如何信任机器学习模型的预测结果?
模型自解释结果与 LIME 解释结果的对比
随机森林回归模型是基于决策树的集成模型,因此,模型本身也具有可解释性。我们对训练好的模型查看模型属性 predictorImportance,并进行可视化:
bagTreeMdl= mdl_bag;
bar(bagTreeMdl.predictorImportance);
f =gca;
f.XTickLabel= bagTreeMdl.PredictorNames;
f.XTickLabelRotation= 45;
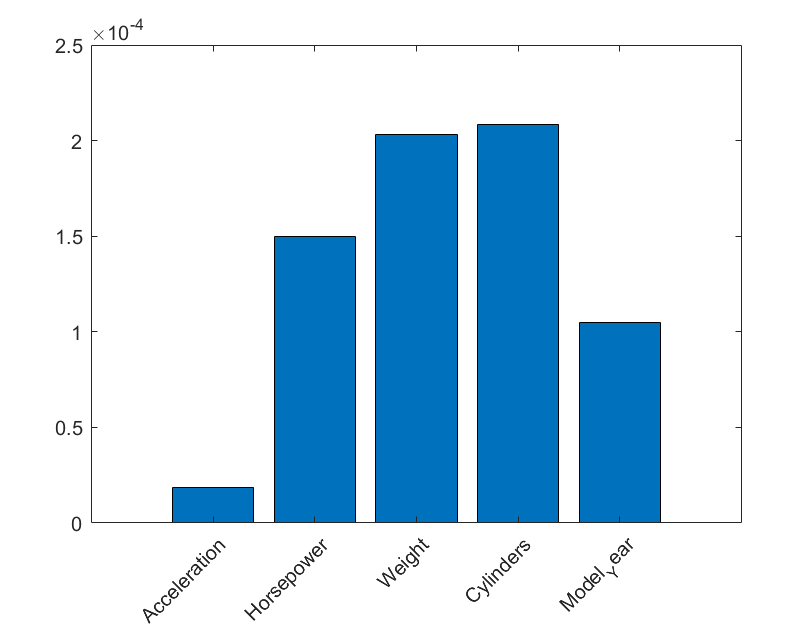
图 4
从图 4 可以看出,对随机森林模型预测结果有重要影响的预测变量依次是 Cylinders、Weight、Horsepower、Model_Year 以及 Acceleration。
与 LIME 的解释相比,Weight 和 Cylinders 重要顺序不同,但都是对预测结果有重要影响的。
因此,对于当前的输入数据,LIME 的解释结果与随机森林的自解释结果是相近的。
对不用机器学习模型的 LIME 解释结果对比
使用同样的训练集,训练一个支持向量机回归模型。并且,对同一个预测数据的预测结果使用 LIME 进行解释。对比两个机器学习模型预测结果以及解释结果。
支持向量机的回归模型指定采用高斯核函数,并指明第 4 和第 5 个预测变量是分类变量。
mdl_svm= fitrsvm(tblX,tbl.MPG,'CategoricalPredictors',[4 5],…
'KernelFunction',"gaussian");
对回归模型使用 LIME 进行解释。首先构建使用 lime 函数构建一个 LIME 对象,解释模型使用决策树,同时 lime 中也指明了原始机器学习模型的训练样本的第 4 和第 5 列是分类变量。
lime_svm= lime(mdl_svm,'CategoricalPredictors',[45],…
'SimpleModelType',"tree");
以预测数据为基础生成合成数据集,并训练一个可解释模型(决策树模型)。对于可解释模型,指定变量个数为 5。
lime_svm= fit(lime_svm,queryPoint,5);
根据预测变量对预测结果的影响程度进行排序并可视化
f =plot(lime_svm);
title('支持向量机回归模型的LIME');
f.CurrentAxes.TickLabelInterpreter= 'none';
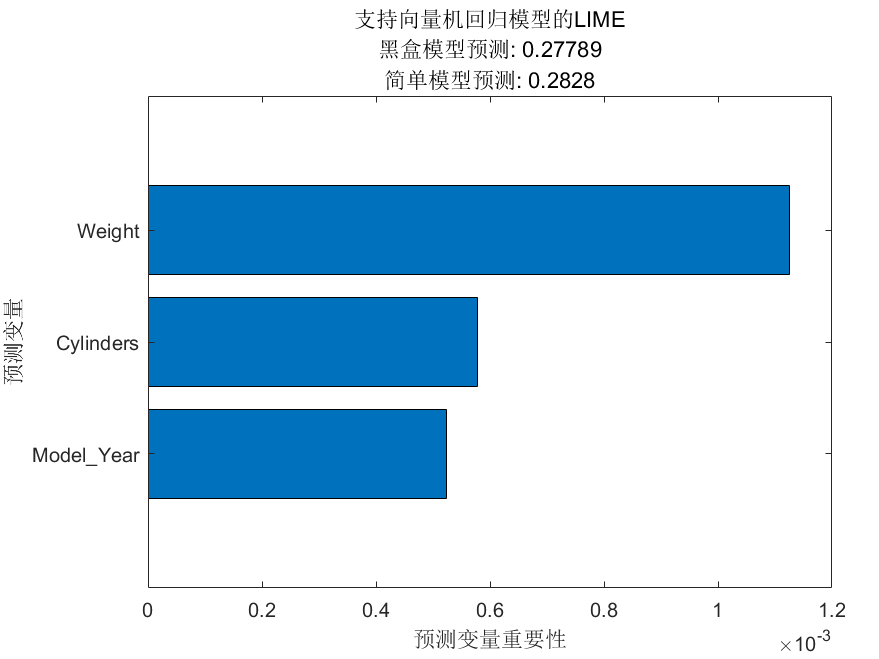
图 5
从图 5 可以看出,预测变量 Weight 对支持向量机回归模型的预测结果影响最大,其次是 Cylinders 和 Model_Year。
也就是说,对于当前的预测数据,支持向量机模型产生预测结果时,重点考虑了 Weight、Cylinders 和 Model_Year 三个变量,而并没有考虑Horsepower。
这与图 3 显示的随机森林模型预测结果的解释有些不同。
对于相同的预测数据,从预测结果和预测结果的解释两个角度,对比分析随机森林模型和支持向量机模型,结果如下表所示(标准化后的数据):,

注:表中的变量是按照重要性降序排列。
从上表中可以看出,两个模型的预测结果差别不大,但是解释的结果却是不同。因此解释结果与领域先验知识的匹配程度,可以作为判定模型可信性的依据。
到这里,只是得到了 LIME 对单个预测数据的预测结果的可信性,也就是模型局部的可信性。
那如何对整个模型的可信性如果获取呢?
如果训练数据集的规模不是很大,最直接的想法就是获取全部训练样本的可信性,也就是获取每个训练集样本的影响较大的预测变量,综合所有的结果取得对模型影响比较大的预测变量,并根据先验知识判断模型整体的可信性。
如果训练数据集规模较大,我们可以利用训练数据集的概率分布进行抽样,获取抽样数据预测结果影响较大的预测变量,综合所有的结果取得对模型影响比较大的预测变量,并根据先验知识判断模型整体的可信性。