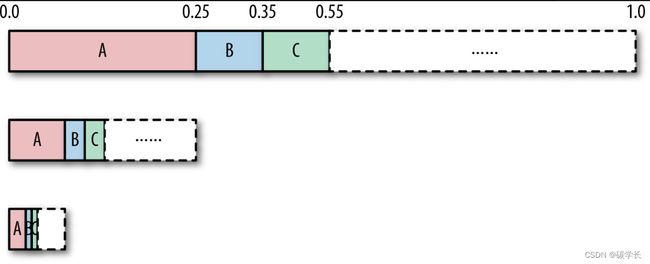
总的来说,每个符号都会以递归的方式再次细分取值区间直到读完整个输入流为止。之后,就得到最终的取值区间,比如[0.253212,0.25421)。而最终输出的数值,也在这一取值区间内。例如,上面所举的输入为AAA的例子,其最终输出值就在[0,0.015625)这个区间之内。
2、编码
假定有3个字符R、G和B,其出现概率分别是0.4、0.5和0.1。根据这3个字符的出现概率,我们在[0,1)范围内为它们分配了相应的取值区间。
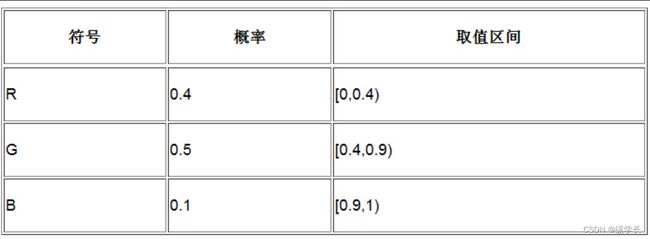
使用这样的概率设定,对字符串“GGB”编码。
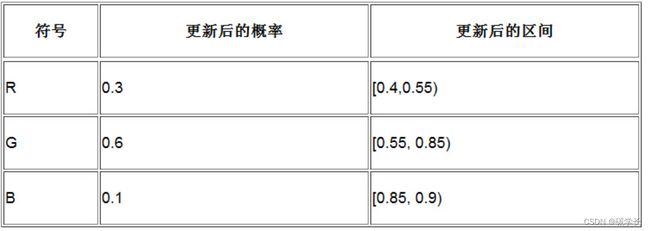
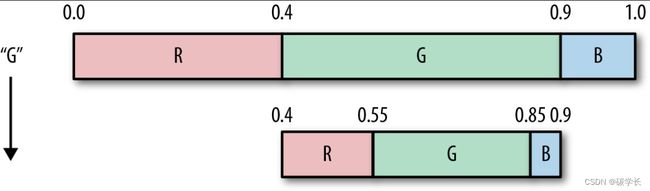
从输入流中读到的第一个字符为G,根据上表可以知道G的取值区间为[0.4,0.9)。因此,需要按3个字符的出现概率对[0.4,0.9)这一区间进行再次细分,得到3个符号的新取值区间,如下图及下表所示:

接着从输入流中读取第二个字符,还是G,因此需要继续细分G的取值区间,此时其范围为0.6~0.85,并再次根据概率更新各个符号的取值区间,如下图及下表所示:
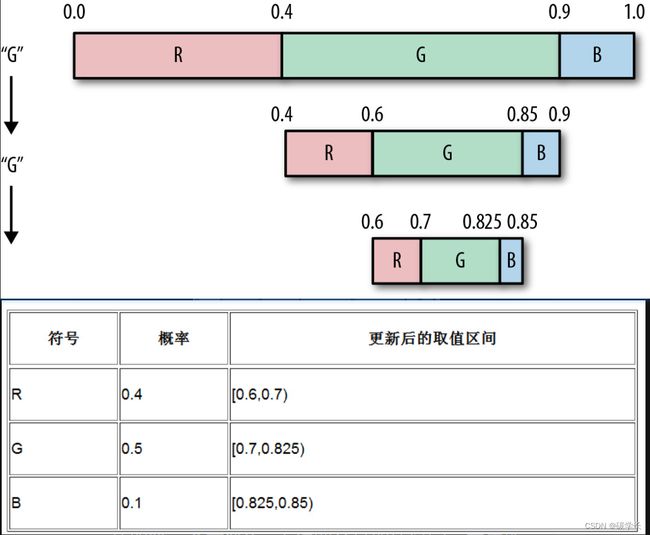
读取第三个字符B,再次细分其取值区间,并更新相应的图和表。
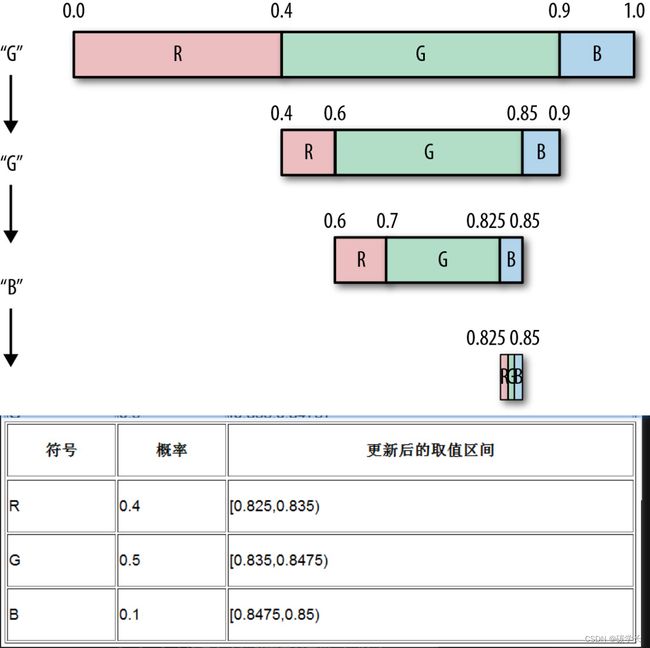
至此,用算术方法就实现了对一个输入流的编码。
3、选择正确的输出值
在上面所举的例子中,B的最终取值区间是[0.825,0.85),在此区间内的任何数值都能让我们重新构建出原来的字符串,因此可以从中任取一值。
在这个取值范围内需要最少二进制位表示的数是0.83。
由于解码器事先“知道”这个数肯定是一个小数,因此可以去掉小数点以节省空间,将最终的值确定为83。由于lb(83) = 7,因此平均每个字符占用2.33个二进制位。
4、解码
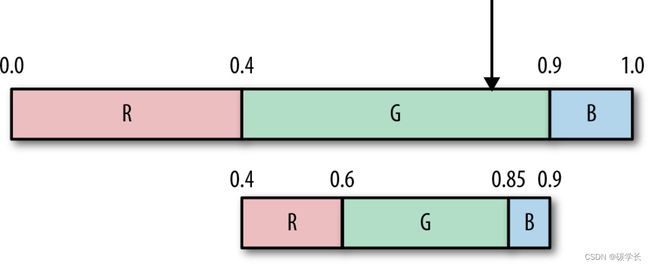
从最终输出值解码非常简单,基本是编码的逆过程。与编码相同,我们也会在[0,1)根据字符的出现概率等比例地创建取值区间,如下图所示。

当拿到输入值83后,移动小数点将其变成小数0.83,这样就能看出它落在哪个区间内,然后再将与此区间相关联的符号输出。
具体到本例中,0.83处在0.4~0.9,因此首先输出字符G。
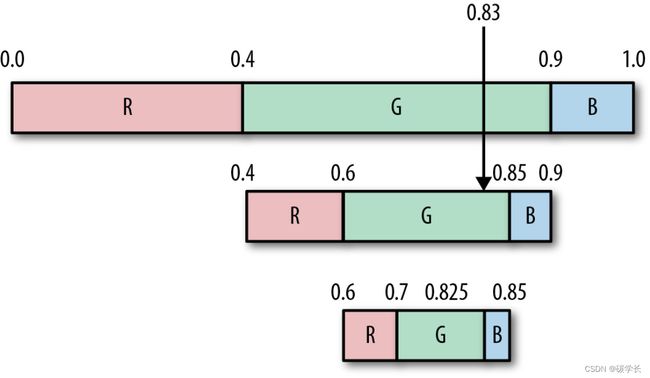
然后,再根据各符号的概率分布(与编码时相同)将G的取值区间细分,如下图所示。
为了得到第二个符号,需要重复这个过程。现在输入值仍然是0.83,再次落在G的取值区间内,因此输出第二个G,并再次对G所在的区间进行细分,如下图所示。
继续这个过程,0.83处在0.825~0.85,这是符号B的取值区间,因此接着输出B,如下图所示。
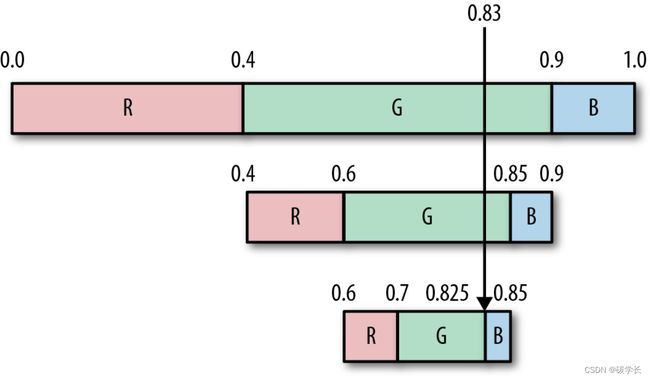
这样就得到了最终解码后的输出流GGB。
21世纪初算术编码的专利到期之后,算术编码得到了大量的使用,并变得流行起来,同时也产生了大量与其具体实现相关的话题。
让人印象深刻的是,人们对不少实现方法进行了修改以适应特定的编码解码器,如JPG和H.264编码解码器所使用的二进制版本(binary-only versions)。
如果想了解更多的话,参见文章Practical Implementations of Arithmetic Coding。
ANS
在哈夫曼编码与算术编码进行了将近40年的较量之后,这两种方法似乎都要被一种全新的统计编码算法替代。
2007年,Jarek Duda引入了一种新的与数据压缩有直接关联的信息论概念:非对称数字系统(asymmetric numeral systems,ANS)。实际上,ANS是一种新的精确熵编码方法,所得到的结果可以和最优熵任意接近,它的压缩率与算术编码接近,而性能则与哈夫曼编码相当。
ANS 的算法原理为:
(1) 根据符号的出现频率对数值区间进行细分。
(2) 创建一张表,将子区间与离散的整数值关联起来。
(3) 每个符号都是通过读取和响应表中的数值来处理的。
(4) 向输出流中写入可变的二进制位位数。
这一算法独有的两个部分在第(2)步(子区间与整数值关联的表)和第(4)步(可变的二进制位位数)中。
1、通过转换表来编码和解码
tANS是ANS的一种变体,它是围绕着一张表格工作的。
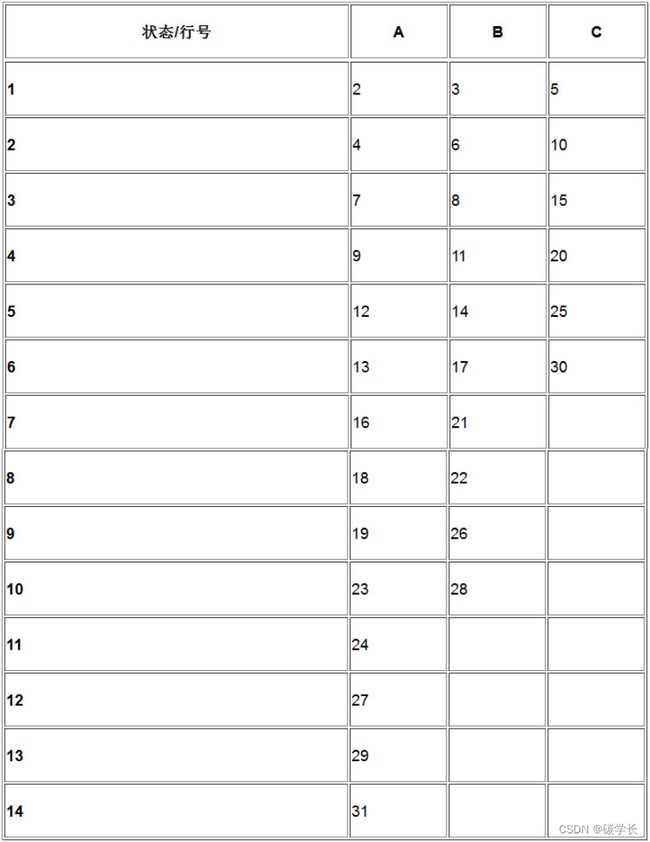
给定了这张表,我们来看一下如何对输入的字符串BAA进行编码:
(1)给定输入字符串BAA,需要从[ 行号, 输入符号] 对开始编码,这里就是[1,B]。
(2)有了这样的[ 行号, 输入符号] 对,就能定位到下一个需要读取的值在表格中的位置。通过查表,得到单元格[1,B] 的值是3,因此,下一个[ 行号,输入符号] 对的值为[3,?]。
(3)为了得到列号,接着读下一个符号,为A,得到新的表位置[3,A]。
(4)再次查表,得到单元格[3,A] 的值是7。
(5)继续读下一个符号,也为A,得到新的表位置[7,A]。
(6) 表中此位置对应的值为16。
(7) 可以一直这样操作下去,直到表尾(或者读取字符串的最后一个字符)。
(8)根据这张表,将输入的BAA转换为了[3,7,16]。
解码过程则与编码过程相反:
(1) 从最后一个值16开始解码。
(2) 搜索整个表后,发现16位于表的7行,A列。
(3) 将A输出作为符号,而7则变为当前的值。
(4) 再次搜索表,发现7位于表的3行,A列。
(5) 再次将A输出,此时3则变为当前的值。
(6) 在表中搜索3,发现它位于1行,B列。由于已经到了第1行,所以不能继续操作,解码过程结束。
(7)解码后的符号流为[A,A,B],这是因为从后往前解码。
(8) 倒置所得到的字符串,就得到了源字符串BAA。
2、创建备查表
这一算法的核心就是这张神奇的备查表,它使得从符号转换为数值再从数值转换为符号成为可能。创建这张表时,需要先根据符号出现概率的大小排序,每个符号作为表的一列,从左往右概率依次递减。
前面的那张表中,符号 A、B、C 的概率为 P([A,B,C]) = [0.45,0.35,0.2],其中每个符号都被分配作为表的一列。
接下来需要往表中填入数值,这些数值需满足以下条件:
•表中的每个值都是唯一的(即不存在重复)
•每列都按照值从小到大排序
•每行的值都要比该行的行号大
如果想要tANS变成真正的熵编码器,还必须要考虑以下两个性质:
(1) 在确定每一列值的个数时,需满足该值乘以maxVal后,等于该列符号的出现概率;
(2) 在确定每一行的值时,需确保该行列选择的值与该列符号的出现概率一致,这样当用该值除以行号,所得商就会(近似)等于该列符号的出现概率。
第一个性质比较简单。这张表中最大的值maxVal=31。为满足前面所述的性质,我们需要将maxVal细分,并将 P(S) * maxVal 个值分配给各个列。具体到前面所举的例子,有如下计算。
•符号 B的出现概率 P(B) = 0.35,因此 B列会有floor(0.35×31) = 10个值出现。
•符号 C进行同样的处理,因此 C列会有 6个值(0.2×31 = 6)。
•最可能出现的符号,也就是最左边的 A列,一共有 P(A) * maxVal + 1 = 0.45 * 31 + 1 = 14 行,这是因为 A列还需要为 maxVal增加额外的一行。
这样,就对maxVal进行了细分,让每个符号出现的行数与maxVal的比等于其出现概率。
第二个性质表明,每一行的值可以用行号乘以每个符号的出现概率计算出来。
具体到前面所举的样表,符号表S =[A,B,C] 中各符号的出现概率为P(S) = [0.45,0.35,0.2],再任意选一个行,比如说第5行,从左到右各单元格的值依次为12、14、25。
现在,用这些值除行号,所得的结果与符号的出现概率非常接近:
[5 / 12, 5 / 14, 5 / 25] = [0.41667,0.357,0.2] ≈ P(S)
第二个性质必须对每一行都成立。如对于 A 列:
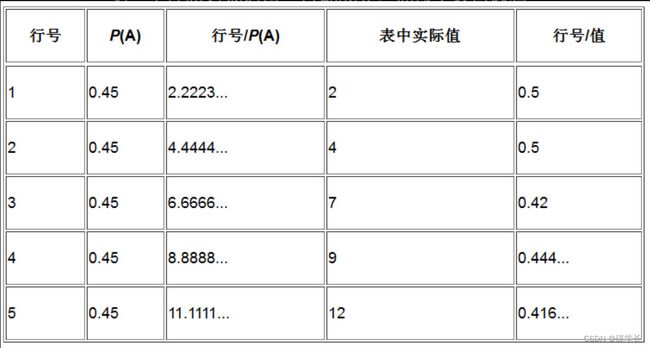
为什么有时候表格中实际分配的值会和计算得出来的值不一致呢?答案是为了避免重复。
表中的每个值都必须是唯一的,但由于计算的时候需要四舍五入,因此有时候就难免会出现彼此冲突的情况。
可以通过使用表中还没有使用的下一个更大的值,来解决冲突问题。
如果这两条性质都能满足,那么我们就能完整地创建出前面那样的表,对数据正确地进行编码解码从而实现压缩的目的。
1、选择一个 maxVal
maxVal的选择直接影响到输出的压缩结果,而压缩结果又直接与编码所允许的整数精度相关。
因此,目标就是为每个符号分配一个子区间,使其长度与该符号的出现概率相匹配。
因此,需要创造出某个大小的整数空间(即从2到maxVal),这样可以为每个符号分配相应的子空间而不会遇到精确度的问题。
因此,选择的maxVal应该是一个函数,该函数是所需要的最小二进制位数加上由于精度的需要而额外增加的二进制位数:

这里,magicExtraBits一般取2~8的某个值,或者取任何对于具体数据集来说合适的值。
对于magicExtraBits的取值,要综合考虑压缩质量和时间,因为这个值越大,压缩率就越高,但同时压缩需要的时间也会越长。
3、使用 ANS 压缩数据
前面介绍了备查表的工作原理,然而,那里的输出达不到统计压缩的目的。为了达到这一目的,还需要对前面介绍的算法进行一些调整:
•首先,不再从 1行开始,而是将初始状态(行号)选择为 maxVal。
•其次,对从数据流中读取的每个符号:
-将目标行设为该符号的列高度;
-右移状态值直到它比目标行的值小;
-状态值右移的过程中所丢弃的每个二进制位都应该输出到编码后的二进制位流中。
经过调整后,来看 “ABAC”的编码过程:
(1)从初始状态开始,由于初始状态值=maxVal=31(二进制为11111),因此从31开始。
(2)从字符串中读取第一个符号A,因此第一个表位置为[31,A],同时将目标行设为符号A的列高14。
(3) 由于31 > 14,因此需要移位并将相应的二进制位输出。
a. 将状态值11111右移一位,得到1111,同时将截断的最右边的1 输出。
b. 现在,状态值为15,还是比14大,再次右移一位,状态值变为111,再次将右边的1 输出。
c. 状态值现在为7,我们已经截断并输出2个二进制位(即11)。(4)现在,将备查表单元格[7,A] 的值16(二进制为10000)赋给状态值。
(5)读取下一个符号B,得到第二个表位置为[16,B],同时将目标行设为符号B的列高10。
(6) 由于16 > 10,需要移位并输出相应的二进制位。
a. 状态值16右移一位后变成8(二进制为1000),同时将最右边的0 输出。
b. 由于8 < 10,因此可以继续读取一个符号。
(7)将备查表单元格[8,B] 的值22(二进制为10110)赋给状态值。
(8)读取下一个符号A,得到第三个表位置为[22,A],同时将目标行设为符号A的列高14。
(9)由于22 > 14,需要移位并输出相应的二进制位。右移后状态值变为1011,同时将最右边的0输出。
(10)将备查表单元格[11,A] 的值24(二进制为11000)赋给状态值。(11)读取下一个符号C,得到第四个表位置为[24,C],同时将目标行设为符号C的列高6。
(12)由于24 > 6,需要移位并输出相应的二进制位。右移两次后状态值变为110,同时将最右边的00 输出。
(13)将备查表单元格[6,C] 的值30(二进制为11110)赋给状态值。
(14) 由于字符串已经为空,将状态值(11110)全部输出。
(15)因此,最终的输出流为11000011110,共11个二进制位。当然,除此之外,还需要加上符号概率表所占的二进制位数。
4、解码示例
解码的过程与上面的编码过程相反。
(1) 从压缩后的数据流中读出符号出现频率数据。
(2) 根据符号出现频率信息创建备查表。
(3) 继续从数据流中读出状态值。
(4) 找出该状态值在备查表中的位置。
(5) 将该值所在的列号作为符号输出。
(6) 将当前行号赋给该值。
(7) 继续从数据流中读取一些二进制位(并放到该值的后面,使其成为完整的状态值)。
注意,在这个例子中maxVal = 31,即精度为5个二进制位(5 bits of precision)。
创建好备查表之后,我们来看一下从编码后的数据流11000011110解码的过程。
(1) 由于目标状态值为5位,因此先从数据流中读出最后5个二进制位,即11110(即十进制数30)。
(2)找到唯一值30在表中的出现位置,为[C,6]。
(3) 输出符号C。
(4) 6(二进制为110)只有3个二进制位,因此需要从数据流中再读取2个二进制位(因为状态值为5个二进制位)。
(5) 继续读取数据流的最后2个二进制位00,并把它加到110后,现在的状态值为11000(即十进制数24)。
(6)找到24在表中的出现位置,为[A,11]。
(7) 输出符号A。
(8) 11(二进制为1011)只有4位,因此需要从数据流中再读取1个二进制位,此时状态值为10110(即十进制数22)。
(9)找到22在表中的出现位置,为[B,8]。
(10) 输出符号B。
(11) 8(二进制为1000)只有4个二进制位,继续读取1个二进制位,此时状态值为10000(即十进制数16)。
(12)找到16在表中的出现位置,为[A,7]。
(13) 输出符号A。
(14) 7(二进制为111)只有3个二进制位,继续读取2个二进制位,此时状态值为11111(即十进制数31)。
(15) 由于状态值现在等于最大值maxVal(11111),我们知道这是结束的标志,因此停止解码。(16)将得到的字符串倒置,就得到了源字符串ABAC。
5、压缩从哪里来的
答案是压缩来自于逐位输出(bit-wise output)。
因为出现可能性越小的符号其列高越低,有效的行号值离最可能出现的符号也就越远(二进制位距离意义上的远),所以为了得到更小的行号,就需要进行更多次的右移操作,这也意味着每次循环会有更多的二进制位输出到数据流。因此,出现可能性越小的符号,就会输出更多的二进制位到最终的数据流中。
位数越多,空间的精确度就越高(因此,maxVal的值也越大)。这也会让备查表中出现更少的精度冲突,因为更大的空间可以让整数与通过 P(S) * maxVal 计算出来的值更接近。
当然,这样做也会有不利的一面。精确度高了,就需要有更大的备查表,创建这张表需要的时间就会越长,存储表需要的空间也会越大。因此,要根据特定的情况,综合考虑性能和存储的要求权衡取舍。
如何选择压缩算法
例如,ZHuff、LZTurbo、LZA、Oodle和LZNA这些压缩工具已开始使用ANS。实际上,在2013年,这一算法又出现了一个被称为有限状态熵(Finite State Entropy,FSE)的更注重性能的版本,它只使用加法、掩码和移位运算,使ANS对开发人员更具吸引力。它的性能是如此强大,以至于2015年推出了一款名为LZFSE的GZIP变种,作为苹果下一代iOS版本的核心API。
目前看来未来的路似乎很清楚:ANS和FSE将终结哈夫曼编码和算术编码在压缩领域内几十年的“霸主”地位。
自适应统计编码
前面介绍的所有统计编码算法,在编码开始之前都需要遍历一次数据,以计算出各符号出现的概率。这样做是有缺点的,为了计算概率总需要多遍历一次数据集,而在计算出整个数据集中各符号的出现概率后,还要继续处理这些数值。如果是相对较小的数据集,那么这些就不是什么问题。
然而,随着要压缩的数据集变大,统计编码的结果与熵的偏差也会越来越大,这是因为数据集的不同部分有着不同的概率特征。如果处理的是流数据,比如视频流或音频流,由于整个数据集没有“结尾”,因此就不能“遍历两次”。
在数据流中,字符Q可能会在前三分之一部分出现很多次,而在后三分之二部分则一次也没有出现。统计编码算法的概率表无法处理字符Q分布的这种局部性。如果字符Q出现的概率为0.01,那么通常我们会期望它在整个数据流中均匀分布,也就是说,大约每100个字符中就有1个是Q。
然而实际数据的情况并非如此,数据中总会存在某种类型的局部偏态(locality-dependent skewing),将某些符号、想法或者单词集中在数据集的某个子区间里。
这让我们接触到数据压缩领域内一个重要的理论,即局部性很重要(locality matters)。
编码时不再提前扫描并去找合适的分割点,而是允许统计编码算法自动“重置”。
这一过程在概念上很简单,就是在编码时,如果“期望”的熵与“实际的符号平均二进制位数”之间出现显著差异,那么统计编码算法会重置概率表,并使用重置后的概率表进行编码。
这种具有适应数据流熵的局部特性能力的统计编码算法,通常被称为“动态”或“自适应”统计编码算法。
这些算法变体构成了大多数重要的、高性能的、高压缩率的多媒体数据流(如图片、视频及音频)压缩算法的基础。
自适应 VLC 编码
一般来说,统计压缩有3个步骤:
(1) 遍历数据流并计算各个符号的出现概率;
(2) 根据概率为符号生成VLC;
(3) 再次遍历数据流并输出对应的码字。
从上面可以看出,压缩时需要遍历(或者说扫描)数据流两次,并且整个数据集只有一套VLC表。这里的问题是,VLC表是静态的。
而在自适应的压缩算法中,这3个步骤简化为仅遍历一次数据集,但是过程要更复杂。关键是符号码字对应表并非必须一成不变,相反,可以根据读到的符号更新它。
1、动态创建 VLC 表
动态创建VLC表的原理:
在编码器处理数据流时,每读取一个符号,编码器都会问:
•这个符号之前出现过吗?
•如果出现过,那么输出当前分配的码字,并更新其出现的概率。
•如果没有,则进行一些特殊处理
假定你正在处理某个数据流,已经知道了其中的符号及相应的概率期望。目前已有的VLC表如下表所示。
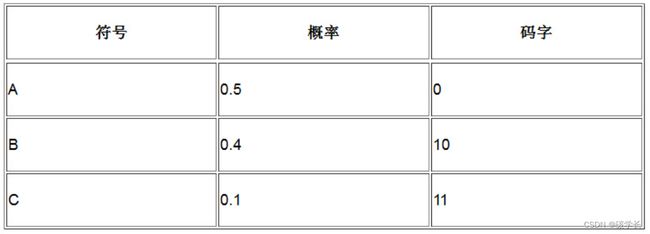
接下来,需要从输入流中读取下一个符号,这个符号恰好是B,于是进行下面的操作。
(1) 输出B当前对应的码字10。
(2) 更新相应的概率,因为B出现的可能性现在变大了一些(其他符号出现的概率变小了一些),更新后的表如下所示。

(3) 继续读取下一个符号,还是B,因此再次输出10,并继续更新相关符号的概率。再次更新后的表如下所示。

注意,这里有一件重要的事情发生。由于B已经成为数据流中最可能出现的符号,因此将最短的码字分配给它,如果下一次读到的符号还是B,那么相应的输出会是0,而不是之前的10。
通过动态更新读到的符号的出现概率,我们就可以根据需要去调整分配给各个符号的码字长度。
解码
从现成的频率以及下表开始:
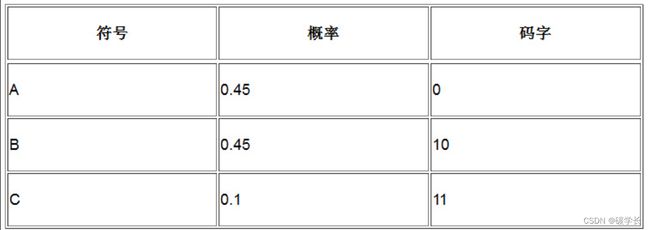
从输入流中去读当前存在的码字,这里是10,然后输出B。由于B再次出现,因此需要更新概率表,更新后的表如下所示。
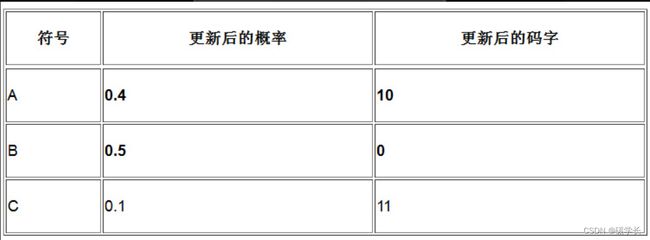
看,这张表的变化与编码时完全相同。
只要解码器更新符号表的方式与编码器相同,那么这两张表就会始终保持同步。
编码流程
(1) 从输入流中读取符号。
(2) 输出该符号对应的码字到输出流中。
(3) 更新符号的出现概率并重新生成码字。
解码流程
(1) 从输入流中读取码字。
(2) 输出该码字对应的符号到输出流中。
(3) 更新符号的出现概率并重新生成码字。
这就是自适应统计编码算法工作的大致流程。编码器和解码器都会动态更新符号的出现概率及相应的码字,这通常以积极的方式影响压缩。
2、字面值
然而,现在我们仍然面临以下两个问题。
•在开始编码前,最初的 VLC表是什么样子?
•在解码过程中,如果读到一个 VLC表中不存在的符号该怎么办?
这两个问题实际上是同一个问题的两种问法,答案是字面值词条(literal tokens)。
字面值流(literal stream),指的是只包含字面值的数据流,换句话说,就是那些实际上被编码的符号流,而且是根据其在数据流中出现的先后顺序排列的。
举个例子,如果数据流是“AAAAABCABC”,那么对应的字面值流为“LITERAL/A/B/C”,编码后的二进制流则为00 1010 01 00 00 00 01 101101 1100 00 10 11.
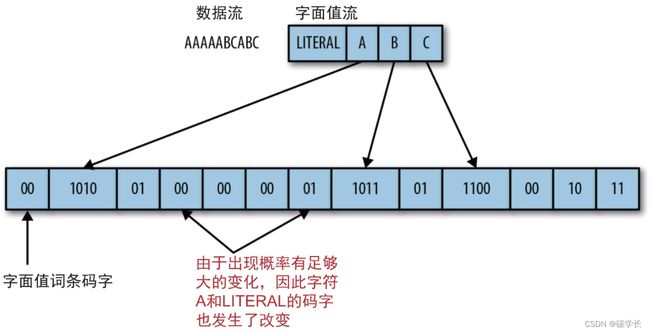
在编码过程中,当编码器读到一个之前没有遇到的符号时,它需要做以下两件事。
(1) 将LITERAL对应的码字写入输出流。
(2) 将读到的新符号添加到字面值流中。而在解码过程中,当解码器读到一个LITERAL码字时,则需要做下面两件事。
(1) 从字面值流中读取下一个字面值。
(2) 将该字面值写入输出流并更新VLC表。
例子如下:
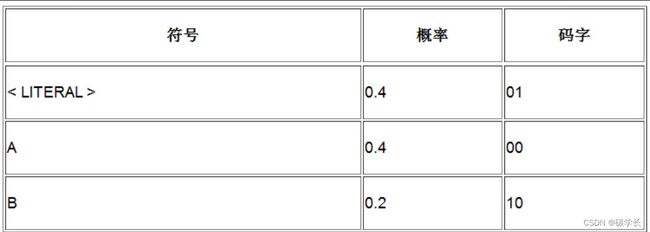
开始编码时,我们还没有读任何符号,因此对于读到的第一个符号,需要输出一个字面值。因为这是唯一的选择,所以VLC表最开始只包含LITERAL这个符号,其出现概率为100%,对应的码字为00,如下表所示。

当我们从输入流中读到一个新符号时,将LITERAL对应的码字输出,后面跟着新符号的二进制位。与前面的操作类似,接着就需要更新符号表以及各符号的出现概率。

假定之后又读到符号A,接着又读到另一个新符号B,因此,读到的符号依次为< LITERAL > A A B,现在的概率如下表所示。
因此,对于输入字符串AAAAABCABC,下面是完整的编码过程示例。
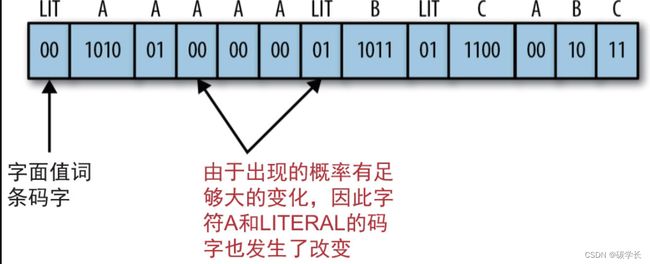
这些字面常量未编码时的4个二进制位表示分别为:
A = 1010
B = 1011
C = 1100
注意,对于VLC,我们将仅使用00、01、10、11这样两位长的码字来简化说明。
(1) VLC表中仅包含LITERAL这个字符,其出现概率为1.0,对应的码字为00。
(2) 读取第一个符号A。
a. 符号A不在VLC表中,因此需要输出字面值词条LIT的码字(即00),然后是A对应的4个二进制位表示:1010。
b. 将符号A添加到VLC表中,并根据符号的出现频次更新表。由于A和LITERAL各出现一次,因此两者的出现概率均为0.5,并为两个符号分配码字:LIT = 00,A = 01。
(3) 继续读下一个符号,还是A。
a. 由于A已经在表中,因此输出其对应的码字01。
b. 更新VLC表。符号A已成为最经常出现的符号,因此需要重新分配相应的码字:A =00,LIT = 01。
(4) 继续读取下一个符号,还是A。输出A对应的码字00 并更新VLC表中的概率。
(5) 继续读取下一个符号,又是A。输出A对应的码字00 并更新VLC表中的概率。
(6) 继续读取下一个符号,仍然是A。输出A对应的码字00 并更新VLC表中的概率。
(7) 继续读取下一个符号,是B。
a. B不在VLC表中,因此需要输出字面值词条LIT的码字(即01),然后是B的4个二进制位表示:1011。
b. 将B添加到VLC表中并更新表,A = 00,LIT = 01,B = 10。
(8) 继续读取下一个符号,是C。
a. C不在VLC表中,因此需要输出字面值词条LIT的码字(即01),然后是C的4个二进制位表示:1100。
b. 将C添加到VLC表中并更新表,A = 00,LIT = 01,B = 10,C = 11。
(9) 继续读取下一个符号,是A。
输出A对应的码字00 并更新VLC表中的概率。
(10) 继续读取下一个符号,是B。
输出B对应的码字10 并更新VLC表中的概率。
(11) 继续读取下一个符号,是C。
输出C对应的码字11 并更新VLC表中的概率。
因此,最终的输出流为00 1010 01 00 00 00 011011 01 1100 00 10 11
3、重置
自适应统计编码的真正强大之处在于,当输出流的熵要变大失控时,它能重置输出流。
以[AAABBBBBCCCCCC] 为例,并将符号放在尖括号中来表示相应的字面值,如< A > 。
对上述字符串编码后,得到如下的输出:
< A > ,0,0, < B > ,1,1,1,0, < C > ,11,11,11,11,0
注意,最后的码字0对应的是最后一个符号C,此时C的出现概率已经足够大,因而需要重新为其分配码字。从中可以看到,更多的符号以及特定符号的更多出现是如何影响最终输出的平均二进制位数的。当然,如果遇到符号C时就能重置VLC表,从而得到用码字0表示所有的C这样理想的结果就更好了,此时得到如下的输出:
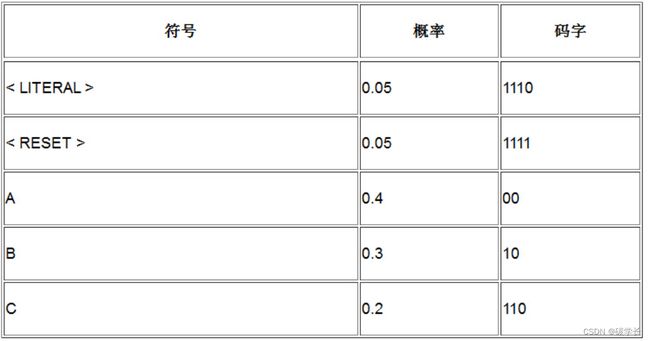
< A > ,0,0, < B > ,1,1,1,0, < C > , < RESET >0,0,0,0,0
结果表明,我们完全可以采用与字面值相同的策略,创建一个< RESET > 词条,如下示例表所示。当解码器遇到这个词条时,它就会重置符号表并重新开始解码。编码与解码的工作原理与前面介绍的相同。
< RESET >和< LITERAL > 会一直在符号表中存在(像其他符号一样),但随着时间的推移,这两个符号出现得越来越少,因此其出现概率也变得越来越小。下表就展示了< RESET >和< LITERAL > 这两个词条最终成为小概率符号的情况。
4、知道何时重置
为了做出重置的决定,需要做以下3件事。
•为重置设定一个阈值,也就是说,当符号平均二进制位数(bits-per-symbol,BPS)为某个值时,放弃现有的 VLC表并重新开始。
•大致计算一下当前输出流的 BPS,并与设定的阈值比较。
•计算当前已读取的输入流的熵。
当输出流的BPS超过设定的阈值时,例如比BPS大5个二进制位,就可以认为数据流已经发生了显著变化,应该重置概率值。
输出符号的平均二进制位数=输出流的二进制位数/目前已读的符号数
当比较熵与输出符号的平均二进制位数时,比较结果就会表明输出流偏离预期BPS的程度。
当偏离的程度大于设定的阈值时,应该重置VLC表,因为此时输出流已经太过冗余膨胀了。
阈值不是硬性规定,其取值也与数据流本身及编码器有关。每种支持此种重置的编码器,都可以根据处理数据的不同而对相应的参数调整优化。
5、实际中的应用
在实际场景中没有人会使用这种简版的自适应VLC算法。
相反,大多数的现代压缩工具已完全采用自适应版的哈夫曼编码器与算术编码器,它们都可以动态生成概率表,并实时更新符号对应的码字。
但是,介绍自适应 VLC 编码的概念时动态 VLC 算法(即动态概率表、重置和字面值)的力量之源,并且大量应用于自适应哈夫曼编码与自适应算术编码中。
自适应算术编码
要将算术编码变成自适应的很容易,这主要是因为其编码步骤与概率表之间的交互很简单。只要编码器与解码器在更新概率的正确顺序上达成一致,我们就能根据需要更新概率表。
假定当前的概率表如下表所示。
(1) 读取下一个输入符号,假定是字母G。
(2) 按G当前的概率对其进行编码。
(3) 根据新信息更新概率表。(由于不知道之前的输入流,因此这里假定下表所示的就是更新后的概率值。)
(4) 根据概率表重新分配区间。
增加字面值与重置词条后,其工作原理仍然与自适应VLC相同。我们可以将这些词条指定为附加符号,并相应地调整它们的权重。
自适应哈夫曼编码
自适应哈夫曼算法每次读取和处理符号时调整现有的树。这就让情况变得稍微有些复杂,因为每读取一个符号都必须要做以下这些事情:
•更新概率;
•对树的大量结点变换位置并重新排序,以使它们与概率的变化同步;
•使树的结构满足哈夫曼树的要求。
自适应哈夫曼算法的最初版本是由Faller(注1)于1973年提出的,1985年高德纳(注2)又对此算法做出重大改进,但是所有现代的版本都是建立在Vitter(注3)于1987年提出的方法之上。
注1:参见Newton Faller的论文An AdaptiveSystem for Data Compression,载于Record of the 7th Asilomar Conferenceon Circuits, Systems, and Computers(lEEE,1973),第593~597页
注2:参见高德纳的论文Dynamic Huffman Coding,载于Journal of Algorithms,1985年第6期,第163~180页。
注3:参见Jeffrey S. Vitter的论文Design andAnalysis of Dynamic Huffman Codes载于Journal of the ACM,1987年10月,第34期,第825页。
示例:
以字符串“aabbbacc”的编码和解码为例,假设原始共有四类字符(a,b,c,d),规定初始化编码:a-00,b-01,c-10,d-11,此为编码器与解码器双方的约定。
编码过程:

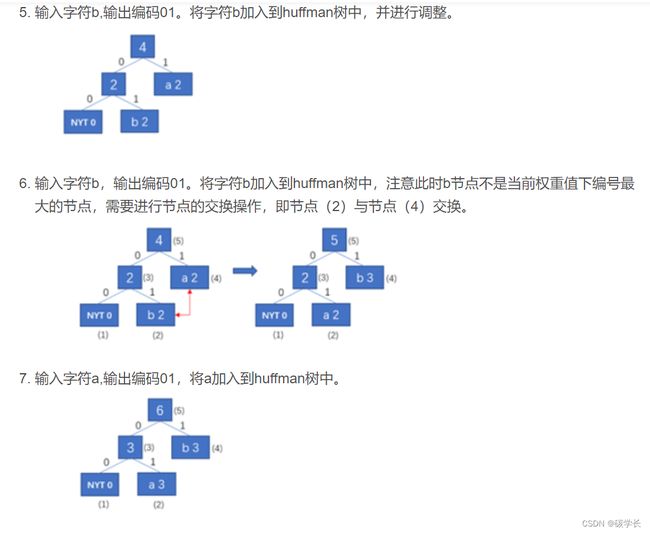
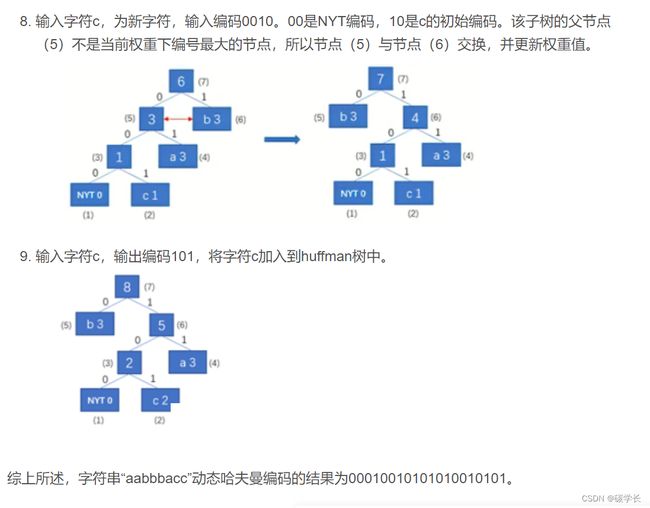
解码算法也使用仅有唯一的NYT节点的编码树作为初始状态,然后根据Huffman编码数据流,对符号进行还原。每次处理完一个符号,就使用这个符号调整编码树。这样,在每一次输入新的符号之前,Huffman树都处于与进行编码时使用的Huffman树完全相同的状态,保证了解码的正确性。
现代的选择
大多数的统计编码算法主要关注的是图片(WebP)和视频(WebM、H.264)文件的压缩。
如果处理的是少量的数据,那么简单的静态统计编码算法就可以工作得很好,并且可以让我们以较低的复杂度实现熵。
如果处理的是大量的数据或者多媒体数据,而且运行时的性能很重要,那么采用自适应统计编码算法无疑是正确的选择。
字典转换
虽然VLC一直都在发挥作用,但它与熵绑定的事实也限制了数据压缩未来的发展。因此,当大多数研究人员在尝试寻找更有效的VLC技术时,也有少数研究人员选择了不同的路,他们找到了使统计压缩可以更有效地预处理数据的新方法。
这种新方法通常被称为“字典转换”(dictionary transforms),它完全改变了人们对数据压缩的认知。
事实上今天所有的主流压缩算法(比如GZIP或者7-Zip)都会在核心转换步骤中使用字典转换。
基本字典转换
统计压缩主要关注数据流中单个符号的出现概率,这一概率与其周围可能出现的符号无关。但忽略了真实数据的基本属性:上下文及词语的组合,或者简单地说就是短语。
例如,对短语“TO BE OR NOT TO BE”,不必将每个字母都当作一个符号去编码,而将实际的英语单词当作符号去编码。这样一来,创建的符号码字对应表就会如下表所示(忽略单词间的空格)。

这样编码后,得到的结果为000110110011。按原来的方式对每个字母编码,最终的结果需要104个二进制位;而按现在这种方式对每个单词编码,最终的结果只需要12个二进制位。
字典转换的工作方式也正如你期望的那样:给定源数据流,首先构建出单词字典(而不是符号字典),然后再将统计压缩应用到字典中的单词上。
字典转换并非是要去替代统计编码,相反,它只是你先应用到数据流上的一个转换,这样统计编码算法就能更有效地对其编码.

字典转换实际是一个数据流的预处理阶段,经过这样的预处理后,生成的数据集会更小,比源数据流压缩率更高。当能识别出那些经常重复使用的长字符串,并为它们分配最短的码字时,字典转换的效率最高。
找出正确的“单词”
可以通过被称为分词(tokenization)的过程找出这些“单词”,即分析一组数据并从中找出理想的“单词”。分词这一过程相当复杂,它本身也是信息论领域的一个研究分支(并有相关专利)。
为了找到数据流的理想分词,我们需要有某种方法来处理现有的和那些还没有遇到的符号,并能以一种高效的方式将两者合并为尽可能长的符号集。
比如 LZ 算法这种方法
LZ 算法
1977年,两位研究人员Abraham Lempel和Jacob Ziv提出了几种解决“理想分词”问题的方法。这些算法根据提出的年份分别被命名为LZ77和LZ78,它们在找出最佳分词方面非常高效,30多年来还没有其他算法可以取代它们。
LZ 算法的工作原理
LZ算法尝试通过在读取的字符串中寻找当前单词的匹配来分词。与读取一组符号然后向后查找它是否重复出现不同,LZ算法向前查找当前单词是否出现过。这样做会对编码过程产生如下两个重要影响:
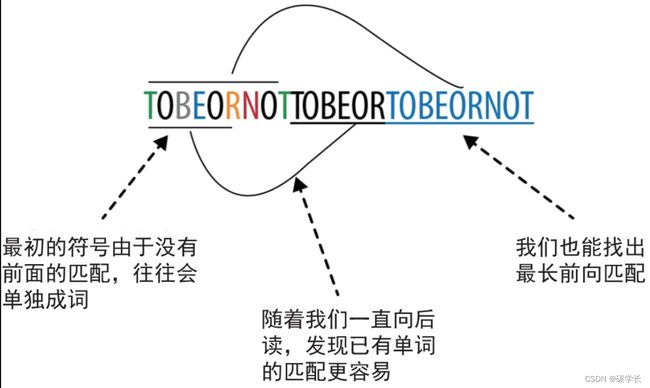
•在数据流的前半部分,由于我们见过的单词很少,因此出现新单词的可能性很大;而在数据流的后半部分,由于已经有了很大的缓冲区,因此出现匹配的可能性更大。
•向前寻找匹配可以让我们找出“最长的匹配词”。
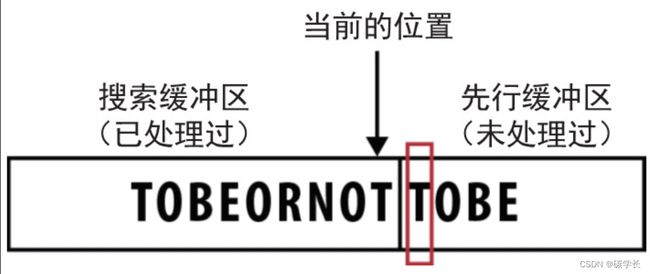
1、搜索缓冲区
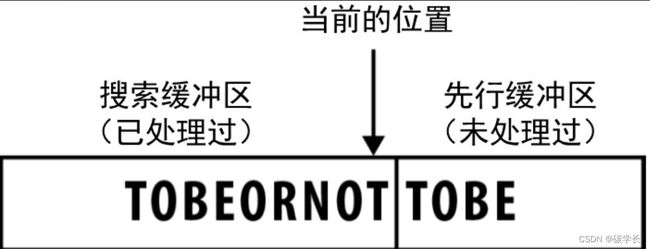
LZ算法的工作原理是将数据流分成如下两部分。
•数据流的左半部分通常被称为“搜索缓冲区”(search buffer),包含的是已经读过并处理过的符号。
•数据流的右半部分则被称为“先行缓冲区”(look ahead buffer),包含的是将要编码的符号。
因此,当前“读取”的位置就位于两个缓冲区之间,如下图所示:
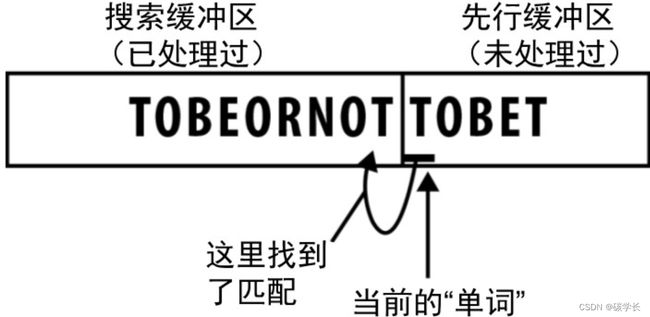
2、找出匹配
找出匹配其实就是搜索缓冲区与先行缓冲区之间一种有机的相互作用。
找出匹配的过程如下图所示:


3、“滑动窗口”
然而,在实际实现时,数据流中可能有上百万个词条,我们不可能去搜索所有处理过的符号。因为如果不对搜索缓冲区的长度加以限制,就会遇到内存及性能方面的问题,所以搜索缓冲区通常只会包含32 KB已经处理过的字符。因此,当移动当前位置时,搜索缓冲区的“滑动窗口”(sliding window)也会跟着移动,如下图所示:

有了滑动窗口,查找匹配的性能要求也就有了上限。它同样也考虑到了局部性原理,即在给定的数据集中相关的数据很可能分布在相似的局部区域。
一般来说,搜索缓冲区滑动窗口的长度大概为几万个字节,而先行缓冲区的长度则只有几十个字节。
4、用记号标记匹配
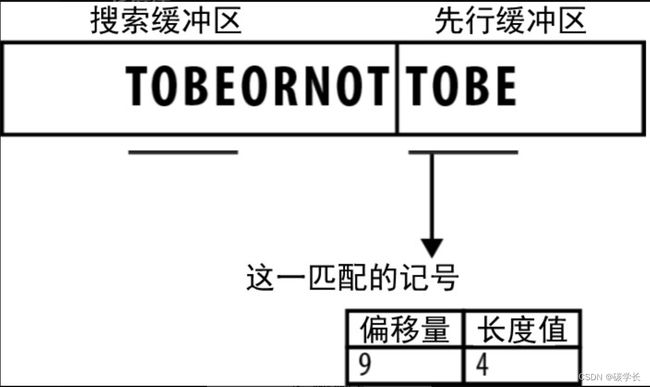
当匹配最终确定下来,编码器就会生成一个固定长度的记号并将它写入输出流。该记号主要由两部分组成:偏移量和长度。
偏移量
该值表示的是搜索缓冲区中匹配单词的起始位置,从当前位置向前数。在前面举的例子中,匹配的字符串需要从当前位置往前数9个字符。
长度值
该值表示的是匹配单词的长度。在本例中,匹配单词的长度为4(即包含4个符号)。
具体到本例中,找到的匹配位于当前位置9个符号前,且其长度为4,因此将二元组[9,4] 写入输出流,如下图所示:
解码器会以非常简单的方法逆转换这些值:
(1) 读取下一个词条;
(2) 以当前位置为起点,在搜索缓冲区中往前数偏移量个符号;
(3) 抓取长度值个符号并添加到数据流后面。
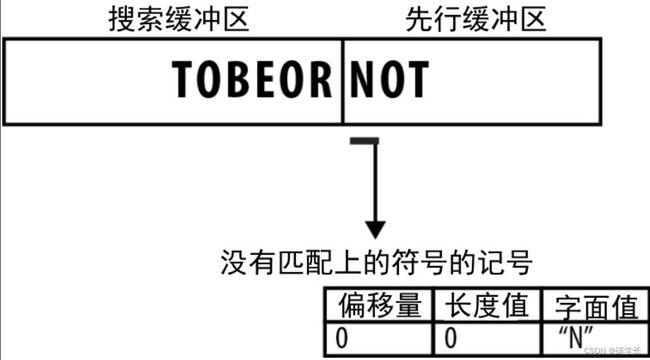
5、没有找到匹配时
一种最基本的做法是,将修改后的记号表示为三部分,前两部分与前面介绍的相同,还是偏移量和长度值,只不过取值都为0,即[0,0],最后一部分则是符号的字面值:
编码
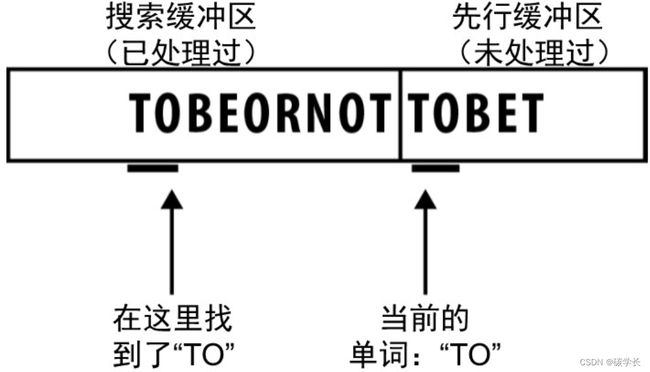
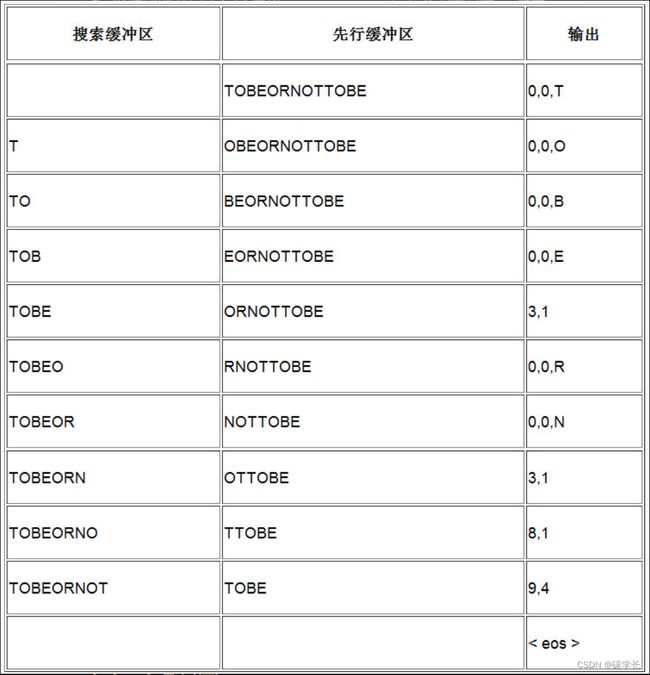
以字符串“TOBEORNOTTOBE”为例。
(1) 开始的4个符号在搜索缓冲区找不到匹配,直接输出字面值记号。
(2) 当在先行缓冲区中读到第二个“O”时,我们在搜索缓冲区找到一个单个值的匹配,因此输出记号(3,1)。
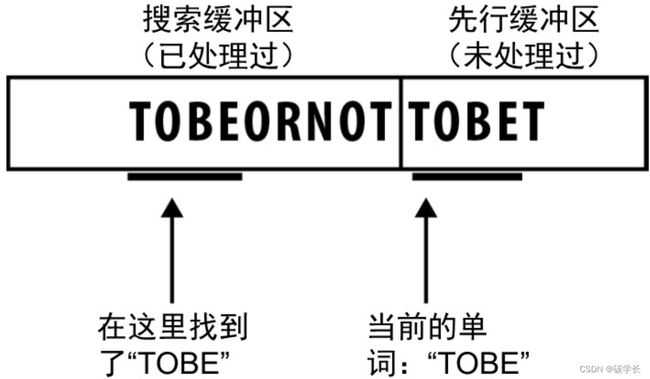
(3) 继续这一过程,发现找不到匹配或者仅找到了单个值的匹配。
(4) 当读到字符串的结尾时,情况变得有意思起来,我们发现在搜索缓冲区的最开始找到了TOBE的匹配,其位置为9,长度为4。
下表展示整个编码过程:
解码
整个解码过程全靠读取输入的记号:
•当解码器读到字面值记号时,就将该值输出到恢复缓冲区;
•当解码器读到“匹配”的记号时,会从当前的位置往前数偏移量个符号,以此为起点将长度值个符号添加到恢复缓冲区的结尾。具体过程如下表所示:

压缩 LZ 算法的输出
经过LZ变换后所生成的编码后的数据流比源数据流小。
对那些有很多重复单词的数据流来说,你可以用小得多的记号对它进行编码,这就是LZ算法吸引人的地方。
LZ算法真正吸引人的地方还在于它可以和统计编码结合使用。可以将记号中的偏移量、长度值以及字面值分开后,再按照类型合并,组成单独的偏移量集、长度值集和字面值集,然后再对这些数据集进行统计压缩。
例如,可以将前面例子输出的记号集[0,0,T][0,0,O][0,0,B][0,0,E][3,1][0,0,R][0,0,N][3,1][8,1][9,4] 分成以下3个数据集。
偏移量集 0,0,0,0,3,0,0,3,8,9
长度值集 0,0,0,0,1,0,0,1,1,4
字面值集 T,O,B,E,R,N
LZ 算法的变体
一些重要的算法:
LZ77、LZSS、LZ78或LZ2、LZW算法。
上下文数据转换
除了字典变换之外,还有一整套其他的变换都是按照同样的原理工作的:给定一组相邻的符号集,对它们进行某种方式的变换使其更容易压缩。我们通常称这样的变换为“上下文变换”(contextual transform),因为在思考数据的理想编码方式时,这些方法考虑到了邻近符号的影响。
这些变换的目标是一致的,即通过对这些信息进行某种方式的变换,使统计编码算法对其进行压缩时更高效。
有3种对现代的数据压缩来说最为重要,即行程编码(run-length encoding,RLE)、增量编码(delta coding)和伯罗斯–惠勒变换(Burrows-Wheeler transform,BWT)。
RLE:行程编码
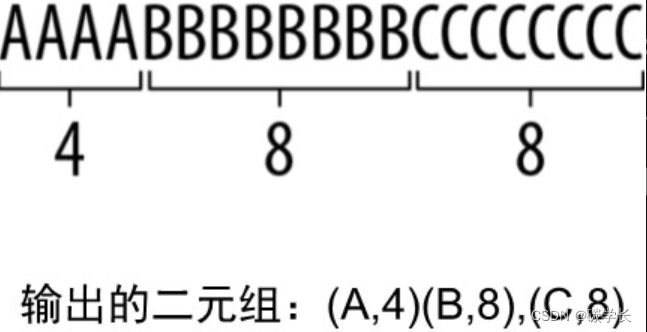
RLE主要针对的是连续出现的相同符号聚类的现象,它会用包含符号值及其重复出现次数的元组,来替换某个符号一段连续的“行程”(run)。例如,字符串AAAABBBBBBBBCCCCCCCC就可以编码为[A,4][B,8][C,8]。
解码工作则相反,给定某个符号值及其长度值的二元组,只需要将正确个数的符号添加到输出流之后就行了。
处理短行程问题
根据RLE的算法,字符串AAAABCCCC会被编码为[A,4][B,1][C,4]。由于字符串中间只有1个B,因此编码后B由一个字符变成字符及其长度值的二元组,反而变大了。
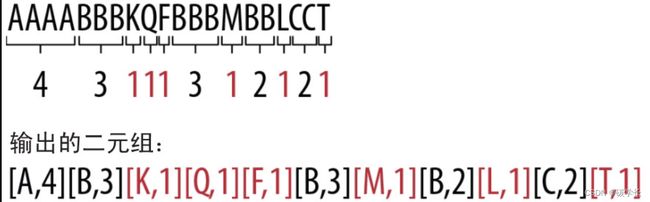
可以只对那些行程长度大于2的符号编码。有了这样的假定,字符串AAAABCCCC就可以编码为[A,4]B[C,4]。
如果将编码后的数据流转换为二进制,那么最终得到的结果为100000110010000101000011100。
如果你认真观察,就会发现每个字面值都是7位的ASCII码,因此整个二进制串的正确划分为1000001|100|1000010|100011|100
这样就无法分清字符B从哪里结束以及字符C从哪里开始。一般来说,数据流中交错出现字面值是会出问题的。
因此,需要有一种方法来区分哪些字符编码后是二元组哪些字符不是。
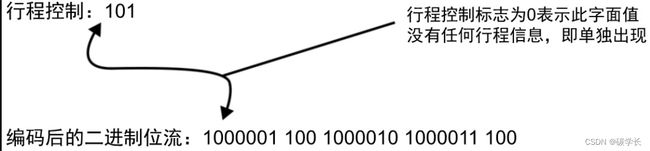
通常采用的方法是,在数据集中增加一个二进制位流,来表示某个给定的符号流中各个符号是否连续重复出现。
因此,要在100000110010000101000011100之前加上二进制位流101,它表示第一个符号连续重复出现,第二个符号没有连续重复出现,第三个符号又连续重复出现。这样,通过为每个行程(符号)增加1个二进制位的标志位,就节省了存储短行程所需的额外开销。
RLE算法最适用于大多数符号都连续重复出现的数据集。如果要处理的数据集没有这样的性质,那么RLE算法并不适用。
压缩
压缩RLE算法输出的结果需要一些技巧。首先,需要将数据集分成两部分:字面值流和行程长度流。(还记得加到最前面的二进制位流吗?它会告诉我们解码时需要从哪个流中读取数据。)对字面值流,可以根据自己的意愿选择一种编码器,剩下的行程长度流才是压缩问题的真正所在。因此,下面将使用试错这种非常现实的方法,为行程长度流找到合适的编码。
。虽然RLE在现代压缩工具中用得并不多,但还是有人在研究更高效的RLE。例如,最近就出现了一种新的RLE压缩工具TurboRLE,号称是速度最快、效率最高的RLE编码器。
增量编码
增量编码:适合于数值型数据。
增量编码,其实就是将一组数据转换为各个相邻数据之间的相对差值(即增量)的过程。它背后的思想是,给定一组数据,相关的或相似的数据往往会集中在一起。如果这样,有了两个相邻值之间的差,就可以用其中一个值以及该差值来表示另外一个值。一般来说,我们会用当前值减去前一个值,然后将差值写入输出流。
例如:
[1,3–1,6–3,8–6,10–8] → [1,2,3,2,2]
但对于:
[1,3–1,10–3,8–10,6–8] → [1,2,7,–2,–2]
这样有负数的情况,增量编码就不适合了。
也有一些改进的方法:
XOR 增量编码
减法增量编码算法的问题是,结果中可能会出现负数,进而产生各种问题。负数不仅在存储的时候需要额外的二进制位,此外还可能会增大数据的变化范围。
例如:
[1,3,10,8,6] → [1,3–1,10–3,8–10,6–8] →[1,2,7,–2,–2]
可以通过使用按位异或运算(bitwise exclusive OR,XOR)代替减法运算来解决这一问题。
XOR会独立地对每个二进制位进行操作。XOR是一种逻辑运算,仅当两个输入不相同时(即其中一个为真,另一个为假时)结果为真。
例如:
0101( 十进制为5)
XOR 0011( 十进制为3)
= 0110( 十进制为6)
注意,与1 XOR相当于对该位取反。又如:
0101( 十进制为5)
XOR 1111( 十进制为3)
= 1010( 十进制为10)
任何值与自己XOR其结果总是0。
XOR完全绕开了负数出现的问题,因为整数之间的XOR根本不可能产生负数。
再次以[1,3,10,8,6] 这组数据为例,由于
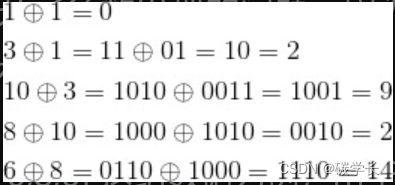
因此,XOR增量编码生成的结果为[1,2,9,2,14]。
虽然这同样没能缩小数值的变化范围,因为存储每个值还是需要4个二进制位的空间,但它的确保证了无论数值之间的相互顺序是怎样的,编码后的每个值都是正的。
参照系增量编码
考虑下面这组数:[107,108,110,115,120,125,132,132,131,135]
参照系方法通过让其他数减去最小的数来解决上面这个问题。在本例中,所有的数都处于107~135。因此,与其对原始序列进行编码,不如先让每个数都减去107,然后再对所得差值进行增量编码,即对[0,1,3,8,13,18,25,25,24,28] 进行编码。
“参照系”(frame of reference,FOR)中那个“参照数”(frame)的选取,与将转换恰当地应用到数据集上有关,因此需要将数据集细分为更小的数据组。
例如,可以将前面那组数拆分成以下两组数:
[107,108,110,115,120] 和[125,132,132,131,135]
使用参照系增量编码处理之后,
得到:[107,0,1,3,8,13] 和[125,0,7,7,6,10]
为数据集确定了参照数后,数值的变化范围缩小了,因此表示每个值所需要的二进制位数也变小了。
遗憾的是,离群值还是可能造成很多问题。
修正的参照系增量编码
继续考虑以下数据:
[1,2,10,256]
增量编码后,
得到:
[1,2–1,10–2,256–10] = [1,1,8,246]
这组数据中的离群值基本上破坏了对其余数据的压缩。
修正的参照系增量编码(Patched Frame of Reference Delta Coding,PFOR)工作原理为:
(1)选择一个位宽度 b。
(2)遍历数据并用 b 位对每个值编码。
(3)当遇到的值所需的编码位数大于 b 时,将这样的离群值存储在单独的位置。
PFOR的神奇之处就在于其对离群值的处理:
(1)考虑前面的例子增量编码后得到的结果,即[1,1,8,246]。
(2)用最简单的形式将这组数据分成两部分,即编码需要的二进制位数不大于 b 的以及大于 b 的。当 b = 4 时,得到[1,1,8][246] 这两组数据。
(3) 用4位对第一组中的每个数编码,用8位对第二组中的离群值编码。
(4)为了让离群值能合并到源数据列中,需要知道它的位置信息,因此得到的结果为[1,1,8][246][3]。
在解码时,我们需要取出离群值并将它们放回源数据流,然后再进行增量编码的逆操作。
1、选择合适的 b 值
使大多数值在编码时需要的位数不超过 b,并且可以通过它识别出那些离群值。
通常可以逐步做到这一点。可以从 b = 1开始试验,看看数据集中有多少数小于 2^1,如果数据集中90%的数小于2,那么就将 b 设置为1。否则,令 b 的值为2,再看看数据集中有多少数小于2^2。如有必要,可以重复这一过程,比如令 b 的值为3并看看有多少值小于 2^3,直到数据集中90% 的值满足条件。
2、怎样处理离群值
根据原始论文Super-Scalar RAM-CPU Cache Compression 的叙述,PFOR没有将整个的离群值原样扔进一个新的列表中,而是将最低的“b”位留在源数据流中,并将剩下的部分存储在离群值列表中。
压缩增量编码后的数据
如果增量编码能做到以下两点,那么我们就可以认为它生成的数据更容易压缩:
•将数据集中的最大值变小,因此缩小了数值的变化范围;
•生成了许多重复值,可以让统计压缩的效率更高。
MTF
MTF反映了如下的预期:如果一个符号在输入流中出现了,那么它很有可能会出现多次,或者至少短时间内会成为常见的符号。MTF是局部自适应的,因为它会根据输入流中局部区域符号的出现频次进行调整。如果输入流满足了这样的预期,换句话说,如果输入流中出现了相同符号集中的情况(即输入流中符号的局部频次会出现显著的变化),那么MTF会产生好的结果。
下图展示了MTF的完整过程,它是通过另外管理一组数据来工作的,其中包含的是数据集中所有不同的值,我们称为SortedArray。当从数据流中读取一个值时,我们会找出该值在SortedArray中的索引并将此索引值输出,然后更新SortedArray,将该值移到最前面,即让其索引变为0。
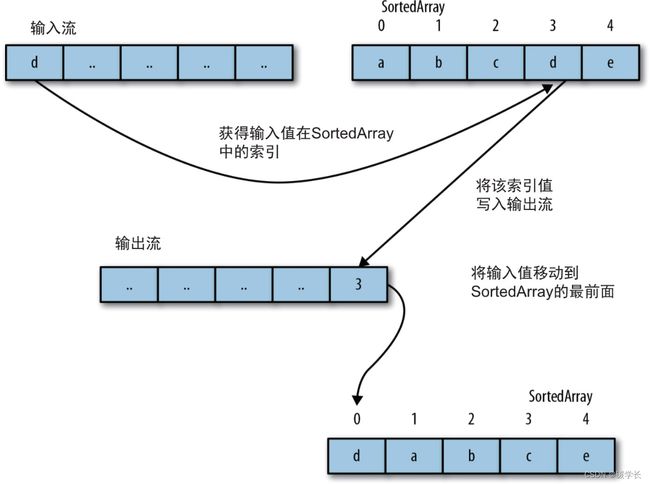
假定数据中的符号都是小写的ASCII字符,输入字符串为“banana”,初始状态下SortedArray中的字符是按字母顺序排列的。
(1) 读取字母“b”。
(2)“b”在SortedArray中的索引为1,因此将1写入输出流。
(3) 将“b”移动到SortedArray的最前面。
(4) 读取字母“a”,由于其现在的索引为1,因此输出1,同时将“a”重新移到最前面。
(5) 对其余的字母,按照顺序重复上面的过程,具体如下表所示。

解码器按照相反的步骤操作就能恢复源数据流。恢复时,输入流为[1,1,14,1,1,1],初始状态的SortedArray为[a,b,…,z],解码器每从输入流中读取一个符号,就将SortedArray中该索引对应的字符输出,再将该字符移到SortedArray的最前面。
消除捣乱符号的影响
MTF存在的一个问题是,有一些捣乱的符号会打乱前面存在的符号流。这个问题比较严重,因为会极大地破坏编码,而且在真实数据中普遍存在。一种解决方法是,不是一读到某个符号就将它移到最前面,而是采取一些探索式方法慢慢地将它移到最前面。
1、向前移动 k 个位置
如果采用这种方法,那么与当前符号匹配的元素就不再是直接移到SortedArray的最前面,而是将它前移 k 个位置。
有下面两种确定 k 值的简单方法:
•令 k = n(n 为符号的个数),原始的 MTF就是这种选择;
•令 k = 1,即某个符号被读取一次,它的位置就前移一位。
将 k 为1时,可能会对降低那些具有较好局部相关性的输入流性能,但是能更好地处理其他类型的输入流。而且,k = 1时算法实现起来也很简单,因为在更新SortedArray时只需要将当前读取的符号与前一个符号交换位置。这样设定之后,也能更好地处理那些捣乱符号,因为这些符号现在需要慢慢地移动到最前面,而不是一下子就移动到最前面。
2、出现 c 次移动
采用这种方法时,SortedArray中的元素只有在输入流中出现过 c 次之后(并非必须连续出现),才会移动到最前面。SortedArray中的每个元素都有一个计数器,记录该元素出现的次数。这样我们就可以为符号移动到最前面设定一个出现次数的阈值。当应用到文本上时,我们就可以通过最终生成的SortedArray,来反映所编码的语言各个字母的使用频率。
压缩 MTF
由于MTF生成的输出流中有很多的0和1,因此简单的统计编码算法就可以工作得很好。MTF的独特之处在于,符号在短时间内重复出现时,MTF会重新分配一个较小的值。而RLE会将最短的编码分配给那些连续重复出现的符号。实际上,MTF是最简单的动态统计转换形式之一。
BWT
有规则就有例外,BWT就属于例外。
从前面的介绍中可以看出,所有其他的压缩算法通常可以归为两类:统计压缩(即VLC)和字典压缩(如LZ78),这两类算法从不同的角度利用了给定数据流中存在的统计冗余信息。
BWT的工作原理并非如此。相反,它通过打乱数据流次序来让重复的子串聚集在一起。这一操作本身不能压缩数据,却可以为后续的压缩系统提供转换好的数据流,方便压缩。
顺序很重要
通过转换数据流中符号之间的顺序,可以让数据流更容易压缩。
最简单的重新排序就是直接将数据按顺序排列,例如,将[9,2,1,3,4,8,0,6,7,5] 排序为[0,1,2,3,4,5,6,7,8,9] 后,我们就可以将其增量编码为[0,1,1,1,1,1,1,1,1,1],它的熵值要比源数据小很多。
不过遗憾的是,纯粹的排序是单方向的。也就是说,在对数据排序后,如果没有更多额外的信息指明它是如何变化的,我们无法让数据重新回到未排序的状态。
因此,我们不能单纯地对数据进行排序,但可以近似地这样做。
BWT会打乱数据流中符号的顺序,并试图让相同的符号簇彼此靠近,这一行为通常称为字典序排列(lexicographical permutation)。或者更确切地说,通过BWT,我们可以找出原始数据集的一种排列,根据其顺序,该排列可能更容易压缩。
其中最值得关注的一点是:通过BWT,在编码与解码时无须增加太多的额外信息。
BWT 的工作原理
要开始BWT的“变换”工作,需要先创建一张表,其中包含输入流的所有移位排列。
举个例子,假定输入流是BANANA,那么需要将它写在表的第一行。然后,在接下来的每一行,我们都会对该字符串进行一次循环右移一位操作。也就是说,将除了最右边的字符之外的所有字符向右移一位,然后将最右边的字符放在最前面。继续进行这样的移位操作,直到对所有的字符都操作了一遍,如下所示。
BANANA
ABANAN
NABANA
ANABAN
NANABA
ANANAB
BANANA
接下来,BWT会对表中的每一行按字典顺序排序。看到所有的字符串又按照顺序排列,是不是感觉很好?
ABANAN
ANABAN
ANANAB
BANANA
NABANA
NANABA
注意每个字符串的最后一个字符。从上到下,这些字符组成了字符串NNBAAA,有意思的是,这恰好是BANANA的一种排列,而且与BANANA相比更好地将相同的字符聚集在了一起。
事实上,这正是我们在找的排列。从上面的过程中可以看出,按照顺序循环生成排列,然后排序,这样由最后一列字符组成的排列,与源字符串相比,能更好地将相同的字符聚集起来。因此,NNBAAA就是字符串BANANA经BWT后输出的结果。
观察排序后的表格,你会发现输入字符串的索引为3。
0 ABANAN
1 ANABAN
2 ANANAB
3 BANANA
4 NABANA
5 NANABA
在BWT的解码阶段,我们需要该索引值,因为它将使我们从更易压缩的排列回到源字符串上。
BWT 的逆操作
BWT最引人注目的特点并不在于它能生成更易压缩的输出(普通排序也能做到这一点),而在于只需要极小的数据开销,它所进行的变换操作就是可逆的(reversible)。
我们的目标是对BWT解码,而所给的条件是字符串NNBAAA和行索引3。
首先需要做的是重新生成排列表格。要做到这一点,就需要迭代利用排序和字符添加操作。
第一步将输出字符串写入下表中,它表示的是每一行的最后一个字符。
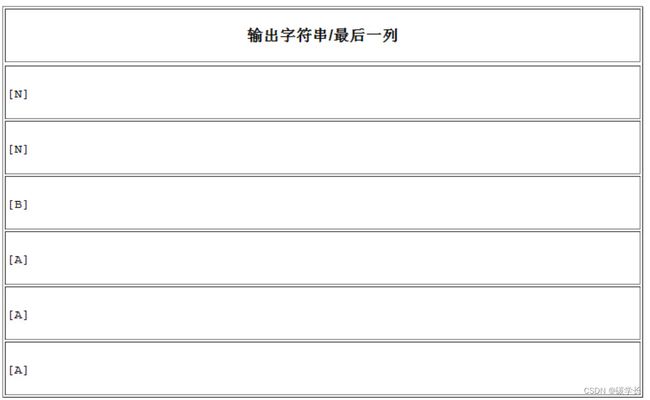
如果对这一列排序,其结果与原来的排序后表格的第一列相同,如下表所示:
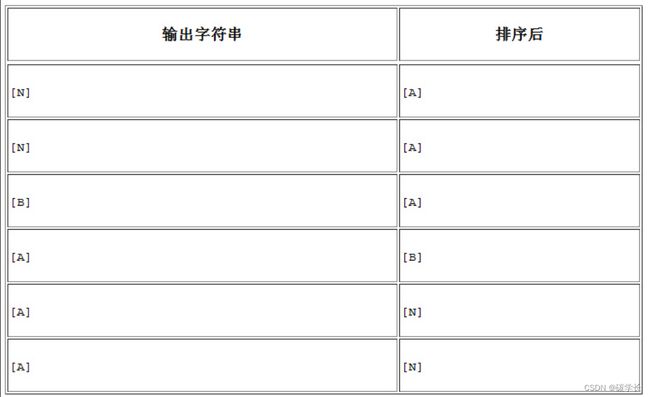
接下来将这两列合并,这样每行就都有两个字符了:
[NA]
[NA]
[BA]
[AB]
[AN]
[AN]
按字典顺序对每行排序,结果如下:
[AB]
[AN]
[AN]
[BA]
[NA]
[NA]
接着,将原始的输出字符串(NNBAAA)按顺序添加每行字符串的最前面(每行添加1个字符),所得结果如下所示:
[NAB]
[NAN]
[BAN]
[ABA]
[ANA]
[ANA]
然后,再次对每行字符串按字典顺序按列排序,继续将原始字符串按顺序添加到每行字符串的最前面并按列排序,直到整个输出矩阵的宽度等于输出字符串的长度,具体过程如下表所示。
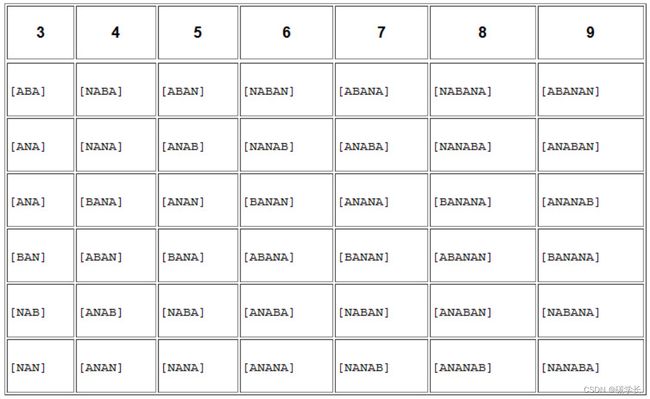
观察最后输出的矩阵,你很快就能发现如下两个神奇的性质:
•最后的矩阵与在编码器中生成的排序后的置换矩阵完全相同。这意味着,即使只给出排序后矩阵的最后一列,NNBAAA,我们也能利用它来恢复生成其整个排序后的矩阵。
•还记得在编码阶段输出的索引 3吗?由于这个矩阵与编码器中排序后的矩形完全相同,因此只需要从矩阵中取出索引号为 3的行(注意索引是从 0开始的,因此索引 3对应的是第四行),就能恢复源输入字符串 BANANA。
具体的实现
遗憾的是,不能在50GB大小的文件上进行BWT。这种置换变换的工作方式就决定了,我们每一行都需要存储50GB大小的符号(每一列也是50GB大小),并且按行依次左移一位符号。整个符号矩阵需要的空间太大了。
通常将BWT称为块排序变换,具体实现时,它会将整个文件分为许多1 MB大小的数据块,然后在每个数据块上分别应用该算法。这样一来,大多数现代设备就能满足该算法对内存的要求,同时该算法也能获得较好的性能。
压缩BWT后的数据
显然,BWT本身不压缩数据,它只是转换数据。为了让BWT真正起作用,还需要应用其他的转换来生成熵值更小的数据流,然后再对其压缩。
最常见的算法是将BWT的输出作为MTF的输入,经过处理后接着用统计编码算法处理。这基本上就是BZIP2的内部工作原理。
数据建模
任何玩过“传话筒”(telephone)游戏的人都知道上下文语境对大脑的重要性。在大多数情况下,单词“cup”(杯子)和“cop”(警察)本身出现的可能性大致相同。然而,如果是在一个喧闹的聚会上,你听到一个单词并认为它不是“cup”就是“cop”,那么你的大脑就会根据前面的上下文来确定它会是哪个单词。例如,如果你新认识的朋友说“Wash the”(洗),那么下一个单词就很有可能是“cup”;如果他说“Run from the”(快跑),那么下一个单词就可能是“cop”。
这就是多上下文编码算法背后的基本概念。它会考虑最后观察到的几个符号以确定当前符号的理想编码位数。
例如,在“典型”的英语文本中,字母“h”平均的出现概率大约是5%。然而,如果当前字母是“t”,那么下一个字母是“h”的概率就会高很多,其出现概率大约为30%,这是因为“th”这样的字母组合在英语中很常见。
而如果当前字母是“q”,那么下一个字母是“u”的可能性则会超过99%。在这个例子中,通过当前字母是“q”,我们就能预测到下一个字母会是“u”,因此可以分配给它更少的二进制位数。
这种基于统计观察的相邻关系,通常也被称作“预测”编码器。
这类编码器也可以认为是统计压缩器的“加强”(on-steroids)版。它将自适应模型和多种符号码字对应表结合起来,根据前面观察到的符号,为当前符号生成尽可能短的码字。
马尔科夫链(Markov chain)
马尔可夫链是一种离散的随机过程,其未来的状态只取决于现在,而与过去的历史无关。
有了这样的定义,假定有一个学生已经完成了中学三年级的课程,而我们想知道他在中学四年级的数学课上得A的概率。一般来说,通常我们会认为这样的预测会取决于他在中学一年级、二年级和三年级的数学课上所取得的成绩。然而,如果只有三年级(即当前)的成绩会对结果产生影响,而前两年的成绩完全可以忽略不计,那么就可以认为这是一个马尔可夫过程。
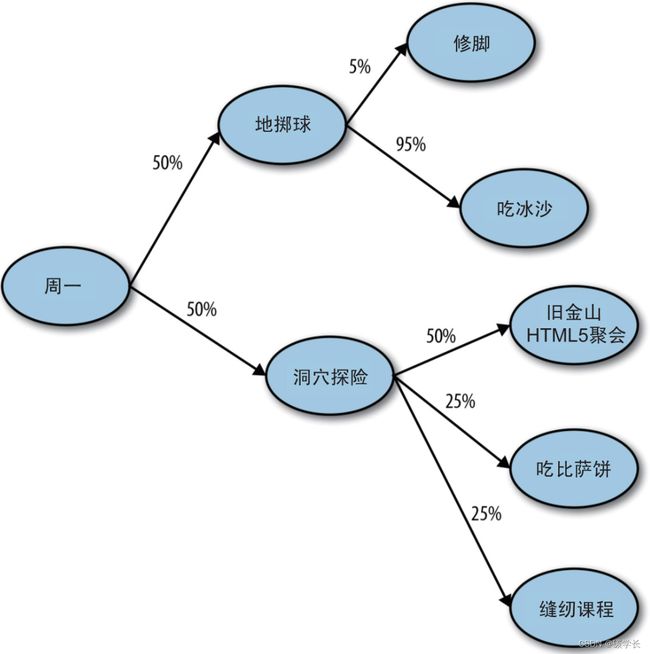
以上的意思是:如果今天是周一,那么有50%的概率会去 地掷球 这个活动,如果做了 地掷球 这个活动,那么接下来有 95% 的概率会去吃冰沙。这就是马尔可夫链。
马尔科夫链与压缩
可以认为统计编码算法就是一阶马尔可夫链。有了数据流中各符号出现的概率表,我们就能为其分配相应的码字。
一阶:星期就是一阶数据,(比如这里的周一,因为可以假设,如果是 周一 那么50%的概率是…,也可以假设如果是周二…)
二阶:第一个活动就是二阶数据
三阶:第一个活动之后的第二个活动就是三阶数据
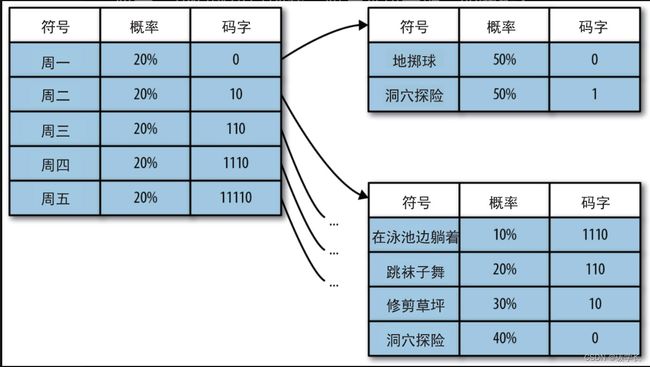
如上图,“周一,洞穴探险;周二,在泳池边躺着”编码后的结果为0 1 10 1110,总共8个二进制位。相比之下,如果想将10个状态都遍历一次,那么编码同样的数据最终需要的二进制位数肯定会超过12。
从技术角度来看,为压缩而建立的马尔可夫链遵循的许多规则与前面介绍的自适应统计编码相同,比如读取符号之后再动态更新频率表,等等。
1、编码
以字符串“TOTOTO”创建马尔可夫链为例来说明整个编码过程。
(1)首先创建一张仅包含字符< literal > 的一阶表,其出现概率为100%,具体如下表和下图所示。

(2) 接着读取第一个字符,这是一个新符号“T”。
(3) 更新一阶表使其包含字符“T”,并相应地调整字符的出现概率,调整后的表如下所示。

(4)输出< literal > 对应的码字和字符“T”,如下图所示。
(5) 从输入流中读取下一个字符,其值为“O”,它同样是一个新符号。
(6) 更新一阶表使其包含字符“O”,并再次调整字符的出现概率。
(7) 接下来调整符号的码字,以包含所有的字符并使其满足前缀性质,调整后的表如下所示。
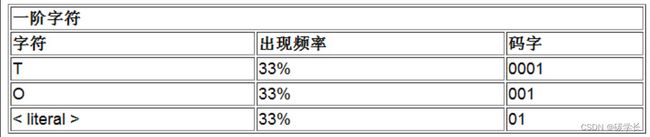
(8)输出< literal > 对应的码字和字符“O”,现在的输出流为0 T 01 O,如下图所示。
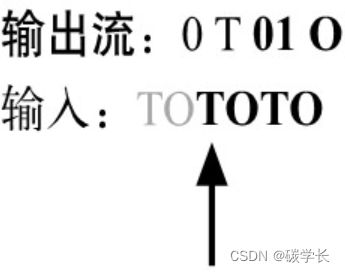
(9) 继续读取下一个字符,其值为“T”,它已在一阶表中。
(10) 更新一阶表中各字符的出现概率。
(11) 交换一阶表中字符对应的码字,使出现概率最大的字符其码字最短,交换后的结果如下表所示。
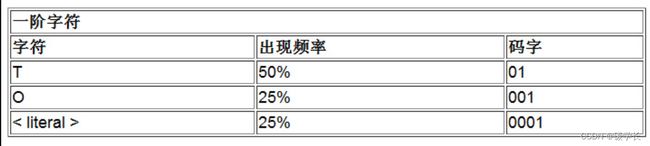
(12) 将字符“T”对应的码字输出,其值为01,现在的输出流为0 T 01 O 01,如下图所示。
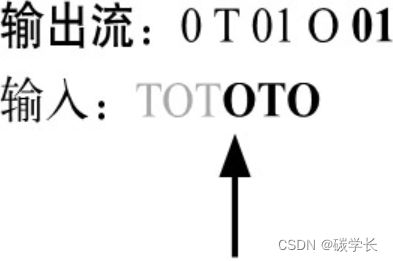
(13) 继续读取下一个字符,其值为“O”。
(14) 更新一阶表中各字符的出现概率,并保持其对应的码字不变。
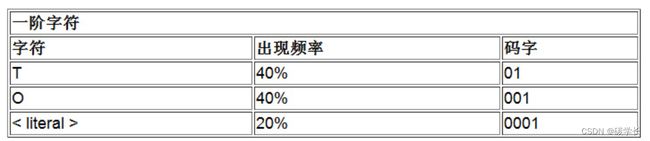
(15) 将字符“O”对应的码字001添加到输出流,这样当前的输出流为0 T 01 O 01 001。
(16) 现在,通过建立第二个符号码字对应表来创建马尔可夫链中的二阶链接,它表示的是“T”后的符号,如下表和下图所示。


(17) 继续从输入流中读取下一个符号,还是“T”。
(18) 更新一阶表中字符的出现概率并保持其对应的码字不变,如下表所示,“T值之后”的二阶表则保持不变。

(19) 将“T”对应的码字01输出,当前的输出流为0 T 01 O 01 001 01。
(20) 现在,为“O”后的符号建立一张二阶表,如下表和下图所示。


(21) 读取最后一个符号“O”。
(22)这里,可以利用“T后”的二阶表,并输出0作为最后一个符号,因此最终的输出流为0 T 01 O 01 001 01 0。
2、解码
(1) 读取0,我们知道这是一个字面值符号,因此建立一张一阶上下文表(概率为100%,以下都将省略百分号,只写数字)。
0 T 01 O 01 001 01 0
(2) 读取字符“T”,它同样是个字面值,将它加入一阶表并更新字符的出现概率(两个字符出现概率为50/50),并将T输出。
(3) 读取“01”,根据一阶表,它还是个字面值。
(4) 读取“O”,更新一阶表(3个字符出现概率为33/33/33),并将“O”输出。
(5) 读取“01”,根据一阶表,其对应的字符为“T”,将“T”输出并再次更新一阶表中字符的出现概率(现在为3个字符的出现概率为50/25/25)。
(6) 读取“001”,根据一阶表,其对应的字符为“O”,将“O”输出并更新一阶表中字符的出现概率(现在为3个字符的出现概率为40/40/20)。
(7) 对“T”之后的符号建立二阶表。
(8) 读取“01”,其对应的字符为“T”,将“T”输出并更新一阶表中字符的出现概率(现在为3个字符的出现概率为33/33/33)。
(9) 对“O”后的符号建立二阶表。
(10) 读取“0”,前面的字符是“T”,在“T后”的二阶表中寻找0,得到“O”,将“O”输出。
3、压缩
当应用到压缩上,马尔可夫链可以让我们用更少的二进制位数对相邻的符号编码。
两个二阶表的码字中都包括0这一最短的可能码字。由于这里使用了前面的符号来区分上下文,因此同样的VLC可以使用两次,从而节省了空间。换一种说法就是,每个上下文都有自己的VLC空间,所以可以使用同样的VLC。
4、实际的实现
值得指出的是,没有人真正地使用马尔可夫链来压缩数据,至少不会用前面说的方法来压缩。
人们创造了各种衍生算法,最值得关注的是部分匹配预测算法和上下文混合算法。
部分匹配预测算法
要使马尔可夫链算法变得实用,就必须要解决内存消耗问题与计算性能问题。
部分匹配预测算法的例子:
(1) 假定我们在压缩某个输入流时遇见“HERE”这个单词好几次,因此“HERE”就变成了上下文之一。
(2) 在之后的某个地方,编码器又遇到了“THERE”并且当前正在压缩的是R字符。
(3) 在三阶(符号)上下文中,R之前的符号是“THE”。
(4) 然而,编码器从来没有见过“THER”,只见过“THE ”(E 后有一个空格)。
(5) 因此,当前字符R出现的概率为“0”。(也就是说,在给定前3个符号的情况下,R从来没有出现过。)
(6) 此时,PPM算法会尝试二阶(符号)上下文,将“HER”匹配为一个链条。
(7) 这样一来就成功了,因为“HERE”在此之前已出现过多次,为“HE”创造了二阶上下文的语境。
(8) 因此,基于二阶上下文链“HE”,字符R的出现概率不再为0。
单词查找树
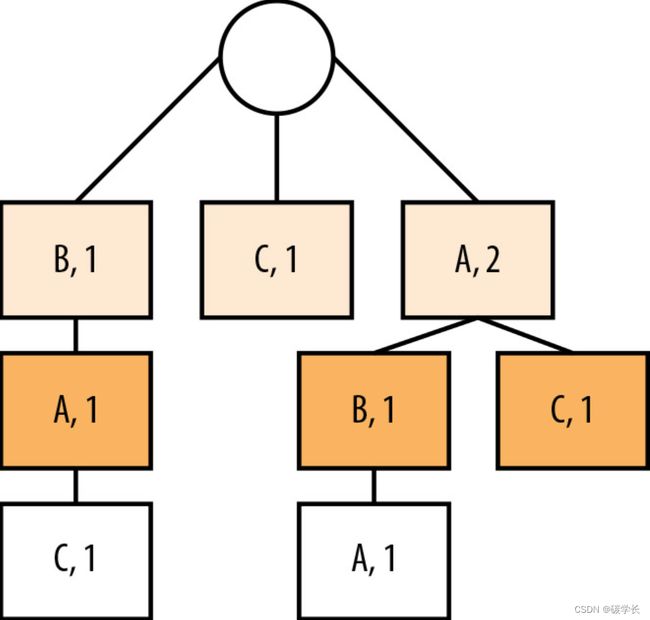
通过一种被称为单词查找树(trie)来存取每个字符的所有上下文。
下面以字符串“ABAC”为例,来创建一棵PPM单词查找树,该字符串所允许的最大上下文为二阶:
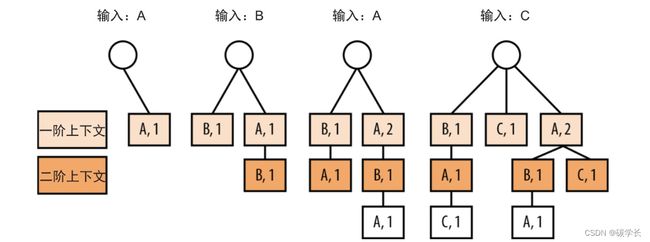
在右边增加新节点的话就会超过前面规定的上下文高度,因此这里没有增加新节点。
假定当前字符是“C”,那么它的二阶上下文是“BA”,一阶上下文是“A”。这与实际完全符合,因为它表示的就是编码“ABAC”时在“C”之前的一个和两个符号的滑动窗口。
在限定二阶上下文的情况下,可以用这棵查找树来表示输入字符串的所有子字符串:B、BA、BAC、C、A、AB、AC和ABA。
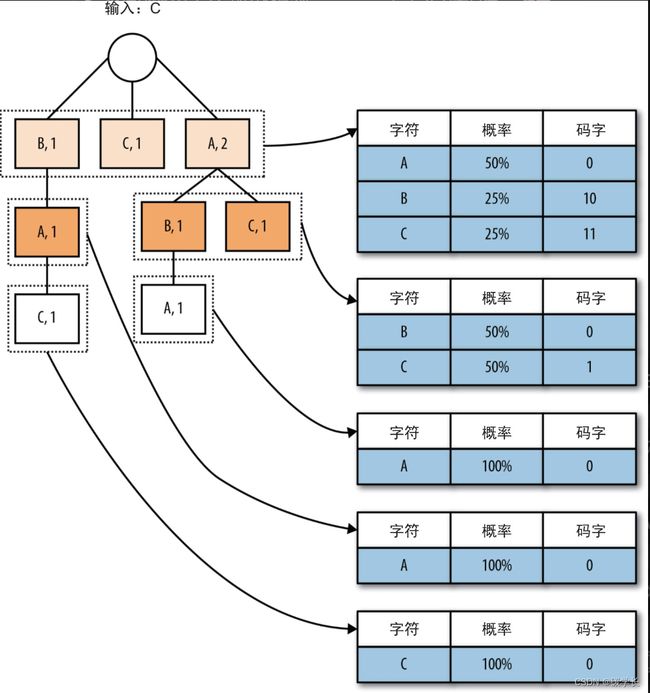
字符的压缩
除了能提供高效的存储以及快速提取子字符串外,单词查找树的每一层都会记录字符出现的次数。有了这些数据,统计编码算法就能构建出字符出现的概率表,并根据概率表为每个字符分配相应的码字。
确定合理的阶数(N 阶、N值)
大多数PPM算法的实现在综合考虑所需内存、处理速度以及压缩率后,将 N 的值设定为5或者6。
也有一些PPM算法的变体,例如PPM*,尝试着使 N 的取值变大,并且是变得非常大。
处理未知的符号
那些没有见过的符号应该赋什么样的概率值呢?这通常被称为零频问题(zero-frequency problem)。
PPMD算法:
新符号的概率等于不同符号的个数与观察到的所有符号的出现次数之比。
PPMZ算法的处理更有意思。刚开始时它的处理方式与PPM* 相同,都试图在 N 阶上下文下找出当前符号的匹配。当找不到这样的匹配时,它就会换上完全不同的算法局部阶估计法(Local-Order-Estimator),而使用的还是基本的PPM模型,只不过预测的算法完全不同。
上下文混合算法
上下文混合算法(context mixing),即为了找出给定符号的最佳编码,我们会使用两个或者更多的统计模型。
例如,通过一个统计模型来预测在所有的经常性活动(比如营救小猫之类)中你去健身房的概率有多大,用另外一个统计模型来预测吃了太多意大利面后的12个小时内你去健身房的概率。
模型的类型
创建基于相邻性的上下文(诸如“A位于B后”之类)很容易,但实际上,相邻性只是在符号之间建立上下文相关的一个方法。例如,你可以创建一个所有下标值为偶数的符号上下文,或者创建取值聚集在某个数值范围内的符号上下文。总的来说,相邻性和局部性都只是上下文的最简单形式,而绝不是唯一的形式。
我们所说的模型其实就是用来识别和描述符号之间的关系。通过对数据的建模,我们就能对数据中包含的各种属性了解得更多,因而也就越能描述好当前的符号。
作为上下文混合算法的先驱压缩器之一,PAQ包含以下模型:
N 元语法、整词 N 元语法、“稀疏”上下文、“模拟”上下文、二维上下文以及针对特定文件类型的特殊模型(如x86可执行文件,BMP、TIFF 或者 JPEG 格式的图片)
PAQ它在大文本压缩基准测试(Large Text Compression Benchmark)中经常排名靠前,它的最新版本之一ZPAQ在压缩人类DNA信息的比赛中获得了第二名。
混合的类型
一种是线性混合(linear mixing),它是将各个模型的预测值加权平均的过程,最终的值则取决于证据权重。
另一种是逻辑混合。逻辑混合使用了神经网络(就是人工智能中的神经网络)来更新权重,而更新的依据则是哪个模型在过去给出了最准确的预测。
逻辑混合的缺点是,在进行数据压缩时,它需要消耗大量的内存,同时运行的时间也较长。
在线性混合中,没有反馈回路来说明在预测如何压缩数据时我们赋给一个模型的权重是否正确。因此,当输入数据流变化时,模型的权重保持不变,最终得到的结果不但没有压缩,反而比原来需要的空间还大。
下一代技术
上下文混合算法给数据压缩的未来指明了方向。
总的来说,如果对所需的内存与运行的时间不加限制,同时还有足够的数据建模知识,那么最优压缩就是个已解决的问题。
这有可能是云计算层次上数据压缩的下一个大的解决方案。
然而这种情况目前还没有在消费市场上出现。由于需要大量的内存和运行时间,这就使得上下文混合算法很难适用于移动设备。
只有当需要处理的数据量很大、数据很复杂并且一直在变化时,上下文混合算法才能真正发挥作用。
因此,我们再次得出了这样的道理:对数据压缩来说,同样没有银弹。无论是哪个数据集,都需要有思考的过程,对信息的定义和处理进行分析。即使是上下文建模,虽然它建立的目的是适应数据的变化,但也同样依赖于人们所建的信息模型。
多媒体数据压缩
当前压缩可以分为两类,即多媒体数据压缩(media-specific compression)与通用压缩(general purpose compression)。
多媒体数据压缩工具是专门设计用来压缩图像、音频、视频等多媒体数据的。
有损压缩指的是为了使数据压缩得更小,可以牺牲多媒体的质量这样的数据转换。
通用压缩
通用压缩工具是设计用来压缩除多媒体数据以外的其他数据。
谷歌对GZIP算法的改进。
标准的HTTP协议栈允许数据包使用GZIP和BZIP编码,现在又多了一种Brotli(前提是服务器端和客户端都支持)。
通过观察各种各样的基准测试,我们发现30%50%这样比例的突破已经不存在了,更多的是经过大量努力后,只能在现有算法的基础上提高2%10%。
斯坦福大学的教授塔奇•魏斯曼(Tsachy Weissman)设计了一种度量数据压缩性能的方法,用数据集的压缩率除以其编码速度作为衡量标准。
被称为魏斯曼评分(Weissman Score)。
图像压缩
imgmin开源项目指出,对于级别在75~100的JPG压缩,通常用户只能感受到很小的质量差别。
对正常的JPEG图片来说,当压缩级别在75~100时,只会出现非常小的、几乎不可见的“明显”质量变化,但文件大小之间的差别比较大。这意味着当质量值为75时对普通用户来说很多图片看着挺好,但是其文件大小只有质量值为95时的一半。当质量值低于75时,图片看起来就变差很多,并且节省的空间也在逐渐递减。
度量图像质量
两个指标来评价图像数据:峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity index,SSIM)。
PSNR通常表示一个信号的最大可能功率与影响它的表示精度的破坏性噪声功率的比值(以对数分贝为单位)。这一度量的基础是压缩图片的均方误差(mean-square error,MSE),换句话说,原始图像的值与压缩后的值差别有多大。
PSNR与MSE之间,存在着反比关系。当误差的数量较少时,图片的质量就比较高(PSNR同样如此),反之亦然。这里唯一需要注意的是,如果你试着去计算两张一样的图像的均方误差值,其结果会为0,那么对应的PSNR会是未定义的(除以0)。
SSIM这个概念的提出就是为了解决PSNR的问题(PSNR的问题是它稍微有些偏向过度平滑(即模糊)的结果),在比较图像的压缩质量时考虑了人眼的感知情况。它是通过比较源图像与压缩后图像的边缘相似性来实现的。SSIM看上去是一个更好的质量度量标准,但是其计算也更复杂。

PNG
PNG格式最吸引人的地方在于它对透明度的支持。除了红、绿和蓝这3种颜色通道外,它还支持alpha通道.
PNG格式还允许文件中存在元数据块,这使得图像编辑器(以及生成图像的客户端设备)可以将额外的数据附加到文件中。
JPG
如果你对透明度没有明确的需求,那么联合图像专家小组(Joint Photographic Experts Group,JPEG或JPG)格式可以说是一个更好的选择。
JPG这种压缩格式的基础是分块编码。
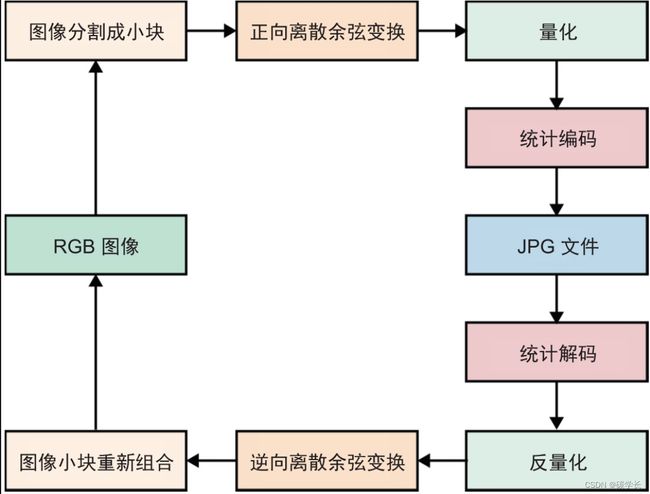
JPG文件中也包含元数据块。
GIF
GIF是另外一种支持透明度的格式,此外它还支持动画(这也是cats on the internet thing的直接原因)。
GIF格式文件的生成包含两个压缩步骤,第一步是有损的色彩数量压缩,将整个图像的颜色数量减少到只有256种,第二步则是无损的LZW压缩。
WebP
WebP格式为用户提供了介于PNG和JPG之间的中间地带。WebP既支持无损模式和透明度,同时也支持有损模式。
但是它也存在一些问题,最主要的是,浏览器不是100% 支持它。
除此之外,在有损压缩模式下的高压缩率,也就意味着在解压时它要比JPG或者PNG格式慢一些。
需要透明且客户端支持 WebP,则选 WebP。
需要透明且客户端不支持 WebP,则选 PNG。
不需要透明且客户端支持 WebP,则选 WebP。
不需要头透明且客户端不支持 WebP,则选 JPG。
GPU 纹理格式
计算机不能直接利用压缩格式的数据绘制图像,而是需要先将压缩的数据加载到内存中,然后再解压为系统可以直接渲染的格式。默认情况下,图像会被解压为每像素32位的格式,其中红绿蓝三种颜色通道以及alpha通道都是8位(也就是RGBA_8888这种表现形式)。然后,图像会被当作纹理传输到GPU中,也就是说你生成的每一个位图都会同时需要CPU和GPU内存。结果就是,不论图像在网络上的压缩质量如何,当在设备上显示时,它就会占用大量的内存。
好消息是,GPU能直接渲染的像素压缩格式是存在的,因此你可以利用这一点,将从网络中传输过来的数据解压为这些压缩格式之一,这样GPU就可以直接渲染,而无须解压这一步骤。DXT、ETC和PVR就是几种这样的有损像素压缩格式

矢量格式
图像是通过二维网格中的像素来显示的,这些像素表示的是图像本身的颜色。当从远处观察图像时,像素之间的边缘就会消失,这样人的眼睛(被欺骗了)看到的就是平滑的颜色渐变。这种类型的图像通常被称为光栅格式图像(raster format image),它可以(比较直接地)在屏幕上渲染。
但是如果传输的不是最终的图像,而是描述图像是怎样生成的语句呢?这就是矢量图像格式背后的概念。一般来说,这样的格式里包含的是一些程序指令,只要按照顺序执行就会生成最终的输出图像。
SVG是一种常用的矢量图像格式。无论源数据多大,有了它,我们就能用很少的内存来描述图像,并在客户端生成高质量的与分辨率无关的图像。当然,SVG也有一些局限,其中之一是它只能用来表示某种类型的图像质量。也就是说,矢量图像通常比较简单,只会使用一组最基本的类型来定义如何在屏幕上生成颜色。例如,草原上的一片绿地,由于涉及太多复杂的形状,因此如果用矢量图来表示,根本就不会节省空间。
序列化数据
序列化是将高级数据对象转化为二进制字符串的过程(与之相反的过程则称为反序列化)。
用它来描述将内存中的结构体或者类转化为能通过网络传输的文件或者内存二进制大对象的过程是最准确的。
最常见的序列化文件格式XML和JSON.
虽然二进制格式不再具备XML和JSON的可读性,但是能保证数据用紧凑和高效的二进制形式编码。这样,文件就会变小,加载速度也会变快。
像BSON和MSGPACK这些格式虽然保留了JSON的模式,但在编码时能提供二进制的大小。这可以让你得到更小的文件,而无须改动大量的代码。
想定义自己的格式,那么Protobufs、Flatbuffers和Cap’n Proto应该是你最先评估的几种格式。
一种数据序列化的重构 而 得到的数据压缩:
在下面这个包含人名及国籍的列表中,对每个人都必须重复“name”和“country”这两个关键字。
...
{
"name": "Joanna",
"country": "USA"
}{
"name": "Alex",
"country": "AUS"
},
{
"name": "Colt",
"country": "USA"
}
...
只需要简单地对列表内容重新排序,就能解决属性的重复和相似属性值之间的距离这两个问题。
如下面的示例所示,可以将前面的数组结构(array structure)转换为某个给定属性的所有值都包含在一个数组中,并紧密地放在一起。
{
"name": ["Joanna", "Alex", "Colt"],
"country": ["USA", "AUS", "USA"]
}
这既减少了冗余,同时也使LZ算法更容易找到匹配。
用编程的语言来就是,对于大的序列化文件,将结构的数组转换为数组的结构极为重要。因此,当你需要处理大的JSON或者XML文件时,建议你认真考虑这样的转换。
高效组织数据的例子:
不好的例子:
{
"messages" : [{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "hello
hello",
"date" : "123"
},
{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "how are you",
"date" : "124"
},
{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "you there",
"date" : "125"
},
{
"from" : {
"user_id" : 1,
"user_name" : "claude",
....
},
"text" : "hello
hello",
"date" : "126"
}]
}
优化后的例子:
{
"users" : {
"1" : {
"user_id" : 1,
"user_name" : "claude",
....
}
},
"messages" : {
"from": [1,1,1,1],
"text": [ "hello
hello","how are you","you there","hello
hello"],
}
让世界变得更小
2G网络的传输速度大约为0.021 MB/s,而GZIP的压缩速度则可达61 MB/s,即使GZIP的压缩速度降为原来的十分之一,压缩1 MB的速度仍然比通过网络传输要快。本书作者柯尔特对这些数据的分析表明,与投入数百万美元升级网络硬件相比,投资更好的压缩解压编解码器要划算得多。
作为开发人员,你既不能真正控制网络,也不能控制硬件。你唯一能控制的只有数据,你可以做大量工作,以确保数据被压缩得很小,这样它们就能以较高的质量、较快的速度传输给用户,从而让用户获得正常的计算体验,并且一直是你的应用程序的忠实用户。