Python代码示例 | 时间序列数据的组成
时间序列数据是以固定的时间间隔记录或收集的数据点序列。它是一种跟踪变量随时间演变的数据,如销售,股票价格,温度等。定期的时间间隔可以是每天,每周,每月,每季度或每年,数据通常表示为线图或时间序列图。时间序列数据通常用于经济、金融、天气预报和运营管理等领域,以分析趋势和模式,并进行预测或预报。
时间序列数据的组成
时间序列数据的组成部分是构成数据的基本模式或结构。在时间序列数据中有几个共同的组成部分。在时间序列数据中,可能出现几种类型的模式:
- 趋势:数据中的长期向上或向下运动,表明随着时间的推移而普遍增加或减少。
- 季节性:数据中定期出现的重复模式,例如每天、每周、每月或每年。
- 周期性:数据中的一种模式,在特定数量的观测之后重复出现,这不一定与季节性有关。
- 不规则性:数据中的随机波动,无法用趋势、季节性或周期来解释。
- 自相关性:同一时间序列中的一个观测值与前一个观测值之间的相关性。
- 离群值:与数据中的其他观测值显著不同的极端观测值。
- 噪声:数据中不可预测和随机的变化。
通过识别时间序列数据中的这些模式,分析师可以更好地理解潜在的结构,并做出更准确的预测。
趋势
时间序列数据中的趋势是指数据中的长期向上或向下移动,表明随着时间的推移一般会增加或减少。趋势表示数据的基本结构,捕捉较长时期内变化的方向和幅度。在时间序列分析中,通常会建模并从数据中删除趋势,以更好地理解潜在模式并做出更准确的预测。时间序列数据中有几种类型的趋势:
- 上升趋势:一种趋势,显示随着时间的推移,数据的价值往往会随着时间的推移而上升。
- 下降趋势:显示随时间推移总体下降的趋势,其中数据的值倾向于随时间推移而下降。
- 水平趋势:显示随时间无显著变化的趋势,其中数据值随时间保持不变。
- 非线性趋势:一种趋势,显示出随时间变化的更复杂模式,包括随时间变化方向或幅度的上升或下降趋势。
- 衰减趋势:一种趋势,显示变化幅度随时间逐渐下降,变化率随时间减慢。
重要的是要注意,时间序列数据可以具有这些类型的趋势的组合或同时存在的多个趋势。准确识别和建模趋势是时间序列分析的关键步骤,因为它可以显著影响预测的准确性和数据模式的解释。
下面是一个Python代码示例,它使用示例数据演示了时间序列数据中不同类型的趋势。
import numpy as np
import matplotlib.pyplot as plt
# Upward Trend
t = np.arange(0, 10, 0.1)
data = t + np.random.normal(0, 0.5, len(t))
plt.plot(t, data, label='Upward Trend')
# Downward Trend
t = np.arange(0, 10, 0.1)
data = -t + np.random.normal(0, 0.5, len(t))
plt.plot(t, data, label='Downward Trend')
# Horizontal Trend
t = np.arange(0, 10, 0.1)
data = np.zeros(len(t)) + np.random.normal(0, 0.5, len(t))
plt.plot(t, data, label='Horizontal Trend')
# Non-linear Trend
t = np.arange(0, 10, 0.1)
data = t**2 + np.random.normal(0, 0.5, len(t))
plt.plot(t, data, label='Non-linear Trend')
# Damped Trend
t = np.arange(0, 10, 0.1)
data = np.exp(-0.1*t) * np.sin(2*np.pi*t)\
+ np.random.normal(0, 0.5, len(t))
plt.plot(t, data, label='Damped Trend')
plt.legend()
plt.show()
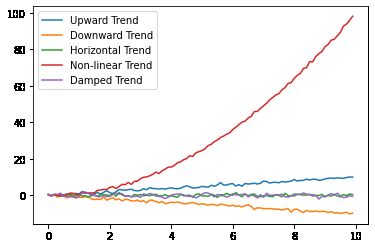
上面的代码生成时间序列数据中五种不同类型趋势的图:向上、向下、水平、非线性和衰减。使用数学函数和随机噪声的组合来生成样本数据。
季节性
时间序列数据中的季节性是指在一个固定的时间段内重复的模式,例如一天,一周,一个月或一年。这些模式是由于常规事件(如假期、周末或季节变化)而出现的,并且可以存在于各种类型的时间序列数据中,如销售、天气或股票价格。
时间序列数据中有几种类型的季节性,包括:
- 每周季节性:一种在7天内重复的季节性,常见于时间序列数据,如销售、能源使用或运输模式。
- 每月季节性:一种在30或31天内重复的季节性,常见于时间序列数据,如销售或天气模式。
- 每年季节性:一种在365天或366天内重复的季节性,常见于销售、农业或旅游模式等时间序列数据中。
- 假期季节性:由特殊事件(如节假日、节日或体育赛事)引起的一种季节性,常见于销售、交通或娱乐模式等时间序列数据中。
重要的是要注意,时间序列数据可以同时存在多种类型的季节性,准确识别和建模季节性是时间序列分析的关键步骤。
下面是一个Python代码示例,它使用样本数据演示了时间序列数据中不同类型的季节性:
import numpy as np
import matplotlib.pyplot as plt
# generate sample data with different types of seasonality
np.random.seed(1)
time = np.arange(0, 366)
# weekly seasonality
weekly_seasonality = np.sin(2 * np.pi * time / 7)
weekly_data = 5 + weekly_seasonality
# monthly seasonality
monthly_seasonality = np.cos(2 * np.pi * time / 30)
monthly_data = 5 + monthly_seasonality
# annual seasonality
annual_seasonality = np.sin(2 * np.pi * time / 365)
annual_data = 5 + annual_seasonality
# plot the data
plt.figure(figsize=(12, 8))
plt.plot(time, weekly_data,
label='Weekly Seasonality')
plt.plot(time, monthly_data,
label='Monthly Seasonality')
plt.plot(time, annual_data,
label='Annual Seasonality')
plt.legend(loc='upper left')
plt.show()
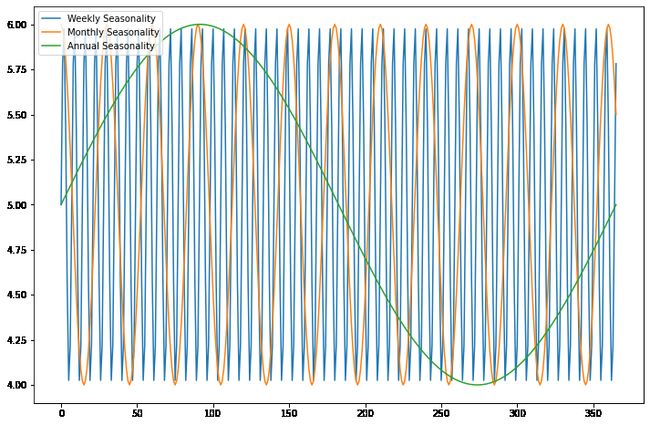
上面的代码生成了一个图,显示了生成的样本数据的三个图表,具有不同类型的季节性。这些数据代表了周、月和年季节性对单个时间序列的不同影响。x轴表示时间,y轴表示添加相应季节性分量后的时间序列值。绘图使用matplotlib库来显示图形,使用NumPy库来生成数据和进行数学运算。图例函数向图中添加图例以帮助区分不同的图形。show函数在屏幕上显示绘图。
周期性
时间序列数据中的周期性是指在特定时间间隔内数据中出现的重复模式或周期性波动。这可能是由于各种因素,如季节性(每日,每周,每月,每年),趋势和其他潜在模式。
季节性和周期性的区别
季节性是指数据中在固定时间间隔(如每天、每周、每月或每年)内发生的重复模式。季节性是一种可预测和重复的模式,可能是由于各种因素,如天气,假期和人类行为。
另一方面,周期性是指在未指定的时间间隔内数据中出现的重复模式或波动。这些模式可能是由于各种因素,如经济周期,趋势和其他基本模式。周期性不限于固定的时间间隔,可以具有不同的频率,这使得识别和建模变得更加困难。
总而言之,季节性是指在固定时间间隔内发生的数据中的重复模式,而周期性是指在未指定的时间间隔内发生的重复模式。
import numpy as np
import matplotlib.pyplot as plt
# Generate sample data with cyclic patterns
np.random.seed(1)
time = np.array([0, 30, 60, 90, 120,
150, 180, 210, 240,
270, 300, 330])
data = 10 * np.sin(2 * np.pi * time / 50)\
+ 20 * np.sin(2 * np.pi * time / 100)
# Plot the data
plt.figure(figsize=(12, 8))
plt.plot(time, data, label='Cyclic Data')
plt.legend(loc='upper left')
plt.xlabel('Time (days)')
plt.ylabel('Value')
plt.title('Cyclic Time Series Data')
plt.show()

上述代码生成具有两个循环模式的组合的时间序列数据。sin函数用于生成循环模式,每个模式具有不同的频率。时间变量定义为具有不均匀时间间隔的12个时间点的数组,以表示数据的不规则采样。使用Matplotlib库绘制数据,该库显示了数据随时间的循环模式,时间间隔不均匀。
不规则性
时间序列数据中的不规则性是指数据中不遵循数据一般模式的意外或异常波动。这些波动可能由于各种原因而发生,例如测量误差、意外事件或其他噪声源。不确定性可能对时间序列模型和预测的准确性产生重大影响,因为它们可能掩盖数据中的潜在趋势和季节性模式。
import numpy as np
import matplotlib.pyplot as plt
# Generate sample time series data
np.random.seed(1)
time = np.arange(0, 100)
data = 5 * np.sin(2 * np.pi * time / 20) + 2 * time
# Introduce irregularities by adding random noise
irregularities = np.random.normal(0, 5, len(data))
irregular_data = data + irregularities
# Plot the original data and the data with irregularities
plt.figure(figsize=(12, 8))
plt.plot(time, data, label='Original Data')
plt.plot(time, irregular_data,
label='Data with Irregularities')
plt.legend(loc='upper left')
plt.show()
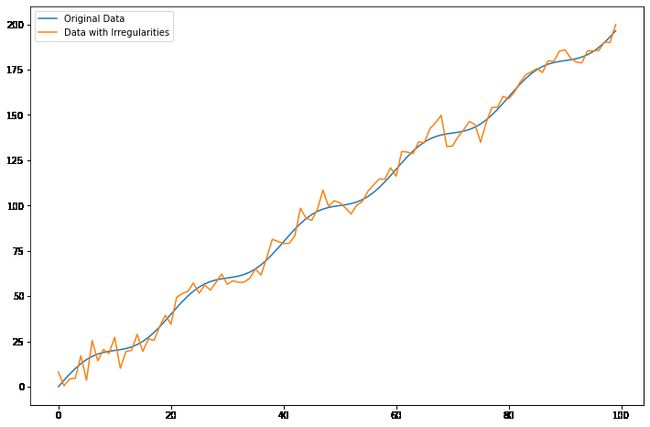
上面的代码生成一个具有正弦模式和线性趋势的时间序列,然后引入随机噪声以在数据中创建不规则性。由此产生的图显示,不规则性会显著影响时间序列数据的外观,使识别潜在模式变得更加困难。
自相关性
时间序列数据中的自相关性是指时间序列中观测值之间的相似程度,作为它们之间的时滞的函数。自相关性是时间序列与其滞后版本之间相关性的度量。换句话说,它衡量时间序列中的值在不同的时间滞后中彼此之间的密切关系。
自相关是理解时间序列属性的有用工具,因为它可以提供有关数据中的底层模式和依赖关系的信息。例如,如果一个时间序列在某个时间滞后处是正自相关的,这表明时间序列中的一个正值很可能在一定时间之后被另一个正值跟随。另一方面,如果一个时间序列在某个时间滞后处是负自相关的,这表明时间序列中的正值很可能在一定时间之后被负值跟随。
自相关可以使用各种统计技术来计算,例如皮尔逊相关系数或自相关函数(ACF)。自相关函数提供了不同时滞的自相关的图形表示,并可用于识别时间序列中的主要模式和依赖关系。
import numpy as np
import matplotlib.pyplot as plt
# generate random time series data with autocorrelation
np.random.seed(1)
data = np.random.randn(100)
data = np.convolve(data, np.ones(10) / 10,
mode='same')
# visualize the time series data
plt.plot(data)
plt.show()
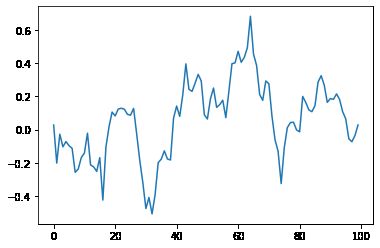
此代码使用NumPy生成随机时间序列数据,然后对数据应用移动平均滤波器以创建自相关。
离群值
时间序列数据中的离群值是与序列中的其余数据点显著不同的数据点。这可能是由于各种原因,如测量误差,极端事件或基础数据生成过程的变化。离群值可能对时间序列分析和建模的结果产生重大影响,因为它们可能会扭曲数据的统计特性。
噪声
时间序列数据中的噪声是指并非由潜在模式或趋势引起的随机波动或变化。它通常被认为是数据中的任何不可预测和随机变化。这些波动可能来自各种来源,例如测量误差、基础过程中的随机波动或数据记录或处理中的误差。噪声的存在可能会使识别数据中的潜在趋势或模式变得困难,因此在进行任何进一步分析之前消除或减少噪声非常重要。
总结
总之,时间序列数据可以分解为几个组成部分,包括趋势,季节性,周期性,不规则性,自相关性,离群值和噪声。了解这些组成对于有效地分析和建模时间序列数据至关重要。通过识别和隔离这些组成部分,我们可以更好地了解时间序列数据中的潜在模式和关系,这可以为决策提供信息并提高预测准确性。