这个标识提取出每条段子信息。

本次的分享主要围绕以下五个方面:
一、数据采集与网络爬虫技术简介
二、网络爬虫技术基础
三、抓包分析
四、挑战案例
五、分享资料
一、数据采集与网络爬虫技术简介
网络爬虫是用于数据采集的一门技术,可以帮助我们自动地进行信息的获取与筛选。从技术手段来说,网络爬虫有多种实现方案,如PHP、Java、Python …。那么用python 也会有很多不同的技术方案(Urllib、requests、scrapy、selenium…),每种技术各有各的特点,只需掌握一种技术,其它便迎刃而解。同理,某一种技术解决不了的难题,用其它技术或方依然无法解决。网络爬虫的难点并不在于网络爬虫本身,而在于网页的分析与爬虫的反爬攻克问题。希望在本次课程中大家可以领会爬虫中相对比较精髓的内容。
二、网络爬虫技术基础
在本次课中,将使用Urllib技术手段进行项目的编写。同样,掌握了该技术手段,其他的技术手段也不难掌握,因为爬虫的难点不在于技术手段本身。本知识点包括如下内容:
需要提前具备的基础知识:正则表达式
1、Urllib基础
爬网页
打开python命令行界面,两种方法:ulropen()爬到内存,urlretrieve()爬到硬盘文件。

同理,只需换掉网址可爬取另一个网页内容

上面是将爬到的内容存在内存中,其实也可以存在硬盘文件中,使用urlretrieve()方法
>>> urllib.request.urlretrieve(“http://www.jd.com”,filename=“D:/我的教学/Python/阿里云系列直播/第2次直播代码/test.html”)
之后可以打开test.html,京东网页就出来了。由于存在隐藏数据,有些数据信息和图片无法显示,可以使用抓包分析进行获取。
2、浏览器伪装
尝试用上面的方法去爬取糗事百科网站url=“https://www.qiushibaike.com/”,会返回拒绝访问的回复,但使用浏览器却可以正常打开。那么问题肯定是出在爬虫程序上,其原因在于爬虫发送的请求头所导致。
打开糗事百科页面,如下图,通过F12,找到headers,这里主要关注用户代理User-Agent字段。User-Agent代表是用什么工具访问糗事百科网站的。不同浏览器的User-Agent值是不同的。那么就可以在爬虫程序中,将其伪装成浏览器。
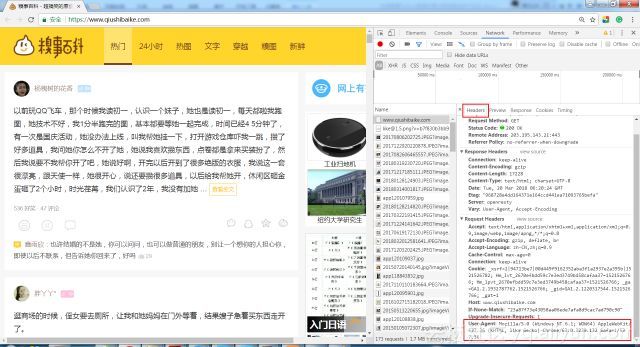
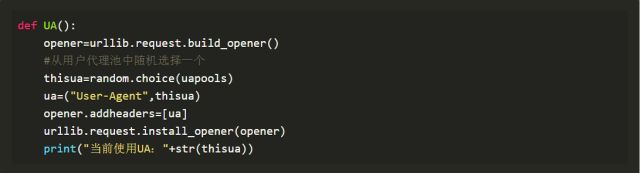
将User-Agent设置为浏览器中的值,虽然urlopen()不支持请求头的添加,但是可以利用opener进行addheaders,opener是支持高级功能的管理对象。代码如下

3、用户代理池
在爬取过程中,一直用同样一个地址爬取是不可取的。如果每一次访问都是不同的用户,对方就很难进行反爬,那么用户代理池就是一种很好的反爬攻克的手段。



4、第一项练习-糗事百科爬虫实战
目标网站:https://www.qiushibaike.com/
需要把糗事百科中的热门段子爬取下来,包括翻页之后内容,该如何获取?



还可以定时的爬取:

换言之,学习爬虫需要灵活变通的思想,针对不同的情况,不同的约束而灵活运用。
三、抓包分析
抓包分析可以将网页中的访问细节信息取出。有时会发现直接爬网页时是无法获取到目标数据的,因为这些数据做了隐藏,此时可以使用抓包分析的手段进行分析,并获取隐藏数据。
1、Fiddler简介
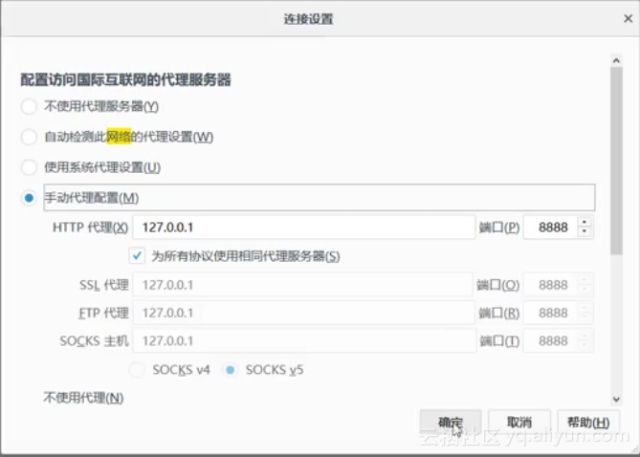
抓包分析可以直接使用浏览器F12进行,也可以使用一些抓包工具进行,这里推荐Fiddler。Fiddler下载安装。假设给Fiddler配合的是火狐浏览器,打开浏览器,如下图,找到连接设置,选择手动代理设置并确定。
假设打开百度,如下图,加载的数据包信息就会在Fiddler中左侧列表中列出来,那么网站中隐藏相关的数据可以从加载的数据包中找到。

2、第二项练习-腾讯视频评论爬虫实战
目标网站:https://v.qq.com/
需要获取的数据:某部电影的评论数据,实现自动加载。
首先可以发现腾讯视频中某个视频的评论,在下面的图片中,如果点击”查看更多评论”,网页地址并无变化,与上面提到的糗事百科中的页码变化不同。而且通过查看源代码,只能看到部分评论。即评论信息是动态加载的,那么该如何爬取多页的评论数据信息?





a.腾讯视频评论爬虫:获取”深度解读”评论内容(单页评论爬虫)
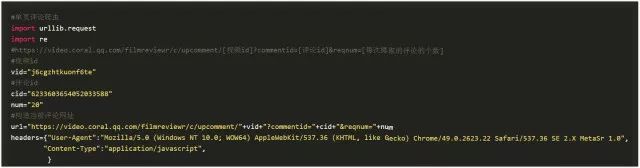
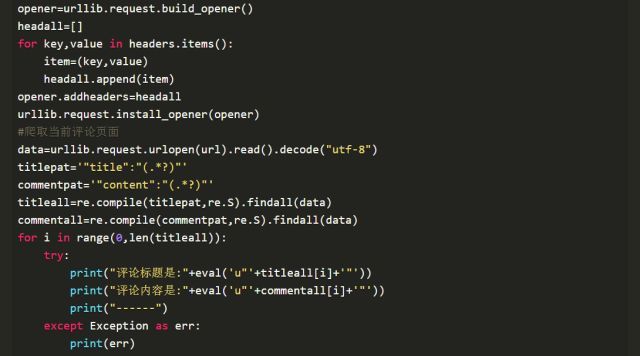
b.腾讯视频评论爬虫:获取”深度解读”评论内容(自动切换下一页评论的爬虫)



四、挑战案例
1、第三项练习-中国裁判文书网爬虫实战
目标网站:http://wenshu.court.gov.cn/
需要获取的数据:2018年上海市的刑事案件接下来进入实战讲解。

可以发现没有对应的网页变换,意味着中国裁判文书网换页是通过POST进行请求,对应的变化数据不显示在网址中。通过F12查看网页代码,再换页操作之后,如下图,查看ListContent,其中有几个字段需要了解:
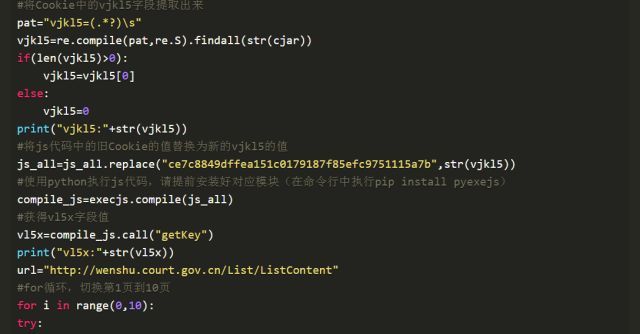
重要的是最后三个字段(vl5x,number,guid)该如何获取?首先,guid即uuid,叫全球唯一标识,是利用python中的uuid随机生成的字段。其次是number字段,找到ListContent上面的GetCode请求,恰好其Response中包含了number字段的值。而GetCode又是通过POST请求的,发现请求的字段只要guid这一项,那么问题便迎刃而解。

后,难点在于vl5x字段如何获取?打开Fiddler,在换页操作后,查看ListContent中的vl5x的值,并在此次ListContent之前出现的数据包中的TextView里寻找这个字段或值,一般的网站可以很容易找到,但中国裁判文书网是政府网站,反爬策略非常高明,寻找的过程需要极高的耐心。
事实上,中国裁判文书网的vl5x字段可以从某个js包中获得,获取的方式是通过getKey()函数。从网页源代码中找到getKey()函数的js代码,由于代码是packed状态,用unpacked工具, 将其进行解码,后利用js界面美观工具可以方便理解。
但无关紧要,只需直接将getKey()函数s代码复制到unpack_js.html中,就可以解出vl5x字段的值,其中需要用到Cookie中的vjkl5字段值。需要注意提前下载好base64.js和md5.js,并在unpack_js.html加载。

opener.addheaders=[("Referer","http://wenshu.court.gov.cn/list/list/?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6&conditions=searchWord+2018+++%E8%A3%81%E5%88%A4%E5%B9%B4%E4%BB%BD:2018&conditions=searchWord+%E4%B8%8A%E6%B5%B7%E5%B8%82+++%E6%B3%95%E9%99%A2%E5%9C%B0%E5%9F%9F:%E4%B8%8A%E6%B5%B7%E5%B8%82")]
urllib.request.install_opener(opener)
\#用户代理池
import random
uapools=[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
\#访问首页urllib.request.urlopen("http://wenshu.court.gov.cn/list/list/?sorttype=1&conditions=searchWord+1+AJLX++%E6%A1%88%E4%BB%B6%E7%B1%BB%E5%9E%8B:%E5%88%91%E4%BA%8B%E6%A1%88%E4%BB%B6&conditions=searchWord+2018+++%E8%A3%81%E5%88%A4%E5%B9%B4%E4%BB%BD:2018&conditions=searchWord+%E4%B8%8A%E6%B5%B7%E5%B8%82+++%E6%B3%95%E9%99%A2%E5%9C%B0%E5%9F%9F:%E4%B8%8A%E6%B5%B7%E5%B8%82").read().decode("utf-8","ignore")
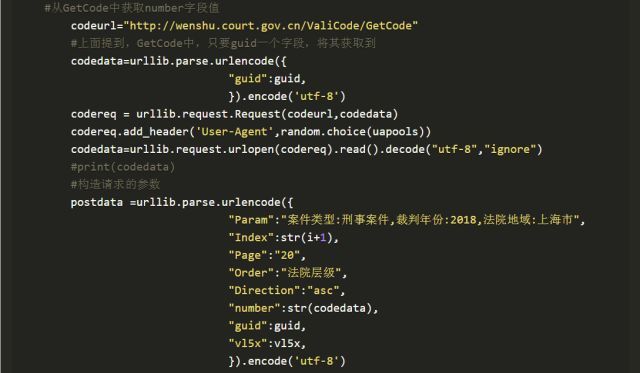

如此便可批量获取中国裁判文书网中的案件信息。友情提示,如果频繁爬取该网站,需扩充用户代理池。
如果对Python感兴趣的话,可以试试我的学习方法以及相关的学习资料
如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。


观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

检查学习结果。

我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。