Tableau Desktop可视化及参数及集及函数经验总结
Tableau Desktop可视化及参数及集及函数经验总结
Tableau Desktop
数据源操作
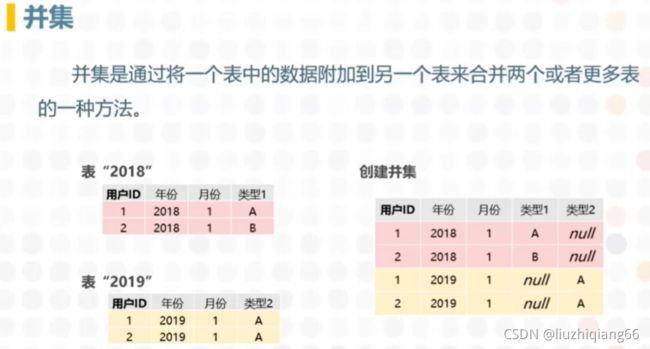
表的并集
表的并集:就是通过将一个表中的数据附件到另一个表来合并两个或者更多表的一种方法。两个表字段差不多,如一个表有十行数据,另一个表有二十行数据,借助表合并变成三十行数据的新表。
运用示例
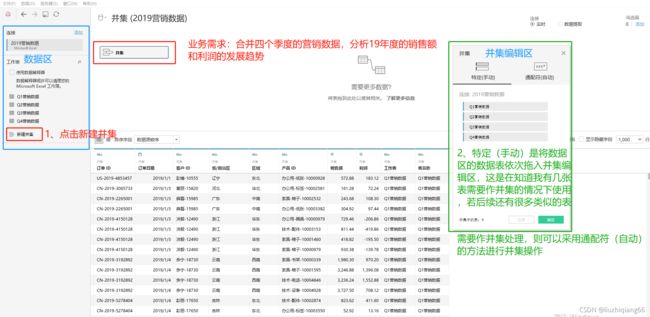
业务需求:合并四个季度的营销数据,分析19年度的销售额和利润的发展趋势。
表的联接
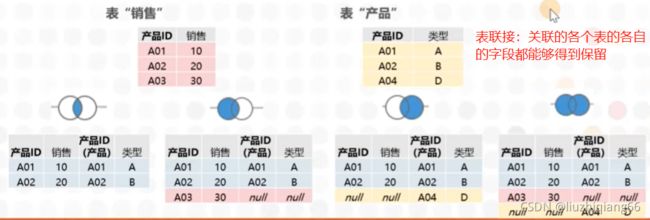
表联接:就是将两个或更多表关联成一个结果集,该结果集是一个通过添加数据列横向扩展的表,即增加字段的表(注意:两个表各自的所有字段都保留了下来)。如:两张表行数差不多,或行数相差比较大,但是有一些值存在第一张表,另一些值存在另一张表,如学生的语文成绩是一张表,数学成绩是另一张表,两张表都有学生的学号和姓名字段,需要把两张表通过表的联接操作合在一起来展示学生的语文和数学成绩。表的联接操作包含:“内联接,外联接,左联接,右联接”等操作。主要是通过两表或多表都包含的一些关联字段进行关联的联接操作。
运用示例
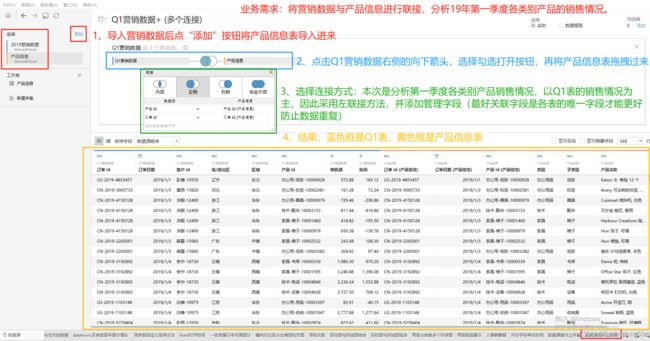
业务需求:将营销数据与产品信息进行联接,分析19年第一季度各类别产品的销售情况。
数据混合
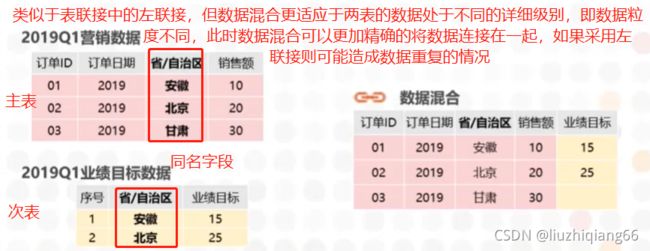
数据混合:就是根据同名关联字段,将来自不同数据库或文本表中的数据进行组合。不同于表的并集和表的联接最后能够输出一个结果集,再进行数据分析,数据混合最后依然是保持了数据源各自的独立性,但会通过同名的关联字段进行数据的联接。
数据混合通常适用于营销中的业绩达标情况分析:订单数据源往往会记录每个订单的数据,但是业绩目标通常不会对每一个订单进行设定,而是单独的另一张表,且业绩目标通常是对某个地区或某个省份,城市或年月份进行设定。当我们需要查看达标情况时,两张表的数据就处于不同的详细级别,所以这时就需要借助数据混合进行达标情况分析。
运用示例
业务需求:混合营销数据源与业绩目标数据源,分析19年第一季度各省份的业绩达标情况。
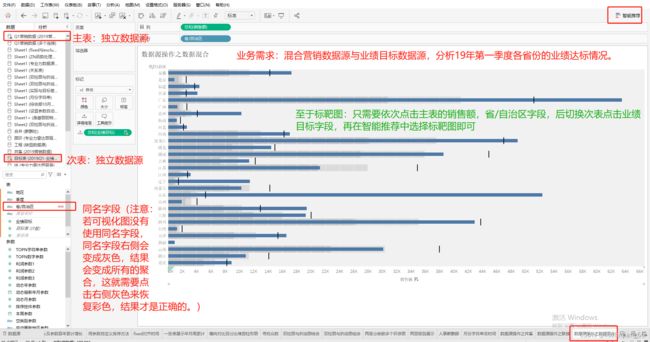
数据混合与表联接区别
数据混合类似于表联接中的左联接,但数据混合更适应于两表的数据处于不同的详细级别,即数据粒度不同,此时数据混合可以更加精确的将数据连接在一起,如果采用左联接则可能造成数据重复的情况。
数据混合适用场景:1、想要合并的数据来自联接不支持的不同数据库;2、数据位于不同的详细级别,使用表联接会产生重复数据;3、正在处理大量数据,表联接会影响处理性能。注意:1、数据混合中出现的“*”值,表示次数据源中具有多个对应的值,即以主数据源存在一对多的关系;2、NULL值,表示次数据源中没有与主数据源对应的匹配项。

常用函数
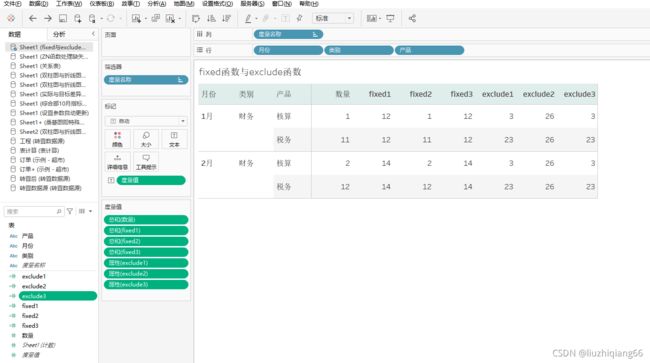
一、fixed函数与exclude函数与include函数(不同维度之间的聚合计算)
{fixed 维度1,维度2,… : 聚合度量},仅使用指定的维度(维度1,维度2,…)计算聚合度量;
{exclude 维度1,维度2,… : 聚合度量},如果指定的维度(维度1,维度2,…)出现在试图中,则计算聚合时会排除这些维度分组的影响。
fixed1 = { FIXED [月份],[类别]:SUM([数量])}
fixed2 = { FIXED [月份],[类别],[产品]:SUM([数量])}
fixed3 = { FIXED [月份]:SUM([数量])}
exclude1 = { EXCLUDE [月份],[类别]:SUM([数量])}
exclude2 = { EXCLUDE [月份],[类别],[产品]:SUM([数量])}
exclude3 = { EXCLUDE [月份]:SUM([数量])}
示例:购物车关联分析(同时购买多种物品)
需求
购物车分析是通过顾客的购物车信息研究其购买行为。主要目的在于找出什么样的东西应该放在一起。通过分析顾客的购买行为来探知顾客的属性及购买某些
商品的可能原因,找出相关的联系规则,企业可利用这些规则更好的挖掘商业利益并建立竞争优势。而且企业最常用的购物车分析当属关联购买分析:通过分析销
售数据,来了解同时购买多个产品的人数或者订单数量,从而进行合理的产品投放。最著名的购物篮分析,就属“啤酒与尿布”的故事,它正是一个典型的关联购买
分析场景。
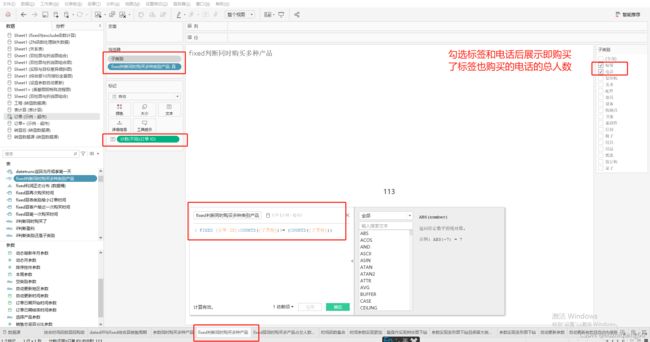
1、创建fixed判断同时购买多种类别产品的计算字段
{ FIXED [订单 ID]:COUNTD([子类别])}= {COUNTD([子类别])}
2、设置筛选器
把子类别及第1步刚刚创建的判断计算字段拖放至筛选器。**再右击筛选器上的“子类别”胶囊,在下拉菜单中选择“添加到上下文”。**然后,右击筛选器上的判断
计算字段胶囊,勾选“真”进行筛选即可。
3、同时购买占购买人数的比率
创建fixed与countd判断购买多种产品人数计算字段
COUNTD(IF { FIXED [订单 ID]:COUNTD([子类别])}= {COUNTD([子类别])}
THEN [订单 ID] END)
创建countd总客户数计算字段
COUNTD([订单 ID])
4、展示效果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sWbxop6f-1638113593141)(D:\gongzuo\超市示例\tableau总结图片\28.png)]
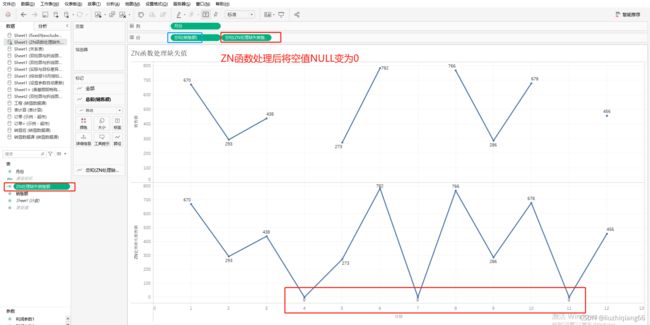
二、ZN函数(处理缺失值,将null变为0):
主要用于处理缺失值,ZN(expression),如果括号内的表达式为NULL,则返回0,如果不为NULL,则返回自身。因为统计计算时可以在某天或某月漏统计,就会出现缺失值,这是使用ZN(SUM(amount))或ZN(number)即可将缺失值填充为0。
ZN([销售额])
三、日期函数
1、date_part(以下日期函数的日期单位):

2、DATEADD(日期偏移指定单位):
1)语法:DATEADD(date_part, interval, date)
2)返回:返回指定日期,该日期的指定 date_part 中添加了指定的数字 interval
3)举例:
DATEADD(‘month’, 3, #2020-04-15#) = 2020-07-15 12:00:00 AM
//该表达式会向日期 #2020-04-15# 添加三个月。
3、DATEDIFF(时间差计算):
1)语法:DATEDIFF(date_part, date1, date2, [start_of_week])
2)返回:返回 date1 与 date2 之差(以 date_part 的单位表示)。
start_of_week 参数(可用于指定哪一天是一周的第一天)是可选的。可能的值为“monday”、“tuesday”等。
3)举例:
DATEDIFF(‘week’, #2020-09-20#, #2020-09-22#, ‘monday’)= 1
DATEDIFF(‘week’, #2020-09-20#, #2020-09-22#, ‘sunday’)= 0
//第一个表达式返回 1,因为当 start_of_week 为 ‘monday’ 时,9 月 22(星期日)和 9 月 24(星期二)不属于同一周。
//第二个表达式返回 0,因为当 start_of_week 为 ‘sunday’ 时,9 月 22(星期日)和 9 月 24(星期二)属于同一周。
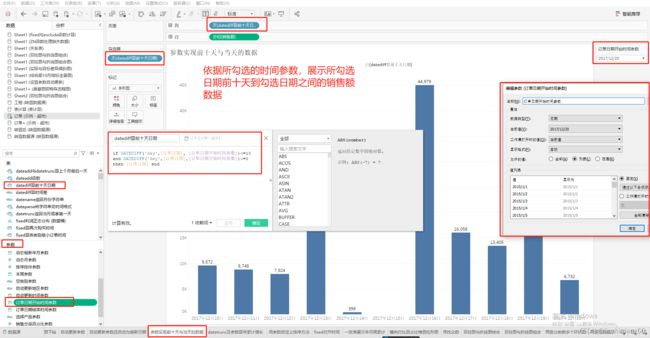
运用示例:结合参数展示前十天数据
if DATEDIFF('day',[订单日期], [订单日期开始时间参数])<=10
and DATEDIFF('day',[订单日期],[订单日期开始时间参数])>=0
then [订单日期] end
4、DATENAME(日期转换为字符串格式):
1)语法:DATENAME(date_part, date, [start_of_week])
2)返回:以字符串的形式返回 date 的 date_part。start_of_week 参数(可用于指定哪一天是一周的第一天)是可选的。可能的值为“monday”、“tuesday”等
3)举例:
DATENAME(‘year’, #2020-04-15#) = “2020”
DATENAME(‘month’, #2020-04-15#) = “April”
5、DATEPARSE(字符串转换为日期格式):
1)语法:DATEPARSE(date_format, [date_string])
2)返回:返回 [date_string] 作为日期。 date_format 参数将描述 [字符串] 字段的排列方式。由于可通过各种方式对字符串字段进行排序,因此 date_format 必
须完全匹配
3)举例:
DATEPARSE(‘yyyy-MM-dd’, #2020-04-15#) = “April 4, 2020”
6、DATEPART(获取单列年或季或月或日):
1)语法:DATEPART(date_part, date, [start_of_week])
2)返回:以整数的形式返回 date 的 date_part。
start_of_week 参数(可用于指定哪一天是一周的第一天)是可选的。可能的值为“monday”、“tuesday”等
3)举例:
DATEPART(‘year’, #2020-04-15#) = 2020
DATEPART(‘month’, #2020-04-15#) = 4
7、DATETRUNC(获取当年或季或月第一天):
1)语法:DATETRUNC(date_part, date, [start_of_week])
2)返回:按 date_part 指定的准确度截断指定日期。此函数返回新日期。例如,以月份级别截断处于月份中间的日期时,此函数返回当月的第一天。
start_of_week 参数(可用于指定哪一天是一周的第一天)是可选的。可能的值为“monday”、“tuesday”获取等
3)举例:
DATETRUNC(‘quarter’, #2020-08-15#) = 2020-07-01 12:00:00 AM
DATETRUNC(‘month’, #2020-04-15#) = 2020-04-01 12:00:00 AM
运用示例:结合参数展示从年初到参数日期的累加和
年累计即从年初累计至当前日期,年累计增长率:本期年累计对比同期年累计的增长情况。例如:计算从 2021 年 1 月 1 日累计至 8 月 31 日的销售额,与
2020 年 1 月 1 日累计至 8 月 31 日的销售额增长情况。非常典型的应用就是 YTD( Year to Date )增长率分析。
1、创建datetrunc算本期年累计销售额计算字段
IF [订单日期]>=DATETRUNC('year',[订单日期开始时间参数])
AND [订单日期]<=[订单日期开始时间参数]
THEN [销售额] END
2、创建datetrunc算年累计增长率计算字段
IF [订单日期]>=DATETRUNC('year',DATEADD('year',-1,[订单日期开始时间参数]))
AND [订单日期]<=DATEADD('year',-1,[订单日期开始时间参数])
THEN [销售额] END
3、创建datetrunc算同期年累计销售额计算字段
SUM([datetrunc算本期年累计销售额]) / SUM([datetrunc算同期年累计销售额])-1
4、显示效果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X9OujcW8-1638113593143)(D:\gongzuo\超市示例\tableau总结图片\26.png)]
8、YEAR(获取给定日期的年):
1)语法:YEAR (date)
2)返回:以整数的形式返回给定日期的年份
3)举例:
YEAR(#2020-04-15#) = 2020
9、QUARTER:
1)语法:QUARTER ( )
2)返回:以整数的形式返回给定日期的季度
3)举例:
QUARTERK (#2004-04-15#) = 2
10、MONTH:
1)语法:MONTH(date)
2)返回:以整数的形式返回给定日期的月份
3)举例:
MONTH(#2020-04-15#) = 4
11、WEEK:
1)语法:WEEK( )
2)返回:以整数的形式返回给定日期的周
3)举例:
WEEK (#2020-04-15#) = 16
12、DAY(获取给定日期的天):
1)语法:DAY(date)
2)返回:以整数的形式返回给定日期的天
3)举例:
DAY(#2020-04-12#) = 12
13、NOW(获取当前本地系统时间和日期):
1)语法:NOW( )
2)返回:返回当前本地系统日期和时间
3)举例:
NOW( ) = 2020-05-15 1:08:21 PM
14、TODAY(获取当前日期):
1)语法:TODAY( )
2)返回:返回当前日期
3)举例:
TODAY( ) = 2020-05-15
15、ISDATE(判断是否是日期格式):
1)语法:ISDATE(string)
2)返回:如果给定字符串为有效日期,则返回 true
3)举例:
ISDATE(“April 15, 2020”) = true
16、MAX(获取两个日期或两个数字的最大值):
1)语法:MAX(expression) or MAX(expr1, expr2)
2)返回:
通常应用于数字,不过也适用于日期。返回 a 和 b 中的较大值(a 和 b 必须为相同类型)。如果任一参数为 Null,则返回 Null
3)举例:
MAX(#2004-01-01# ,#2004-03-01#) = 2004-03-01 12:00:00 AM
4)运用场景举例:
如零售或互联网行业,查找出每个客户的最近一次购买时间,则采用:
{ FIXED [客户 ID] : MAX([订单日期]) }
17、MIN(获取两个日期或两个数字的最小值):
1)语法:MIN(expression) or MIN(expr1, expr2)
2)返回:
通常应用于数字,不过也适用于日期。返回 a 和 b 中的较小值(a 和 b 必须为相同类型)。如果任一参数为 Null,则返回 Null
3)举例:
MIN(#2004-01-01# ,#2004-03-01#) = 2004-01-01 12:00:00 AM
4)运用场景举例:
如零售或互联网行业,查找出每个客户的第一次购买时间,则采用:
{ FIXED [客户 ID] : MIN([订单日期]) }
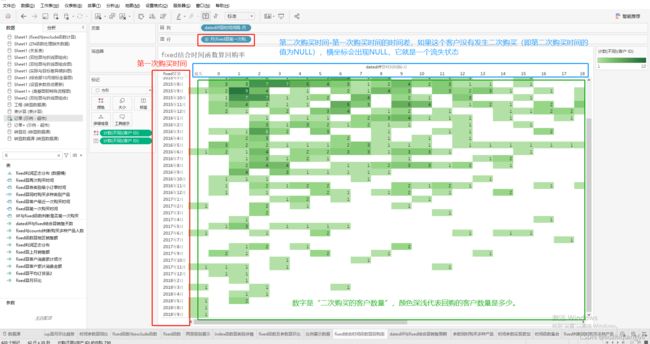
运用示例:客户回购分析
市场营销中,能否抓住回头客以及回头客的多少,都是产品是否能够经受市场考验的具体表现,对于回头客的分析则会直接影响到公司的决策。
如下图所示:1、图表中的纵坐标是”第一次购买时间”,我们这里按照季度统计(实际应用中也可以换成年、月、日等);2、图表中的横坐标是“第二次购买
时间-第一次购买时间”,如果这个客户没有发生二次购买(即第二次购买时间的值为NULL),横坐标会出现NULL,它就是一个流失状态;3、图表中的数字是“二
次购买的客户数量”,颜色深浅代表回购的客户数量是多少。
创建计算字段
1:fixed算第一次购买时间
{ FIXED [客户 ID] : MIN([订单日期]) }
2:IIF与fixed函数判断是否第一次购买:功能:如果不是第一次购买,则返回订单日期,如果只购买了一次则返回NULL,说明客户流失。
IIF([订单日期]>[fixed算第一次购买时间],[订单日期],NULL)
3、fixed算再次购买时间
{ FIXED [客户 ID]:MIN([IIF与fixed函数判断是否第一次购买])}
4:datediff算时间间隔-月
DATEDIFF('month',[fixed算第一次购买时间],[fixed算再次购买时间])
展示效果图如下:
18、日期函数示例:获取上个月最后一天
DATEADD('day',-1,DATEADD('month',0,DATETRUNC('month',TODAY())))
//获取上个月最后一天
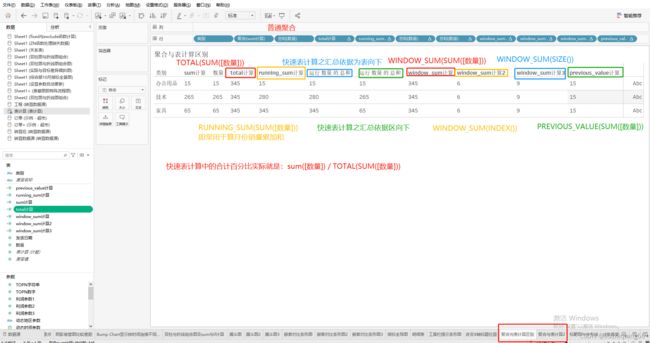
三、表计算函数
四、iif()函数:
主要用于是否满足条件,IIF(expression,then,else,[unknown]),如果括号内的表达式为真,则返回then这个值,如果为假,则返回else值,如果未知,则返回可选的第三个值或者NULL。
IIF([利润]>= 0,1,2)
//找出利润大于0的利润数量。
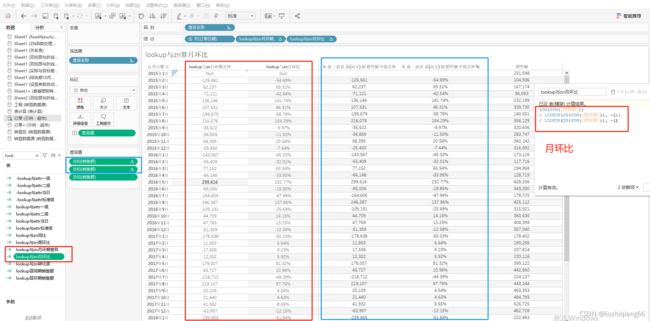
五、lookup()函数:
主要用于计算同期,环期,进而计算同环比,一般lookup(SUM(amount),-1):按年,季,月,周计算环期值,即上一个年,季,月,周的销量(注意:年环
期和年同期是一样的即年同比 = 年环比,所以年环比和年同比计算公式一模一样);而lookup(SUM(amount),-12):按月计算同期值,即去年这个月的销量。注
意,现实场景中如果是计算环期差异或环比,可以借助快速表计算的差异算环期差异值,快速表计算的百分比差异算环比,如果想生成一个新的计算环期差异和环
比值计算字段,可以直接把表计算拖拽到计算字段编辑处。


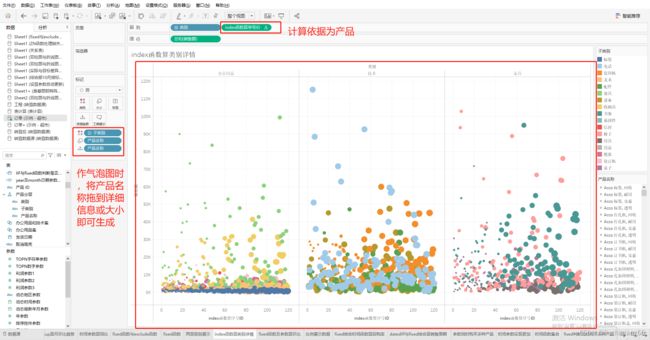
六、index()函数:
主要用于计算序号,也就是SQL中的序号,直接书写index()即可以得出对应的序号。注意:此函数计算序号,如果有分层结构,如超市示例的类别,子类别,
产品名称三级分层,如果index()的计算依据是类别,则就是3。如下图展示的气泡图,计算依据就是产品名称。
七、left()函数:
主要用于截取字符串前端指定数量的字符,一般left(string,number):截取字符串string开头部门的字符串。
left('calculation',4) = 'calc'
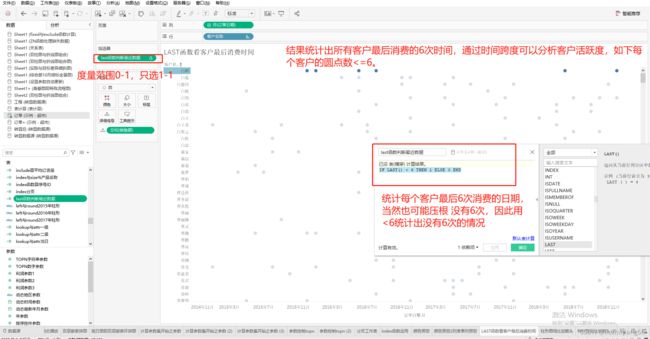
八、last()函数(返回当前行到分区最后一行的行数):
主要用于返回当前行到分区最后一行的行数,常用于查看不同客户的最后几次消费。
IF LAST() < 6 THEN 1 ELSE 0 END
九、RANK_UNIQUE()排序函数
主要用于排序,特别适用于显示TOPN或者动态更改排序方式场景,RANK_UNIQUE(expression,[‘asc’ | ‘desc’]):功能:为分区中的当前行返回唯一排名,或为不同的排名分配相同的值。使用可选的’asc’ | ‘desc’ 参数指定升序或降序。默认为降序。
RANK_UNIQUE(expression,['asc' | 'desc'])
//示例:对应分区中的第一行,RANK_UNIQUE() = 1
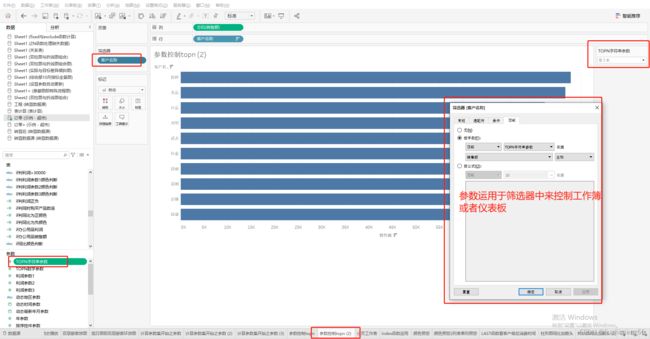
运用示例1:展示TOPN
在同一仪表板中,有时需要在同一个报表模块中,有左右两个工作簿共同组成一个可视化模块,但需要依据任务数展示TOP10,这时借助参数的话,可能有些大材小用,借助表计算中排序显然难于保障两个工作簿的排序依据完全一样。这时最好的方法是有一个两个工作簿都能够使用排序计算字段,并分别将该计算字段使用到各自的筛选器中。
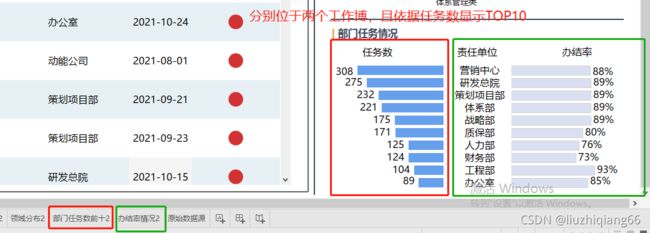
创建计算字段
任务数排序计算字段:功能:如果依据COUNT([编号])所计算的任务个数排行前十,将改计算字段拖拽到筛选器时,选择显示按钮,让前十显示。
if RANK_UNIQUE(COUNT([督办编号 (复制)]) ,'desc') >10 then '不显示' else '显示' end
展示效果图如下:
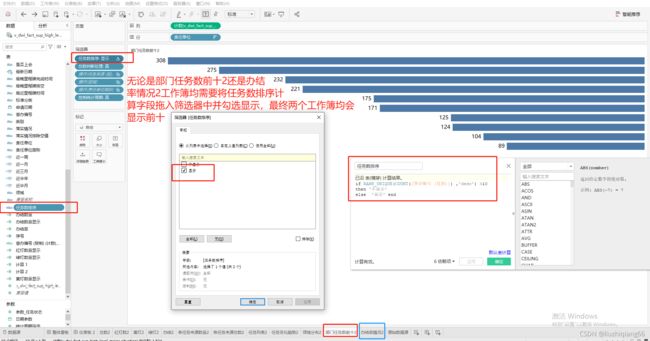
运用示例2:自定义排序
实际场景运用中,有时需要可以自定义排序方面,或依据首字母升序,或依据首字母降序,或依据销售额升序,或依据销售额降序等方式进行排序。这时可以创建一个排序控件参数将各种排序方式列出,再借助RANK_UNIQUE() 函数创建一个计算字段来定义排序依据及排序方式,最后将这个创建的排序字段拖入可视化报表的行中。
创建排序控件参数
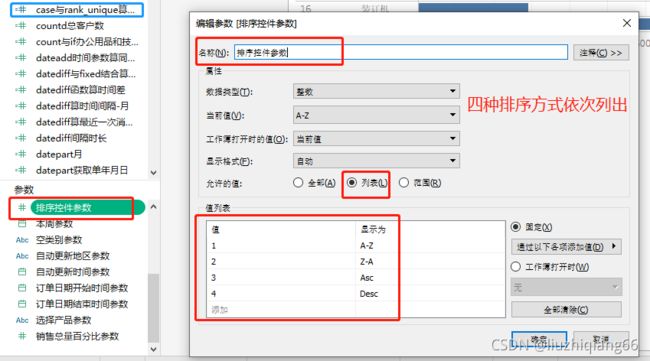
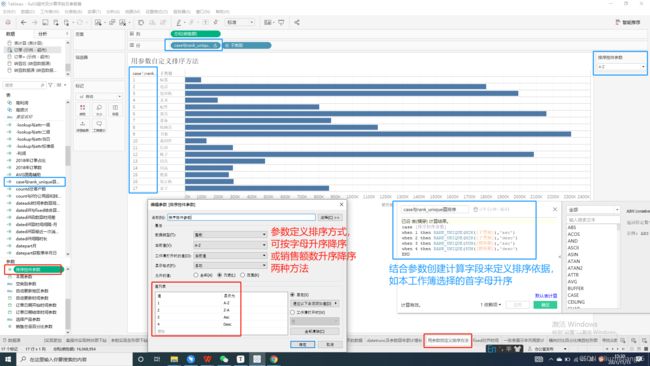
创建计算字段
case与rank_unique算排序计算字段:功能:结合参数定义排序方式及其依据。
case [排序控件参数]
when 1 then RANK_UNIQUE(MIN([子类别]),'asc')
when 2 then RANK_UNIQUE(MIN([子类别]),'desc')
when 3 then RANK_UNIQUE(SUM([销售额]),'asc')
when 4 then RANK_UNIQUE(SUM([销售额]),'desc') END
//排序控件参数:是上一步所创建的参数
创建计算字段
1:fixed算第一次购买时间
{ FIXED [客户 ID] : MIN([订单日期]) }
2:IIF与fixed函数判断是否第一次购买:功能:如果不是第一次购买,则返回订单日期,如果只购买了一次则返回NULL,说明客户流失。
IIF([订单日期]>[fixed算第一次购买时间],[订单日期],NULL)
3、fixed算再次购买时间
{ FIXED [客户 ID]:MIN([IIF与fixed函数判断是否第一次购买])}
4:datediff算时间间隔-月
展示效果图如下:
十、MAKEPOINT()创建空间点与MAKELINE()创建两点线函数
MAKEPOINT()函数主要用于创建空间上的地理点,且借助此函数创建的点会自动变成地理角色,MAKEPOINT(数字,数字)或MAKEPOINT(数字,数字,数字)表达形式,结果返回依据纬度和经度构建的空间地理点位置,或者返回依据X坐标或Y坐标和SRID构成的空间对象。如:MAKEPOINT([纬度],[经度])或MAKEPOINT([X坐标],[Y坐标],102748)。运用示例如多层旭日图中创建点
MAKELINE()函数主要用于创建两点间的连线,MAKELINE([Start],[End])表达形式,结果返回依开始点和结束点所构建的连线。可以是地理位置间的连线,或坐标轴上两点之间的连线。
整体运用示例:如下方数据地图运用中的“航线地图”。
MAKEPOINT(数字,数字)
MAKEPOINT(数字,数字,数字)
MAKEPOINT([纬度],[经度])
MAKEPOINT([X坐标],[Y坐标],102748)
MAKELINE([Start],[End])
数据地图运用
1、使用场景
总体来说,想要了解地理空间分布特点,最好使用数据地图。大型连锁超市分析产品在全国各城市的销量对比,寻找针对各种城市的营销策略;或者如某个沃尔玛等大型商场,分析整栋商场各货架的摆放位置,寻找合适的货架摆放地点,以及寻求各产品的关联关系,以求在货架上合理摆放两种不同,以求增加销量,制定合理价格等等;或者飞机或货轮或影院各位置客户的最佳选择位置,寻求合理分配,制定合理价格等等。
数据地图有散点地图和染色地图及航线图等。染色地图可以一眼看出大型连锁超市各区域或省份的销量分布,了解业绩是否达标情况,散点地图可以清晰通过点位的大小及颜色等分析各地域销售具体情况。
2、商场摊位自定义地图示例
如下图所示:通过这张数据地图,就可以很清晰的发现,颜色越绿,代表这个摊位点人流量越大;圆圈越大,代表这个摊位点顾客平均停留时间越长,所以我们就可以比较容易的找到最合适的摊位地点。

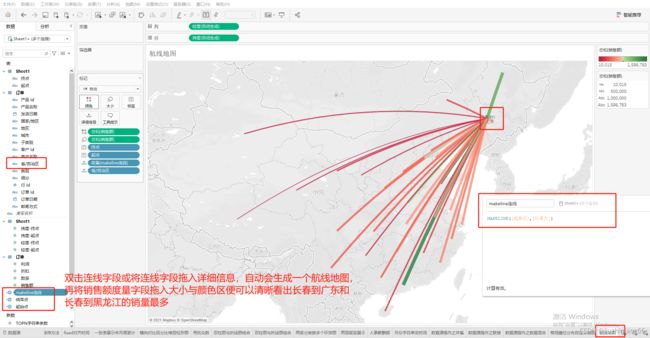
3、航线地图示例
如下图所示:这是一个大型供应商从长春出发供应全国各省货运商品的航线地图,销售额越大,航线的宽度越宽,且颜色越绿,从这里可以清晰看出长春到广东和长春到黑龙江的销量最多。
依据起点经纬度创建地理起始点
MAKEPOINT([纬度-起点],[经度-起点])
依据终点经纬度创建地理结束点
MAKEPOINT([纬度-终点],[经度-终点])
依据起始点和结束点创建两点间的连线:makeline连线计算字段
MAKELINE([起始点],[结束点])
参数运用
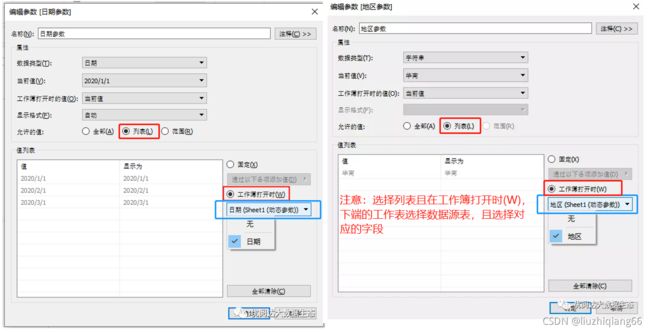
一、参数创建:
参数创建时:如果是时间参数,可以选中数据源中的时间字段,右键单击即可创建时间参数,如下的利润参数则是选中数据源中的利润字段,右键创建利润参数。

二、参数控制工作簿或仪表板
方法1:将参数运用于所需控制的工作簿或仪表板的计算字段中。
IF SUM([利润]) > [利润参数2] THEN '高'
ELSEIF SUM([利润]) >=0 THEN '低'
ELSE '亏' END

方法2:将参数运用于所需控制的工作簿或仪表板的筛选器的顶部条件中。
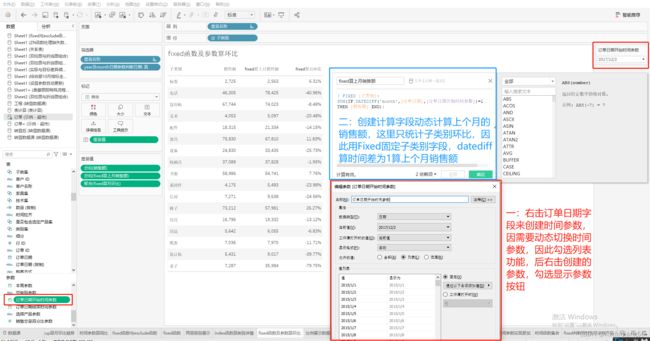
三、参数结合Fixed函数动态算环比
1:创建时间参数,并显示参数
计算上个月的销售额
{ FIXED [子类别]:
SUM(IF DATEDIFF('month',[订单日期],[订单日期开始时间参数])=1
THEN [销售额] END)}
//此函数用于统计上个月的销售额,注意:订单日期为数据源中自带的字段,而订单日期开始时间参数则是利用订单日期字段所创建的动态时间参数。
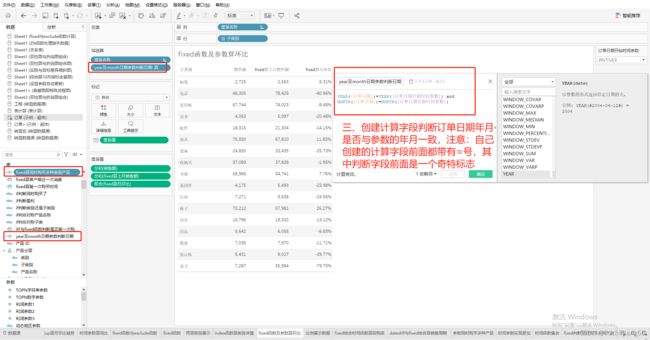
计算月环比
(SUM([销售额])-SUM([fixed算上月销售额])) / SUM([fixed算上月销售额])
2:创建年月日期判断计算字段并只选真
结果:月环比等数值数据谁订单日期开始时间参数动态变化。
四、时间参数动态控制月销售额累加
需求
通过筛选器选择销售额的累计月数,选择1月时,柱图就只显示出1月的销售额,选择2月时,柱图就显示出1月和2月销售额的累加和。接着以此类推。
1:创建年和月两个时间参数,并显示参数
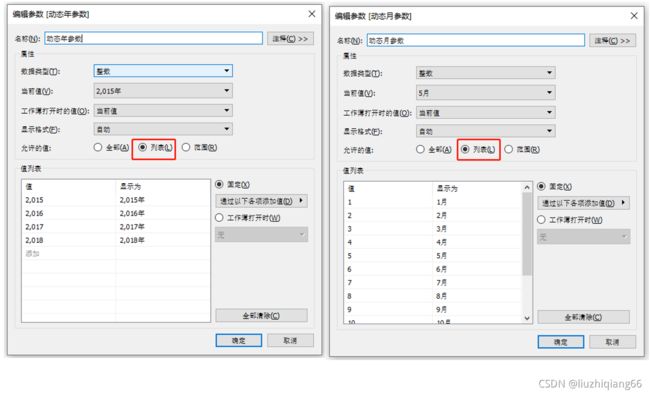
2:创建if与year与month参数实现时间金额累加计算字段与结果展示
IF YEAR([订单日期])=[动态年参数] AND
MONTH([订单日期])<=[动态月参数] THEN [销售额] END
展示效果如下:切换动态月参数,柱图的高度及其数值会随之变化。
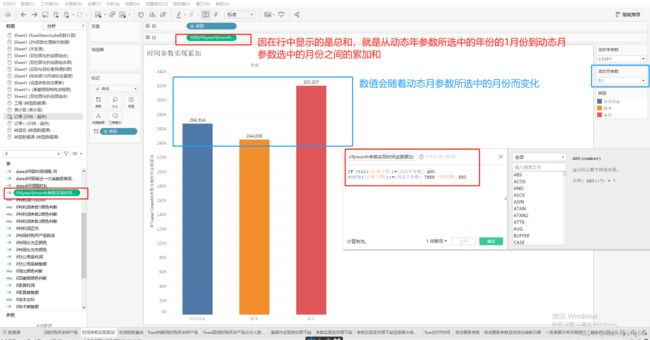
五、参数实现数据下钻
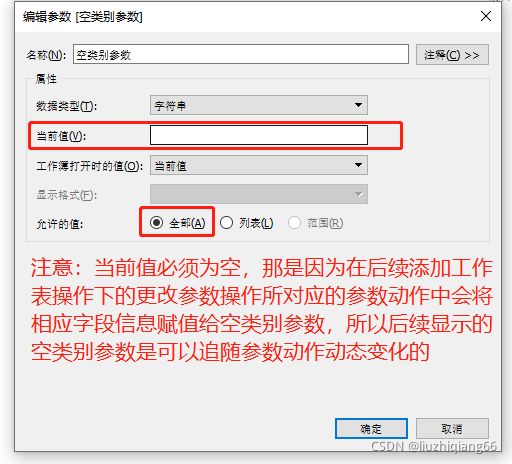
1:创建类别参数,并显示参数
注意:当前值必须为空,那是因为在后续添加工作表操作下的更改参数操作所对应的参数动作中会将相应字段信息赋值给空类别参数,所以后续显示的空类别
参数是可以追随参数动作动态变化的。
2:创建if判断类别还是子类别计算字段
IF [空类别参数] = [类别] THEN [子类别] ELSE [类别] END
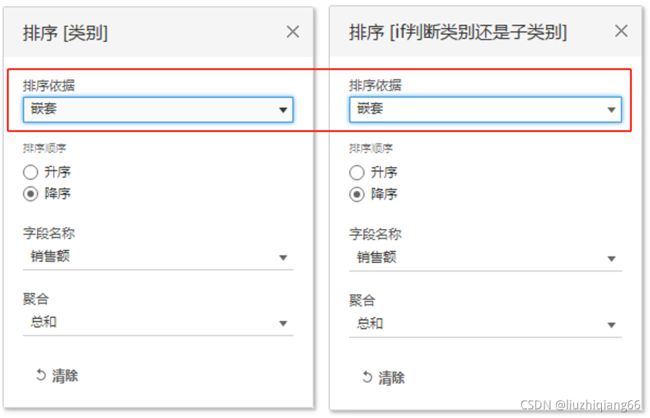
3:设置嵌套降序排序
这部可以有,也可以无,有排序,相对更好看,展开前,类别字段依据销售额降序排序,展开后,所属子类别意思依据销售额降序排序。
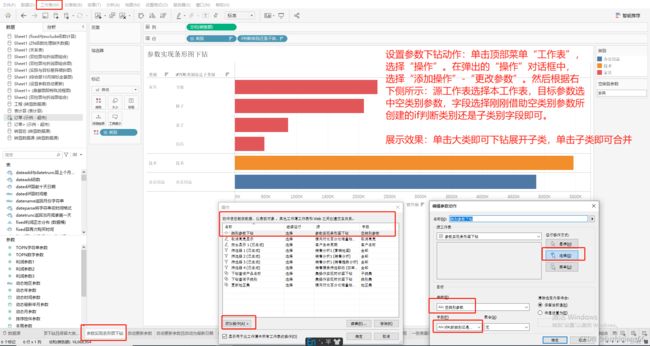
4:设置参数下钻所对应参数动作及结果展示
设置参数下钻动作:单击顶部菜单“工作表”,选择“操作”。在弹出的“操作”对话框中,选择“添加操作”-“更改参数”。然后根据右下侧所示:源工作表选择本工作
表,目标参数选中空类别参数,字段选择刚刚借助空类别参数所创建的if判断类别还是子类别字段即可。
展示效果:单击大类时,空类别参数显示为所单击的大类,再单击展开的任意一个子类即可完毕,对应的空类别参数则显示为所单击的子类。
六、自动更新参数
1:需求1
参数可以自动随着数据源excel表或数据库表中内容的更新而更新,即现实生活中零售行业或者互联网行业数据的每天在数据源中会添加一些新的销售数据或
流量数据,需要所对应的参数也能随着数据源数据的添加而刷新增加。
2:自动更新参数创建
3:需求2
在需求1的基础上,报表需要展示最新日期的数据,且自动更新展示最新日期的数据,展示也是自动更新显示最新日期。
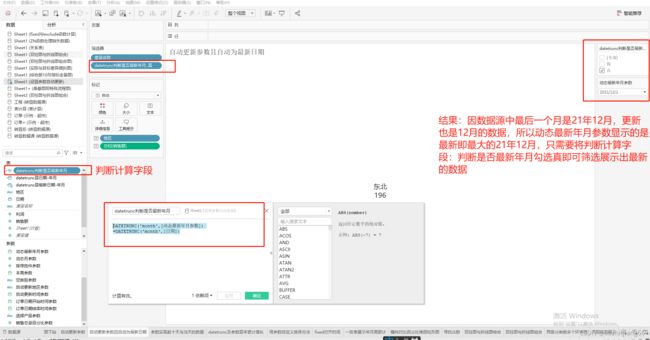
4:借助MAX函数创建计算字段显示最新日期
{MAX(DATETRUNC('month',[日期]))}
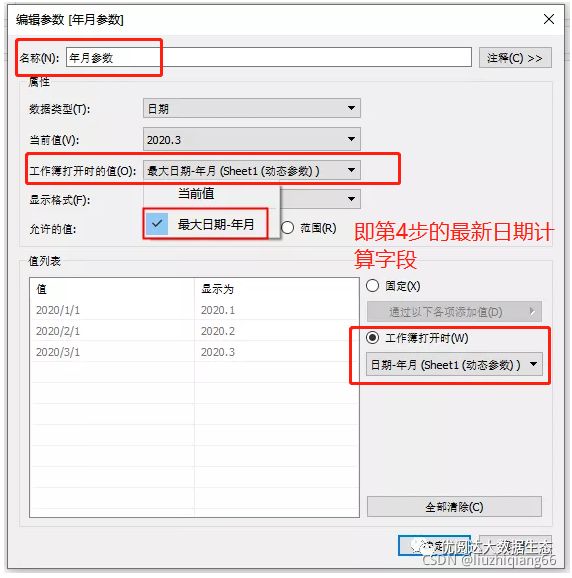
5:创建动态最新年月参数
其他设置跟上述第二个步骤的日期参数设置一样,但是其中工作簿打开时的值设置为步骤4对应的最新日期计算字段。
6:创建datetrunc判断是否最新年月计算字段
DATETRUNC('month',[动态最新年月参数]) = DATETRUNC('month',[日期])
将上述创建的判断计算字段拖到筛选器中并选择真即可展示最新日期的数据。
七、参数控制日期切换(近7天,近一月等)
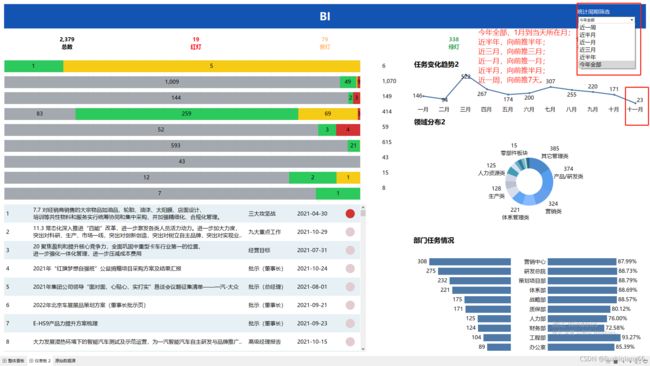
1:需求
如下图所示:实现的效果是:打开报表页面默认显示今年全部,报表数据全部按时间维度年进行统计,若今天是十一月初,还没有到十二月,则显示今年前十一月的汇总数据,时间趋势图则展示今年前十一月的趋势折线图。但可以切换时间维度为近半年,同理,若今天是十一月初,前近半年会展示从五月到十一月的汇总数据,时间趋势图则展示今年从五月到十一月的趋势折线图。同理可以切换为近三月,向前推三月;近一月,向前推一月;近半月,向前推半月;近一周,向前推7天。
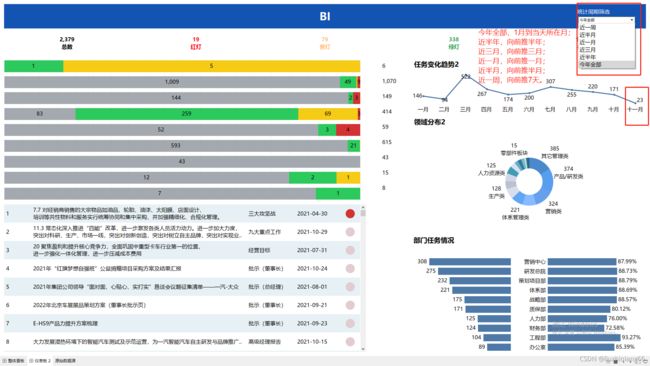
2、难点
卡片中的统计数据与图形中的数据及趋势图数据均可随着统计周期筛选参数的切换而随之变化,因此需要建立日期参数和统计周期筛选两个参数,以便用切换参数时通过将参数运用于判断计算字段中的方法实现时间维度的切换。因此除了需要创建两个参数外,还需要创建判断是否近一周,近半月等6个计算字段。
3、参数的创建
报表顶端统计周期筛选日期参数的设置,因日期参数的切换包含今年全部,近半年,近三月,近一月,近半月,近一周共6个选项,所以在值列表区域将6种情况依次列出。而日期参数则需要能够自动更新的参数,需要连接数据库中的数据表的日期字段。如本次为数据表中的最新日期字段。

4、创建计算字段
判断近一周计算字段
[申请日期]>=DATEADD('day',-6,[日期参数]) and [申请日期]<=[日期参数]
//含义:申请日期是数据表中自带的日期字段,后面的日期参数是第3步所创建的参数。
判断近一月计算字段
[申请日期]>=DATEADD('month',-1,[日期参数]) and [申请日期]<=[日期参数]
//含义:申请日期是数据表中自带的日期字段,后面的日期参数是第3步所创建的参数。
判断近三月计算字段
[申请日期]>=DATEADD('quarter',-1,[日期参数]) and [申请日期]<=[日期参数]
//含义:申请日期是数据表中自带的日期字段,后面的日期参数是第3步所创建的参数。
判断近半年计算字段
[申请日期]>=DATEADD('month',-6,[日期参数]) and [申请日期]<=[日期参数]
//含义:申请日期是数据表中自带的日期字段,后面的日期参数是第3步所创建的参数。
判断近半月计算字段
[申请日期]>=DATEADD('day',-14,[日期参数]) and [申请日期]<=[日期参数]
//含义:申请日期是数据表中自带的日期字段,后面的日期参数是第3步所创建的参数。
判断控制统计周期计算字段
case [统计周期筛选]
when 1 then [近一周]
when 2 then [近半月]
when 3 then [近一月]
when 4 then [近三月]
when 5 then [近半年]
else [今年全部]
END
//含义:统计周期筛选是第3步所创建的统计周期筛选参数,then后面的是本步骤所创建的5个计算字段。
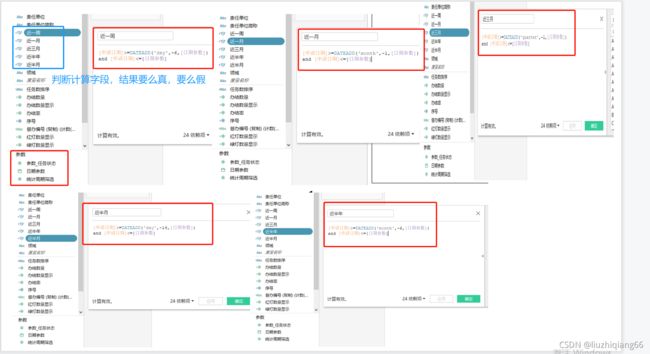
5、日期切换实现方式
凡是仪表板中所包含的需要切换日期展示的工作簿,均需要将控制统计周期计算字段放入本工作簿的筛选器中,且选中为真。

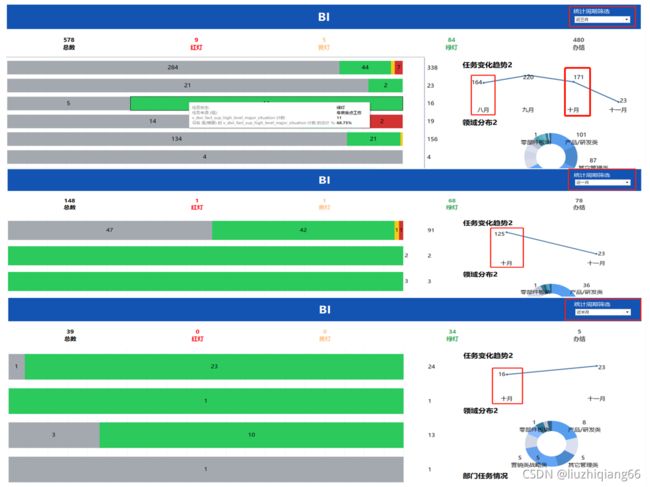
八、参数控制总数与各分状态切换(总数,红灯,绿灯等切换)
1:需求
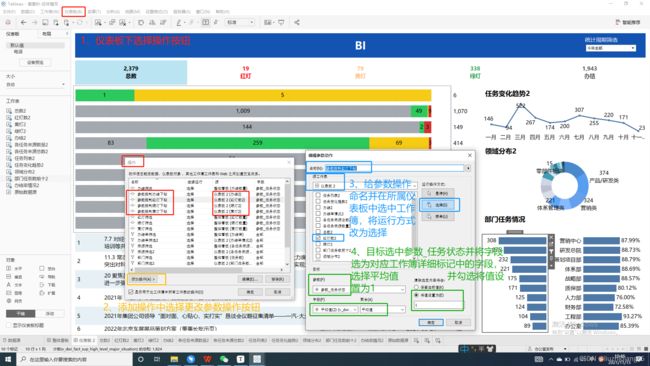
如下图所示:实现的效果是:打开报表页面时,顶端的卡片数据显示有:”总数、红灯、黄灯、绿灯、办结,五项;其中总数=红灯+黄灯+绿灯+办结“。除了卡片数据外,报表中的各类图形,表格均随点击的卡片而切换,只是默认显示是总数,这时,下方的条状图显示的是五颜六色的,且条状图的右侧合计数值的总和正好等于卡片的总数,而且趋势折线图和领域分布饼图及部门任务情况柱图的数值总和均等于卡片中的总数大小。但是一旦点击了红灯后,则条状图的柱子全部展示为红色,且右侧的合计数值的总和正好等于卡片中的红色数,而且趋势折线图和领域分布饼图及部门任务情况柱图的数值总和均等于卡片中的红灯数大小。总体而言:“卡片控制报表除卡位外其他所有图形和表格。”
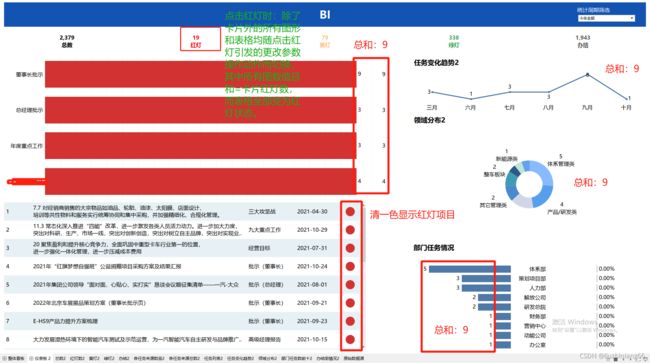
2、难点
除了卡片中的统计数据之外,其他的图形中的数据及表格状态均可随着点击卡片的切换切换而引发的更改参数操作动作而随之变化,因此需要建立参数_任务状态参数,以便用切换参数时通过将参数运用于判断计算字段中的方法实现点击卡片动作的切换。因此除了需要创建1个参数外,还需要创建判断参数=任务状态及总数判断处理共计2个计算字段。
3、参数的创建
参数_任务状态参数的设置,因卡片的切换包含总数,红灯,黄灯,绿灯,办结共5个选项,所以在值列表区域将5种情况依次列出。

4、创建计算字段
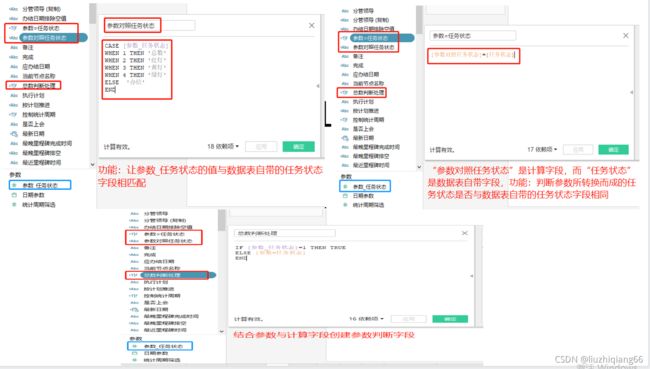
“参数对照任务状态”计算字段
CASE [参数_任务状态]
WHEN 1 THEN '总数'
WHEN 2 THEN '红灯'
WHEN 3 THEN '黄灯'
WHEN 4 THEN '绿灯'
ELSE '办结'
END
//含义:参数_任务状态是第3步所创建的参数;本计算字段是为了结合第3步的参数_任务状态参数,因为那个参数实际值是1-5,而数据表中的状态是总数,红灯等。
判断"参数=任务状态"计算字段
[参数对照任务状态]=[任务状态]
//含义:“参数对照任务状态”是刚刚所创建的计算字段,而“任务状态”则是数据表中含有的字段
判断“总数判断处理”计算字段
IF [参数_任务状态]=1 THEN TRUE
ELSE [参数=任务状态] END
//含义:“参数=任务状态”是刚刚所创建的计算字段。
5、状态切换实现方式
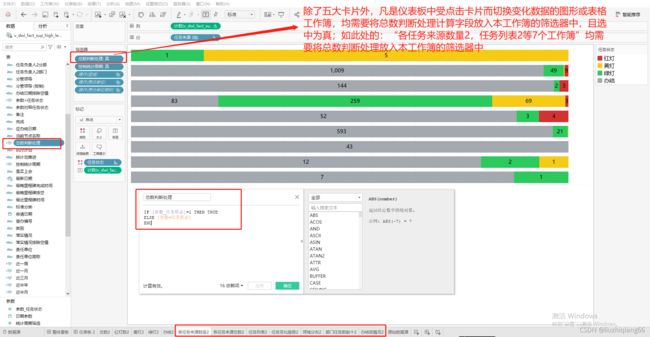
除了五大卡片外,凡是仪表板中受点击卡片而切换变化数据的图形或表格工作簿,均需要将总数判断处理计算字段放入本工作簿的筛选器中,且选中为真。
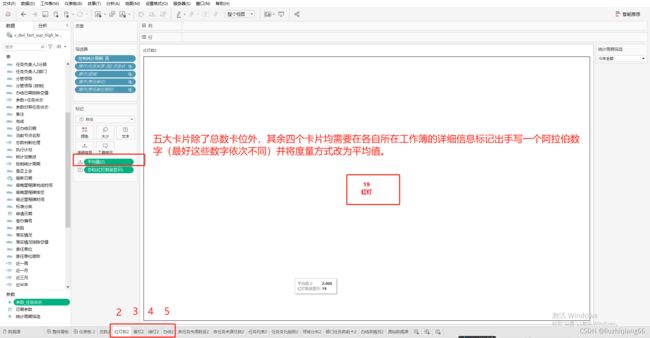
五大卡片除了总数卡位外,其余四个卡片均需要在各自所在工作簿的详细信息标记出手写一个阿拉伯数字(最好这些数字依次不同)并将度量方式改为平均值。
在本仪表板栏目下,选择操作按钮,添加4个更改参数操作来控制除卡片外其他工作簿的切换变化。
九、参数与集判断同时购买了其他产品
1、需求
如图常用函数一的购物车示例一样,只是示例中采用的是FIXED函数。此处采用参数来分析,购物车分析是通过顾客的购物车信息研究其购买行为。主要目的
在于找出什么样的东西应该放在一起。通过分析顾客的购买行为来探知顾客的属性及购买某些商品的可能原因,找出相关的联系规则,企业可利用这些规则更好的
挖掘商业利益并建立竞争优势。而且企业最常用的购物车分析当属关联购买分析:通过分析销售数据,来了解同时购买多个产品的人数或者订单数量,从而进行合
理的产品投放。最著名的购物篮分析,就属“啤酒与尿布”的故事,它正是一个典型的关联购买分析场景。
1、创建并显示参数
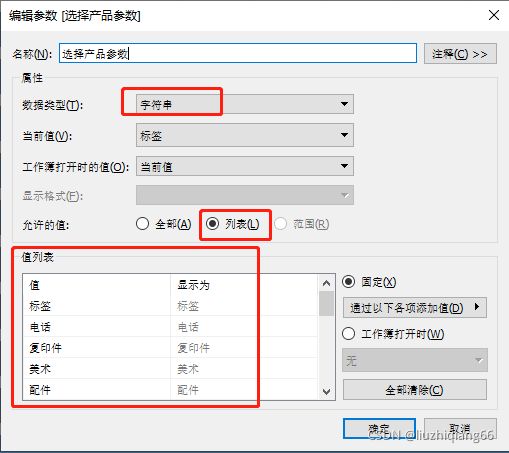
2、创建计算字段
if与参数判断同时购买了计算字段
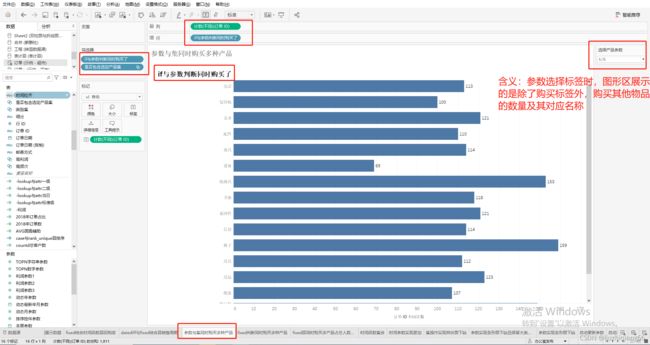
IF [子类别] <> [选择产品参数] THEN [子类别] END
//含义:除了用户通过参数选择的产品外,同时包含的其他产品。其中的'<>'表示不等于的含义
if与参数判同时购买产品数量计算字段
IF [子类别]=[选择产品参数] THEN 1 END
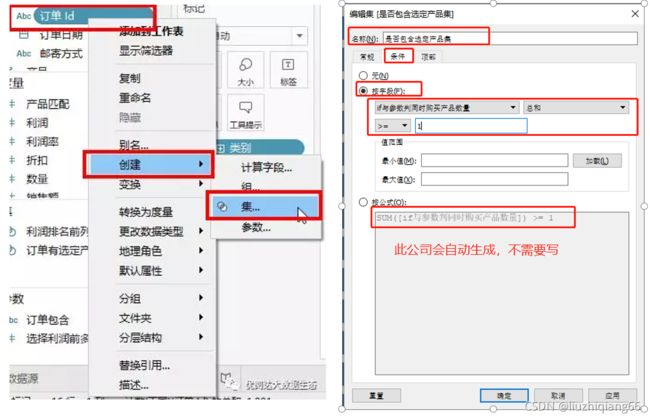
3、创建是否包含选定产品集
注意:选中订单ID字段,再创建集,选中从条件栏,根据上面创建if与参数判同时购买产品数量计算字段输入判断条件。
4、展示效果
集操作运用
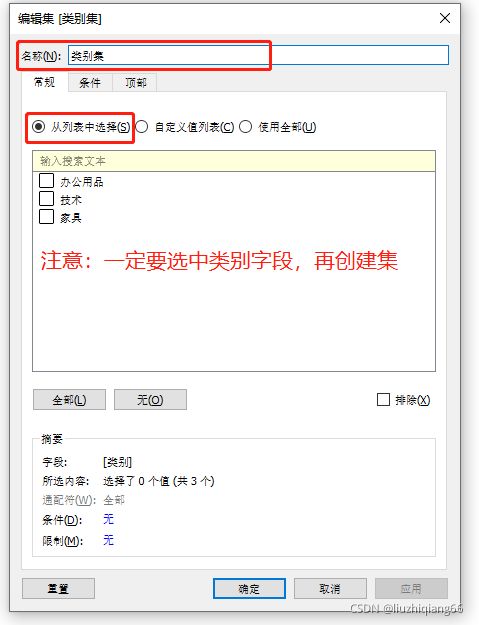
1:创建类别集
注意:选中类别字段,再创建集,选中从列表中选择按钮,但列表中的所有类别全部不得勾选,其原理跟参数运用下第五点参数实现数据下钻一样,只是参数
是让当前值为空白而已。
2:创建if判非对称子类计算字段
IF [类别集] THEN [子类别] ELSE [类别] END
3:创建类别集
注意:选中上述步骤2创建的计算字段,再创建集,选中从列表中选择按钮,但列表中的所有类别全部不得勾选。

4:创建if判非对称产品名称计算字段
IF [子类集] THEN [产品名称] ELSE '' END
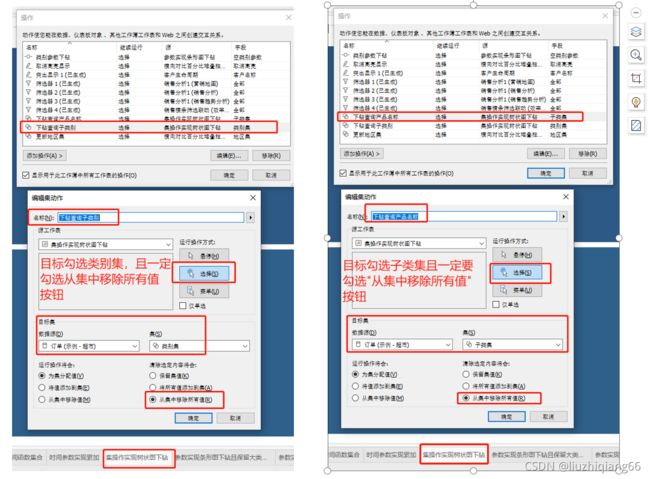
5:设置集下钻所对应更改集值操作及结果展示
设置更改集值操作控制树状图下钻:单击顶部菜单“工作表”,选择“操作”。在弹出的“操作”对话框中,选择“添加操作”-“更改集值”。然后根据右下侧所示:源工
作表选择本工作表,第1个集操作的目标集选中类别集,第2个集操作的目标集选中子类集,统一勾选从集中移除所有值按钮。
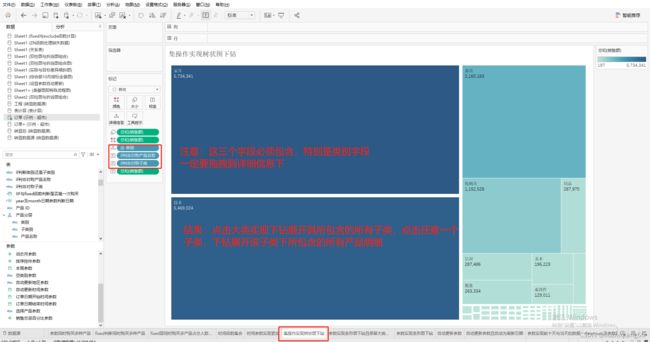
展示效果:结果:点击大类实现下钻展开其所包含的所有子类,点击任意一个子类,下钻展开该子类下所包含的所有产品明细。
手机端报表展示配置
