Uncertainty-guided dual-views for semi-supervised volumetric medical image segmentation
本篇文章发表于Nature Machine Intelligence 2023。
文章链接:Uncertainty-guided dual-views for semi-supervised volumetric medical image segmentation | Nature Machine Intelligence
一、概述
1. Background and motivation
医学图像分割是疾病诊断、治疗规划的基石(building block),在医疗领域占据着十分重要的地位。近些年,随着深度学习技术的飞快发展,基于深度学习的医学图像分割也取得了长足进步。然而,深度学习模型通常需要大量有标注的数据实现有监督(supervised)训练以达到较高的性能,尤其对于图像分割这种需要dense annotations的任务,这是十分昂贵又费时费力(expensive and laborious);当涉及到三维图像如CT、MRI时,这个问题将更加突出,这给AI在医学领域的发展与应用造成了阻碍;而即使我们不遗余力地找专家对数据进行标注,又常常会引入来自标注者的偏见,导致标注的不客观、预测的不准确。
在现实的医疗场景中,除了有标注的数据,还存在大量未标记的数据;我们在利用已有的labelled data的同时,也应该尽可能充分地利用这些大量的unlabelled data,最大化获取数据提供给我们的信息与知识,帮助我们的模型更好地学习,从而达到更高的性能——而这,恰恰对应着半监督学习。
2. Consensus principle
在这里我们暂且把“consensus principle”译为“共识原则”。共识原则的直观解释是,使不同观点之间尽可能达成一致可以将每种观点出现错误的概率降低。这种思想在日常生活中很常见,一个综合不同视角、汲取不同观点、被多方认可的一致协商往往更加客观、合理。
现在我们用数学语言来表示共识原则:假设我们有一个数据集 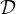 ,其中的数据点
,其中的数据点 ![]() 拥有两种视角(view),即
拥有两种视角(view),即 ![]() ,假设每一种视角的数据都是sufficient的,也就是说都可以独立地训练一个有效的模型,设
,假设每一种视角的数据都是sufficient的,也就是说都可以独立地训练一个有效的模型,设 ![]() 与
与 ![]() 对应于在两种视角下训练得到的模型,在一些“mild assumptions”下(这个assumption具体请参考文献[1]),我们可以定义:
对应于在两种视角下训练得到的模型,在一些“mild assumptions”下(这个assumption具体请参考文献[1]),我们可以定义:
![]()
也就是说,最小化两个模型之间不一致的概率可以降低所有模型犯错概率的最大值;共识原则可以理解为一种normalization,已经被很好地应用于multi-view learning中。
3. Challenges
在医学图像分割中利用multi-view learning面临着两方面的挑战。
(i) Multi-view learning requires diversity among multiple views.
Multi-vew learning要求同一数据在多个视图之间存在差异性,这样才能从不同视角观察同一样本,从而获得更客观、准确、丰富的样本信息,提升模型性能。比如,在分类任务中,我们可以使用data augmentation来构建多个view。然而在图像分割中,构建多个视图仍然“not well understood”。
(ii) The use of unlabelled data should be mindful.
对于semi-supervised learning,我们通过通过估计unlabelled data的label(即,伪标签)来消除训练过程中不确定样本的影响。然而,一旦伪标签估计存在错误,将极大地影响最终模型的效果。在分类问题中,我们可以通过测量prediction的uncertainty来衡量伪标签的质量(例如,通过对softmax产生的结果阈值化);然而对于图像分割,模型可能对图像某些部分的不确定性较高、其余部分不确定性较低,对整体uncertainty的衡量将变得十分敏感,因此需要谨慎设计。
4. Overall
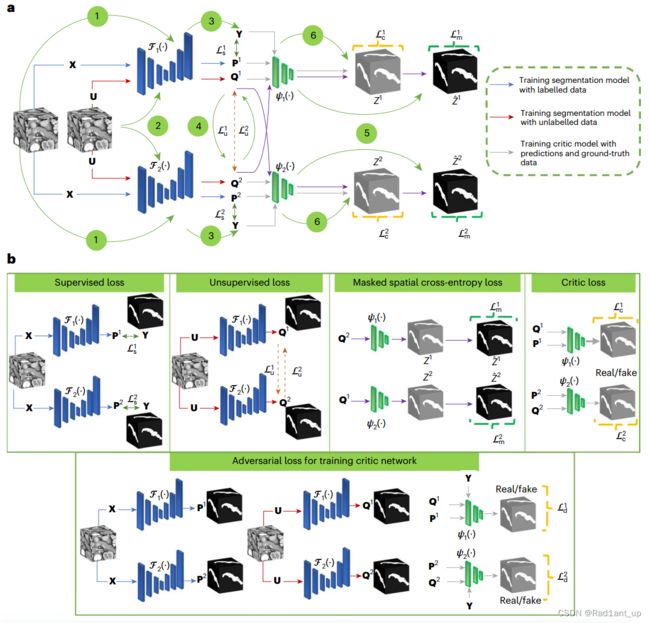
受半监督(semi-supervised)算法的启发,本文提出了一种基于对抗学习(adversarial learning)的双视图框架(dual-view framework)以完成对三维医学图像的分割任务。
所提出的算法Co-BioNet利用unlabelled data,通过一致性训练和基于熵的不确定性估计来指导模型的学习过程(基本思想是,“像素的熵值越高,表示不确定性越大”);为了处理这种不确定性,作者探索了贝叶斯建模(e.g. Mote-Carlo Dropout)和数据增强等方法。
在训练过程中,“协同”训练两个分割网络,并引入两个critics进行评估,每个视图(view)都可以从另一个视图的高置信预测(high-confidence predictins)中学习到有用的知识,确保两个view都可以进行可靠的预测。(相当于两个网络互相教,取长补短)
作者在四个包含有多个模态数据的公共数据集上对所提出方法与其它最先进的基准方法进行了比较(包括NIH胰腺CT数据集、左心房分割挑战MRI数据集、MSD脑肿瘤分割数据集以及BraTS Challenge 2022多机构多mpMRI数据集)。结果表明,所提出的Co-BioNet达到了与完全监督相媲美(competitive)的性能,证明了基于uncertainty的协同训练框架可以使两个神经网络对异常数据据具有鲁棒性,并且能够生成合理的segmentation mask,对半自动分割(semi-automated segmentation)任务有一定帮助。
二、结果与讨论
Nature系列的大部分文章习惯先讲results再讲methods,因此在本篇文章也遵循这个顺序进行介绍。
1. Evaluation metircs
(i) Dice similarity coefficient;
(ii) the Jaccard index/intersection over union, IoU;
(iii) the average symmetric surface distance, ASD;
(iv) Hausdorff distance
2. Results & Discussion
(i) Performance on NIH Pancreas CT dataset

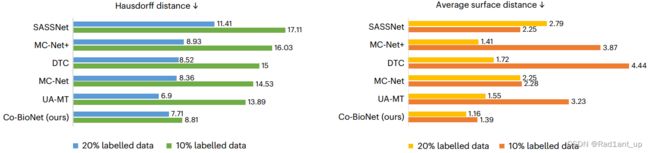
在10%与20% labelled data上评估semi-supervised segmentation的效果,Co BioNet在四项指标上几乎全部领先于其余方法。

使用20% labelled data的Co BioNet达到了与使用了100% labelled data的V-Netcompetitive的性能(上图最左侧两列,深蓝和橙色)。

对比了Co BioNet与MC-Net+的ROC曲线,Co BioNet的AUC更高。

箱线图。Co BioNet比MC-Net+的平均精度更高(中位数更大),性能更稳定(四分位距更小)、异常值更少。
(ii) Performance on MSD BraTS Dataset
作者评估了Co-BioNet在大规模多模态数据集上的扩展性(scalability)(e.g. MSD BraTS dataset,四种模态)。结果表明,使用30% labelled data训练的Co-BioNet与全监督的VNet和nnUNet 表现相当。
需要指出的是,目前的Co-BioNet框架使用VNet作为其分割网络。因此,通过配置不同的分割网络或优化后的分割网络可以进一步提高Co-BioNet的准确性。
(iii) View difference to satisfy conditional independence

使用centered kernel alignment (CKA)分析Co BioNet中两个模型分割结果的相似性(resemblance)——“CKA can reliably identify the resemblance between representations of networks trained with different random initializations and hyperparameters”——结果显示,大部分的CKA值小于0.5,意味着两个网络之间不相似,存在diversity,这样可以保证网络在训练期间不容易缺乏充分性(sufficiency),即前面所提到的任一视角的数据都可以独立训练一个网络(“the individual view is sufficient for classification on its own”)。
(iv) Satisfying view sufficiency towards compatibility
“Insufficient views of a co-training structure can lead to performance degradation of all views in co-training”,一个视图的不充分会导致所有视图性能下降。因此,引入两个critics用于判断每个分割网络所生成segmentation mask的置信区域,保证视图之间的diversity并避免出现视图不充分问题。再次说明,所谓“充分”就是指每个view都可以独立训练一个表现良好的模型。
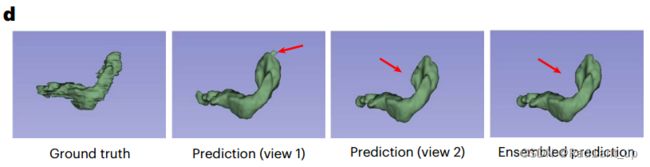
经过训练,两个视图都可以得到性能良好的分割网络(如上方图及下方表格所示;其中,下方表格分别对应10% labelled data以及20% labelled data)。
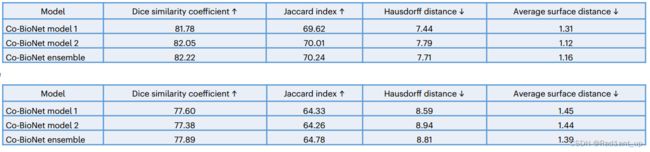
(v) Robustness analysis
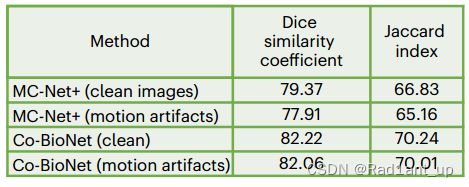

人为地在推理时向医学图像中引入了常见的运动伪影,以模拟患者运动和采集条件可能带来的噪音。比较了Co BioNet与 MC-Net+的表现,发现Co BioNet具有更强的鲁棒性。(ps.结果被叠加在了original image上)
(vi) Uncertainty estimation
这一部分作者主要讲述了不确定性估计的重要性,以及 Co-BioNet 框架是如何借鉴生成对抗网络(GAN)的discriminative feature detection来进行不确定性估计的。
Co-BioNet 期望模型能够生成准确的分割掩模,并通过两个critic networks的辨别能力对生成的预测进行置信度评估。下中的分割结果展示了 Co-BioNet 既能够产生准确的预测结果,还可以生成对应的置信度图。

置信度图以热图的形式展示,对预测的掩模中不同区域的不确定程度进行可视化。红色像素代表置信度较低/高度不确定的部分,蓝色像素代表置信度较高/确定的部分。(该模型在NIH 20% labelled data上进行训练得到)
(vii) Ablation study

(iix) Dual-views to multi-views
理论上,视角(view)越多,效果应该越好。因此作者尝试了将当前的dual-views扩展到multi-views(以三视角为例),但是发现性能有所下降。
对于这个现象,作者给出了分析:当模型数量增加的时候(≥3),需要开发一种特殊的“通信”方法将一个模型的置信度用于其它模型。
“A straightforward way is to consider aggregated masked spatial cross-entropy loss for the confidence maps generated from the neighbouring critic and calculate symmetric cross-entropy only based on the neighbouring segmentation model’s prediction for unlabelled data (in a cyclic pattern, as shown in Fig. 3c). However, our results show that this design is not successful.”

多视角类似于人类从群体中学习的方式,这部分算是未来工作。
(ix) Discussion
本篇文章的优势在于it provides a generic semi-supervised learning approach for segmenting volumetric medical image modalities. 可见Nature系列还是十分关注方法的通用性和文章高度的;提出的并不单单是一个方法,而是一个新的范式,以指导其它半监督学习任务的方法研究,适用于多种视觉场景与任务。
此外,作者也探讨了关于Co BioNet需要更多计算资源的原因,但是同时也指出随着计算工具和硬件设备的发展,模型的参数量大小并不应该影响AI与医疗之间的结合。
三、方法
1. Problem formulation
向量用bold lower-case 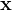 表示,矩阵用bold upper-case
表示,矩阵用bold upper-case 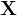 表示;如果对张量使用norm或inner product操作,则默认张量是flattened的。比如,对于3D tensors
表示;如果对张量使用norm或inner product操作,则默认张量是flattened的。比如,对于3D tensors ![]() and
and ![]() :
:
![]()
and
![]()
Let ![]() be a labelled set with
be a labelled set with  samples, where each sample
samples, where each sample ![]() consists of an image
consists of an image ![]() and its associated ground-truth segmentation mask
and its associated ground-truth segmentation mask ![]() encoded as a one-hot
encoded as a one-hot  -dimensional vector for a -class problem per voxel. Here,
-dimensional vector for a -class problem per voxel. Here,  ,
,  ,
,  and
and  represent the number of channels, height, width and depth of the input medical volume.
represent the number of channels, height, width and depth of the input medical volume.
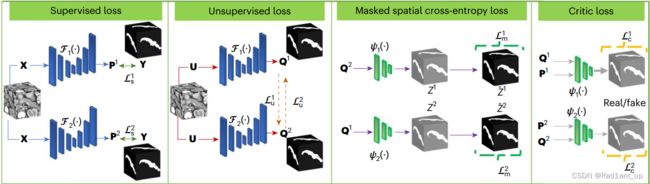
Furthermore, let ![]() be a set of n unlabelled samples with
be a set of n unlabelled samples with 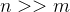 . The primary objective is to learn two segmentation models
. The primary objective is to learn two segmentation models ![]() from
from ![]() , while introducing uncertainty guidance using two critic networks
, while introducing uncertainty guidance using two critic networks ![]() .
.
2. Co-BioNet and baselines
(i) Co-BioNet

使用相同的labelled data与unlabelled data协同训练两个分割网络 ![]() 与
与 ![]() ;
;
作者指出,虽然可以使用data augmentation以及adversarial perturbation的方法构造multi views of inputs,但这种创建方式是否合理仍不清楚,构建不同视图以进行协同训练的理论还需进一步完善。本文可以通过网络来实现视图之间的dissimilarity,因此输入的数据是相同的。(Note:,一般而言,多视图模型的输入是不一致的,但Co BioNet可以使用一些constraint限制网络从不同视角学习到数据的不同特征,因此输入是一致的)
(ii) Baselines
包括UA-MT,SASSNet,DTC,MC-Net,MC-Net+以及全监督的V-Net。
3. Training objective
模型包含两个部分、四个模块:segmentation network(![]() 与
与 ![]() )以及critic network(
)以及critic network(![]() 与
与 ![]() )。其中,segmentaion network用V-Net实现,拥有类似于U-Net的编码器解码器及跳跃连接;critic network用扩展到3D版本的Markovian PatchGAN实现,是一个全卷积网络。
)。其中,segmentaion network用V-Net实现,拥有类似于U-Net的编码器解码器及跳跃连接;critic network用扩展到3D版本的Markovian PatchGAN实现,是一个全卷积网络。
假设dual-view network(其实就是segmentation network)的参数为 ![]() ,critic network的参数为
,critic network的参数为 ![]() 。通过解决以下min-max问题来得到模型的参数:
。通过解决以下min-max问题来得到模型的参数:
![]()
其中,![]() 包含了网络的全部参数
包含了网络的全部参数 ![]() ;
;
这里的min-max problem与GAN[2]的想法是一致的。判别器critic(![]() )的任务是要正确判断输入的segmentation mask到底是来自ground-truth label还是由segmentation network生成的(我们希望输入是ground-truth label时,critic的输出为1;输入是segmentation network生成的label时,critic的输出为0);因此,此处的“max”意味着使critic的判别能力最大化,可以准确判断标签是“真的”还是“假的”;而“min”意味着使generator所生成的label与ground-truth label之间的差异最小化,使生成的label更加逼真,从而可以骗过critic。
)的任务是要正确判断输入的segmentation mask到底是来自ground-truth label还是由segmentation network生成的(我们希望输入是ground-truth label时,critic的输出为1;输入是segmentation network生成的label时,critic的输出为0);因此,此处的“max”意味着使critic的判别能力最大化,可以准确判断标签是“真的”还是“假的”;而“min”意味着使generator所生成的label与ground-truth label之间的差异最小化,使生成的label更加逼真,从而可以骗过critic。
我们希望同时使用labelled data与unlabelled data协同训练,因此定义以下multi-task loss function:
其中,![]() 分别是the supervised loss,the unsupervised loss,the critic loss以及the masked loss,我们一个一个来看一下。
分别是the supervised loss,the unsupervised loss,the critic loss以及the masked loss,我们一个一个来看一下。
(Note:以下步骤仅优化 ![]() 而不涉及
而不涉及 ![]() )
)
(i) The supervised loss ![]()
首先是第一项损失![]() ,the supervised loss
,the supervised loss ![]() encourages each segmentation network to generate prediction masks for labelled data close to the ground-truth mask. 这一项loss由两部分组成,cross-entropy loss以及dice loss:
encourages each segmentation network to generate prediction masks for labelled data close to the ground-truth mask. 这一项loss由两部分组成,cross-entropy loss以及dice loss:
![]()
当![]() 与
与![]() 分布一致时,交叉熵最小;dice系数最大,dice loss最小。
分布一致时,交叉熵最小;dice系数最大,dice loss最小。
The supervised loss ![]() 就是二者的aggregated form:
就是二者的aggregated form:
![]()
(ii) The unsupervised loss ![]()
继续看第二项损失 ![]() ,该loss function的输入是两个segmentation network的参数以及unlabelled data
,该loss function的输入是两个segmentation network的参数以及unlabelled data ![]() 。定义:
。定义:
![]()
![]()
![]() 鼓励
鼓励 ![]() 与
与 ![]() 的分布趋向于一致,即,当处理同一个unlabelled data时,所生成的segmentation mask要相似,也就是所谓的不同分割网络之间要“达成共识”。
的分布趋向于一致,即,当处理同一个unlabelled data时,所生成的segmentation mask要相似,也就是所谓的不同分割网络之间要“达成共识”。
(iii) The critic loss ![]()
第三项损失 ![]()

当 ![]() 最小时,意味着
最小时,意味着 ![]() 的输出均为1,即对于当前的判别器critic而言,会将所有segmentation network生成的label都认为是“真的”。
的输出均为1,即对于当前的判别器critic而言,会将所有segmentation network生成的label都认为是“真的”。
——这正是我们的目的,优化![]() 使得segmentation network能够“以假乱真”,让critic出错。(再次强调,这一步更新的是segmentation network的参数
使得segmentation network能够“以假乱真”,让critic出错。(再次强调,这一步更新的是segmentation network的参数 ![]() ,不涉及critic network的参数
,不涉及critic network的参数 ![]() )
)
(iv) The masked loss ![]()
以 ![]() 为例进行说明:设置一个阈值
为例进行说明:设置一个阈值 ![]() ,如果由第二个segmentation network(参数为
,如果由第二个segmentation network(参数为 ![]() )产生的generated mask即
)产生的generated mask即 ![]() 中的点
中的点 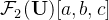 通过critic后的结果大于阈值
通过critic后的结果大于阈值 ![]() ,则说明critic对该点的输出置信度很高,也说明
,则说明critic对该点的输出置信度很高,也说明![]() 在
在![]() 处生成的mask与真实分布很相近;此时indicator function取值为1,会encourage另一个network(也就是
处生成的mask与真实分布很相近;此时indicator function取值为1,会encourage另一个network(也就是 ![]() )的输出与当前network的输出分布一致;反之,如果低于
)的输出与当前network的输出分布一致;反之,如果低于 ![]() 则说明不确定,信号就不会传递到另一个网络中。
则说明不确定,信号就不会传递到另一个网络中。
两个segmentation network可以通过这种信息传递方式告诉对方自己在哪个区域生成的mask较好,成为对方的“老师”,互相学习、取长补短。
总结一下四个损失。generator的目的是生成与真实标签分布一致的标签,(1) 通过对labelled data有监督的交叉熵、dice损失使predicted label与ground-truth label一致;(2) 通过unsupervised loss实现两个network对unlabelled data分割的“协商一致”;(3) 通过critic loss使generator生成的label尽可能逼真从而骗过critic;(4) 通过masked loss实现两个网络的“有用信息传递”,成为对方的老师“共同进步”。
以上是用来更新segmentation network参数 ![]() 的损失函数,接下来我们看一下critic network(参数
的损失函数,接下来我们看一下critic network(参数 ![]() )对应的损失函数定义:
)对应的损失函数定义:
对于generator来说,它的目的是尽可能成功判断哪些label是来自于ground-truth的、哪些是来自于segmentation network的。因此,我们需要通过优化参数 ![]() 使critic有高超的分辨能力。
使critic有高超的分辨能力。
我们将利用:
(1) labelled data的ground-truth label;
(2) labelled data的prediction mask;
(3) unlabelled data的prediction mask
对参数 ![]() 进行优化。
进行优化。
We define the adversarial loss as maximizing the log-likelihood for labelled prediction distribution as ——使用的是(1)和(2):
where ![]() if the sample is a prediction mask from a segmentation network, and
if the sample is a prediction mask from a segmentation network, and ![]() if the sample is fetched from the ground-truth label distribution.
if the sample is fetched from the ground-truth label distribution.
而对于unlabelled data,由于我们没有ground-truth label,因此我们不能应用任何有监督的loss。但是我们知道的是,unlabelled data的label一定是由segmentation network生成的,即,一定是“假的”,相当于上式中 ![]() 。于是,the adversarial loss for prediction masks without annotated data is defined as——使用的是(3):
。于是,the adversarial loss for prediction masks without annotated data is defined as——使用的是(3):
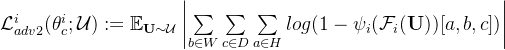
The overall normalized critic loss for training individual critic networks is defined as
![]()
同时利用到了labelled data  与unlabelled data
与unlabelled data ![]() 。
。

4. Algorithm

在每个epoch,先优化generator(segmentation network)的参数 ![]() ,使其产生与ground-truth label分布一致的mask并“骗过”critic;再优化critic network的参数
,使其产生与ground-truth label分布一致的mask并“骗过”critic;再优化critic network的参数 ![]() ,使其能够准确分辨输入的mask是否来自ground-truth label。
,使其能够准确分辨输入的mask是否来自ground-truth label。
参考文献
- Dasgupta S, Littman M, McAllester D. PAC generalization bounds for co-training. Advances in neural information processing systems, 2001, 14.
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks. Communications of the ACM, 2020, 63(11): 139-144.