解决方案:爬虫被反爬,检测出是selenium,报400,无法进入网站
问题:“被网站检测出来是selenium,不让爬了”。
以下是报错及解决方案:
!!!文中出现的网站是一个有此检测的案例,仅供学习参考!!!
一、报错:
1.报错截图(记住这个 true 哈,间接地代表你是selenium;咱们正常F12这里都是 false 的哈):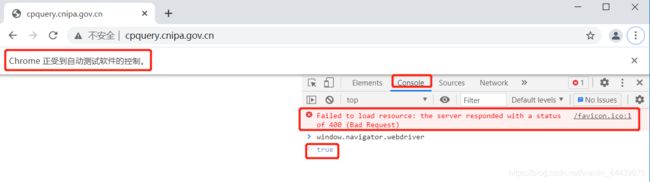
2.报错截图对应的代码:
from selenium import webdriver
import time
class Crawl_ZhuanLi(object):
def __init__(self):
chromeoption = webdriver.ChromeOptions()
# chromeoption.add_argument('--headless') # 无头浏览器
chromeoption.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
self.driver_path = './windows_chromedriver.exe'
self.driver = webdriver.Chrome(self.driver_path, chrome_options=chromeoption)
def get_value(self,url):
self.driver.get(url)
print("开始爬取...")
time.sleep(60)
Crawl_ZhuanLi().get_value(url='http://cpquery.cnipa.gov.cn/')
3.备注:
(1)driver_path 对应的chromedriver路径请自行填写,
(2)chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html;
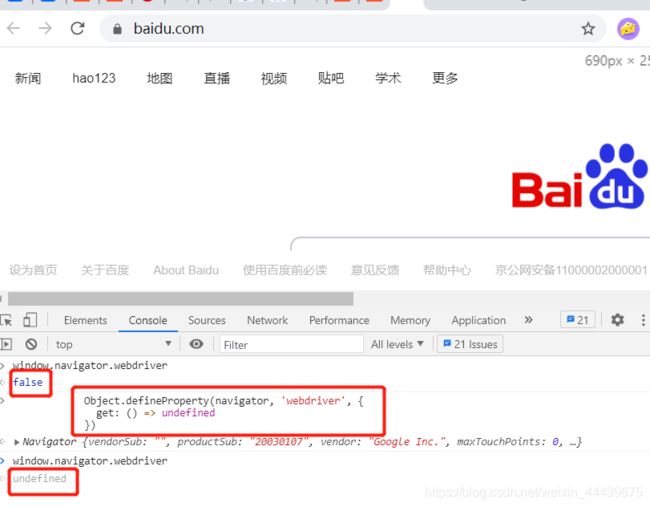
(3)非爬虫操作时,我们在F12控制台输入window.navigator.webdriver时,显示的是false;
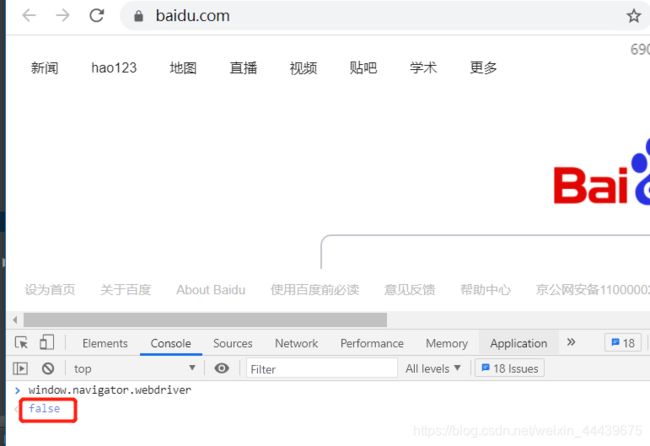
二、解决方案:
1.在driver.get(url)前加入如下代码:
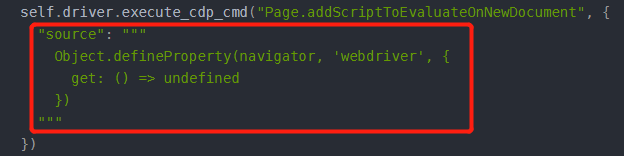
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
2.效果:

三、完整代码:
from selenium import webdriver
import time
class Crawl_ZhuanLi(object):
def __init__(self):
chromeoption = webdriver.ChromeOptions()
# chromeoption.add_argument('--headless') # 无头浏览器
chromeoption.add_argument('--no-sandbox') # 解决linux DevToolsActivePort文件不存在的报错
chromeoption.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36')
self.driver_path = './windows_chromedriver.exe'
self.driver = webdriver.Chrome(self.driver_path, chrome_options=chromeoption)
def get_value(self,url):
# 下面这行代码目的为:防止网站识别出是selenium
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
self.driver.get(url)
print("开始爬取...")
time.sleep(60)
Crawl_ZhuanLi().get_value(url='http://cpquery.cnipa.gov.cn/')
四、分析总结:
1.为什么我们进不了网站:
待爬取网站运行自己的 JavaScript 代码,对我们(爬虫)发送过去的请求信息进行检测,然后发现我们是selenium后,把我们(爬虫)的请求禁掉了。
(比如待爬网站做了一个 window.navigator.webdriver 检测,发现你返回的是 true)
2.解决思路:
在待爬取的网站运行其自带的 JavaScript 代码前,先执行下我们的js代码,去隐藏或修改掉我们的window.navigator.webdriver信息。
3.按照思路,如何解决:
利用Chrome 开发工具协议( 简称CDP ),在 Selenium 中调用 CDP 的命令。
即:在使用selenium时,使用driver.execute_cdp_cmd命令,传入需要调用的 CDP 命令和参数,之后selenium会帮我们对Chrome的window.navigator.webdriver信息进行调整。
selenium会给定一段 JavaScript 代码,让 Chrome 刚打开页面,还没运行网站自带的 js 代码时,就先执行一个js,修改Chrome的window.navigator.webdriver。
4.查找文档,逐个分析:
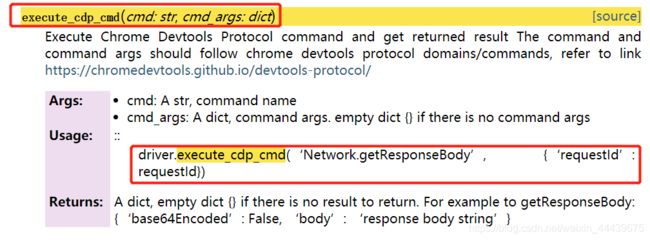
(1)execute_cdp_cmd: selenium去执行CDP方法。
这里的英文逐字拼起来,我理解为:执行(execute),按照Chrome开发协议(CDP),在终端命令行(cmd)。
即:在Chrome浏览器控制台终端,按照其开发协议,执行XX命令。
(2)Page.addScriptToEvaluateOnNewDocument:
从CDP 的官方文档,我们可以看到 Page.addScriptToEvaluateOnNewDocument 的作用是:在页面创建前(也是被爬页面的script加载前),先执行截图里的 javascript。
即:1.添加javascript; 2.在frame(页面)加载前;
(这里做过前端的可以参考下vue的生命周期,这里涉及了html的生命周期);
(3)
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
作用:定义webdriver浏览器驱动的 navigator 的值为 undefined。
4.备注:
(1)除了上述这个方法,还有别的方法解决此问题;
(2)仅较新版本的 Chrome+ChromeDriver 适用此方法,不兼容的话,可以考虑升级下,不过较老版本的Chrome,也有对应老版本的方法来解决此问题(不过老版本方法,不兼容新版本)。
五、参考资料:
1.CPD 的官方文档: https://chromedevtools.github.io/devtools-protocol/tot/Page#method-addScriptToEvaluateOnNewDocument
2.selenium官方文档:https://www.selenium.dev/selenium/docs/api/py/webdriver_chromium/selenium.webdriver.chromium.webdriver.html?highlight=execute_cdp_cmd#selenium.webdriver.chromium.webdriver.ChromiumDriver.execute_cdp_cmd
3.最初参考网站(感谢):
https://www.cnblogs.com/presleyren/p/12936553.html