Oracle(4)
-
子查询
子查询语法很简单,就是select 语句的嵌套使用。
查询工资比SCOTT高的员工信息
分析:两步即可完成
1. 查出SCOTT的工资 SQL> select ename, sal from emp where ename='SCOTT' 其工资3000
2. 查询比3000高的员工 SQL> select * from emp where sal>3000
通过两步可以将问题结果得到。子查询,可以将两步合成一步。
——子查询解决的问题:问题本身不能一步求解的情况。
SQL> select *
from emp
where sal > (select sal
from emp
where ename='SCOTT')
子查询语法格式:
SELECT select_list
FROM table
WHERE expr operator
(SELECT select_list
FROM table);
本章学习目标:
描述子查询可以解决的问题
定义子查询(子查询的语法)
列出子查询的类型。
书写单行子查询和多行子查询。
定义子查询 需要注意的问题
1. 合理的书写风格 (如上例,当写一个较复杂的子查询的时候,要合理的添加换行、缩进)
2. 小括号( )
3. 主查询和子查询可以是不同表,只要子查询返回的结果主查询可以使用即可
4. 可以在主查询的where、select、having、from后都可以放置子查询
5. 不可以在主查询的group by后面放置子查询 (SQL语句的语法规范)
6. 强调:在from后面放置的子查询(***) from后面放置是一个集合(表、查询结果)
7. 一般先执行子查询(内查询),再执行主查询(外查询);但是相关子查询除外
8. 一般不在子查询中使用order by, 但在Top-N分析问题中,必须使用order by
9. 单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
10. 子查询中的null值
主、子查询在不同表间进行。
查询部门名称是“SALES”的员工信息
主查询:查询员工信息。select * from emp;
子查询:负责得到部门名称(在dept表中)、部门号对应关系。select deptno from dept where dname='SALES'
SQL> select *
from emp
where deptno= (select deptno
from dept
where dname='SALES')
主查询,查询的是员工表emp,子查询,查询的是部门表dept。是两张不同的表。
将该问题使用“多表查询”解决:
SQL> select e.* from emp e, dept d where e.deptno=d.deptno and d.dname='SALES'
两种方式哪种好呢?
※SQL优化: 理论上,既可以使用子查询,也可以使用多表查询,尽量使用“多表查询”。子查询有2次from
不同数据库处理数据的方式不尽相同,如Oracle数据库中,子查询地位比较重要,做了深入的优化。有可能实际看到结果是子查询快于多表查询。
在主查询的where select having from 放置子查询
子查询可以放在select后,但,要求该子查询必须是 单行子查询:(该子查询本身只返回一条记录,2+叫多行子查询)
SQL> select empno, ename, (select dname from dept where deptno=10) 部门 from emp
注意:SQL中没有where是不可以的,那样是多行子查询。
进一步理解查询语句,实际上是在表或集合中通过列名来得到行数据,子查询如果是多行,select无法做到这一点。
在 having 后 和 where 类似。但需注意在where后面不能使用组函数。
在from后面放置的子查询(***)
表,代表一个数据集合、查询结果(SQL)语句本身也代表一个集合。
查询员工的姓名、薪水和年薪:
说明:该问题不用子查询也可以完成。但如果是一道填空题:select * from ___________________
因为显示的告诉了,要使用select *
SQL> select * from (select ename, sal, sal*12 年薪 from emp);
将select 语句放置到from后面,表示将select语句的结果,当成表来看待。这种查询方式在Oracle语句中使用比较频繁。
单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
-
单行子查询:
单行子查询就是该条子查询执行结束时,只返回一条记录(一行数据)。
使用单行操作符:
=、>、>=、<、<=、<>
如:
SELECT last_name, job_id, salary
FROM employees
WHERE job_id =
(SELECT job_id
FROM employees
WHERE employee_id = 141)
AND salary >
(SELECT salary
FROM employees
WHERE employee_id = 143);
再如:
SELECT last_name, job_id, salary
FROM employees
WHERE salary =
(SELECT MIN(salary)
FROM employees);
也可以在having子句中使用:
SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) >
(SELECT MIN(salary)
FROM employees
WHERE department_id = 50);
上面的例子告诉我们:
1. 单行子查询,只能使用单行操作符(=号、>号)
2. 在一个主查询中可以有多个子查询。
3. 子查询里面可以嵌套多层子查询。
4. 子查询也可以使用组函数。子查询也是查询语句,适用于前面所有知识。
非法使用子查询的例子:
SELECT employee_id, last_name
FROM employees
WHERE salary =
(SELECT MIN(salary)
FROM employees
GROUP BY department_id);
在此例中,单行操作符“=”连接了返回多条记录的子查询。查询语句执行会报错。
多行子查询:
子查询返回2条记录以上就叫多行。
多行操作符有:
IN 等于列表中的任意一个
ANY 和子查询返回的任意一个值比较
ALL 和子查询返回的所有值比较
IN(表示在集合中):
查询部门名称为SALES和ACCOUNTING的员工信息。
分析:部门名称在dept表中,员工信息在emp表中。→
子查询应先去dept表中将SALES和ACCOUNTING的部门号得到,交给主查询得员工信息
SQL> select *
from emp
where deptno in (select deptno
from dept
where dname= 'SALES 'or dname= 'ACCOUNTING ');
使用 多表查询 来解决该问题:
SQL> select e.*
from emp e, dept d
where e.deptno=d.deptno and (d.dname= 'SALES ' or d.dname= 'ACCOUNTING ');
这种解决方式,注意使用()来控制优先级。
如果查询不是这两个部门的员工,只要把in → not in就可以了,注意不能含有空值。
ANY(表示和集合中的任意一个值比较):
查询薪水比30号部门任意一个员工高的员工信息:
分析:首先查出30号部门的员工薪水的集合,然后 > 它就得到了该员工信息。
SQL> select * from emp where sal > (select sal from emp where deptno=30); 正确吗?
这样是错的,子句返回多行结果。而‘>’是单行操作符。 ——应该将‘>’替换成‘> any’
实际上>集合的任意一个值,就是大于集合的最小值。
若将这条语句改写成单行子查询应该怎么写呢?
SQL> select * from emp where sal > (select min(sal) from emp where deptno=30);
ALL(表示和集合中的所有值比较):
查询薪水比30号部门所有员工高的员工信息。
SQL> Select * from emp where sal > all (select sal from emp where deptno=30);
同样,将该题改写成单行子句查询:
SQL> Select * from emp where sal > (select max(sal) from emp where deptno=30);
对于any 和 all 来说,究竟取最大值还是取最小值,不一定。将上面的两个例子中的“高”换成“低”,any和all就各自取相反的值了。
子查询中null
判断一个值等于、不等于空,不能使用=和!=号,而应该使用is 和 not。
如果集合中有NULL值,不能使用not in。如: not in (10, 20, NULL),但是可以使用in。为什么呢?
先看一个例子:
查询不是老板的员工信息:
分析:不是老板就是树上的叶子节点。在emp表中有列mgr,该列表示该员工的老板的员工号是多少。那么,如果一个员工的员工号在这列中,那么说明这员工是老板,如果不在,说明他不是老板。
SQL> select * from emp where empno not in (select mgr from emp); 但是运行没有结果,因为有NULL
查询是老板的员工信息: 只需要将not去掉。
SQL> select * from emp where empno in (select mgr from emp );
还是我们之前null的结论:in (10, 20, null) 可以,not in (10, 20, null) 不可以
例如:a not in(10, 20, NULL) 等价于 (a != 10) and (a != 20) and (a != NULL)
因为,not in操作符等价于 !=All,最后一个表达式为假,整体假。如:
SELECT emp.last_name
FROM employees emp
WHERE emp.employee_id NOT IN
(SELECT mgr.manager_id
FROM employees mgr);
a in (10, 20, NULL) 等价于 (a = 10) or (a = 20) or (a = null)只要有一个为真即为真。
in 操作符等价于 = Any
所以子查询中,如果有NULL值,主查询使用where xxx=子查询结果集。永远为假。
继续,查询不是老板的员工信息。 只要将空值去掉即可。
SQL> select * from emp where empno not in (select mgr from emp where mgr is not null);
-
- 一般不在子查询中使用order by
一般情况下,子查询使用order by或是不使用order by对主查询来说没有什么意义。子查询的结果给主查询当成集合来使用,所以没有必要将子查询order by。
但,在Top-N分析问题中,必须使用order by
-
- 一般先执行子查询,再执行主查询
含有子查询的SQL语句执行的顺序是,先子后主。
但,相关子查询例外
- 集合运算
查询部门号是10和20的员工信息: ?思考有几种方式解决该问题 ?
- SQL> select * from emp where deptno in(10, 20)
- SQL> select * from emp where deptno=10 or deptno=20
- 集合运算:
Select * from emp where deptno=10 加上
Select * from emp where deptno=20
集合运算所操作的对象是两个或者多个集合,而不再是表中的列(select一直在操作表中的列)
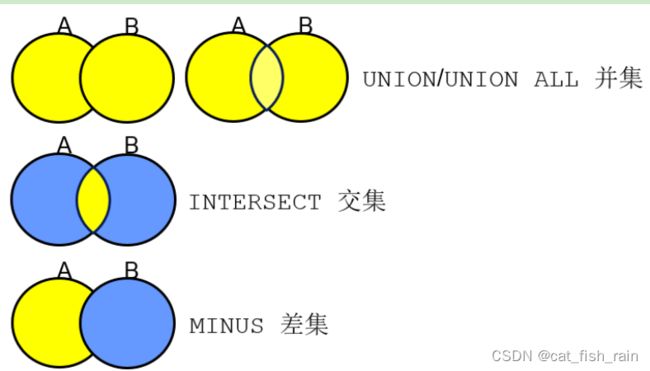
集合运算符
集合运算的操作符。A∩B、A∪ B、A - B
QL> select * from emp where deptno=10
union
select * from emp where deptno=20 注意:这是一条SQL语句。
集合运算需要注意的问题:
- 参与运算的各个集合必须列数相同,且类型一致。
- 采用第一个集合的表头作为最终使用的表头。 (别名也只能在第一个集合上起)
- 可以使用括号()先执行后面的语句。
问题:按照部门统计各部门不同工种的工资情况,要求按如下格式输出:
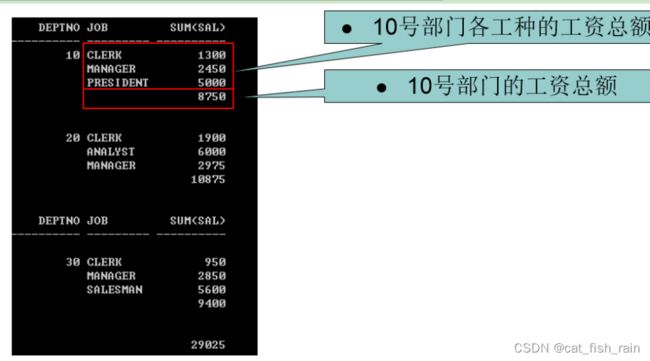
分析SQL执行结果。
第一部分数据是按照deptno和job进行分组;select 查询deptno、job、sum(sal)
第二部分数据是直接按照deptno分组即可,与job无关;select 只需要查询deptno,sum(sal)
第三部分数据不按照任何条件分组,即group by null;select 查询sum(sal)
所以,整体查询结果应该= group by deptno,job + group by deptno + group by null
按照集合的要求,必须列数相同,类型一致,所以写法如下,使用null强行占位!
SQL> select deptno,job,sum(sal) from emp group by deptno,job
union
select deptno,to_char(null),sum(sal) from emp group by deptno
union
select to_number(null),to_char(null),sum(sal) from emp;
需要注意:集合运算的性能一般较差.
SQL的执行时间:
set timing on/off 默认是off
交集和差集与并集类似,也要注意以上三点。只不过算法不同而已。